Best AI tools for< Image Classifier >
Infographic
20 - AI tool Sites
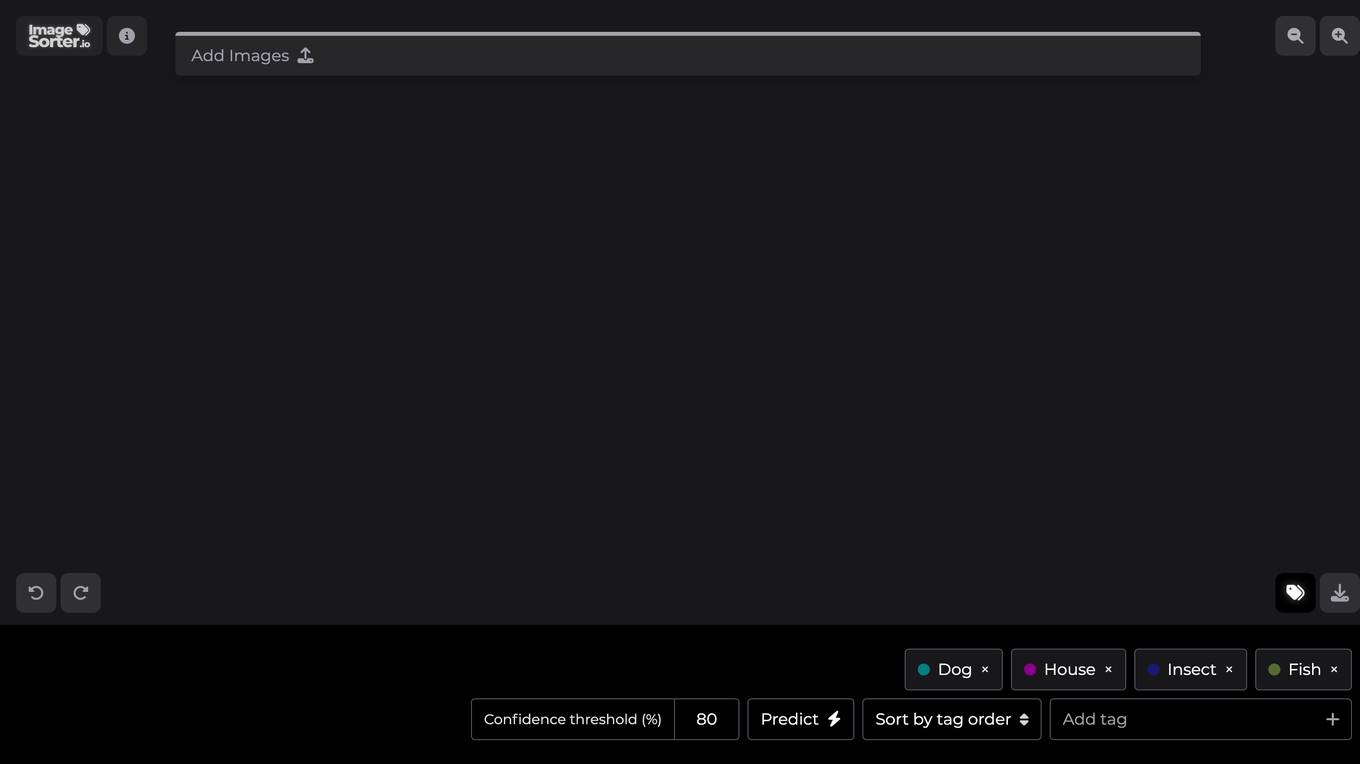
ImageSorter.io
ImageSorter.io is a free tool designed to help users sort and organize their images efficiently. Users can easily add images and use drag-and-drop functionality to rearrange them. The tool also offers a Pro version with additional features such as setting confidence thresholds and predicting image sorting based on tags. ImageSorter.io simplifies the image organization process, making it convenient for users to manage their image collections effectively.
Ximilar Visual AI for Business
Ximilar Visual AI for Business is an AI tool that offers a comprehensive platform for image recognition and visual search solutions. It provides features such as image classification, regression, object detection, AI model combination, image annotation, and more. Users can easily build custom machine learning models without coding, access ready-to-use visual AI demos, and benefit from features like image upscaling, background removal, and color extraction. The platform caters to various industries including fashion, home decor, stock photos, collectibles, med & biotech, manufacturing, and real estate.
SentiSight.ai
SentiSight.ai is a machine learning platform for image recognition solutions, offering services such as object detection, image segmentation, image classification, image similarity search, image annotation, computer vision consulting, and intelligent automation consulting. Users can access pre-trained models, background removal, NSFW detection, text recognition, and image recognition API. The platform provides tools for image labeling, project management, and training tutorials for various image recognition models. SentiSight.ai aims to streamline the image annotation process, empower users to build and train their own models, and deploy them for online or offline use.
Roboflow
Roboflow is a platform that provides tools for building and deploying computer vision models. It offers a range of features, including data annotation, model training, and deployment. Roboflow is used by over 250,000 engineers to create datasets, train models, and deploy to production.
Meta AI
Meta AI is a research lab dedicated to advancing the field of artificial intelligence. Our mission is to build foundational AI technologies that will solve some of the world's biggest challenges, such as climate change, disease, and poverty.
Landing AI
Landing AI is a computer vision platform and AI software company that provides a cloud-based platform for building and deploying computer vision applications. The platform includes a library of pre-trained models, a set of tools for data labeling and model training, and a deployment service that allows users to deploy their models to the cloud or edge devices. Landing AI's platform is used by a variety of industries, including automotive, electronics, food and beverage, medical devices, life sciences, agriculture, manufacturing, infrastructure, and pharma.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing. The company's products and services are used by businesses and governments around the world to develop and deploy AI applications. NVIDIA's AI platform includes hardware, software, and tools that make it easy to build and train AI models. The company also offers a range of cloud-based AI services that make it easy to deploy and manage AI applications. NVIDIA's AI platform is used in a wide variety of industries, including healthcare, manufacturing, retail, and transportation. The company's AI technology is helping to improve the efficiency and accuracy of a wide range of tasks, from medical diagnosis to product design.

TensorFlow
TensorFlow is an end-to-end platform for machine learning. It provides a wide range of tools and resources to help developers build, train, and deploy ML models. TensorFlow is used by researchers and developers all over the world to solve real-world problems in a variety of domains, including computer vision, natural language processing, and robotics.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.

Keras
Keras is an open-source deep learning API written in Python, designed to make building and training deep learning models easier. It provides a user-friendly interface and a wide range of features and tools to help developers create and deploy machine learning applications. Keras is compatible with multiple frameworks, including TensorFlow, Theano, and CNTK, and can be used for a variety of tasks, including image classification, natural language processing, and time series analysis.
fast.ai
fast.ai is a non-profit organization that provides free online courses and resources on deep learning and artificial intelligence. The organization was founded in 2016 by Jeremy Howard and Rachel Thomas, and has since grown to a community of over 100,000 learners from all over the world. fast.ai's mission is to make deep learning accessible to everyone, regardless of their background or experience. The organization's courses are taught by leading experts in the field, and are designed to be practical and hands-on. fast.ai also offers a variety of resources to help learners get started with deep learning, including a forum, a wiki, and a blog.
Gradio
Gradio is a tool that allows users to quickly and easily create web-based interfaces for their machine learning models. With Gradio, users can share their models with others, allowing them to interact with and use the models remotely. Gradio is easy to use and can be integrated with any Python library. It can be used to create a variety of different types of interfaces, including those for image classification, natural language processing, and time series analysis.
Amazon Science
Amazon Science is a research and development organization within Amazon that focuses on developing new technologies and products in the fields of artificial intelligence, machine learning, and computer science. The organization is home to a team of world-renowned scientists and engineers who are working on a wide range of projects, including developing new algorithms for machine learning, building new computer vision systems, and creating new natural language processing tools. Amazon Science is also responsible for developing new products and services that use these technologies, such as the Amazon Echo and the Amazon Fire TV.

Teachable Machine
Teachable Machine is a web-based tool that makes it easy to create custom machine learning models, even if you don't have any coding experience. With Teachable Machine, you can train models to recognize images, sounds, and poses. Once you've trained a model, you can export it to use in your own projects.

Deep Learning
The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. The online version of the book is now complete and will remain available online for free. The deep learning textbook can now be ordered on Amazon. For up to date announcements, join our mailing list.
RunwayML Experiments
RunwayML Experiments is a platform that allows users to create and share machine learning models. It provides a variety of tools and resources to help users get started with machine learning, including a library of pre-trained models, a visual programming interface, and a community of experts. RunwayML Experiments is used by a variety of people, including researchers, students, and hobbyists.
CVAT
CVAT is an open-source data annotation platform that helps teams of any size annotate data for machine learning. It is used by companies big and small in a variety of industries, including healthcare, retail, and automotive. CVAT is known for its intuitive user interface, advanced features, and support for a wide range of data formats. It is also highly extensible, allowing users to add their own custom features and integrations.

Garden of AI
Garden of AI is a comprehensive AI-powered platform that provides a wide range of tools and resources to help users explore, learn, and apply AI in their daily lives and work. With a vast collection of AI models, tutorials, datasets, and community forums, Garden of AI empowers users to stay up-to-date with the latest AI advancements and leverage its capabilities to solve real-world problems.

CVF Open Access
The Computer Vision Foundation (CVF) is a non-profit organization dedicated to advancing the field of computer vision. CVF organizes several conferences and workshops each year, including the International Conference on Computer Vision (ICCV), the Conference on Computer Vision and Pattern Recognition (CVPR), and the Winter Conference on Applications of Computer Vision (WACV). CVF also publishes the International Journal of Computer Vision (IJCV) and the Computer Vision and Image Understanding (CVIU) journal. The CVF Open Access website provides access to the full text of all CVF-sponsored conference papers. These papers are available for free download in PDF format. The CVF Open Access website also includes links to the arXiv versions of the papers, where available.

Viso Suite
Viso Suite is a no-code computer vision platform that enables users to build, deploy, and scale computer vision applications. It provides a comprehensive set of tools for data collection, annotation, model training, application development, and deployment. Viso Suite is trusted by leading Fortune Global companies and has been used to develop a wide range of computer vision applications, including object detection, image classification, facial recognition, and anomaly detection.
1 - Open Source Tools

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
20 - OpenAI Gpts
Deep Learning Master
Guiding you through the depths of deep learning with accuracy and respect.
Pixie: Computer Vision Engineer
Expert in computer vision, deep learning, ready to assist you with 3d and geometric computer vision. https://github.com/kornia/pixie

Identify movies, dramas, and animations by image
Just send us an image of a scene from a video work and i will guess the name of the work!

Image Generation with Selfcritique & Improvement
More accurate and easier image generation with self critique & improvement! Try it now
Easy Image Maker
Question-and-answer style image design agent, solving the problem of not knowing how to describe design parameters to GPT.
The Ultimate Image Generator
Highly optimized prompts and top secret refinements to create the perfect image every time...
Reliable Image Generator with LGTM Overlay
Efficiently generates images and overlays 'LGTM'
Image Scout
A comprehensive guide for finding themed public domain images with a vast resource list.
Consistent Image Generator
Geneate an image ➡ Request modifications. This GPT supports generating consistent and continuous images with Dalle. It also offers the ability to restore or integrate photos you upload. ✔️Where to use: Wordpress Blog Post, Youtube thumbnail, AI profile, facebook, X, threads feed, Instagram reels
Image Translator(→日本語)
画像中の文章を日本語に翻訳します。(使い方:画像をアップロードするだけ。プロンプトの文章は不要です。) 2023/12/29 より自然な日本語になるように修正