Best AI tools for< Provide Evaluation Metrics >
20 - AI tool Sites

usefulAI
usefulAI is a platform that allows users to easily add AI features to their products in minutes. Users can find AI features that best meet their needs, test them using the platform's playground, and integrate them into their products through a single API. The platform offers a user-friendly playground to test and compare AI solutions, provides pricing and metrics for evaluation, and allows integration within applications using a single API. usefulAI aims to provide practical AI engines in one place, without hype, for users to leverage in their products.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
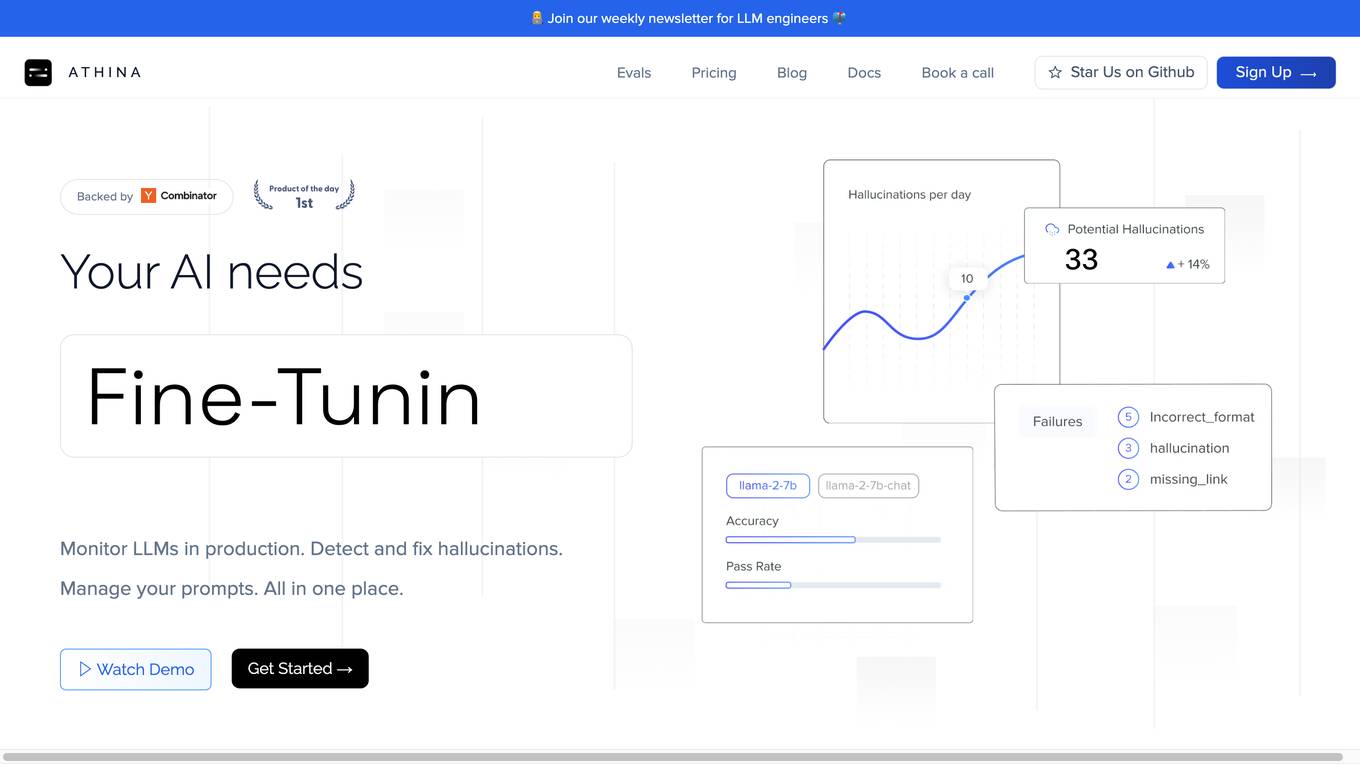
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
Reka
Reka is a cutting-edge AI application offering next-generation multimodal AI models that empower agents to see, hear, and speak. Their flagship model, Reka Core, competes with industry leaders like OpenAI and Google, showcasing top performance across various evaluation metrics. Reka's models are natively multimodal, capable of tasks such as generating textual descriptions from videos, translating speech, answering complex questions, writing code, and more. With advanced reasoning capabilities, Reka enables users to solve a wide range of complex problems. The application provides end-to-end support for 32 languages, image and video comprehension, multilingual understanding, tool use, function calling, and coding, as well as speech input and output.
Langfuse
Langfuse is an AI tool that offers the Langfuse TypeScript SDK v4 for building and debugging LLM (Large Language Models) applications. It provides features such as tracing, prompt management, evaluation, and metrics to enhance the performance of LLM applications. Langfuse is backed by a team of experts and offers integrations with various platforms and SDKs. The tool aims to simplify the development process of complex LLM applications and improve overall efficiency.
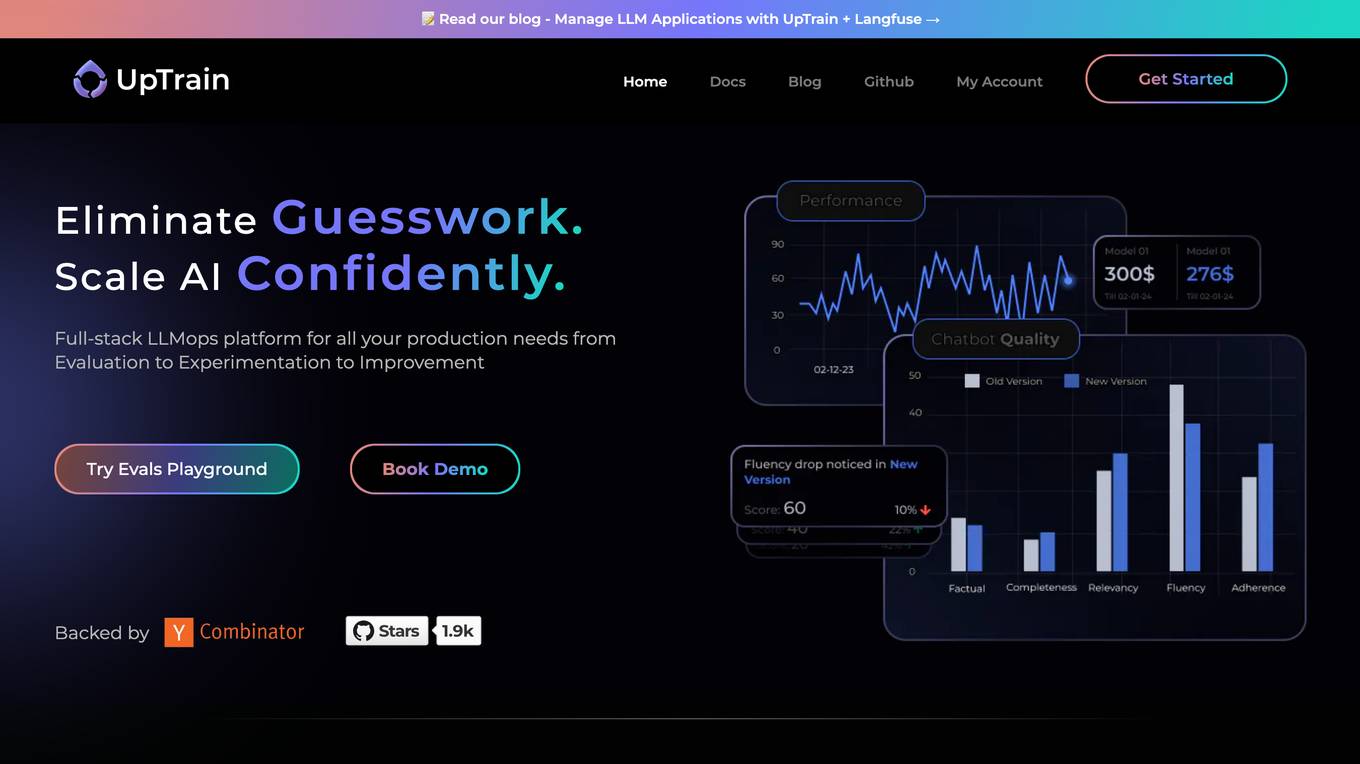
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
GreetAI
GreetAI is an AI-powered platform that revolutionizes the hiring process by conducting AI video interviews to evaluate applicants efficiently. The platform provides insightful reports, customizable interview questions, and highlights key points to help recruiters make informed decisions. GreetAI offers features such as interview simulations, job post generation, AI video screenings, and detailed candidate performance metrics.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.
User Evaluation
User Evaluation is an AI-first user research platform that leverages AI technology to provide instant insights, comprehensive reports, and on-demand answers to enhance customer research. The platform offers features such as AI-driven data analysis, multilingual transcription, live timestamped notes, AI reports & presentations, and multimodal AI chat. User Evaluation empowers users to analyze qualitative and quantitative data, synthesize AI-generated recommendations, and ensure data security through encryption protocols. It is designed for design agencies, product managers, founders, and leaders seeking to accelerate innovation and shape exceptional product experiences.
The Futurum Group
The Futurum Group is an AI tool that provides data and intelligence analysis, testing, labs, validation, research, advisory services, media activation, and custom projects. It covers various topics such as artificial intelligence software and tools, devices, channels, go-to-market strategies, cybersecurity, DevOps, application development, enterprise applications, semiconductors, and more. The platform offers insights, research reports, and expert analysis to help businesses stay competitive and make informed decisions in the tech industry.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps refine and improve ideas quickly and intelligently, acting as a one-person team for business dreamers. The platform assists in turning ideas into reality, from business concepts to creative projects, by leveraging the latest AI tools and technologies to innovate faster and smarter.
VMock Dashboard
VMock Dashboard is an AI-powered platform designed to provide personalized feedback on resumes. It leverages machine learning algorithms to analyze resumes and offers detailed insights on areas of improvement. Users can upload their resumes, receive instant feedback on content, formatting, and overall effectiveness, and track their progress over time. VMock Dashboard aims to help individuals enhance their resumes and increase their chances of landing their desired job opportunities.
Resumecheck.net
Resumecheck.net is an AI-powered resume improvement platform that helps users create error-free, professional resumes that stand out to recruiters. The platform uses GPT4 technology to provide personalized feedback and suggestions, including grammar corrections, formatting adjustments, and industry-specific keyword optimization. Additionally, Resumecheck.net offers an AI Cover Letter Writer that generates tailored cover letters based on the user's resume and the specific job position they are applying for.
Checkmyidea-IA
Checkmyidea-IA is an AI-powered tool that helps entrepreneurs and businesses evaluate their business ideas before launching them. It uses a variety of factors, such as customer interest, uniqueness, initial product development, and launch strategy, to provide users with a comprehensive review of their idea's potential for success. Checkmyidea-IA can help users save time, increase their chances of success, reduce risk, and improve their decision-making.
DisplayGateGuard
DisplayGateGuard is an AI-powered brand safety and suitability provider that helps advertisers choose the right placements, isolate fraudulent websites, and enhance brand safety. By leveraging artificial intelligence, the platform offers curated inclusion and exclusion lists to provide deeper insights into the environments and contexts where ads are shown, ensuring campaigns reach the right audience effectively.
TOPY AI LTD
TOPY AI LTD is an AI tool designed to provide affordable and advanced AI agents to automate core services for startups. The tool focuses on services such as project evaluation, market research, financial mentoring, and more. It aims to empower startups to succeed through autonomous AI agents that streamline project and team management, co-founder matchmaking, talent sourcing, business reviews, market research insights, and financial mentoring. TOPY AI LTD's mission is to be the leading AI service provider for startups, enhancing their innovation and competitiveness globally.
Adminer
Adminer is a comprehensive platform designed to assist e-commerce entrepreneurs in identifying, analyzing, and validating profitable products. It leverages artificial intelligence to provide users with data-driven insights, enabling them to make informed decisions and optimize their product offerings. Adminer's suite of features includes product research, market analysis, supplier evaluation, and automated copywriting, empowering users to streamline their operations and maximize their sales potential.
Skyline AI
Skyline AI is an AI tool that specializes in the analysis of commercial real estate properties. It offers a platform for faster and more comprehensive evaluation of real estate investments. The tool leverages artificial intelligence to provide state-of-the-art updates on real estate and technology, enabling users to make informed decisions in the real estate sector.
GPTHelp.ai
GPTHelp.ai is an AI chatbot tool designed to help website owners provide instant answers to their visitors' questions. The tool is trained on the website content, files, and FAQs to deliver accurate responses. Users can customize the chatbot's design, behavior, and personality to fit their needs. With GPTHelp.ai, creating and training your own AI chatbot is quick and easy, eliminating the need for manual setup of FAQs. The tool also allows users to monitor conversations, intervene if necessary, and view chat history for performance evaluation.
Eve
Eve is an AI-powered tool designed for labor and employment lawyers to streamline their casework, increase efficiency, and boost revenue. It acts as a 'second brain' and an extra set of hands, tailored to the lifecycle of cases. Eve assists in case intake and evaluation, drafting documents and letters, propounding discovery, responding to discovery, and more. The tool is trusted by thousands of forward-thinking plaintiff lawyers and offers features like powerful analytics, shared team inboxes, instant customer service, and easy-to-use reports.
1 - Open Source AI Tools

Quantus
Quantus is a toolkit designed for the evaluation of neural network explanations. It offers more than 30 metrics in 6 categories for eXplainable Artificial Intelligence (XAI) evaluation. The toolkit supports different data types (image, time-series, tabular, NLP) and models (PyTorch, TensorFlow). It provides built-in support for explanation methods like captum, tf-explain, and zennit. Quantus is under active development and aims to provide a comprehensive set of quantitative evaluation metrics for XAI methods.
20 - OpenAI Gpts
Evaluation Criteria Creator
Simply write any topic (anything superheroes, vacuums, Pokémon’, diamonds…) and I’ll provide the evaluation criteria you can use.

Agile Consultant
Expert in Agile SDLC, helping the teams to get familiar with best practices and provide audit and evaluation services

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.
EduCheck
Automatically evaluates uploaded lesson plans against educational standards. Upload text or a PDF.
Essay Evaluator
Evaluates essays, highlights strengths and improvement areas, and justifies scores.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.
Design Crit
I conduct design critiques focused on enhancing understanding and improvement.

CIM Analyst
In-depth CIM analysis with a structured rating scale, offering detailed business evaluations.


M&E Expert
I'm an M&E expert for NGOs, offering professional, detailed guidance to specialists.
Face Rating GPT 😐
Evaluates faces and rates them out of 10 ⭐ Provides valuable feedback to improving your attractiveness!
IQ Test Assistant
An AI conducting 30-question IQ tests, assessing and providing detailed feedback.