
gollama
Go manage your Ollama models
Stars: 912
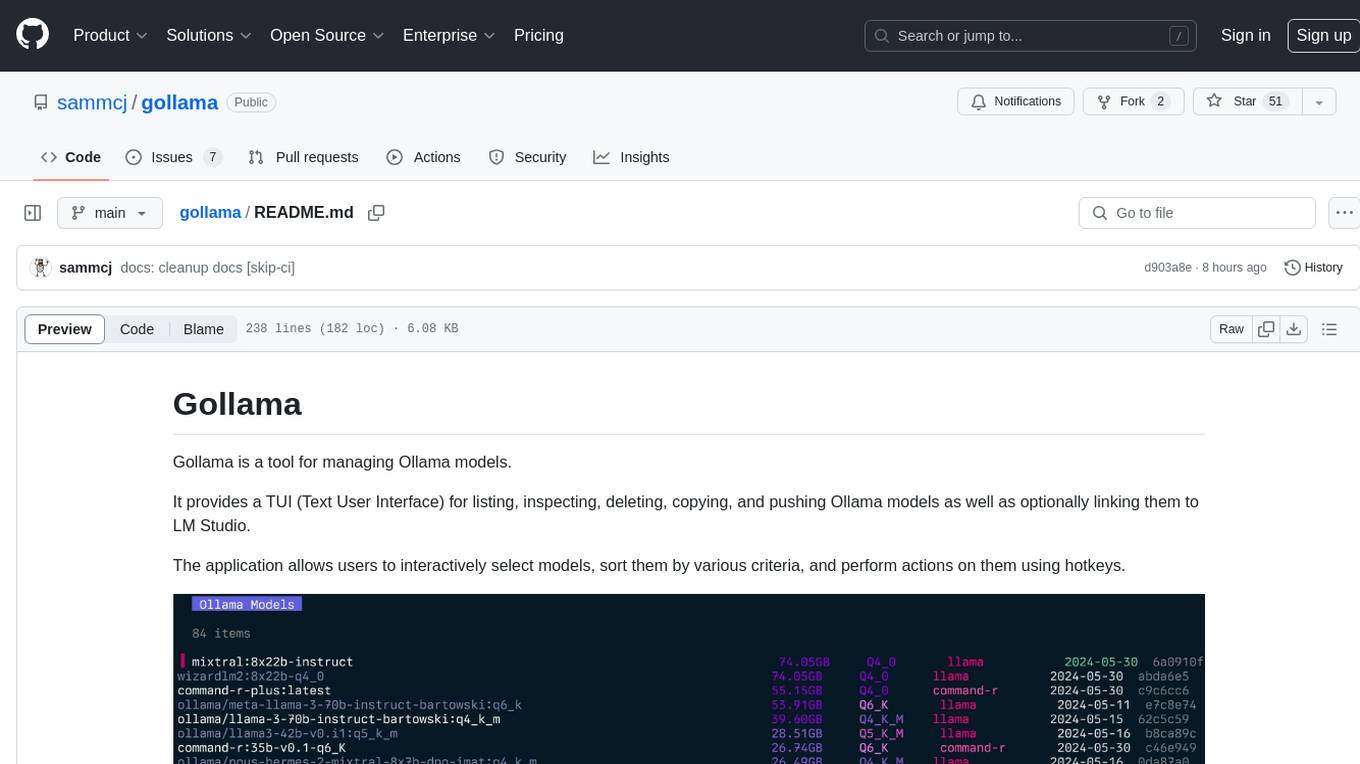
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.
README:
![]()
Gollama is a macOS / Linux tool for managing Ollama models.
It provides a TUI (Text User Interface) for listing, inspecting, deleting, copying, and pushing Ollama models as well as optionally linking them to LM Studio*.
The application allows users to interactively select models, sort, filter, edit, run, unload and perform actions on them using hotkeys.

The project started off as a rewrite of my llamalink project, but I decided to expand it to include more features and make it more user-friendly.
It's in active development, so there are some bugs and missing features, however I'm finding it useful for managing my models every day, especially for cleaning up old models.
- List available models
- Display metadata such as size, quantisation level, model family, and modified date
- Edit / update a model's Modelfile
- Sort models by name, size, modification date, quantisation level, family etc
- Select and delete models
- Run and unload models
- Inspect model for additional details
- Calculate approximate vRAM usage for a model
- Link models to LM Studio
- Copy / rename models
- Push models to a registry
- Show running models
- Has some cool bugs
See also - ingest for passing directories/repos of code to markdown formatted for LLMs.
Gollama Intro ("Podcast" Episode):
go install github.com/sammcj/gollama@HEADI don't recommend this method as it's not as easy to update, but you can use the following command:
curl -sL https://raw.githubusercontent.com/sammcj/gollama/refs/heads/main/scripts/install.sh | bashDownload the most recent release from the releases page and extract the binary to a directory in your PATH.
e.g. zip -d gollama*.zip -d gollama && mv gollama /usr/local/bin
If you see this error, add environment variables to .zshrc or .bashrc.
echo 'export PATH=$PATH:$HOME/go/bin' >> ~/.zshrc
source ~/.zshrcTo run the gollama application, use the following command:
gollamaTip: I like to alias gollama to g for quick access:
echo "alias g=gollama" >> ~/.zshrc-
Space: Select -
Enter: Run model (Ollama run) -
i: Inspect model -
t: Top (show running models) -
D: Delete model -
e: Edit model -
c: Copy model -
U: Unload all models -
p: Pull an existing model -
ctrl+k: Pull model & preserve user configuration -
ctrl+p: Pull (get) new model -
P: Push model -
n: Sort by name -
s: Sort by size -
m: Sort by modified -
k: Sort by quantisation -
f: Sort by family -
B: Sort by parameter size -
l: Link model to LM Studio -
L: Link all models to LM Studio -
r: Rename model (Work in progress) -
q: Quit
Top (t)

Inspect (i)

Link (l), Link All (L) and Link in the reverse direction: (link-lmstudio)
When linking models to LM Studio, Gollama creates a Modelfile with the template from LM-Studio and a set of default parameters that you can adjust.
Note: Linking requires admin privileges if you're running Windows.
-
-l: List all available Ollama models and exit -
-L: Link all available Ollama models to LM Studio and exit -
-link-lmstudio: Link all available LM Studio models to Ollama and exit -
--dry-run: Show what would be linked without making any changes (use with -link-lmstudio or -L) -
-s <search term>: Search for models by name- OR operator (
'term1|term2') returns models that match either term - AND operator (
'term1&term2') returns models that match both terms
- OR operator (
-
-e <model>: Edit the Modelfile for a model -
-ollama-dir: Custom Ollama models directory -
-lm-dir: Custom LM Studio models directory -
-cleanup: Remove all symlinked models and empty directories and exit -
-no-cleanup: Don't cleanup broken symlinks -
-u: Unload all running models -
-v: Print the version and exit -
-h, or--host: Specify the host for the Ollama API -
-H: Shortcut for-h http://localhost:11434(connect to local Ollama API) -
--vram: Estimate vRAM usage for a model. Accepts:- Ollama models (e.g.
llama3.1:8b-instruct-q6_K,qwen2:14b-q4_0) - HuggingFace models (e.g.
NousResearch/Hermes-2-Theta-Llama-3-8B) -
--fits: Available memory in GB for context calculation (e.g.6for 6GB) -
--vram-to-nthor--context: Maximum context length to analyze (e.g.32kor128k) -
--quant: Override quantisation level (e.g.Q4_0,Q5_K_M)
- Ollama models (e.g.
Gollama can also be called with -l to list models without the TUI.
gollama -lList (gollama -l):

Gollama can be called with -e to edit the Modelfile for a model.
gollama -e my-modelGollama can be called with -s to search for models by name.
gollama -s my-model # returns models that contain 'my-model'
gollama -s 'my-model|my-other-model' # returns models that contain either 'my-model' or 'my-other-model'
gollama -s 'my-model&instruct' # returns models that contain both 'my-model' and 'instruct'Gollama includes a comprehensive vRAM estimation feature:
- Calculate vRAM usage for a pulled Ollama model (e.g.
my-model:mytag), or huggingface model ID (e.g.author/name) - Determine maximum context length for a given vRAM constraint
- Find the best quantisation setting for a given vRAM and context constraint
- Shows estimates for different k/v cache quantisation options (fp16, q8_0, q4_0)
- Automatic detection of available CUDA vRAM (coming soon!) or system RAM

To estimate (v)RAM usage:
gollama --vram llama3.1:8b-instruct-q6_K
📊 VRAM Estimation for Model: llama3.1:8b-instruct-q6_K
| QUANT | CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| ------- | ---- | --- | --- | --------------- | --------------- | --------------- | --------------- |
| IQ1_S | 1.56 | 2.2 | 2.8 | 3.7(3.7,3.7) | 5.5(5.5,5.5) | 7.3(7.3,7.3) | 9.1(9.1,9.1) |
| IQ2_XXS | 2.06 | 2.6 | 3.3 | 4.3(4.3,4.3) | 6.1(6.1,6.1) | 7.9(7.9,7.9) | 9.8(9.8,9.8) |
| IQ2_XS | 2.31 | 2.9 | 3.6 | 4.5(4.5,4.5) | 6.4(6.4,6.4) | 8.2(8.2,8.2) | 10.1(10.1,10.1) |
| IQ2_S | 2.50 | 3.1 | 3.8 | 4.7(4.7,4.7) | 6.6(6.6,6.6) | 8.5(8.5,8.5) | 10.4(10.4,10.4) |
| IQ2_M | 2.70 | 3.2 | 4.0 | 4.9(4.9,4.9) | 6.8(6.8,6.8) | 8.7(8.7,8.7) | 10.6(10.6,10.6) |
| IQ3_XXS | 3.06 | 3.6 | 4.3 | 5.3(5.3,5.3) | 7.2(7.2,7.2) | 9.2(9.2,9.2) | 11.1(11.1,11.1) |
| IQ3_XS | 3.30 | 3.8 | 4.5 | 5.5(5.5,5.5) | 7.5(7.5,7.5) | 9.5(9.5,9.5) | 11.4(11.4,11.4) |
| Q2_K | 3.35 | 3.9 | 4.6 | 5.6(5.6,5.6) | 7.6(7.6,7.6) | 9.5(9.5,9.5) | 11.5(11.5,11.5) |
| Q3_K_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_M | 3.70 | 4.2 | 5.0 | 6.0(6.0,6.0) | 8.0(8.0,8.0) | 9.9(9.9,9.9) | 12.0(12.0,12.0) |
| Q3_K_M | 3.91 | 4.4 | 5.2 | 6.2(6.2,6.2) | 8.2(8.2,8.2) | 10.2(10.2,10.2) | 12.2(12.2,12.2) |
| IQ4_XS | 4.25 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.6(10.6,10.6) | 12.7(12.7,12.7) |
| Q3_K_L | 4.27 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.7(10.7,10.7) | 12.7(12.7,12.7) |
| IQ4_NL | 4.50 | 5.0 | 5.7 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 10.9(10.9,10.9) | 13.0(13.0,13.0) |
| Q4_0 | 4.55 | 5.0 | 5.8 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_S | 4.58 | 5.0 | 5.8 | 6.9(6.9,6.9) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_M | 4.85 | 5.3 | 6.1 | 7.1(7.1,7.1) | 9.2(9.2,9.2) | 11.4(11.4,11.4) | 13.5(13.5,13.5) |
| Q4_K_L | 4.90 | 5.3 | 6.1 | 7.2(7.2,7.2) | 9.3(9.3,9.3) | 11.4(11.4,11.4) | 13.6(13.6,13.6) |
| Q5_K_S | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_0 | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_K_M | 5.69 | 6.1 | 6.9 | 8.0(8.0,8.0) | 10.2(10.2,10.2) | 12.4(12.4,12.4) | 14.6(14.6,14.6) |
| Q5_K_L | 5.75 | 6.1 | 7.0 | 8.1(8.1,8.1) | 10.3(10.3,10.3) | 12.5(12.5,12.5) | 14.7(14.7,14.7) |
| Q6_K | 6.59 | 7.0 | 8.0 | 9.4(9.4,9.4) | 12.2(12.2,12.2) | 15.0(15.0,15.0) | 17.8(17.8,17.8) |
| Q8_0 | 8.50 | 8.8 | 9.9 | 11.4(11.4,11.4) | 14.4(14.4,14.4) | 17.4(17.4,17.4) | 20.3(20.3,20.3) |To find the best quantisation type for a given memory constraint (e.g. 6GB) you can provide --fits <number of GB>:
gollama --vram NousResearch/Hermes-2-Theta-Llama-3-8B --fits 6
📊 VRAM Estimation for Model: NousResearch/Hermes-2-Theta-Llama-3-8B
| QUANT/CTX | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| --------- | ---- | --- | --- | ------------ | ------------- | -------------- | --------------- |
| IQ1_S | 1.56 | 2.4 | 3.8 | 5.7(4.7,4.2) | 9.5(7.5,6.5) | 13.3(10.3,8.8) | 17.1(13.1,11.1) |
| IQ2_XXS | 2.06 | 2.9 | 4.3 | 6.3(5.3,4.8) | 10.1(8.1,7.1) | 13.9(10.9,9.4) | 17.8(13.8,11.8) |
...This will display a table showing vRAM usage for various quantisation types and context sizes.
The vRAM estimator works by:
- Fetching the model configuration from Hugging Face (if not cached locally)
- Calculating the memory requirements for model parameters, activations, and KV cache
- Adjusting calculations based on the specified quantisation settings
- Performing binary and linear searches to optimize for context length or quantisation settings
Note: The estimator will attempt to use CUDA vRAM if available, otherwise it will fall back to system RAM for calculations.
Gollama uses a JSON configuration file located at ~/.config/gollama/config.json. The configuration file includes options for sorting, columns, API keys, log levels, theme etc...
Example configuration:
{
"default_sort": "modified",
"columns": [
"Name",
"Size",
"Quant",
"Family",
"Modified",
"ID"
],
"ollama_api_key": "",
"ollama_api_url": "http://localhost:11434",
"lm_studio_file_paths": "",
"log_level": "info",
"log_file_path": "/Users/username/.config/gollama/gollama.log",
"sort_order": "Size",
"strip_string": "my-private-registry.internal/",
"editor": "",
"docker_container": ""
}-
strip_stringcan be used to remove a prefix from model names as they are displayed in the TUI. This can be useful if you have a common prefix such as a private registry that you want to remove for display purposes. -
docker_container- experimental - if set, gollama will attempt to perform any run operations inside the specified container. -
editor- experimental - if set, gollama will use this editor to open the Modelfile for editing. -
theme- experimental The name of the theme to use (without .json extension)
-
Clone the repository:
git clone https://github.com/sammcj/gollama.git cd gollama -
Build:
go get make build
-
Run:
./gollama
Gollama has basic customisable theme support, themes are stored as JSON files in ~/.config/gollama/themes/.
The active theme can be set via the theme setting in your config file (without the .json extension).
Default themes will be created if they don't exist:
-
default- Dark theme with neon accents (default) -
light-neon- Light theme with neon accents, suitable for light terminal backgrounds
To create a custom theme:
- Create a new JSON file in the themes directory (e.g.
~/.config/gollama/themes/my-theme.json) - Use the following structure:
{
"name": "my-theme",
"description": "My custom theme",
"colours": {
"header_foreground": "#AA1493",
"header_border": "#BA1B11",
"selected": "#FFFFFF",
...
},
"family": {
"llama": "#FF1493",
"alpaca": "#FF00FF",
...
}
}Colours can be specified as ANSI colour codes (e.g. "241") or hex values (e.g. "#FF00FF"). The family section defines colours for different model families in the list view.
Note: Using the VSCode extension 'Color Highlight' makes it easier to find the hex values for colours.
Logs can be found in the gollama.log which is stored in $HOME/.config/gollama/gollama.log by default.
The log level can be set in the configuration file.
Contributions are welcome! Please fork the repository and create a pull request with your changes.

Sam |

Cameron Kingsbury |

KimCookieYa |

Denis Balan |

Doug Coleman |

Jose Almaraz |

Jose Roberto Almaraz |

Oleksii Filonenko |

SouthWolf |

anrgct |

ondrej |
Thank you to folks such as Matt Williams, Fahd Mirza and AI Code King for giving this a shot and providing feedback.



Copyright © 2024 Sam McLeod
This project is licensed under the MIT License. See the LICENSE file for details.
<script src="http://api.html5media.info/1.1.8/html5media.min.js"></script>For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for gollama
Similar Open Source Tools
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.
api-for-open-llm
This project provides a unified backend interface for open large language models (LLMs), offering a consistent experience with OpenAI's ChatGPT API. It supports various open-source LLMs, enabling developers to seamlessly integrate them into their applications. The interface features streaming responses, text embedding capabilities, and support for LangChain, a tool for developing LLM-based applications. By modifying environment variables, developers can easily use open-source models as alternatives to ChatGPT, providing a cost-effective and customizable solution for various use cases.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.
AnyCrawl
AnyCrawl is a high-performance crawling and scraping toolkit designed for SERP crawling, web scraping, site crawling, and batch tasks. It offers multi-threading and multi-process capabilities for high performance. The tool also provides AI extraction for structured data extraction from pages, making it LLM-friendly and easy to integrate and use.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
Backlog.md
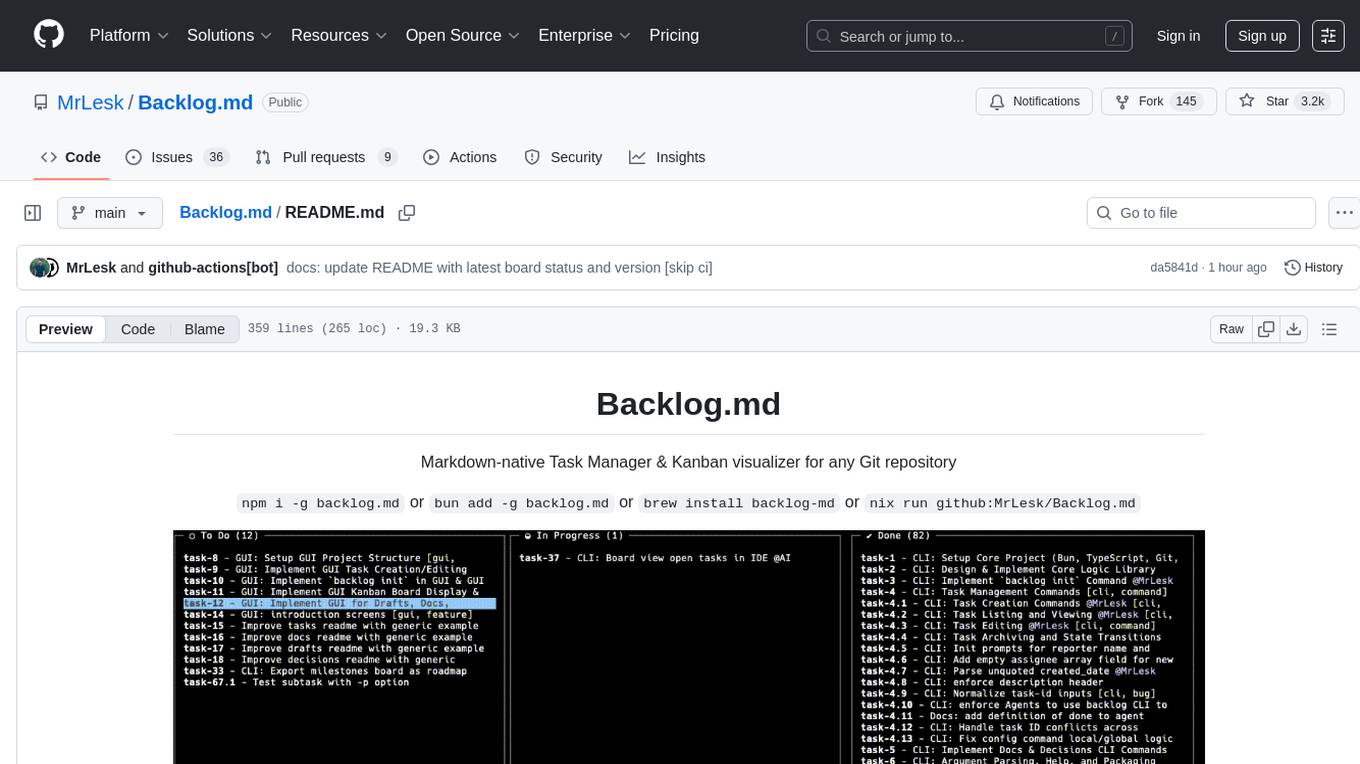
Backlog.md is a Markdown-native Task Manager & Kanban visualizer for any Git repository. It turns any folder with a Git repo into a self-contained project board powered by plain Markdown files and a zero-config CLI. Features include managing tasks as plain .md files, private & offline usage, instant terminal Kanban visualization, board export, modern web interface, AI-ready CLI, rich query commands, cross-platform support, and MIT-licensed open-source. Users can create tasks, view board, assign tasks to AI, manage documentation, make decisions, and configure settings easily.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.
DownEdit
DownEdit is a fast and powerful program for downloading and editing videos from top platforms like TikTok, Douyin, and Kuaishou. Effortlessly grab videos from user profiles, make bulk edits throughout the entire directory with just one click. Advanced Chat & AI features let you download, edit, and generate videos, images, and sounds in bulk. Exciting new features are coming soon—stay tuned!
DownEdit
DownEdit is a fast and powerful program for downloading and editing videos from platforms like TikTok, Douyin, and Kuaishou. It allows users to effortlessly grab videos, make bulk edits, and utilize advanced AI features for generating videos, images, and sounds in bulk. The tool offers features like video, photo, and sound editing, downloading videos without watermarks, bulk AI generation, and AI editing for content enhancement.
slidev-mcp
slidev-mcp is an intelligent slide generation tool based on Slidev that integrates large language model technology, allowing users to automatically generate professional online PPT presentations with simple descriptions. It dramatically lowers the barrier to using Slidev, provides natural language interactive slide creation, and offers automated generation of professional presentations. The tool also includes various features for environment and project management, slide content management, and utility tools to enhance the slide creation process.
terminator
Terminator is an AI-powered desktop automation tool that is open source, MIT-licensed, and cross-platform. It works across all apps and browsers, inspired by GitHub Actions & Playwright. It is 100x faster than generic AI agents, with over 95% success rate and no vendor lock-in. Users can create automations that work across any desktop app or browser, achieve high success rates without costly consultant armies, and pre-train workflows as deterministic code.
DownEdit
DownEdit is a powerful program that allows you to download videos from various social media platforms such as TikTok, Douyin, Kuaishou, and more. With DownEdit, you can easily download videos from user profiles and edit them in bulk. You have the option to flip the videos horizontally or vertically throughout the entire directory with just a single click. Stay tuned for more exciting features coming soon!

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.
chatglm.cpp
ChatGLM.cpp is a C++ implementation of ChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B and more LLMs for real-time chatting on your MacBook. It is based on ggml, working in the same way as llama.cpp. ChatGLM.cpp features accelerated memory-efficient CPU inference with int4/int8 quantization, optimized KV cache and parallel computing. It also supports P-Tuning v2 and LoRA finetuned models, streaming generation with typewriter effect, Python binding, web demo, api servers and more possibilities.
PureChat
PureChat is a chat application integrated with ChatGPT, featuring efficient application building with Vite5, screenshot generation and copy support for chat records, IM instant messaging SDK for sessions, automatic light and dark mode switching based on system theme, Markdown rendering, code highlighting, and link recognition support, seamless social experience with GitHub quick login, integration of large language models like ChatGPT Ollama for streaming output, preset prompts, and context, Electron desktop app versions for macOS and Windows, ongoing development of more features. Environment setup requires Node.js 18.20+. Clone code with 'git clone https://github.com/Hyk260/PureChat.git', install dependencies with 'pnpm install', start project with 'pnpm dev', and build with 'pnpm build'.
airswap-protocols
AirSwap Protocols is a repository containing smart contracts for developers and traders on the AirSwap peer-to-peer trading network. It includes various packages for functionalities like server registry, atomic token swap, staking, rewards pool, batch token and order calls, libraries, and utils. The repository follows a branching and release process for contracts and tools, with steps for regular development process and individual package features or patches. Users can deploy and verify contracts using specific commands with network flags.
For similar tasks
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.

kitops
KitOps is a packaging and versioning system for AI/ML projects that uses open standards so it works with the AI/ML, development, and DevOps tools you are already using. KitOps simplifies the handoffs between data scientists, application developers, and SREs working with LLMs and other AI/ML models. KitOps' ModelKits are a standards-based package for models, their dependencies, configurations, and codebases. ModelKits are portable, reproducible, and work with the tools you already use.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.
AI-Horde
The AI Horde is an enterprise-level ML-Ops crowdsourced distributed inference cluster for AI Models. This middleware can support both Image and Text generation. It is infinitely scalable and supports seamless drop-in/drop-out of compute resources. The Public version allows people without a powerful GPU to use Stable Diffusion or Large Language Models like Pygmalion/Llama by relying on spare/idle resources provided by the community and also allows non-python clients, such as games and apps, to use AI-provided generations.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.
vertex-ai-mlops
Vertex AI is a platform for end-to-end model development. It consist of core components that make the processes of MLOps possible for design patterns of all types.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.