
tiny-ai-client
Tiny client for LLMs with vision and tool calling. As simple as it gets.
Stars: 70
Tiny AI Client is a lightweight tool designed for easy usage and switching of Language Model Models (LLMs) with support for vision and tool usage. It aims to provide a simple and intuitive interface for interacting with various LLMs, allowing users to easily set, change models, send messages, use tools, and handle vision tasks. The core logic of the tool is kept minimal and easy to understand, with separate modules for vision and tool usage utilities. Users can interact with the tool through simple Python scripts, passing model names, messages, tools, and images as required.
README:
Inspired by tinygrad and simpleaichat, tiny-ai-client is the easiest way to use and switch LLMs with vision and tool usage support. It works because it is tiny, simple and most importantly fun to develop.
I want to change LLMs with ease, while knowing what is happening under the hood. Langchain is cool, but became bloated, complicated there is just too much chaos going on. I want to keep it simple, easy to understand and easy to use. If you want to use a LLM and have an API key, you should not need to read a 1000 lines of code and write response.choices[0].message.content to get the response.
Simple and tiny, that's the goal.
Features:
- OpenAI
- Anthropic
- Async
- Tool usage
- Structured output
- Vision
- PyPI package
tiny-ai-client - Gemini (vision, no tools)
- Ollama (text, no vision, no tools) (you can also pass a custom model_server_url to AI/AsyncAI)
- To use it,
model_name='ollama:llama3'or your model name.
- To use it,
- Groq (text, tools, no vision)
- To use it
model_name='groq:llama-70b-8192'or your model name as in Groq docs.
- To use it
Roadmap:
- Gemini tools
tiny-ai-client is simple and intuitive:
- Do you want set your model? Just pass the model name.
- Do you want to change your model? Just change the model name.
- Want to send a message?
msg: str = ai("hello")and say goodbye to parsing a complex json. - Do you want to use a tool? Just pass the tool as a function
- Type hint it with a single argument that inherits from
pydantic.BaseModeland just pass the callable.AIwill call it and get its results to you if the model wants to.
- Type hint it with a single argument that inherits from
- Want to use vision? Just pass a
PIL.Image.Image. - Video? Just pass a list of
PIL.Image.Image.
-
tiny-ai-clientis very small, its core logic is < 250 lines of code (including comments and docstrings) and ideally won't pass 500. It is and always will be easy to understand, tweak and use.- The core logic is in
tiny_ai_client/models.py - Vision utils are in
tiny_ai_client/vision.py - Tool usage utils are in
tiny_ai_client/tools.py
- The core logic is in
- The interfaces are implemented by subclassing
tiny_ai_client.models.LLMClientWrapperbinding it to a specific LLM provider. This logic might get bigger, but it is isolated in a single file and does not affect the core logic.
pip install tiny-ai-clientTo test, set the following environment variables:
- OPENAI_API_KEY
- ANTHROPIC_API_KEY
- GROQ_API_KEY
- GOOGLE_API_KEY
Then
To run all examples:
./scripts/run-all-examples.shFor OpenAI:
from tiny_ai_client import AI, AsyncAI
ai = AI(
model_name="gpt-4o", system="You are Spock, from Star Trek.", max_new_tokens=128
)
response = ai("What is the meaning of life?")
ai = AsyncAI(
model_name="gpt-4o", system="You are Spock, from Star Trek.", max_new_tokens=128
)
response = await ai("What is the meaning of life?")For Anthropic:
from tiny_ai_client import AI, AsyncAI
ai = AI(
model_name="claude-3-haiku-20240307", system="You are Spock, from Star Trek.", max_new_tokens=128
)
response = ai("What is the meaning of life?")
ai = AsyncAI(
model_name="claude-3-haiku-20240307", system="You are Spock, from Star Trek.", max_new_tokens=128
)
response = await ai("What is the meaning of life?")We also support tool usage for both. You can pass as many functions you want as type-hinted functions with a single argument that inherits from pydantic.BaseModel. AI will call the function and get its results to you.
from pydantic import BaseModel, Field
from tiny_ai_client import AI, AsyncAI
class WeatherParams(BaseModel):
location: str = Field(..., description="The city and state, e.g. San Francisco, CA")
unit: str = Field(
"celsius", description="Temperature unit", enum=["celsius", "fahrenheit"]
)
def get_current_weather(weather: WeatherParams):
"""
Get the current weather in a given location
"""
return f"Getting the current weather in {weather.location} in {weather.unit}."
ai = AI(
model_name="gpt-4o",
system="You are Spock, from Star Trek.",
max_new_tokens=32,
tools=[get_current_weather],
)
response = ai("What is the meaning of life?")
print(f"{response=}")
response = ai("Please get the current weather in celsius for San Francisco.")
print(f"{response=}")
response = ai("Did it work?")
print(f"{response=}")And vision. Pass a list of PIL.Image.Image (or a single one) and we will handle the rest.
from tiny_ai_client import AI, AsyncAI
from PIL import Image
ai = AI(
model_name="gpt-4o",
system="You are Spock, from Star Trek.",
max_new_tokens=32,
)
response = ai(
"Who is on the images?",
images[
Image.open("assets/kirk.jpg"),
Image.open("assets/spock.jpg")
]
)
print(f"{response=}")For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for tiny-ai-client
Similar Open Source Tools
tiny-ai-client
Tiny AI Client is a lightweight tool designed for easy usage and switching of Language Model Models (LLMs) with support for vision and tool usage. It aims to provide a simple and intuitive interface for interacting with various LLMs, allowing users to easily set, change models, send messages, use tools, and handle vision tasks. The core logic of the tool is kept minimal and easy to understand, with separate modules for vision and tool usage utilities. Users can interact with the tool through simple Python scripts, passing model names, messages, tools, and images as required.

airflow-ai-sdk
This repository contains an SDK for working with LLMs from Apache Airflow, based on Pydantic AI. It allows users to call LLMs and orchestrate agent calls directly within their Airflow pipelines using decorator-based tasks. The SDK leverages the familiar Airflow `@task` syntax with extensions like `@task.llm`, `@task.llm_branch`, and `@task.agent`. Users can define tasks that call language models, orchestrate multi-step AI reasoning, change the control flow of a DAG based on LLM output, and support various models in the Pydantic AI library. The SDK is designed to integrate LLM workflows into Airflow pipelines, from simple LLM calls to complex agentic workflows.
aiorun
aiorun is a Python package that provides a `run()` function as the starting point of your `asyncio`-based application. The `run()` function handles everything needed during the shutdown sequence of the application, such as creating a `Task` for the given coroutine, running the event loop, adding signal handlers for `SIGINT` and `SIGTERM`, cancelling tasks, waiting for the executor to complete shutdown, and closing the loop. It automates standard actions for asyncio apps, eliminating the need to write boilerplate code. The package also offers error handling options and tools for specific scenarios like TCP server startup and smart shield for shutdown.
experts
Experts.js is a tool that simplifies the creation and deployment of OpenAI's Assistants, allowing users to link them together as Tools to create a Panel of Experts system with expanded memory and attention to detail. It leverages the new Assistants API from OpenAI, which offers advanced features such as referencing attached files & images as knowledge sources, supporting instructions up to 256,000 characters, integrating with 128 tools, and utilizing the Vector Store API for efficient file search. Experts.js introduces Assistants as Tools, enabling the creation of Multi AI Agent Systems where each Tool is an LLM-backed Assistant that can take on specialized roles or fulfill complex tasks.

langevals
LangEvals is an all-in-one Python library for testing and evaluating LLM models. It can be used in notebooks for exploration, in pytest for writing unit tests, or as a server API for live evaluations and guardrails. The library is modular, with 20+ evaluators including Ragas for RAG quality, OpenAI Moderation, and Azure Jailbreak detection. LangEvals powers LangWatch evaluations and provides tools for batch evaluations on notebooks and unit test evaluations with PyTest. It also offers LangEvals evaluators for LLM-as-a-Judge scenarios and out-of-the-box evaluators for language detection and answer relevancy checks.
simplemind
Simplemind is an AI library designed to simplify the experience with AI APIs in Python. It provides easy-to-use AI tools with a human-centered design and minimal configuration. Users can tap into powerful AI capabilities through simple interfaces, without needing to be experts. The library supports various APIs from different providers/models and offers features like text completion, streaming text, structured data handling, conversational AI, tool calling, and logging. Simplemind aims to make AI models accessible to all by abstracting away complexity and prioritizing readability and usability.

LongRAG
This repository contains the code for LongRAG, a framework that enhances retrieval-augmented generation with long-context LLMs. LongRAG introduces a 'long retriever' and a 'long reader' to improve performance by using a 4K-token retrieval unit, offering insights into combining RAG with long-context LLMs. The repo provides instructions for installation, quick start, corpus preparation, long retriever, and long reader.

ActionWeaver
ActionWeaver is an AI application framework designed for simplicity, relying on OpenAI and Pydantic. It supports both OpenAI API and Azure OpenAI service. The framework allows for function calling as a core feature, extensibility to integrate any Python code, function orchestration for building complex call hierarchies, and telemetry and observability integration. Users can easily install ActionWeaver using pip and leverage its capabilities to create, invoke, and orchestrate actions with the language model. The framework also provides structured extraction using Pydantic models and allows for exception handling customization. Contributions to the project are welcome, and users are encouraged to cite ActionWeaver if found useful.
MiniAgents
MiniAgents is an open-source Python framework designed to simplify the creation of multi-agent AI systems. It offers a parallelism and async-first design, allowing users to focus on building intelligent agents while handling concurrency challenges. The framework, built on asyncio, supports LLM-based applications with immutable messages and seamless asynchronous token and message streaming between agents.
backtrack_sampler
Backtrack Sampler is a framework for experimenting with custom sampling algorithms that can backtrack the latest generated tokens. It provides a simple and easy-to-understand codebase for creating new sampling strategies. Users can implement their own strategies by creating new files in the `/strategy` directory. The repo includes examples for usage with llama.cpp and transformers, showcasing different strategies like Creative Writing, Anti-slop, Debug, Human Guidance, Adaptive Temperature, and Replace. The goal is to encourage experimentation and customization of backtracking algorithms for language models.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.
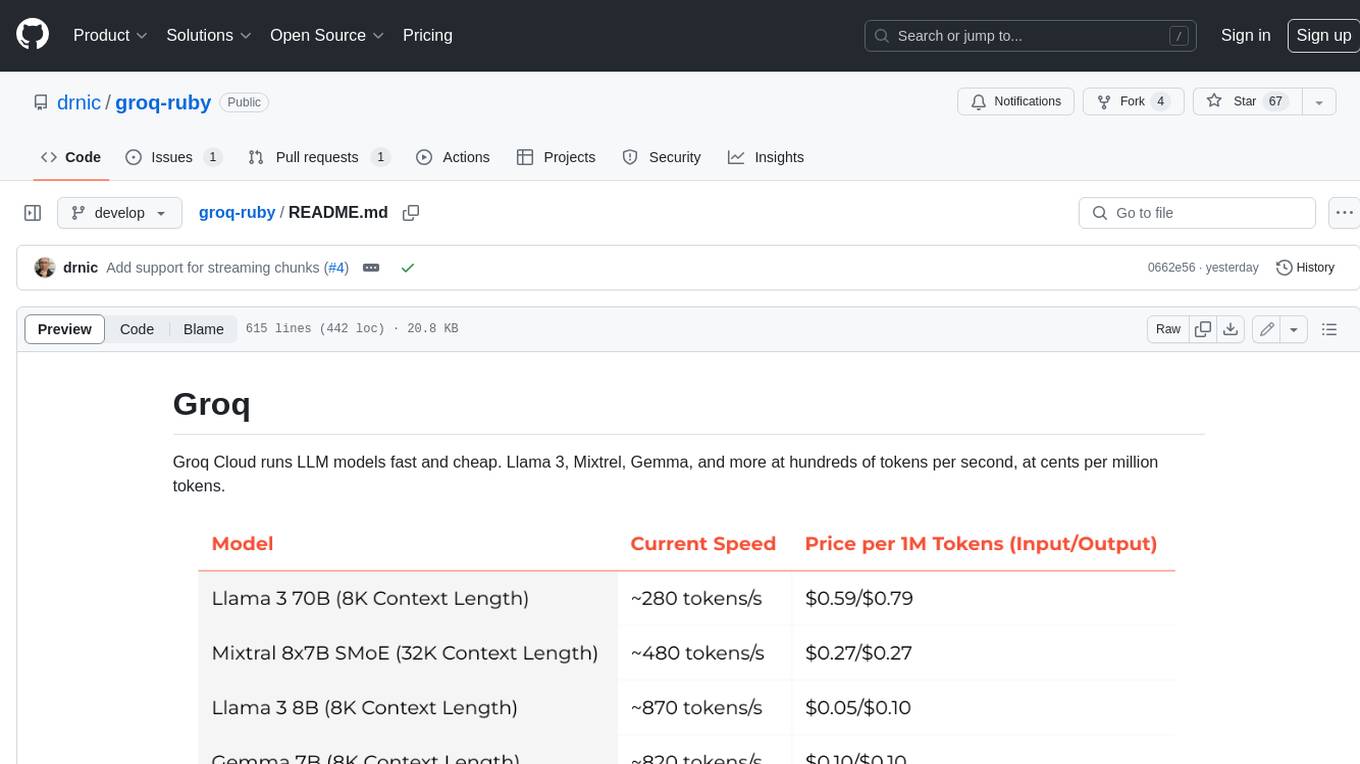
groq-ruby
Groq Cloud runs LLM models fast and cheap. Llama 3, Mixtrel, Gemma, and more at hundreds of tokens per second, at cents per million tokens.

neocodeium
NeoCodeium is a free AI completion plugin powered by Codeium, designed for Neovim users. It aims to provide a smoother experience by eliminating flickering suggestions and allowing for repeatable completions using the `.` key. The plugin offers performance improvements through cache techniques, displays suggestion count labels, and supports Lua scripting. Users can customize keymaps, manage suggestions, and interact with the AI chat feature. NeoCodeium enhances code completion in Neovim, making it a valuable tool for developers seeking efficient coding assistance.
agent-mimir
Agent Mimir is a command line and Discord chat client 'agent' manager for LLM's like Chat-GPT that provides the models with access to tooling and a framework with which accomplish multi-step tasks. It is easy to configure your own agent with a custom personality or profession as well as enabling access to all tools that are compatible with LangchainJS. Agent Mimir is based on LangchainJS, every tool or LLM that works on Langchain should also work with Mimir. The tasking system is based on Auto-GPT and BabyAGI where the agent needs to come up with a plan, iterate over its steps and review as it completes the task.

invariant
Invariant Analyzer is an open-source scanner designed for LLM-based AI agents to find bugs, vulnerabilities, and security threats. It scans agent execution traces to identify issues like looping behavior, data leaks, prompt injections, and unsafe code execution. The tool offers a library of built-in checkers, an expressive policy language, data flow analysis, real-time monitoring, and extensible architecture for custom checkers. It helps developers debug AI agents, scan for security violations, and prevent security issues and data breaches during runtime. The analyzer leverages deep contextual understanding and a purpose-built rule matching engine for security policy enforcement.
POPPER
Popper is an agentic framework for automated validation of free-form hypotheses using Large Language Models (LLMs). It follows Karl Popper's principle of falsification and designs falsification experiments to validate hypotheses. Popper ensures strict Type-I error control and actively gathers evidence from diverse observations. It delivers robust error control, high power, and scalability across various domains like biology, economics, and sociology. Compared to human scientists, Popper achieves comparable performance in validating complex biological hypotheses while reducing time by 10 folds, providing a scalable, rigorous solution for hypothesis validation.
For similar tasks

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.

spark-free-api
Spark AI Free 服务 provides high-speed streaming output, multi-turn dialogue support, AI drawing support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository includes multiple free-api projects for various AI services. Users can access the API for tasks such as chat completions, AI drawing, document interpretation, image analysis, and ssoSessionId live checking. The project also provides guidelines for deployment using Docker, Docker-compose, Render, Vercel, and native deployment methods. It recommends using custom clients for faster and simpler access to the free-api series projects.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.

horde-worker-reGen
This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.

geospy
Geospy is a Python tool that utilizes Graylark's AI-powered geolocation service to determine the location where photos were taken. It allows users to analyze images and retrieve information such as country, city, explanation, coordinates, and Google Maps links. The tool provides a seamless way to integrate geolocation services into various projects and applications.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.