Best AI tools for< Object Detector >
Infographic
20 - AI tool Sites
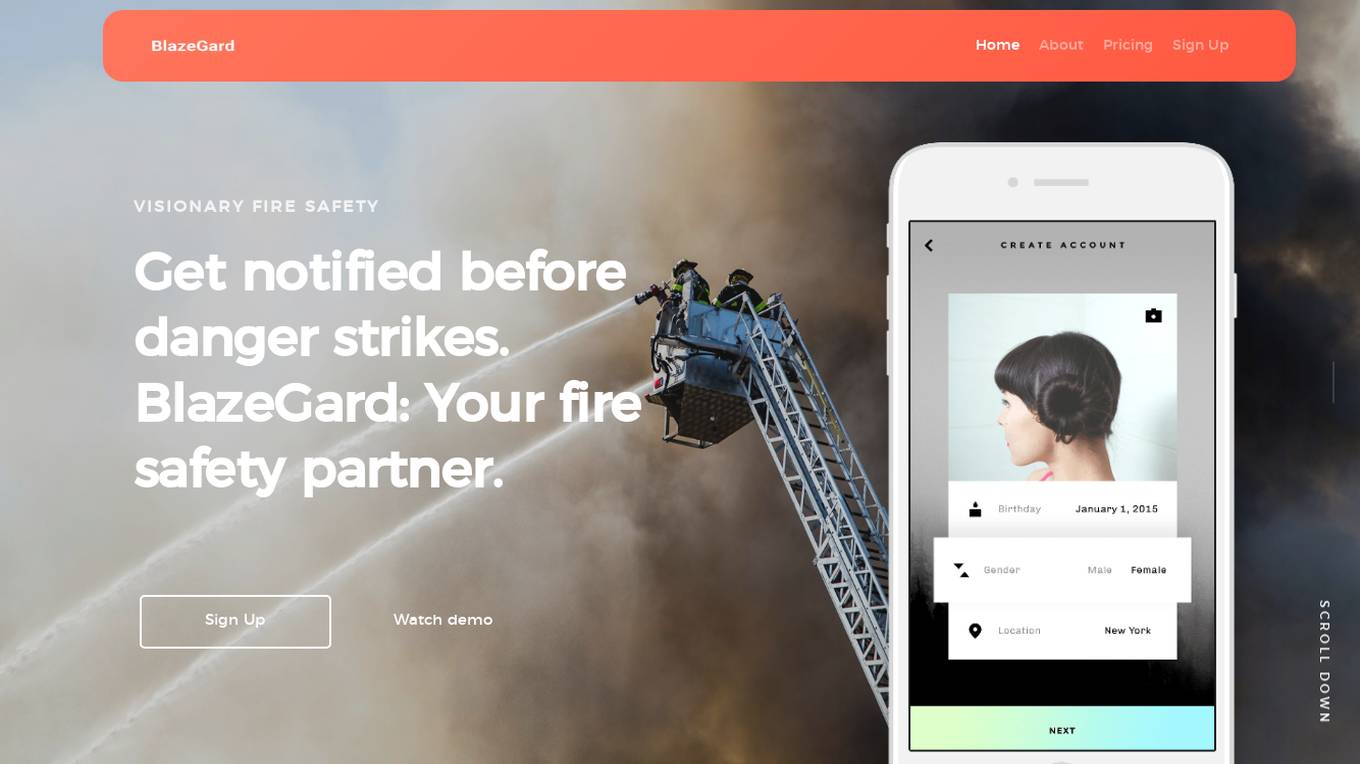
BlazeGard
BlazeGard is an AI-powered fire safety application that utilizes cutting-edge object detection technology to analyze video feeds in real-time, identifying potential fire hazards and smoke before flames erupt. It offers comprehensive protection for homes, businesses, and industrial facilities, going beyond traditional smoke detectors. BlazeGard provides early detection, real-time alerts, and peace of mind through its proactive approach to fire safety.
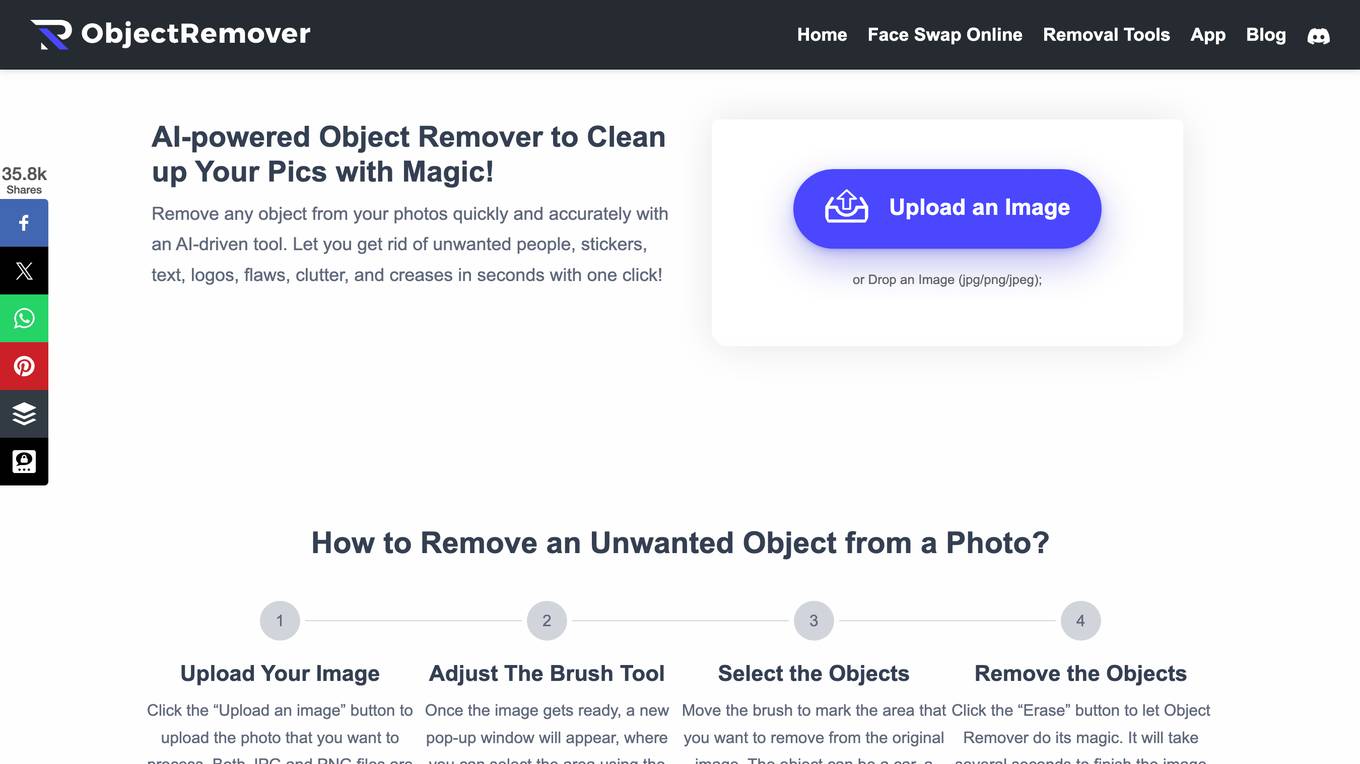
Object Remover
Object Remover is an AI-powered online tool that allows users to remove unwanted objects from their photos quickly and accurately. It uses advanced algorithms to analyze images and erase elements like people, stickers, text, logos, flaws, clutter, and creases with just one click. The tool is user-friendly, provides high-quality results, processes images fast, and offers a preview of the edited image before downloading. Object Remover is suitable for e-commerce product images, social media posts, and any photos that need object removal. Users can enjoy watermark-free editing and benefit from the AI-powered technology for picture-perfect results.
Object Remover
Object Remover is an online image cleanup tool that uses AI to remove unwanted objects, people, and defects from your photos. It's easy to use, just upload your photo and select the objects you want to remove. Object Remover will then automatically process your photo and remove the selected objects, leaving you with a clean, professional-looking image.

Ultralytics YOLO
Ultralytics YOLO is an advanced real-time object detection and image segmentation model that leverages cutting-edge advancements in deep learning and computer vision. It offers unparalleled performance in terms of speed and accuracy, making it suitable for various applications and easily adaptable to different hardware platforms. The comprehensive Ultralytics Docs provide resources to help users understand and utilize its features and capabilities, catering to both seasoned machine learning practitioners and newcomers to the field.

Segment Anything by Meta AI
Segment Anything by Meta AI is an advanced AI model that specializes in image segmentation, allowing users to easily 'cut out' any object in an image with a single click. The model, named SAM, offers zero-shot generalization to unfamiliar objects and images without the need for additional training. SAM's promptable design enables a wide range of segmentation tasks through input prompts, making it a versatile tool for various applications.
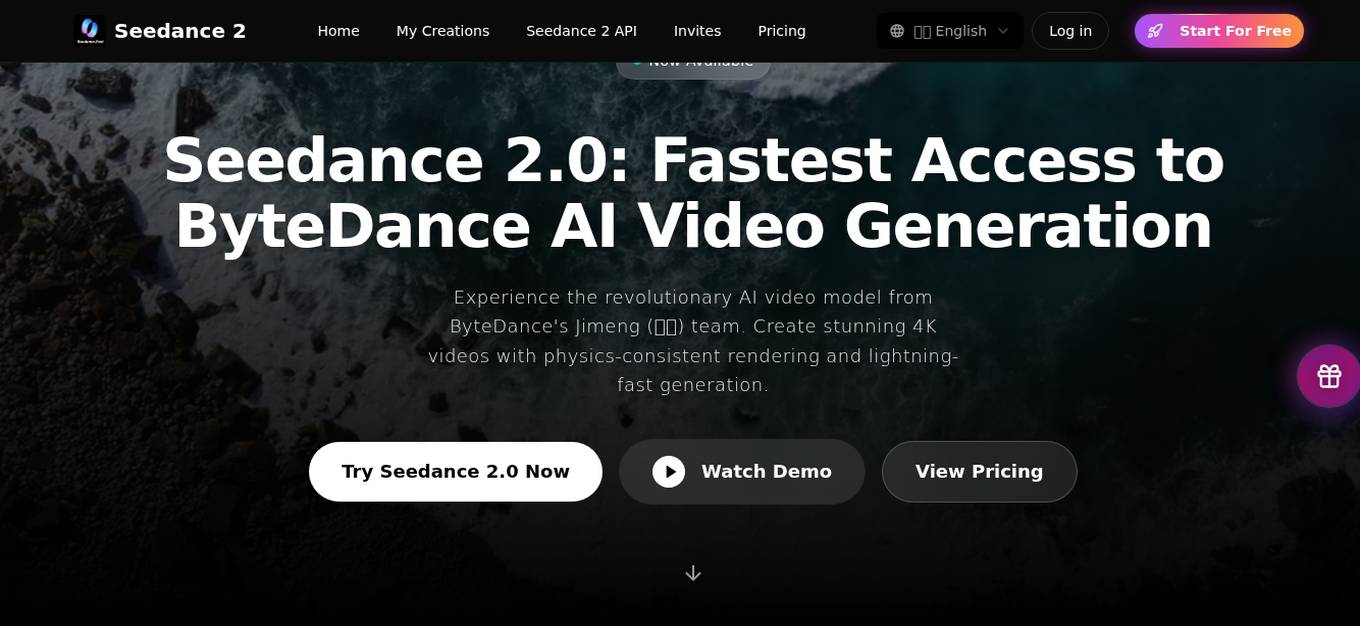
Seedance 2.0
Seedance 2.0 is an AI video generation tool developed by ByteDance's Jimeng team. It offers revolutionary AI video creation capabilities, including 4K resolution support, physics-consistent rendering, and lightning-fast generation speeds. The platform democratizes access to professional-grade AI video generation for content creators, developers, and enterprises, leveraging advanced neural architectures and vast training data to deliver unparalleled results in text-to-video, image-to-video, and video-to-video transformations.
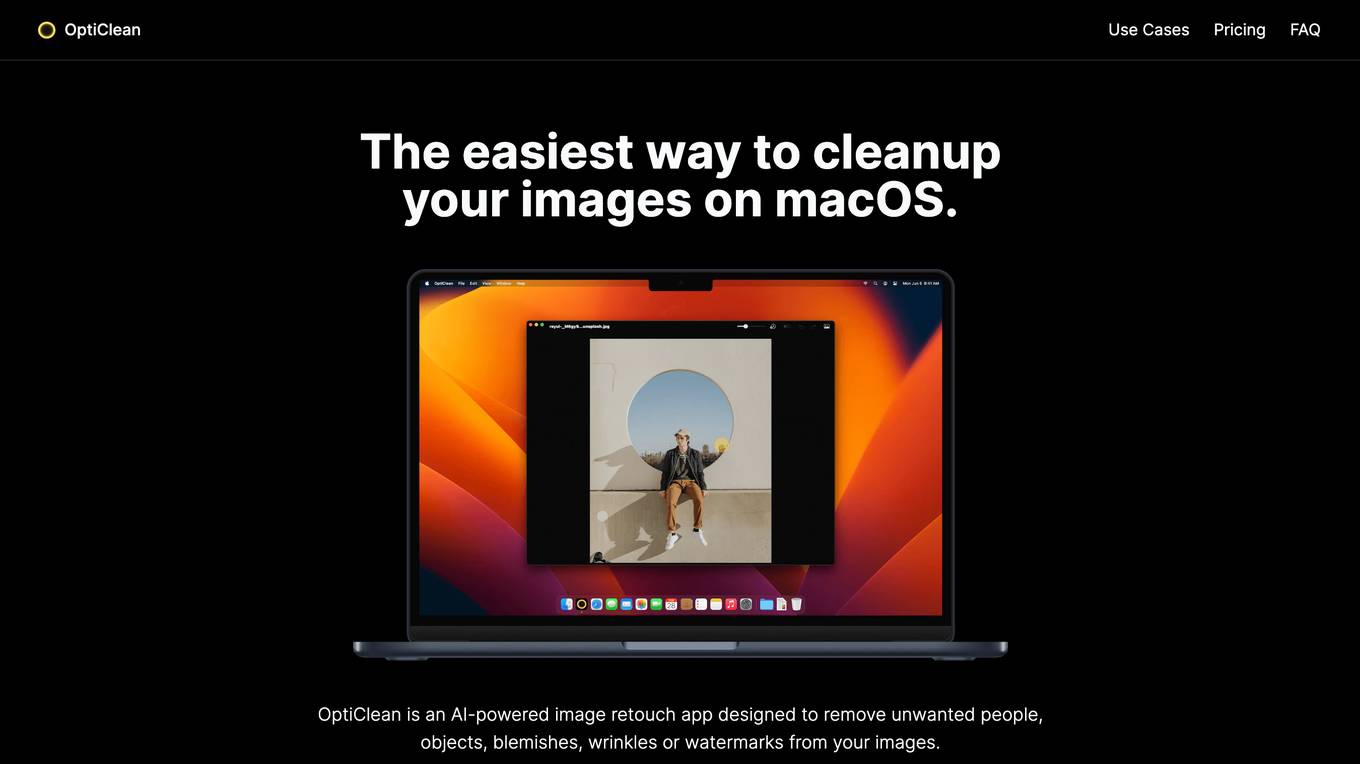
OptiClean
OptiClean is an AI-powered image retouch application specifically designed for macOS users. It offers a simple and efficient solution for cleaning up images by removing unwanted elements like people, objects, blemishes, wrinkles, and watermarks. With OptiClean, users can enhance the quality of their images effortlessly, without the need for complex editing tools. The application provides a user-friendly interface and advanced AI algorithms to deliver precise and professional results in image retouching.
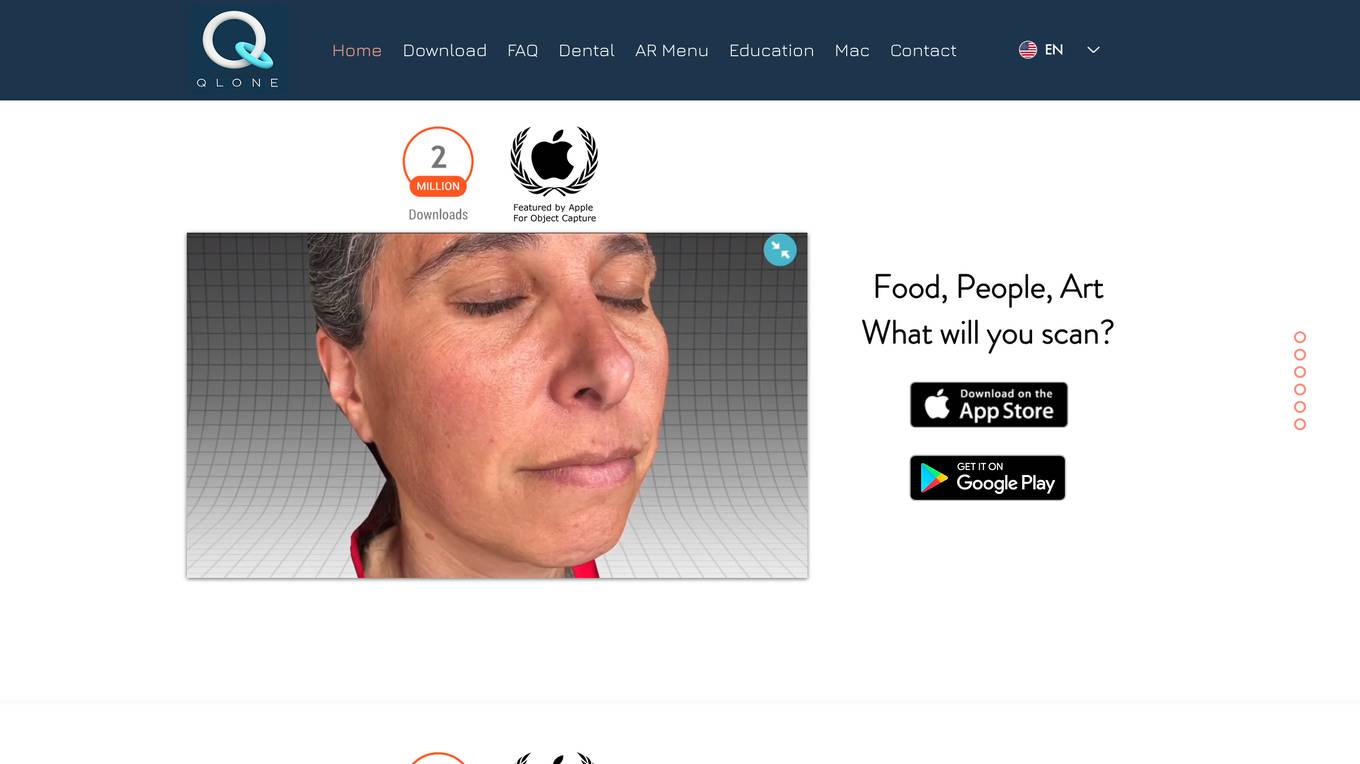
Qlone
Qlone is a user-friendly 3D scanning app that allows users to easily create 3D models using their smartphone or tablet. The app offers seamless integration with leading 3D platforms for printing, sharing, and selling models. Users can create AR menus, scan various objects like food, people, and art, and engage in educational activities. Qlone is developed by EyeCue Vision Technologies LTD and is designed to provide a simple and efficient 3D scanning experience.
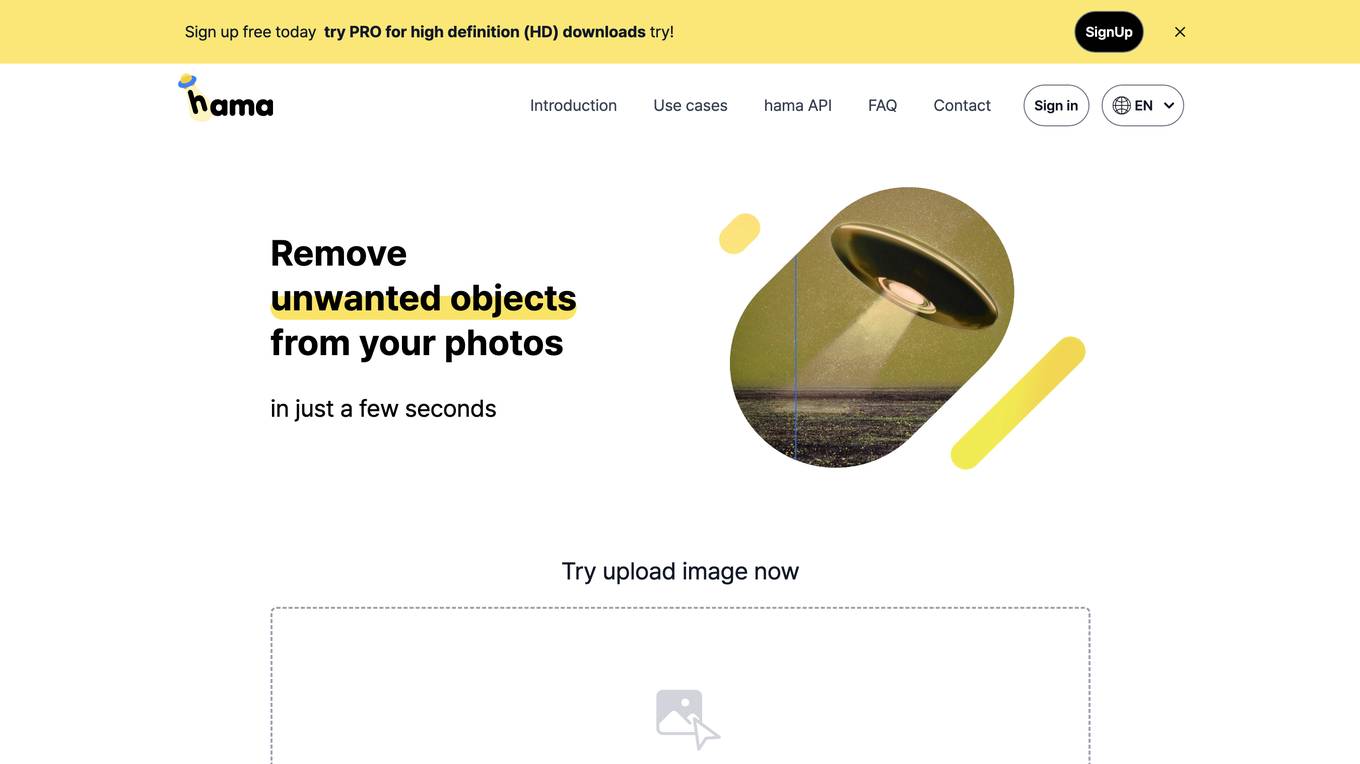
hama.app
Remove Objects from Photos - AI Image Eraser tool hama.app is an online tool that allows you to remove unwanted objects from your photos with just a few clicks. It uses artificial intelligence to automatically detect and remove objects, making it easy to clean up your photos and get rid of anything you don't want. With hama.app, you can remove people, objects, blemishes, and even entire backgrounds from your photos, leaving you with a clean and polished image.
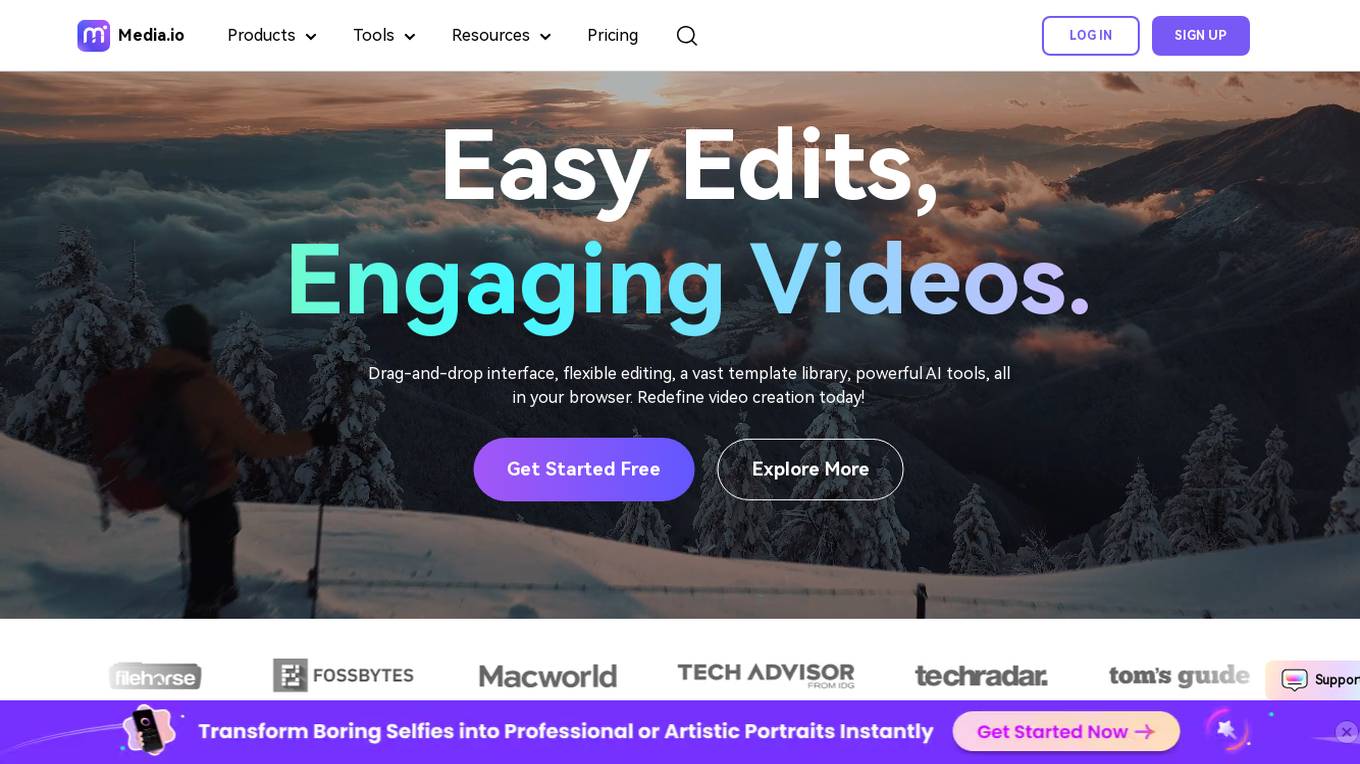
Media.io
Media.io is an online platform offering a wide range of AI tools for video, audio, and image editing. Users can easily enhance their creative projects with features like AI Portrait Generator, AI Video Generator, Video Editor, Image Enhancer, and more. The platform provides a drag-and-drop interface, flexible editing options, a vast template library, and powerful AI tools, all accessible directly from the browser. Media.io aims to redefine video creation by providing smart editing solutions for creators in various fields such as business, marketing, social media, and entertainment.
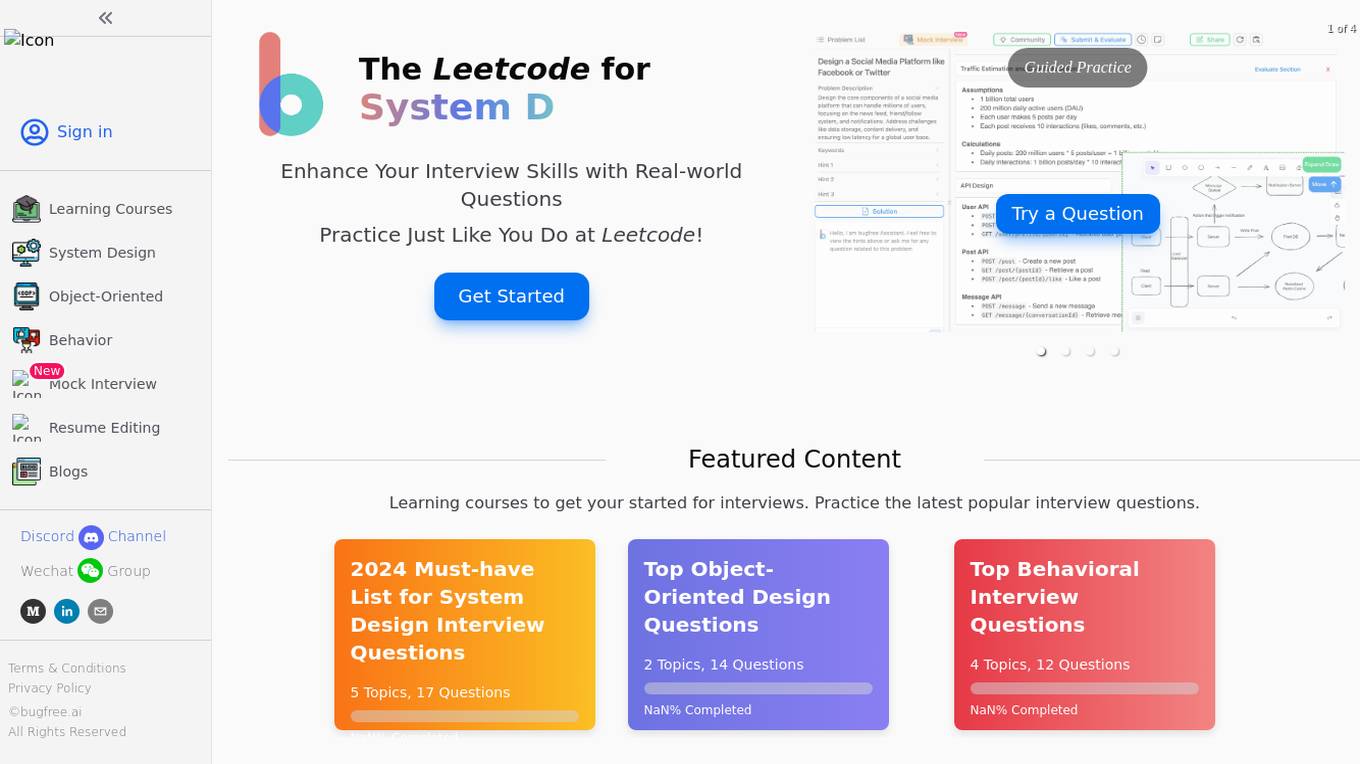
BugFree.ai
BugFree.ai is an AI-powered platform designed to help users practice system design and behavior interviews, similar to Leetcode. The platform offers a range of features to assist users in preparing for technical interviews, including mock interviews, real-time feedback, and personalized study plans. With BugFree.ai, users can improve their problem-solving skills and gain confidence in tackling complex interview questions.
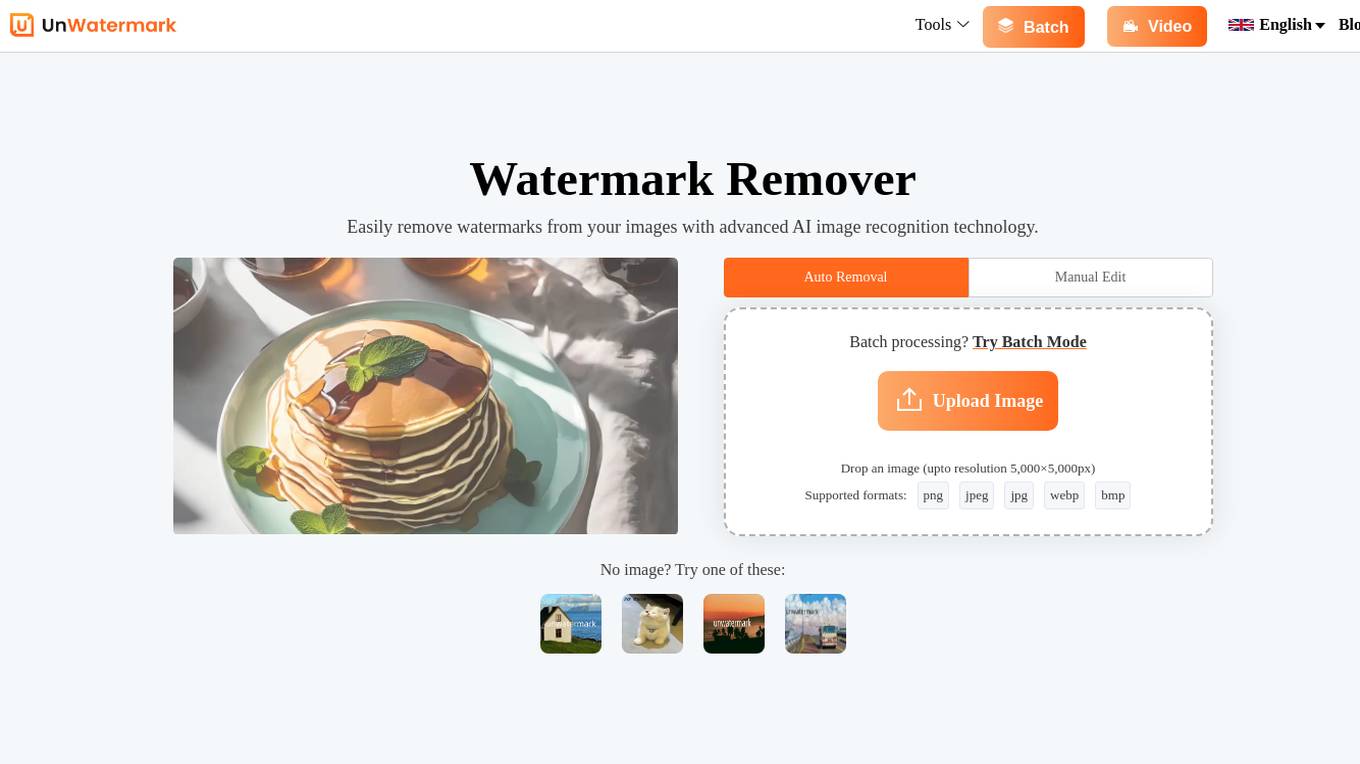
Unwatermark.AI
Unwatermark.AI is an advanced AI-powered tool designed specifically for removing watermarks from images and videos. It offers a fast, reliable, and user-friendly experience, allowing users to easily remove logos, text, and other unwanted elements from their visuals. The tool supports common image formats like JPG, PNG, WEBP, JPEG, BMP, and even provides a step-by-step guide for watermark removal. With features like high quality output, privacy assurance, multi-terminal support, and fast processing speed, Unwatermark.AI is a valuable solution for content creators, influencers, students, and anyone looking to manage their visual content effectively.

Luma AI
Luma AI is an AI application that specializes in AI video generation using advanced models like Ray3 and Dream Machine. The platform aims to provide production-ready images and videos with precision, speed, and control. Luma AI focuses on building multimodal general intelligence to generate, understand, and operate in the physical world, catering to a new era of creativity and human expression.
Stylar
Stylar is a powerful AI-powered image generation and design tool that provides users with unparalleled control over image composition and style. With its user-friendly interface and advanced features, Stylar makes it easy for users of all skill levels to create stunning and professional-looking images. Key features of Stylar include predefined styles for effortless design customization, layering, positioning, and sketching tools for intuitive design, and user-friendly interface for all skill levels.
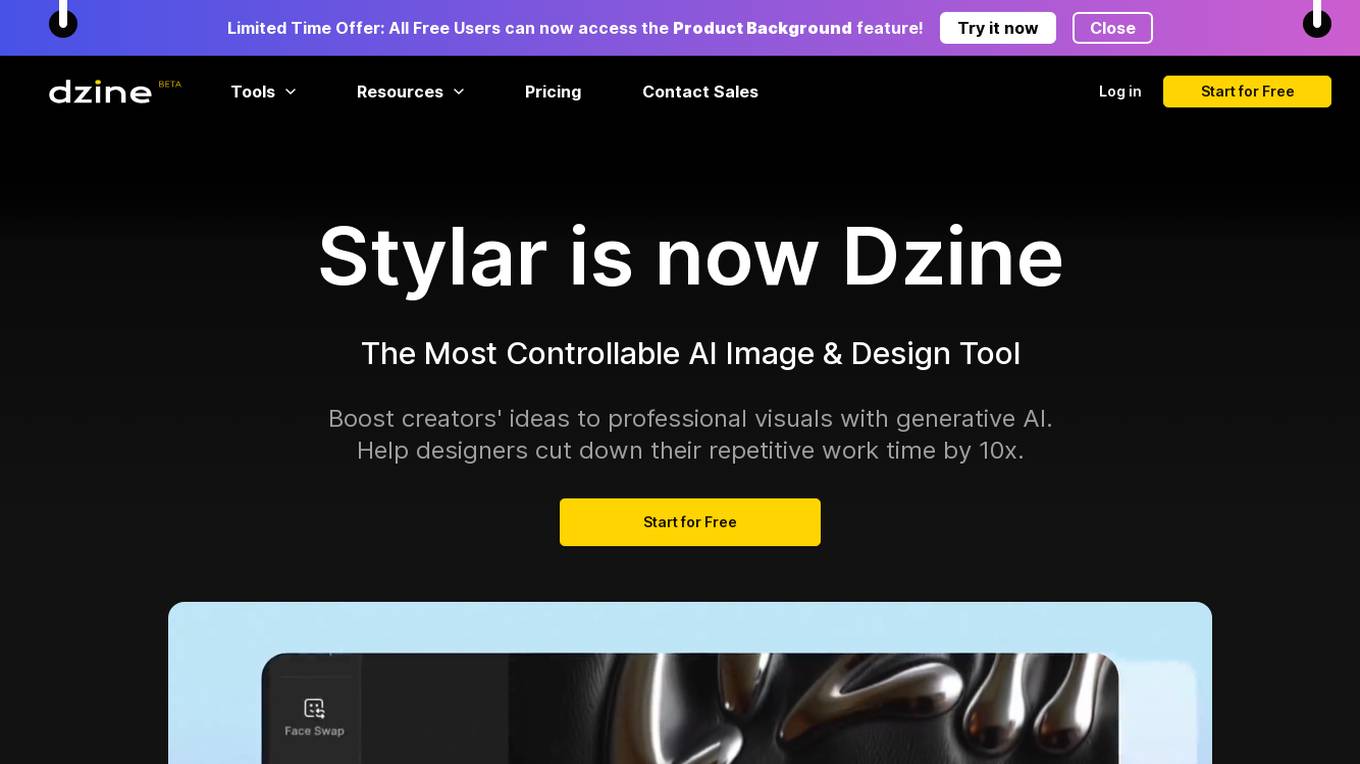
Dzine
Dzine (formerly Stylar.ai) is a powerful AI image generation and design tool that provides users with unparalleled control over image composition and style. It offers predefined styles for effortless design customization, layering, positioning, and sketching tools for intuitive design, and an 'Enhance' feature to address common challenges with AI-generated images. With a user-friendly interface suitable for all skill levels, Dzine makes it easy to create stunning and stylish images. It supports high-resolution exports and provides free credits for new users to try out its features.

Eazy Editor
Eazy Editor is an AI-powered image editing tool designed to streamline the editing process for eCommerce businesses, photographers, and content creators. With features like background removal, batch editing, text & watermark removal, and unlimited online backgrounds, Eazy Editor helps users transform product photos efficiently. The tool is praised for its time-saving capabilities, ease of use, and value for money, making it a popular choice for enhancing product imagery.
Luma AI
Luma AI is a 3D capture platform that allows users to create interactive 3D scenes from videos. With Luma AI, users can capture 3D models of people, objects, and environments, and then use those models to create interactive experiences such as virtual tours, product demonstrations, and training simulations.
Z.ai
Z.ai is a free AI chatbot and agent powered by GLM-5 and GLM-4.7. It provides users with an interactive platform to engage with AI technology for various purposes. The chatbot is designed to assist users in answering questions, providing information, and offering personalized recommendations. With advanced algorithms and machine learning capabilities, Z.ai aims to enhance user experience and streamline communication processes.
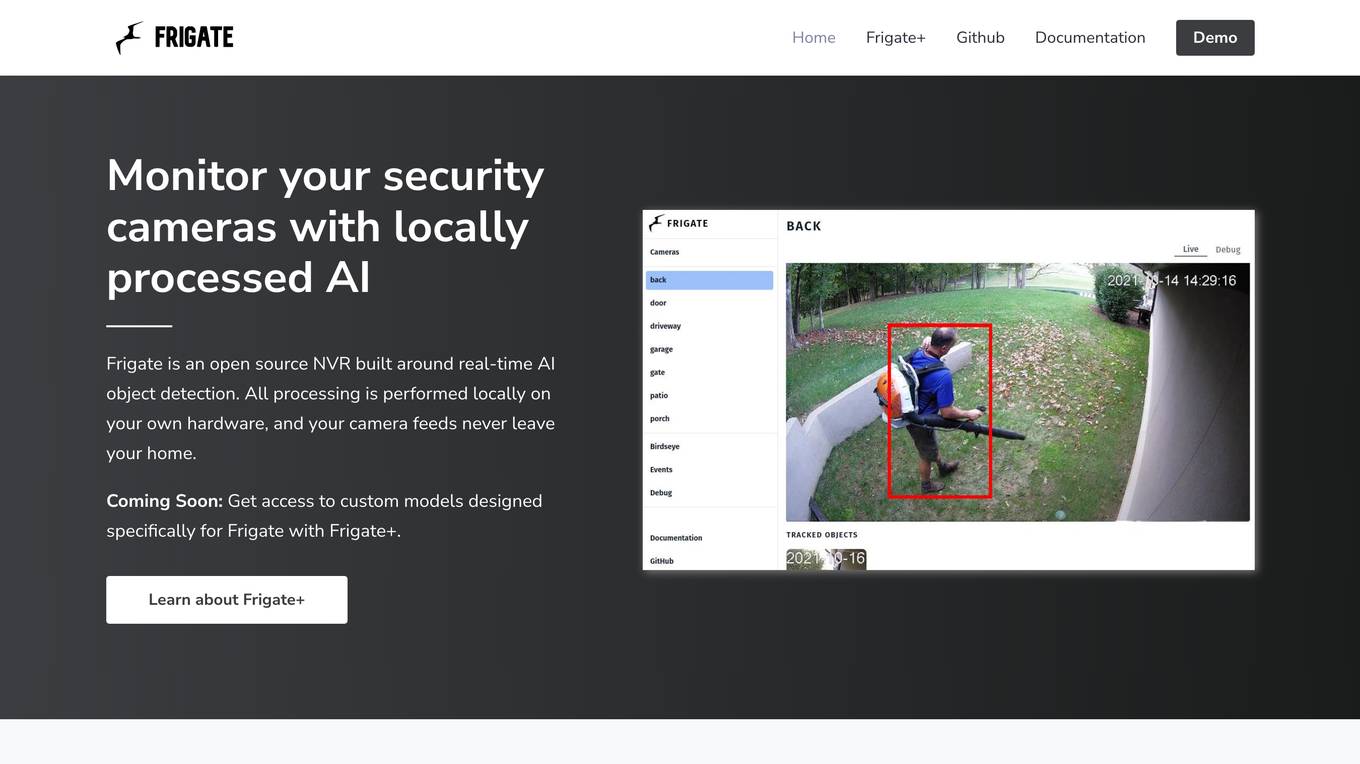
Frigate
Frigate is an open source NVR application that focuses on locally processed AI object detection for security camera monitoring. It ensures privacy by performing all processing on the user's hardware, without sending camera feeds to the cloud. Frigate offers custom models through Frigate+ and is popular among privacy-focused home automation enthusiasts.

Blackshark.ai
Blackshark.ai is an AI-based platform that generates real-time accurate semantic photorealistic 3D digital twin of the entire planet. The platform extracts insights about the planet's infrastructure from satellite and aerial imagery via machine learning at a global scale. It enriches missing attributes using AI to provide a photorealistic, geo-typical, or asset-specific digital twin. The results can be used for visualization, simulation, mapping, mixed reality environments, and other enterprise solutions. The platform offers end-to-end geospatial solutions, including globe data input sources, no-code data labeling, geointelligence at scale, 3D semantic map, and synthetic environments.
1 - Open Source Tools

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
20 - OpenAI Gpts
Everyday Object Storyteller
I craft stories from the perspective of objects, from mundane to horror.
Object Detection Mate
An Object Detection chatbot assistant offering educational materials, code examples, and multilingual support.
16-bit Multiview
Multiple perspective 16-bit sprite/pixel art objects/characters. Just name an object. A great starting point for 2d game assets.
3D Illustrations Creator by Mojju
Experience bespoke 3D illustration creation with 3D Illustrations Creator by Mojju. Specializing in modern, minimalistic 3D designs with a playful touch, it transforms your ideas into visually appealing single-object illustrations.

Pixie: Computer Vision Engineer
Expert in computer vision, deep learning, ready to assist you with 3d and geometric computer vision. https://github.com/kornia/pixie

Stardust meaning?
What is Stardust lyrics meaning? Stardust singer:Jill Cunniff,album:,album_time:. Click The LINK For More ↓↓↓

Deep Learning Master
Guiding you through the depths of deep learning with accuracy and respect.
¿Cómo funciona?
Este GPT explica cómo funciona un objeto y todos los avancces científicos que han permitido su creación.