
SakuraLLM
适配轻小说/Galgame的日中翻译大模型
Stars: 2717
SakuraLLM is a project focused on building large language models for Japanese to Chinese translation in the light novel and galgame domain. The models are based on open-source large models and are pre-trained and fine-tuned on general Japanese corpora and specific domains. The project aims to provide high-performance language models for galgame/light novel translation that are comparable to GPT3.5 and can be used offline. It also offers an API backend for running the models, compatible with the OpenAI API format. The project is experimental, with version 0.9 showing improvements in style, fluency, and accuracy over GPT-3.5.
README:
🤗 Hugging Face • 🤖 ModelScope
目前Sakura发布的所有模型均采用CC BY-NC-SA 4.0协议,Sakura所有模型与其衍生模型均禁止任何形式的商用!Sakura系列所有模型皆仅供学习交流使用,开发者对使用Sakura模型造成的问题不负任何责任。
-
基于一系列开源大模型构建,在通用日文语料与轻小说/Galgame等领域的中日语料上进行继续预训练与微调,旨在提供开源可控可离线自部署的、ACGN风格的日中翻译模型。
-
新建了TG交流群,欢迎交流讨论。
对于其他适配本模型的项目如使用非本项目提供的prompt格式进行翻译,不保证会获得与README中的说明一致的质量!
如果使用模型翻译并发布,请在最显眼的位置标注机翻!!!!!开发者对于滥用本模型造成的一切后果不负任何责任。
由于模型一直在更新,请同时注明使用的模型版本等信息,方便进行质量评估和更新翻译。
对于模型翻译的人称代词问题(错用,乱加,主宾混淆,男女不分等)和上下文理解问题,如果有好的想法或建议,欢迎提issue!
详见本仓库Wiki.
部分使用方法:usage.md
请注意,如果给轻小说机翻站使用,请参见机翻站站内教程,本 repo 不适用。
如果是翻译字幕等文本,可以考虑直接使用 AiNiee
| 参数量 | 发布时间-底模-版本 | 模型 |
|---|---|---|
| 32B | 20240508-Qwen1.5-32B-v0.9 | 🤗 Sakura-32B-Qwen2beta-v0.9-GGUF |
| 14B | 20241008-Qwen2.5-14B-v1.0 | 🤗 Sakura-14B-Qwen2.5-v1.0-GGUF |
| 7B | 20241123-Qwen2.5-7B-v1.0 | 🤗 Sakura-7B-Qwen2.5-v1.0-GGUF |
| 20240531-Qwen1.5-7B-Galtransl-v2.6 | 🤗 Galtransl-v2.6 | |
| ~2B | 20241012-Qwen2.5-1.5B-v1.0 | 🤗 Sakura-1.5B-Qwen2.5-v1.0-GGUF |
p.s. 如果无法连接到HuggingFace服务器,可将链接中的huggingface.co改成hf-mirror.com,使用hf镜像站下载。
-
更新了基于Qwen2.5的v1.0正式版14B模型Sakura-14B-Qwen2.5-v1.0、1.5B模型Qwen2.5-1.5B-v1.0和7B模型Sakura-7B-Qwen2.5-v1.0-GGUF。prompt格式参见下方说明。主要改进:
- 改善翻译质量,提高翻译准确率,尤其是人称的准确率。
- 支持术语表(GPT字典),以保持专有名词和人称的一致性。
- 提高部分简单控制符的保留能力,尤其是单行内存在
\n的情况下保留\n的能力。降低行数与原文不一致的概率。 - 由于底模使用GQA,推理速度和显存占用显著改善,可实现更快的多线程推理。关于多线程推理,可参考Sakura启动器GUI使用教程或SakuraLLMServer。
-
更新了基于Qwen1.5-7B的Galtransl模型,为视觉小说翻译任务专项优化。对视觉小说脚本中的行内换行、控制符、ruby注音等符号具有较好的保留能力。适配GalTransl视觉小说翻译工具并调优,支持GPT字典(字典写法见此)。
-
增加了vllm模型后端的支持,详见#40
-
感谢Isotr0py提供运行模型的NoteBook仓库SakuraLLM-Notebooks,可在Colab(免费T4*1)与Kaggle(免费P100*1或T4*2)平台使用。已经更新Kaggle平台的使用教程,可以白嫖一定时间的T4*2。警告,Kaggle 官方已经采取措施封禁 SakuraLLM 所有模型,参见 ,在 Kaggle 上使用 SakuraLLM 将会导致永久性封号。请转移至租卡或者利用机翻站算力共享工具(为防止滥用,请自行搜索)。 -
Sakura API已经支持OpenAI格式,现在可以通过OpenAI库或者OpenAI API Reference上的请求形式与Server交互。 一个使用OpenAI库与Sakura模型交互的例子详见openai_example.py。
-
网站:轻小说机翻机器人已接入Sakura模型(v0.8-4bit),站内有大量模型翻译结果可供参考。你也可以自行部署模型并使用该网站生成机翻,目前已经支持v0.8与v0.9模型,且提供了llama.cpp一键包。
轻小说机翻机器人网站是一个自动生成轻小说机翻并分享的网站。你可以浏览日文网络小说,或者上传Epub/Txt文件,并生成机翻。
-
LunaTranslator已经支持Sakura API,可以通过本地部署API后端,并在LunaTranslator中配置Sakura API来使用Sakura模型进行Galgame实时翻译。
使用KurikoMoe的版本可以支持流式输出。目前官方版本已经支持流式输出,只需在翻译设置界面勾选流式输出即可。LunaTranslator是一个Galgame翻译工具,支持剪贴板、OCR、HOOK,支持40余种翻译引擎。
-
GalTransl已经支持Sakura API,可以通过本地部署API后端,在GalTransl中配置使用Sakura模型来翻译Galgame,制作内嵌式翻译补丁。
GalTransl是一个galgame自动化翻译工具,用于制作内嵌式翻译补丁。一个使用GalTransl和Sakura模型翻译的示例
-
翻译Unity引擎游戏的工具SakuraTranslator。感谢fkiliver提供。
-
翻译RPGMaker引擎游戏的工具RPGMaker_LLaMA_Translator。感谢fkiliver提供。
-
AiNiee已经支持Sakura API,可以通过本地部署API后端,在AiNiee中使用Sakura模型进行翻译。
AiNiee是一款基于【mtool】或【Translator++】,chatgpt自动批量翻译工具,主要是用来翻译各种RPG游戏。
-
manga-image-translator已经支持Sakura API,可以通过本地部署API后端,使用Sakura自动翻译漫画。
-
BallonsTranslator已经支持Sakura API,可以通过本地部署API后端,使用Sakura翻译漫画。
目前Sakura Launcher GUI可以支持NVIDIA独立显卡,部分AMD独立显卡和一部分核显的一键安装与启动。
下面的表格显示了部分模型推荐的显卡显存大小。如果你的显卡显存不满足上述需求,可以尝试同时使用CPU与GPU进行推理。
| 模型 | 显存大小 | 模型规模 |
|---|---|---|
| sakura-7b-qwen2.5-v1.0-iq4xs.gguf | 8G/10G | 7B |
| sakura-14b-qwen2.5-v1.0-iq4xs.gguf | 11G/12G/16G | 14B |
| sakura-14b-qwen2.5-v1.0-q6k.gguf | 24G | 14B |
- Finetuned by SakuraUmi
- Finetuned on Baichuan2-13B-Chat
- Continual Pre-trained on Qwen model series
- Continual Pre-trained on Qwen1.5 model series
- Finetuned on Sakura-Base model series
- Languages: Chinese/Japanese
-
Galgame
-
轻小说
网站:轻小说机翻机器人已接入Sakura模型(v0.9),站内有大量模型翻译的轻小说可供参考。
-
PPL
Sakura-14B-Qwen2beta-v0.9-iq4_xs_ver2: 4.43
Sakura-32B-Qwen2beta-v0.9-iq4xs: 3.28
-
openai api messages格式:
- v0.9
使用代码处理如下:
input_text_list = ['a', 'bb', 'ccc', ...] # 一系列上下文文本,每个元素代表一行的文本 raw_text = "\n".join(input_text_list) messages=[ { "role": "system", "content": "你是一个轻小说翻译模型,可以流畅通顺地以日本轻小说的风格将日文翻译成简体中文,并联系上下文正确使用人称代词,不擅自添加原文中没有的代词。" }, { "role": "user", "content": "将下面的日文文本翻译成中文:" + raw_text } ]
- v0.9
使用代码处理如下:
-
prompt格式:
-
v1.0pre1 代码处理如下:
gpt_dict = [{ "src": "原文1", "dst": "译文1", "info": "注释信息1", },] gpt_dict_text_list = [] for gpt in gpt_dict: src = gpt['src'] dst = gpt['dst'] info = gpt['info'] if "info" in gpt.keys() else None if info: single = f"{src}->{dst} #{info}" else: single = f"{src}->{dst}" gpt_dict_text_list.append(single) gpt_dict_raw_text = "\n".join(gpt_dict_text_list) user_prompt = "根据以下术语表(可以为空):\n" + gpt_dict_raw_text + "\n" + "将下面的日文文本根据对应关系和备注翻译成中文:" + japanese prompt = "<|im_start|>system\n你是一个轻小说翻译模型,可以流畅通顺地以日本轻小说的风格将日文翻译成简体中文,并联系上下文正确使用人称代词,不擅自添加原文中没有的代词。<|im_end|>\n" \ # system prompt + "<|im_start|>user\n" + user_prompt + "<|im_end|>\n" \ # user prompt + "<|im_start|>assistant\n" # assistant prompt start # 如果术语表为空,也可以使用如下prompt(在术语表为空时更加推荐) user_prompt = "将下面的日文文本翻译成中文:" + japanese prompt = "<|im_start|>system\n你是一个轻小说翻译模型,可以流畅通顺地以日本轻小说的风格将日文翻译成简体中文,并联系上下文正确使用人称代词,不擅自添加原文中没有的代词。<|im_end|>\n" \ # system prompt + "<|im_start|>user\n" + user_prompt + "<|im_end|>\n" \ # user prompt + "<|im_start|>assistant\n" # assistant prompt start
-
v0.9 文本格式如下:
<|im_start|>system 你是一个轻小说翻译模型,可以流畅通顺地以日本轻小说的风格将日文翻译成简体中文,并联系上下文正确使用人称代词,不擅自添加原文中没有的代词。<|im_end|> <|im_start|>user 将下面的日文文本翻译成中文:日文第一行 日文第二行 日文第三行 ... 日文第n行<|im_end|> <|im_start|>assistant使用代码处理如下:
input_text_list = ['a', 'bb', 'ccc', ...] # 一系列上下文文本,每个元素代表一行的文本 raw_text = "\n".join(input_text_list) prompt = "<|im_start|>system\n你是一个轻小说翻译模型,可以流畅通顺地以日本轻小说的风格将日文翻译成简体中文,并联系上下文正确使用人称代词,不擅自添加原文中没有的代词。<|im_end|>\n" \ # system prompt + "<|im_start|>user\n将下面的日文文本翻译成中文:" + raw_text + "<|im_end|>\n" \ # user prompt + "<|im_start|>assistant\n" # assistant prompt start
-
-
prompt构建:
-
v0.8
input_text = "" # 要翻译的日文 query = "将下面的日文文本翻译成中文:" + input_text prompt = "<reserved_106>" + query + "<reserved_107>"
注意 0.8 虽然还可以使用,但是本仓库不再支持调用基于 transformer 的 0.8 版本模型。
-
v0.9
input_text = "" # 要翻译的日文 query = "将下面的日文文本翻译成中文:" + input_text prompt = "<|im_start|>system\n你是一个轻小说翻译模型,可以流畅通顺地以日本轻小说的风格将日文翻译成简体中文,并联系上下文正确使用人称代词,不擅自添加原文中没有的代词。<|im_end|>\n<|im_start|>user\n" + query + "<|im_end|>\n<|im_start|>assistant\n"
-
-
推理与解码参数:
| 参数 | 值 |
|---|---|
| temperature | 0.1 |
| top p | 0.3 |
| do sample | True |
| beams number | 1 |
| repetition penalty | 1 |
| max new token | 512 |
| min new token | 1 |
如出现退化(退化的例子可参见#35与#36),可增加frequency_penalty参数,并设置为大于0的某值,一般设置0.1~0.2即可。
模型微调框架参考BELLE或LLaMA-Factory,prompt构造参考推理部分。
| 参数量 | 发布时间-底模-版本 | 模型 |
|---|---|---|
| 32B | 20240508-Qwen1.5-32B-v0.9 | 🤗 Sakura-32B-Qwen2beta-v0.9-GGUF |
| 20240508-Qwen1.5-32B-v0.10pre1 | 🤗 Sakura-32B-Qwen2beta-v0.10pre1-GGUF | |
| 14B | 20240111-Qwen-14B-v0.9 | 🤗 Sakura-13B-LNovel-v0.9b-GGUF |
| 20240213-Qwen1.5-14B-v0.9 | 🤗 Sakura-14B-Qwen2beta-v0.9-GGUF | |
| 20240516-Qwen1.5-14B-v0.9.2 | 🤗 Sakura-14B-Qwen2beta-v0.9.2-GGUF | |
| 7B | 20240116-Qwen-7B-v0.9 | 🤗 Sakura-7B-LNovel-v0.9-GGUF |
| 20240531-Qwen1.5-7B-Galtransl-v2.6 | 🤗 Galtransl-v2.6 | |
| ~2B | 20240214-Qwen1.5-1.8B-v0.9.1 | 🤗 Sakura-1B8-Qwen2beta-v0.9.1-GGUF |
-
轻小说机翻机器人:轻小说翻译
-
LunaTranslator:Galgame在线翻译
-
GalTransl:Galgame离线翻译,制作补丁
-
AiNiee:RPG游戏翻译
v0.8版本模型的使用须遵守Apache 2.0、《Baichuan 2 模型社区许可协议》和CC BY-NC-SA 4.0协议。
v0.9版本模型的使用须遵守Qwen模型许可协议和CC BY-NC-SA 4.0协议。
v1.0版本模型的使用须遵守CC BY-NC-SA 4.0协议。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SakuraLLM
Similar Open Source Tools
SakuraLLM
SakuraLLM is a project focused on building large language models for Japanese to Chinese translation in the light novel and galgame domain. The models are based on open-source large models and are pre-trained and fine-tuned on general Japanese corpora and specific domains. The project aims to provide high-performance language models for galgame/light novel translation that are comparable to GPT3.5 and can be used offline. It also offers an API backend for running the models, compatible with the OpenAI API format. The project is experimental, with version 0.9 showing improvements in style, fluency, and accuracy over GPT-3.5.
kirara-ai
Kirara AI is a chatbot that supports mainstream large language models and chat platforms. It provides features such as image sending, keyword-triggered replies, multi-account support, personality settings, and support for various chat platforms like QQ, Telegram, Discord, and WeChat. The tool also supports HTTP server for Web API, popular large models like OpenAI and DeepSeek, plugin mechanism, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, custom workflows, web management interface, and built-in Frpc intranet penetration.
chatgpt-mirai-qq-bot
Kirara AI is a chatbot that supports mainstream language models and chat platforms. It features various functionalities such as image sending, keyword-triggered replies, multi-account support, content moderation, personality settings, and support for platforms like QQ, Telegram, Discord, and WeChat. It also offers HTTP server capabilities, plugin support, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, and custom workflows. The tool can be accessed via HTTP API for integration with other platforms.
app-builder
AppBuilder SDK is a one-stop development tool for AI native applications, providing basic cloud resources, AI capability engine, Qianfan large model, and related capability components to improve the development efficiency of AI native applications.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
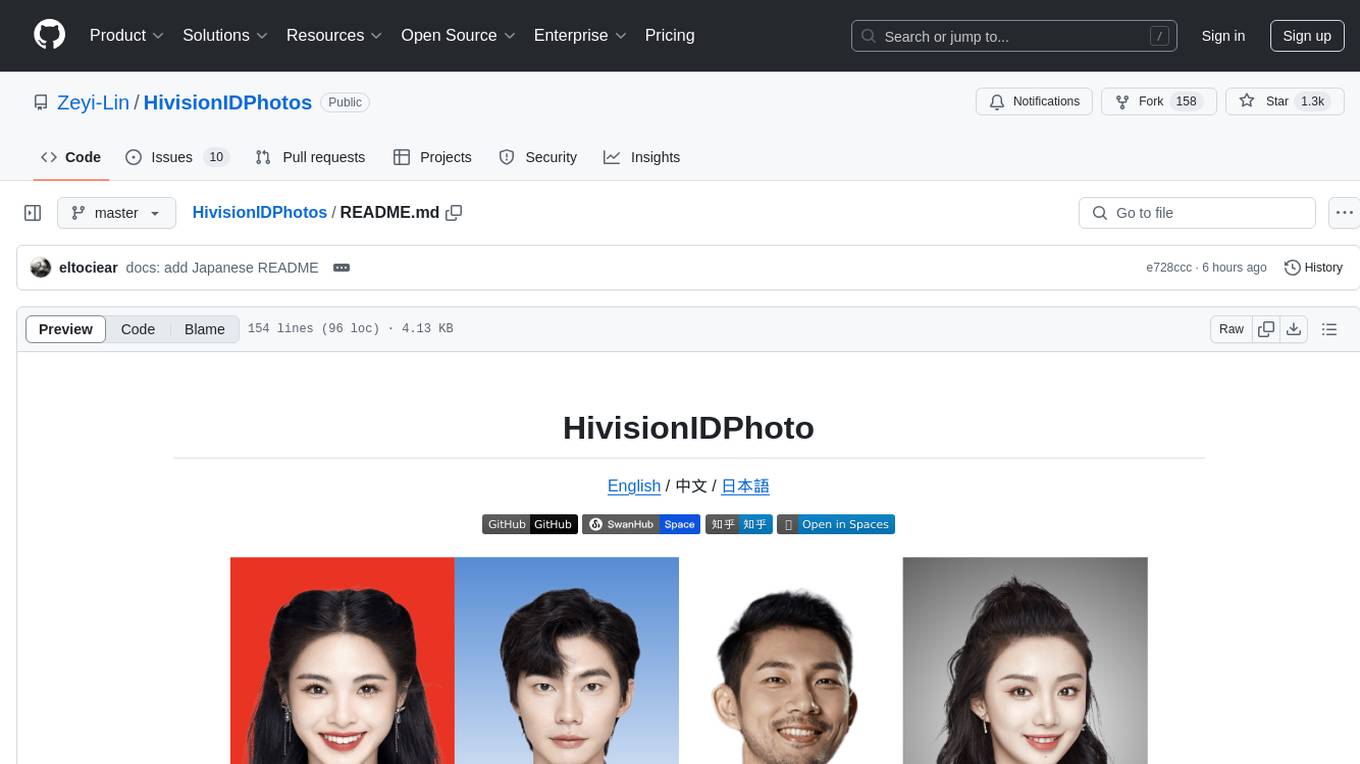
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.
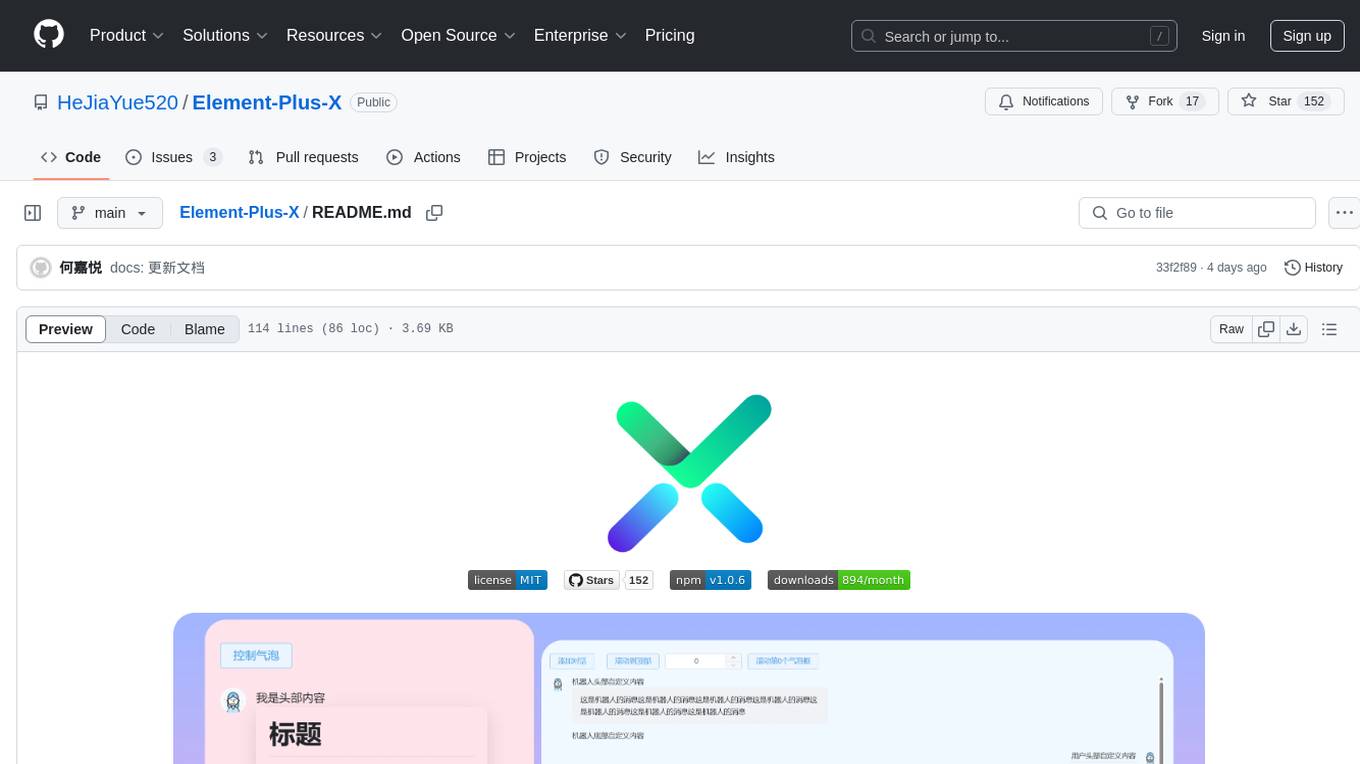
Element-Plus-X
Element-Plus-X is an out-of-the-box enterprise-level AI component library based on Vue 3 + Element-Plus. It features built-in scenario components such as chatbots and voice interactions, seamless integration with zero configuration based on Element-Plus design system, and support for on-demand loading with Tree Shaking optimization.

agentica
Agentica is a human-centric framework for building large language model agents. It provides functionalities for planning, memory management, tool usage, and supports features like reflection, planning and execution, RAG, multi-agent, multi-role, and workflow. The tool allows users to quickly code and orchestrate agents, customize prompts, and make API calls to various services. It supports API calls to OpenAI, Azure, Deepseek, Moonshot, Claude, Ollama, and Together. Agentica aims to simplify the process of building AI agents by providing a user-friendly interface and a range of functionalities for agent development.
Awesome-ChatTTS
Awesome-ChatTTS is an official recommended guide for ChatTTS beginners, compiling common questions and related resources. It provides a comprehensive overview of the project, including official introduction, quick experience options, popular branches, parameter explanations, voice seed details, installation guides, FAQs, and error troubleshooting. The repository also includes video tutorials, discussion community links, and project trends analysis. Users can explore various branches for different functionalities and enhancements related to ChatTTS.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
ChatGLM3
ChatGLM3 is a conversational pretrained model jointly released by Zhipu AI and THU's KEG Lab. ChatGLM3-6B is the open-sourced model in the ChatGLM3 series. It inherits the advantages of its predecessors, such as fluent conversation and low deployment threshold. In addition, ChatGLM3-6B introduces the following features: 1. A stronger foundation model: ChatGLM3-6B's foundation model ChatGLM3-6B-Base employs more diverse training data, more sufficient training steps, and more reasonable training strategies. Evaluation on datasets from different perspectives, such as semantics, mathematics, reasoning, code, and knowledge, shows that ChatGLM3-6B-Base has the strongest performance among foundation models below 10B parameters. 2. More complete functional support: ChatGLM3-6B adopts a newly designed prompt format, which supports not only normal multi-turn dialogue, but also complex scenarios such as tool invocation (Function Call), code execution (Code Interpreter), and Agent tasks. 3. A more comprehensive open-source sequence: In addition to the dialogue model ChatGLM3-6B, the foundation model ChatGLM3-6B-Base, the long-text dialogue model ChatGLM3-6B-32K, and ChatGLM3-6B-128K, which further enhances the long-text comprehension ability, are also open-sourced. All the above weights are completely open to academic research and are also allowed for free commercial use after filling out a questionnaire.
DeepAI
DeepAI is a proxy server that enhances the interaction experience of large language models (LLMs) by integrating the 'thinking chain' process. It acts as an intermediary layer, receiving standard OpenAI API compatible requests, using independent 'thinking services' to generate reasoning processes, and then forwarding the enhanced requests to the LLM backend of your choice. This ensures that responses are not only generated by the LLM but also based on pre-inference analysis, resulting in more insightful and coherent answers. DeepAI supports seamless integration with applications designed for the OpenAI API, providing endpoints for '/v1/chat/completions' and '/v1/models', making it easy to integrate into existing applications. It offers features such as reasoning chain enhancement, flexible backend support, API key routing, weighted random selection, proxy support, comprehensive logging, and graceful shutdown.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.

Native-LLM-for-Android
This repository provides a demonstration of running a native Large Language Model (LLM) on Android devices. It supports various models such as Qwen2.5-Instruct, MiniCPM-DPO/SFT, Yuan2.0, Gemma2-it, StableLM2-Chat/Zephyr, and Phi3.5-mini-instruct. The demo models are optimized for extreme execution speed after being converted from HuggingFace or ModelScope. Users can download the demo models from the provided drive link, place them in the assets folder, and follow specific instructions for decompression and model export. The repository also includes information on quantization methods and performance benchmarks for different models on various devices.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.
grps_trtllm
The grps-trtllm repository is a C++ implementation of a high-performance OpenAI LLM service, combining GRPS and TensorRT-LLM. It supports functionalities like Chat, Ai-agent, and Multi-modal. The repository offers advantages over triton-trtllm, including a complete LLM service implemented in pure C++, integrated tokenizer supporting huggingface and sentencepiece, custom HTTP functionality for OpenAI interface, support for different LLM prompt styles and result parsing styles, integration with tensorrt backend and opencv library for multi-modal LLM, and stable performance improvement compared to triton-trtllm.
For similar tasks
SakuraLLM
SakuraLLM is a project focused on building large language models for Japanese to Chinese translation in the light novel and galgame domain. The models are based on open-source large models and are pre-trained and fine-tuned on general Japanese corpora and specific domains. The project aims to provide high-performance language models for galgame/light novel translation that are comparable to GPT3.5 and can be used offline. It also offers an API backend for running the models, compatible with the OpenAI API format. The project is experimental, with version 0.9 showing improvements in style, fluency, and accuracy over GPT-3.5.
OpenVoiceChat
OpenVoiceChat is an open-source tool designed for having natural voice conversations with an LLM model. It supports various speech-to-text (STT), text-to-speech (TTS), and large language model (LLM) models. The tool aims to provide an alternative to closed commercial implementations, with well-abstracted APIs that are easy to use and extend. Users can install base and functionality-specific packages using pip, and the tool supports interruptions during conversations. The project encourages contributions through bounties and has a detailed roadmap available for reference.
glossAPI
The glossAPI project aims to develop a Greek language model as open-source software, with code licensed under EUPL and data under Creative Commons BY-SA. The project focuses on collecting and evaluating open text sources in Greek, with efforts to prioritize and gather textual data sets. The project encourages contributions through the CONTRIBUTING.md file and provides resources in the wiki for viewing and modifying recorded sources. It also welcomes ideas and corrections through issue submissions. The project emphasizes the importance of open standards, ethically secured data, privacy protection, and addressing digital divides in the context of artificial intelligence and advanced language technologies.

llama.cpp
llama.cpp is a C++ implementation of LLaMA, a large language model from Meta. It provides a command-line interface for inference and can be used for a variety of tasks, including text generation, translation, and question answering. llama.cpp is highly optimized for performance and can be run on a variety of hardware, including CPUs, GPUs, and TPUs.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.
manga-image-translator
Translate texts in manga/images. Some manga/images will never be translated, therefore this project is born. * Image/Manga Translator * Samples * Online Demo * Disclaimer * Installation * Pip/venv * Poetry * Additional instructions for **Windows** * Docker * Hosting the web server * Using as CLI * Setting Translation Secrets * Using with Nvidia GPU * Building locally * Usage * Batch mode (default) * Demo mode * Web Mode * Api Mode * Related Projects * Docs * Recommended Modules * Tips to improve translation quality * Options * Language Code Reference * Translators Reference * GPT Config Reference * Using Gimp for rendering * Api Documentation * Synchronous mode * Asynchronous mode * Manual translation * Next steps * Support Us * Thanks To All Our Contributors :

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.
MateCat
Matecat is an enterprise-level, web-based CAT tool designed to make post-editing and outsourcing easy and to provide a complete set of features to manage and monitor translation projects.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.