
Auto-Analyst
AI data scientist
Stars: 180
Auto-Analyst is an AI-driven data analytics agentic system designed to simplify and enhance the data science process. By integrating various specialized AI agents, this tool aims to make complex data analysis tasks more accessible and efficient for data analysts and scientists. Auto-Analyst provides a streamlined approach to data preprocessing, statistical analysis, machine learning, and visualization, all within an interactive Streamlit interface. It offers plug and play Streamlit UI, agents with data science speciality, complete automation, LLM agnostic operation, and is built using lightweight frameworks.
README:

Auto-Analyst is an AI-driven data analytics agentic system designed to simplify and enhance the data science process. By integrating various specialized AI agents, this tool aims to make complex data analysis tasks more accessible and efficient for data analysts and scientists. Auto-Analyst provides a streamlined approach to data preprocessing, statistical analysis, machine learning, and visualization, all within an interactive Streamlit interface.

-
Plug and Play Streamlit UI:
- An intuitive and interactive web interface powered by Streamlit that makes it easy to use and visualize data without extensive setup.
-
Agents with Data Science Speciality:
- Data Visualization Agent: Generates a wide range of Plotly charts and visualizations.
- Statistical Analytics Agent: Performs comprehensive statistical analyses and generates descriptive statistics.
- Scikit-Learn Agent: Integrates with Scikit-Learn to build and evaluate machine learning models.
- Preprocessing Agent: Handles data cleaning, transformation, and preparation tasks.
-
Completely Automated, LLM Agnostic:
- The system operates with full automation and is agnostic to large language models (LLMs), making it adaptable to various AI models and technologies.
-
Built Using Lightweight Frameworks:
- Constructed with efficient frameworks like DSPy, ensuring a lightweight and responsive application.
To run the Streamlit app locally, follow these steps:
First, clone the repository to your local machine using Git:
git clone https://github.com/ArslanS1997/Auto-Analyst.git
cd your-repositoryCreate a virtual environment and install the required Python packages. The required packages are listed in the requirements.txt file. Make sure you have pip installed, and then run:
python -m venv venv
source venv/bin/activate # On Windows use `venv\Scripts\activate`
pip install -r requirements.txtYou need to set up the OPENAI_API_KEY environment variable for the app to function. You can do this by adding the following line to your .env file or by exporting the variable in your terminal:
Create a file named .env in the root of your project and add:
OPENAI_API_KEY=your_openai_api_key_here
export OPENAI_API_KEY=your_openai_api_key_hereReplace your_openai_api_key_here with your actual OpenAI API key.
Start the Streamlit app using the following command:
streamlit run new_frontend.pyThe project consists of several key files, each serving a distinct purpose:
-
agents.py:- Description: Contains the definitions for various AI agents used in the system.
-
Key Agents:
-
auto_analyst_ind: Routes queries to the appropriate agent based on user input and provides a detailed response. -
auto_analyst: Integrates a planner agent for routing queries and a code combiner agent for synthesizing outputs from multiple agents. -
memory_summarize_agent: Summarizes agent responses and user queries. -
error_memory_agent: Creates summaries of code errors and their corrections.
-
-
memory_agents.py:- Description: Defines agents that help summarize memory and errors.
-
Key Agents:
-
memory_summarize_agent: Provides summaries of agent responses and user goals. -
error_memory_agent: Analyzes and summarizes code errors and suggested corrections.
-
-
retrievers.py:- Description: Contains functions and configurations for retrieving and processing data.
-
Key Functions:
-
return_vals: Collects useful information about data columns, such as statistics and top categories. -
correct_num: Cleans numeric columns by removing commas and converting to float. -
make_data: Pre-processes data and generates a description of the dataset.
-
- Styling Instructions: Provides instructions for styling Plotly charts for different types of visualizations, including line charts, bar charts, histograms, pie charts, and heat maps.
-
new_frontend.py:- Description: The main Streamlit script that runs the application and integrates all the agents and functionalities provided in the other files.
This project is licensed under the MIT License. See the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Auto-Analyst
Similar Open Source Tools
Auto-Analyst
Auto-Analyst is an AI-driven data analytics agentic system designed to simplify and enhance the data science process. By integrating various specialized AI agents, this tool aims to make complex data analysis tasks more accessible and efficient for data analysts and scientists. Auto-Analyst provides a streamlined approach to data preprocessing, statistical analysis, machine learning, and visualization, all within an interactive Streamlit interface. It offers plug and play Streamlit UI, agents with data science speciality, complete automation, LLM agnostic operation, and is built using lightweight frameworks.
awsome_kali_MCPServers
awsome-kali-MCPServers is a repository containing Model Context Protocol (MCP) servers tailored for Kali Linux environments. It aims to optimize reverse engineering, security testing, and automation tasks by incorporating powerful tools and flexible features. The collection includes network analysis tools, support for binary understanding, and automation scripts to streamline repetitive tasks. The repository is continuously evolving with new features and integrations based on the FastMCP framework, such as network scanning, symbol analysis, binary analysis, string extraction, network traffic analysis, and sandbox support using Docker containers.

minefield
BitBom Minefield is a tool that uses roaring bit maps to graph Software Bill of Materials (SBOMs) with a focus on speed, air-gapped operation, scalability, and customizability. It is optimized for rapid data processing, operates securely in isolated environments, supports millions of nodes effortlessly, and allows users to extend the project without relying on upstream changes. The tool enables users to manage and explore software dependencies within isolated environments by offline processing and analyzing SBOMs.
trip_planner_agent
VacAIgent is an AI tool that automates and enhances trip planning by leveraging the CrewAI framework. It integrates a user-friendly Streamlit interface for interactive travel planning. Users can input preferences and receive tailored travel plans with the help of autonomous AI agents. The tool allows for collaborative decision-making on cities and crafting complete itineraries based on specified preferences, all accessible via a streamlined Streamlit user interface. VacAIgent can be customized to use different AI models like GPT-3.5 or local models like Ollama for enhanced privacy and customization.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.

cosdata
Cosdata is a cutting-edge AI data platform designed to power the next generation search pipelines. It features immutability, version control, and excels in semantic search, structured knowledge graphs, hybrid search capabilities, real-time search at scale, and ML pipeline integration. The platform is customizable, scalable, efficient, enterprise-grade, easy to use, and can manage multi-modal data. It offers high performance, indexing, low latency, and high requests per second. Cosdata is designed to meet the demands of modern search applications, empowering businesses to harness the full potential of their data.
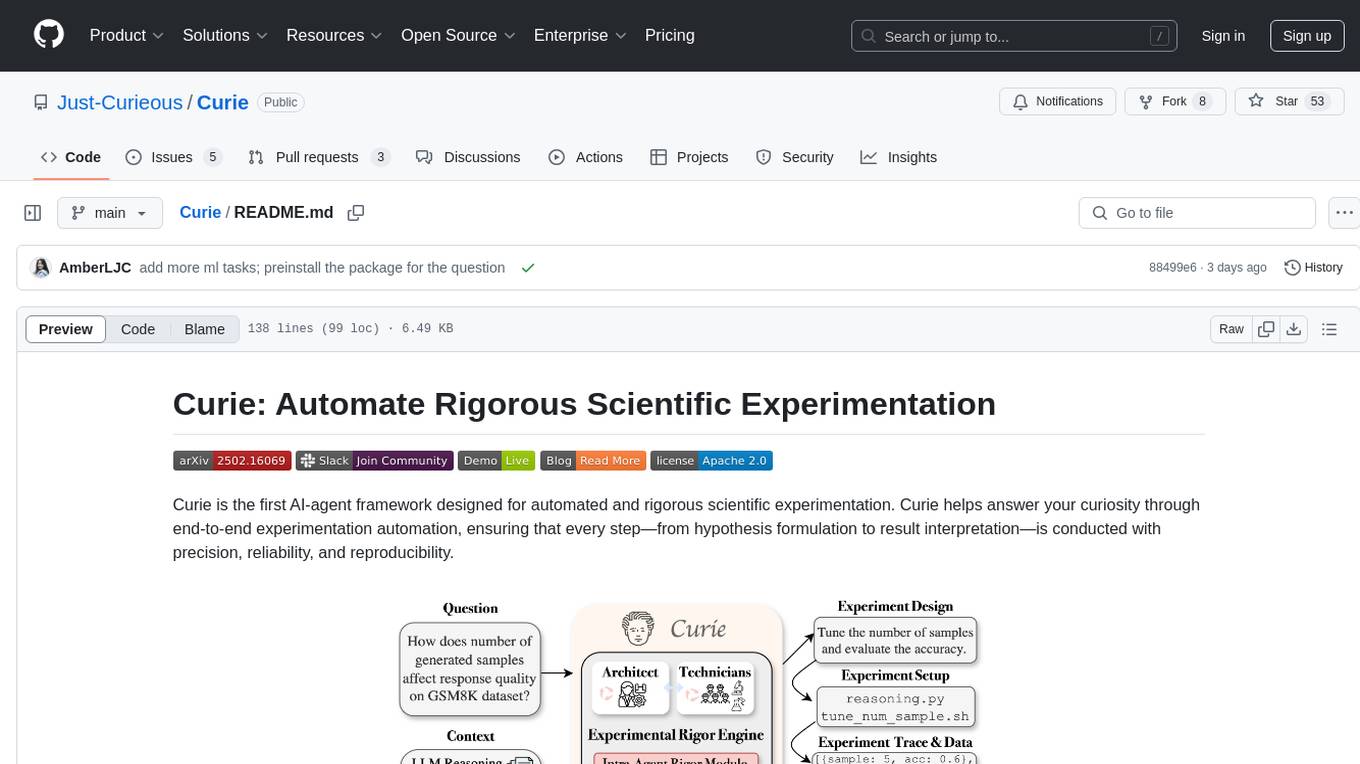
Curie
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.
ai_automation_suggester
An integration for Home Assistant that leverages AI models to understand your unique home environment and propose intelligent automations. By analyzing your entities, devices, areas, and existing automations, the AI Automation Suggester helps you discover new, context-aware use cases you might not have considered, ultimately streamlining your home management and improving efficiency, comfort, and convenience. The tool acts as a personal automation consultant, providing actionable YAML-based automations that can save energy, improve security, enhance comfort, and reduce manual intervention. It turns the complexity of a large Home Assistant environment into actionable insights and tangible benefits.
Auditor
TheAuditor is an offline-first, AI-centric SAST & code intelligence platform designed to find security vulnerabilities, track data flow, analyze architecture, detect refactoring issues, run industry-standard tools, and produce AI-ready reports. It is specifically tailored for AI-assisted development workflows, providing verifiable ground truth for developers and AI assistants. The tool orchestrates verifiable data, focuses on AI consumption, and is extensible to support Python and Node.js ecosystems. The comprehensive analysis pipeline includes stages for foundation, concurrent analysis, and final aggregation, offering features like refactoring detection, dependency graph visualization, and optional insights analysis. The tool interacts with antivirus software to identify vulnerabilities, triggers performance impacts, and provides transparent information on common issues and troubleshooting. TheAuditor aims to address the lack of ground truth in AI development workflows and make AI development trustworthy by providing accurate security analysis and code verification.

LLMstudio
LLMstudio by TensorOps is a platform that offers prompt engineering tools for accessing models from providers like OpenAI, VertexAI, and Bedrock. It provides features such as Python Client Gateway, Prompt Editing UI, History Management, and Context Limit Adaptability. Users can track past runs, log costs and latency, and export history to CSV. The tool also supports automatic switching to larger-context models when needed. Coming soon features include side-by-side comparison of LLMs, automated testing, API key administration, project organization, and resilience against rate limits. LLMstudio aims to streamline prompt engineering, provide execution history tracking, and enable effortless data export, offering an evolving environment for teams to experiment with advanced language models.
resume-job-matcher
Resume Job Matcher is a Python script that automates the process of matching resumes to a job description using AI. It leverages the Anthropic Claude API or OpenAI's GPT API to analyze resumes and provide a match score along with personalized email responses for candidates. The tool offers comprehensive resume processing, advanced AI-powered analysis, in-depth evaluation & scoring, comprehensive analytics & reporting, enhanced candidate profiling, and robust system management. Users can customize font presets, generate PDF versions of unified resumes, adjust logging level, change scoring model, modify AI provider, and adjust AI model. The final score for each resume is calculated based on AI-generated match score and resume quality score, ensuring content relevance and presentation quality are considered. Troubleshooting tips, best practices, contribution guidelines, and required Python packages are provided.
llmgateway
The llmgateway repository is a tool that provides a gateway for interacting with various LLM (Large Language Model) models. It allows users to easily access and utilize pre-trained language models for tasks such as text generation, sentiment analysis, and language translation. The tool simplifies the process of integrating LLMs into applications and workflows, enabling developers to leverage the power of state-of-the-art language models for various natural language processing tasks.
RA.Aid
RA.Aid is an AI software development agent powered by `aider` and advanced reasoning models like `o1`. It combines `aider`'s code editing capabilities with LangChain's agent-based task execution framework to provide an intelligent assistant for research, planning, and implementation of multi-step development tasks. It handles complex programming tasks by breaking them down into manageable steps, running shell commands automatically, and leveraging expert reasoning models like OpenAI's o1. RA.Aid is designed for everyday software development, offering features such as multi-step task planning, automated command execution, and the ability to handle complex programming tasks beyond single-shot code edits.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.