
ddddocr
ddddocr rust 版本,ocr_api_server rust 版本,二进制版本,验证码识别,不依赖 opencv 库,跨平台运行,a simple OCR API server, very easy to deploy。
Stars: 80
ddddocr is a Rust version of a simple OCR API server that provides easy deployment for captcha recognition without relying on the OpenCV library. It offers a user-friendly general-purpose captcha recognition Rust library. The tool supports recognizing various types of captchas, including single-line text, transparent black PNG images, target detection, and slider matching algorithms. Users can also import custom OCR training models and utilize the OCR API server for flexible OCR result control and range limitation. The tool is cross-platform and can be easily deployed.
README:
ddddocr rust 版本。
ocr_api_server rust 版本。
二进制版本,验证码识别,不依赖 opencv 库,跨平台运行。
a simple OCR API server, very easy to deploy。


一个容易使用的通用验证码识别 rust 库
·
报告Bug
·
提出新特性
| 系统 | CPU | GPU | 备注 |
|---|---|---|---|
| Windows 64位 | √ | ? | 部分版本 Windows 需要安装 vc 运行库 |
| Windows 32位 | √ | ? | 不支持静态链接,部分版本 Windows 需要安装 vc 运行库 |
| Linux 64 / ARM64 | √ | ? | 可能需要升级 glibc 版本, 升级 glibc 版本 |
| Linux 32 | × | ? | |
| Macos X64 | √ | ? | M1/M2/M3 ... 芯片参考 #67 |
lib.rs 实现了 ddddocr。
main.rs 实现了 ocr_api_server。
model 目录是模型与字符集。
依赖本库 ddddocr = {git = "https://github.com/86maid/ddddocr.git", branch = "master"}
开启 cuda 特性 ddddocr = { git = "https://github.com/86maid/ddddocr.git", branch = "master", features = ["cuda"] }
支持静态和动态链接,默认使用静态链接,构建时将会自动下载链接库,请设置好代理,cuda 特性不支持静态链接(会自己下载动态链接库)。
如有更多问题,请跳转至疑难杂症部分。
如果你不想从源代码构建,这里有编译好的二进制版本。
旧版本。
主要用于识别单行文字,即文字部分占据图片的主体部分,例如常见的英数验证码等,本项目可以对中文、英文(随机大小写or通过设置结果范围圈定大小写)、数字以及部分特殊字符。
let image = std::fs::read("target.png").unwrap();
let mut ocr = ddddocr::ddddocr_classification().unwrap();
let res = ocr.classification(image, false).unwrap();
println!("{:?}", res);let image = std::fs::read("target.png").unwrap();
let mut ocr = ddddocr::ddddocr_classification_old().unwrap();
let res = ocr.classification(image, false).unwrap();
println!("{:?}", res);classification(image, true);




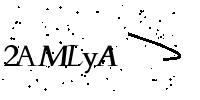






let image = std::fs::read("target.png").unwrap();
let mut det = ddddocr::ddddocr_detection().unwrap();
let res = det.detection(image).unwrap();
println!("{:?}", res);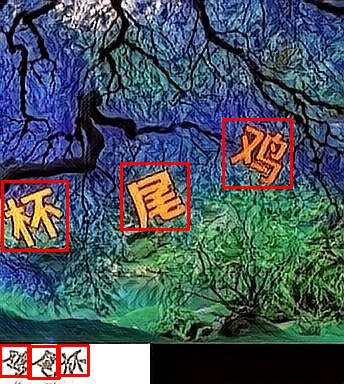

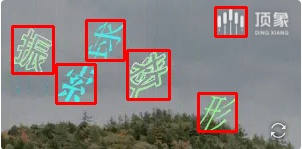


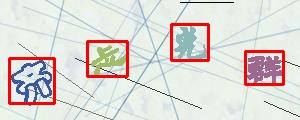

以上只是目前我能找到的点选验证码图片,做了一个简单的测试。
算法非深度神经网络实现。
小滑块为单独的png图片,背景是透明图,如下图:

然后背景为带小滑块坑位的,如下图:

let target_bytes = std::fs::read("target.png").unwrap();
let background_bytes = std::fs::read("background.png").unwrap();
let res = ddddocr::slide_match(target_bytes, background_bytes).unwrap();
println!("{:?}", res);如果小图无过多背景部分,则可以使用 simple_slide_match,通常为 jpg 或者 bmp 格式的图片
let target_bytes = std::fs::read("target.png").unwrap();
let background_bytes = std::fs::read("background.png").unwrap();
let res = ddddocr::simple_slide_match(target_bytes, background_bytes).unwrap();
println!("{:?}", res);一张图为带坑位的原图,如下图:

一张图为原图,如下图:

let target_bytes = std::fs::read("target.png").unwrap();
let background_bytes = std::fs::read("background.png").unwrap();
let res = ddddocr::slide_comparison(target_bytes, background_bytes).unwrap();
println!("{:?}", res);为了提供更灵活的 ocr 结果控制与范围限定,项目支持对ocr结果进行范围限定。
可以通过在调用 classification_probability 返回全字符表的概率。
当然也可以通过 set_ranges 设置输出字符范围来限定返回的结果。
| 参数值 | 意义 |
|---|---|
| 0 | 纯整数 0-9 |
| 1 | 纯小写字母 a-z |
| 2 | 纯大写字母 A-Z |
| 3 | 小写字母 a-z + 大写字母 A-Z |
| 4 | 小写字母 a-z + 整数 0-9 |
| 5 | 大写字母 A-Z + 整数 0-9 |
| 6 | 小写字母 a-z + 大写字母A-Z + 整数0-9 |
| 7 | 默认字符库 - 小写字母a-z - 大写字母A-Z - 整数0-9 |
如果值为 string 类型,请传入一段不包含空格的文本,其中的每个字符均为一个待选词,例如:"0123456789+-x/="
let image = std::fs::read("image.png").unwrap();
let mut ocr = ddddocr::ddddocr_classification().unwrap();
// 数字 3 对应枚举 CharsetRange::LowercaseUppercase,不用写枚举
// ocr.set_ranges(3);
// 自定义字符集
ocr.set_ranges("0123456789+-x/=");
let result = ocr.classification_probability(image, false).unwrap();
// 哦呀,看来数据有点儿太多了,小心卡死哦!
println!("概率: {}", result.json());
println!("识别结果: {}", result.get_text());支持导入 dddd_trainer 训练后的自定义模型。
use ddddocr::*;
let mut ocr = Ddddocr::with_model_charset(
"myproject_0.984375_139_13000_2022-02-26-15-34-13.onnx",
"charsets.json",
)
.unwrap();
let image_bytes = std::fs::read("888e28774f815b01e871d474e5c84ff2.jpg").unwrap();
let res = ocr.classification(&image_bytes).unwrap();
println!("{:?}", res);Usage: ddddocr.exe [OPTIONS]
Options:
-a, --address <ADDRESS>
监听地址 [default: 127.0.0.1]
-p, --port <PORT>
监听端口 [default: 9898]
-f, --full
开启所有选项
--jsonp
开启跨域,需要一个 query 指定回调函数的名字,不能使用 file (multipart) 传递参数, 例如 http://127.0.0.1:9898/ocr/b64/text?callback=handle&image=xxx
--ocr
开启内容识别,支持新旧模型共存
--old
开启旧版模型内容识别,支持新旧模型共存
--det
开启目标检测
--ocr-probability <OCR_PROBABILITY>
开启内容概率识别,支持新旧模型共存,只能使用官方模型, 如果参数是 0 到 7,对应内置的字符集, 如果参数为空字符串,表示默认字符集, 除此之外的参数,表示自定义字符集,例如 "0123456789+-x/="
--old-probability <OLD_PROBABILITY>
开启旧版模型内容概率识别,支持新旧模型共存,只能使用官方模型, 如果参数是 0 到 7,对应内置的字符集, 如果参数为空字符串,表示默认字符集, 除此之外的参数,表示自定义字符集,例如 "0123456789+-x/="
--ocr-path <OCR_PATH>
内容识别模型以及字符集路径, 通过哈希值判断是否为自定义模型, 使用自定义模型会使 old 选项失效, 路径 model/common 对应模型 model/common.onnx 和字符集 model/common.json [default: model/common]
--det-path <DET_PATH>
目标检测模型路径 [default: model/common_det.onnx]
--slide-match
开启滑块识别
--simple-slide-match
开启简单滑块识别
--slide-compare
开启坑位识别
-h, --help
Print help测试是否启动成功,可以通过直接 GET/POST 访问 http://{host}:{port}/ping 来测试,如果返回 pong 则启动成功。
http://{host}:{port}/{opt}/{img_type}/{ret_type}
opt:
ocr 内容识别
old 旧版模型内容识别
det 目标检测
ocr_probability 内容概率识别
old_probability 旧版模型内容概率识别
match 滑块匹配
simple_match 简单滑块匹配
compare 坑位匹配
img_type:
file 文件,即 multipart/form-data
b64 base64,即 {"a": encode(bytes), "b": encode(bytes)}
ret_type:
json json,成功 {"status": 200, "result": object},失败 {"status": 404, "msg": "失败原因"}
text 文本,失败返回空文本
import requests
import base64
host = "http://127.0.0.1:9898"
file = open('./image/3.png', 'rb').read()
# 测试 jsonp,只能使用 b64,不能使用 file
api_url = f"{host}/ocr/b64/text"
resp = requests.get(api_url, params = {
"callback": "handle",
"image": base64.b64encode(file).decode(),
})
print(f"jsonp, api_url={api_url}, resp.text={resp.text}")
# 测试 ocr
api_url = f"{host}/ocr/file/text"
resp = requests.post(api_url, files={'image': file})
print(f"api_url={api_url}, resp.text={resp.text}")cuda 和 cuDNN 都需要安装好。
CUDA 12 构建需要 cuDNN 9.x。
CUDA 11 构建需要 cuDNN 8.x。
不确定 cuda 10 是否有效。
默认使用静态链接,构建时将会自动下载链接库,请设置好代理,cuda 特性不支持静态链接(会自己下载动态链接库)。
如果要指定静态链接库的路径,可以设置环境变量 ORT_LIB_LOCATION,设置后将不会自动下载链接库。
例如,库路径为 onnxruntime\build\Windows\Release\Release\onnxruntime.lib,则 ORT_LIB_LOCATION 设置为 onnxruntime\build\Windows\Release。
默认开启 download-binaries 特性,自动下载链接库。
自动下载的链接库存放在 C:\Users\<用户名>\AppData\ort.pyke.io。
开启动态链接特性 ddddocr = { git = "https://github.com/86maid/ddddocr.git", branch = "master", features = ["load-dynamic"] }
开启 load-dynamic 特性后,可以使用 Ddddocr::set_onnxruntime_path 指定 onnxruntime 动态链接库的路径。
开启 load-dynamic 特性后,构建时将不会自动下载 onnxruntime 链接库。
请手动下载 onnxruntime 链接库,并将其放置在程序运行目录下(或系统 API 目录),这样无需再次调用 Ddddocr::set_onnxruntime_path。
windows 静态链接失败,请安装 vs2022。
linux x86-64 静态链接失败,请安装 gcc11 和 g++11,ubuntu ≥ 20.04。
linux arm64 静态链接失败,需要 glibc ≥ 2.35 (Ubuntu ≥ 22.04)。
macOS 静态链接失败,需要 macOS ≥ 10.15。
cuda 在执行 cargo test 的时候可能会 painc (exit code: 0xc000007b),这是因为自动生成的动态链接库是在 target/debug 目录下,需要手动复制到 target/debug/deps 目录下(cuda 目前不支持静态链接)。
动态链接需要 1.18.x 版本的 onnxruntime。
更多疑难杂症,请跳转至 ort.pyke.io。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ddddocr
Similar Open Source Tools
ddddocr
ddddocr is a Rust version of a simple OCR API server that provides easy deployment for captcha recognition without relying on the OpenCV library. It offers a user-friendly general-purpose captcha recognition Rust library. The tool supports recognizing various types of captchas, including single-line text, transparent black PNG images, target detection, and slider matching algorithms. Users can also import custom OCR training models and utilize the OCR API server for flexible OCR result control and range limitation. The tool is cross-platform and can be easily deployed.
Streamer-Sales
Streamer-Sales is a large model for live streamers that can explain products based on their characteristics and inspire users to make purchases. It is designed to enhance sales efficiency and user experience, whether for online live sales or offline store promotions. The model can deeply understand product features and create tailored explanations in vivid and precise language, sparking user's desire to purchase. It aims to revolutionize the shopping experience by providing detailed and unique product descriptions to engage users effectively.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.
grps_trtllm
The grps-trtllm repository is a C++ implementation of a high-performance OpenAI LLM service, combining GRPS and TensorRT-LLM. It supports functionalities like Chat, Ai-agent, and Multi-modal. The repository offers advantages over triton-trtllm, including a complete LLM service implemented in pure C++, integrated tokenizer supporting huggingface and sentencepiece, custom HTTP functionality for OpenAI interface, support for different LLM prompt styles and result parsing styles, integration with tensorrt backend and opencv library for multi-modal LLM, and stable performance improvement compared to triton-trtllm.
Senparc.AI
Senparc.AI is an AI extension package for the Senparc ecosystem, focusing on LLM (Large Language Models) interaction. It provides modules for standard interfaces and basic functionalities, as well as interfaces using SemanticKernel for plug-and-play capabilities. The package also includes a library for supporting the 'PromptRange' ecosystem, compatible with various systems and frameworks. Users can configure different AI platforms and models, define AI interface parameters, and run AI functions easily. The package offers examples and commands for dialogue, embedding, and DallE drawing operations.
AMchat
AMchat is a large language model that integrates advanced math concepts, exercises, and solutions. The model is based on the InternLM2-Math-7B model and is specifically designed to answer advanced math problems. It provides a comprehensive dataset that combines Math and advanced math exercises and solutions. Users can download the model from ModelScope or OpenXLab, deploy it locally or using Docker, and even retrain it using XTuner for fine-tuning. The tool also supports LMDeploy for quantization, OpenCompass for evaluation, and various other features for model deployment and evaluation. The project contributors have provided detailed documentation and guides for users to utilize the tool effectively.
dify-chat
Dify Chat Web is an AI conversation web app based on the Dify API, compatible with DeepSeek, Dify Chatflow/Workflow applications, and Agent Mind Chain output information. It supports multiple scenarios, flexible deployment without backend dependencies, efficient integration with reusable React components, and style customization for unique business system styles.
solon-ai
Solon-AI is a Java AI & MCP application development framework that supports various AI development capabilities. It is designed to be versatile, efficient, and open for integration with frameworks like SpringBoot, jFinal, and Vert.x. The framework provides examples of embedding solon-ai(& mcp) and showcases interfaces for chat models, function calling, vision, RAG (EmbeddingModel, Repository, DocumentLoader, RerankingModel), Ai Flow, MCP server, MCP client, and MCP Proxy. Solon-AI is part of the Solon project ecosystem, which includes other repositories for different functionalities.
huge-ai-search
Huge AI Search MCP Server integrates Google AI Mode search into clients like Cursor, Claude Code, and Codex, supporting continuous follow-up questions and source links. It allows AI clients to directly call 'huge-ai-search' for online searches, providing AI summary results and source links. The tool supports text and image searches, with the ability to ask follow-up questions in the same session. It requires Microsoft Edge for installation and supports various IDEs like VS Code. The tool can be used for tasks such as searching for specific information, asking detailed questions, and avoiding common pitfalls in development tasks.
CareGPT
CareGPT is a medical large language model (LLM) that explores medical data, training, and deployment related research work. It integrates resources, open-source models, rich data, and efficient deployment methods. It supports various medical tasks, including patient diagnosis, medical dialogue, and medical knowledge integration. The model has been fine-tuned on diverse medical datasets to enhance its performance in the healthcare domain.
Thor
Thor is a powerful AI model management tool designed for unified management and usage of various AI models. It offers features such as user, channel, and token management, data statistics preview, log viewing, system settings, external chat link integration, and Alipay account balance purchase. Thor supports multiple AI models including OpenAI, Kimi, Starfire, Claudia, Zhilu AI, Ollama, Tongyi Qianwen, AzureOpenAI, and Tencent Hybrid models. It also supports various databases like SqlServer, PostgreSql, Sqlite, and MySql, allowing users to choose the appropriate database based on their needs.
YesImBot
YesImBot, also known as Athena, is a Koishi plugin designed to allow large AI models to participate in group chat discussions. It offers easy customization of the bot's name, personality, emotions, and other messages. The plugin supports load balancing multiple API interfaces for large models, provides immersive context awareness, blocks potentially harmful messages, and automatically fetches high-quality prompts. Users can adjust various settings for the bot and customize system prompt words. The ultimate goal is to seamlessly integrate the bot into group chats without detection, with ongoing improvements and features like message recognition, emoji sending, multimodal image support, and more.
aigcpanel
AigcPanel is a simple and easy-to-use all-in-one AI digital human system that even beginners can use. It supports video synthesis, voice synthesis, voice cloning, simplifies local model management, and allows one-click import and use of AI models. It prohibits the use of this product for illegal activities and users must comply with the laws and regulations of the People's Republic of China.
MINI_LLM
This project is a personal implementation and reproduction of a small-parameter Chinese LLM. It mainly refers to these two open source projects: https://github.com/charent/Phi2-mini-Chinese and https://github.com/DLLXW/baby-llama2-chinese. It includes the complete process of pre-training, SFT instruction fine-tuning, DPO, and PPO (to be done). I hope to share it with everyone and hope that everyone can work together to improve it!
ChatGLM3
ChatGLM3 is a conversational pretrained model jointly released by Zhipu AI and THU's KEG Lab. ChatGLM3-6B is the open-sourced model in the ChatGLM3 series. It inherits the advantages of its predecessors, such as fluent conversation and low deployment threshold. In addition, ChatGLM3-6B introduces the following features: 1. A stronger foundation model: ChatGLM3-6B's foundation model ChatGLM3-6B-Base employs more diverse training data, more sufficient training steps, and more reasonable training strategies. Evaluation on datasets from different perspectives, such as semantics, mathematics, reasoning, code, and knowledge, shows that ChatGLM3-6B-Base has the strongest performance among foundation models below 10B parameters. 2. More complete functional support: ChatGLM3-6B adopts a newly designed prompt format, which supports not only normal multi-turn dialogue, but also complex scenarios such as tool invocation (Function Call), code execution (Code Interpreter), and Agent tasks. 3. A more comprehensive open-source sequence: In addition to the dialogue model ChatGLM3-6B, the foundation model ChatGLM3-6B-Base, the long-text dialogue model ChatGLM3-6B-32K, and ChatGLM3-6B-128K, which further enhances the long-text comprehension ability, are also open-sourced. All the above weights are completely open to academic research and are also allowed for free commercial use after filling out a questionnaire.
TechFlow
TechFlow is a platform that allows users to build their own AI workflows through drag-and-drop functionality. It features a visually appealing interface with clear layout and intuitive navigation. TechFlow supports multiple models beyond Language Models (LLM) and offers flexible integration capabilities. It provides a powerful SDK for developers to easily integrate generated workflows into existing systems, enhancing flexibility and scalability. The platform aims to embed AI capabilities as modules into existing functionalities to enhance business competitiveness.
For similar tasks
ddddocr
ddddocr is a Rust version of a simple OCR API server that provides easy deployment for captcha recognition without relying on the OpenCV library. It offers a user-friendly general-purpose captcha recognition Rust library. The tool supports recognizing various types of captchas, including single-line text, transparent black PNG images, target detection, and slider matching algorithms. Users can also import custom OCR training models and utilize the OCR API server for flexible OCR result control and range limitation. The tool is cross-platform and can be easily deployed.
ToolNeuron
ToolNeuron is a secure, offline AI ecosystem for Android devices that allows users to run private AI models and dynamic plugins fully offline, with hardware-grade encryption ensuring maximum privacy. It enables users to have an offline-first experience, add capabilities without app updates through pluggable tools, and ensures security by design with strict plugin validation and sandboxing.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.