
experts
Experts.js is the easiest way to create and deploy OpenAI's Assistants and link them together as Tools to create advanced Multi AI Agent Systems with expanded memory and attention to detail.
Stars: 964
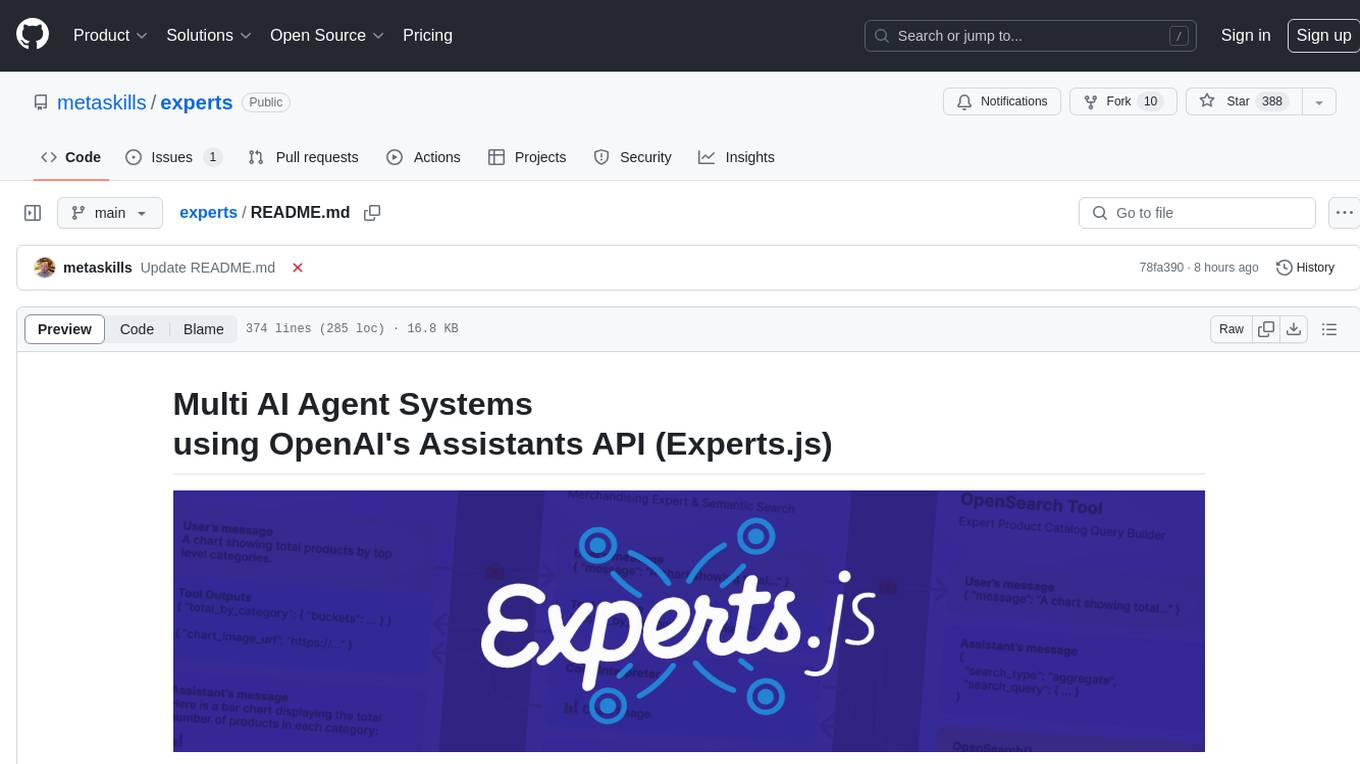
Experts.js is a tool that simplifies the creation and deployment of OpenAI's Assistants, allowing users to link them together as Tools to create a Panel of Experts system with expanded memory and attention to detail. It leverages the new Assistants API from OpenAI, which offers advanced features such as referencing attached files & images as knowledge sources, supporting instructions up to 256,000 characters, integrating with 128 tools, and utilizing the Vector Store API for efficient file search. Experts.js introduces Assistants as Tools, enabling the creation of Multi AI Agent Systems where each Tool is an LLM-backed Assistant that can take on specialized roles or fulfill complex tasks.
README:

![]()
![]()
Experts.js is the easiest way to create and deploy OpenAI's Assistants and link them together as Tools to create a Panel of Experts system with expanded memory and attention to detail.
Made via support ❤️ by Custom Ink | Tech
The new Assistants API from OpenAI sets a new industry standard, significantly advancing beyond the widely adopted Chat Completions API. It represents a major leap in the usability of AI agents and the way engineers interact with LLMs. Paired with the cutting-edge GPT-4o mini model, Assistants can now reference attached files & images as knowledge sources within a managed context window called a Thread. Unlike Custom GPTs, Assistants support instructions up to 256,000 characters, integrate with 128 tools, and utilize the innovative Vector Store API for efficient file search on up to 10,000 files per assistant.
Experts.js aims to simplify the usage of this new API by removing the complexity of managing Run objects and allowing Assistants to be linked together as Tools.
import { Assistant, Thread } from "experts";
const thread = await Thread.create();
const assistant = await Assistant.create();
const output = await assistant.ask("Say hello.", thread.id);
console.log(output) // HelloMore importantly, Experts.js introduces Assistants as Tools, enabling the creation of Multi AI Agent Systems. Each Tool is an LLM-backed Assistant that can take on specialized roles or fulfill complex tasks on behalf of their parent Assistant or Tool. Allowing for complex orchestration workflows or choreographing a series of tightly knit tasks. Shown here is an example of a company assistant with a product catalog tool which itself has a LLM backed tool to create OpenSearch queries.

Install via npm. Usage is very simple, there are only three objects to import.
npm install expertsExperts.js supports both ES6 import syntax and CommonJS require statements.
import { Assistant, Tool, Thread } from "experts";- Assistants - The main object that represents an AI agent.
- Tools - An Assistant that can be used by other Assistants.
- Threads - A managed context window for your agents.
The constructor of our Assistant facade object requires a name, description, and instructions. The third argument is a set of options which directly maps to all the request body options outlined in the create assistant documentation. All examples in Experts.js are written in ES6 classes for simplicity. The default model is gpt-4o-mini.
class MyAssistant extends Assistant {
constructor() {
super({
name: "My Assistant",
instructions: "...",
model: "gpt-4o-mini",
tools: [{ type: "file_search" }],
temperature: 0.1,
tool_resources: {
file_search: {
vector_store_ids: [process.env.VECTOR_STORE_ID],
},
},
});
}
}
const assistant = await MyAssistant.create();The Experts.js async Assistant.create() base factory function is a simple way to create an assistant using the same constructor options.
const assistant = Assistant.create({
name: "My Assistant",
instructions: "...",
model: "gpt-4o-mini",
});[!IMPORTANT]
Creating assistants without anidparameter will always create a new assistant. See our deployment section for more information.
The ask() function is a simple interface to ask or instruct your assistant(s). It requires a message and a thread identifier. More on Threads below. The message can be a string or native OpenAI message object. This is where Experts.js really shines. You never have to manage Run objects or their Run Steps directly.
const output = await assistant.ask("...", threadID)
const output = await assistant.ask({ role: "user", content: "..." }, threadID);Normal OpenAI tools and function calling are supported via our constructors options object via tools and tool_resources. Experts.js also supports adding Assistants as Tools. More information on using Assistants as Tools can be found in the next section. Use the addAssistantTool function to add an Assistant as a Tool. This must happen after super() in your Assistant's constructor.
class MainAssistant extends Assistant {
constructor() {
super({
name: "Company Assistant",
instructions: "...",
});
this.addAssistantTool(ProductsTools);
}
}By default, Experts.js leverages the Assistants Streaming Events. These allow your applications to receive text, image, and tool outputs via OpenAI's server-send events. We leverage openai-node's stream helpers and surface these events along with a few custom ones giving your assistants to tap into the complete lifecycle of a Run.
const assistant = await MainAssistant.create();
assistant.on("textDelta", (delta, _snapshot) => {
process.stdout.write(delta.value)
});All openai-node streaming events are supported via our Assistant's on() function. The available event names are: event, textDelta, textDone, imageFileDone, toolCallDelta, runStepDone, toolCallDone, and end
[!IMPORTANT]
OpenAI's server-send events are not async/await friendly.
If your listeners need to perform work in an async fashion, such as redirecting tool outputs, consider using our extensions to these events. They are called in this order after the Run has been completed. The available async event names are: textDoneAsync, imageFileDoneAsync, runStepDoneAsync, toolCallDoneAsync, and endAsync.
If you want to lazily standup additional resources when an assistant's create() function is called, implement the beforeInit() function in your class. This is an async method that will be called before the assistant is created.
async beforeInit() {
await this.#createFileSearch();
}Likewise, the afterInit() function can be used. For example, to write out newly created Assistants' IDs to an environment file.
async afterInit() {
// ...
}All Assistant events receive an extra Experts'js metadata argument. An object that contains the Run's stream. This allows you to use the openai-node's helper functions such as currentEvent, finalMessages, etc.
assistant.on("endAsync", async (metadata) => {
await metadata.stream.finalMessages();
});Using an Assistant as a Tool is central focal point of the Experts.js framework. Tools are a subclass of Assistant and encapsulate the interface for their parent objects. In this way Experts.js tools are reusable components in your agentic architecture. Our examples illustrate a basic message passing pattern, for brevity. You should leverage all of OpenAI's tool and function calling features to their fullest.
class EchoTool extends Tool {
constructor() {
super({
name: "Echo Tool",
instructions: "Echo the same text back to the user",
parentsTools: [
{
type: "function",
function: {
name: "echo",
description: description,
parameters: {
type: "object",
properties: { message: { type: "string" } },
required: ["message"],
},
},
},
],
});
}
}[!CAUTION] It is critical that your tool's function name be unique across its parent's entire set of tool names.
As such, Tool class names are important and help OpenAI's models decide which tool to call. So pick a good name for your tool class. For example, ProductsOpenSearchTool will be products_open_search and clearly helps the model infer along with the tool's description what role it performs.
Tools are added to your Assistant via the addAssistantTool function. This function will add the tool to the assistant's tools array and update the assistant's configuration. This must happen after super() in your Assistant's constructor.
class MainAssistant extends Assistant {
constructor() {
super({
name: "Company Assistant",
instructions: "..."
});
this.addAssistantTool(EchoTool);
}
}Your Tool assistant response will automatically be submitted as the output for the parent Assistant or Tool.
By default Tools are backed by an LLM model and perform all the same lifecycles events, runs, etc as Assistants. However, you can create a Tool that does not use any of the core Assistant's features by setting the llm option to false. When doing so, you must implement the ask() function in your Tool. The return value will be submitted as the tool's output.
class AnswerTwoTool extends Tool {
constructor() {
super({
// ...
llm: false,
parentsTools: [...],
});
}
async ask(message) {
return ...;
}
}In complex workflows, a LLM backed Tool can be used to convert human or other LLM instructions into executable code and the result of that code (not the LLM output) would need to be submitted for your Tool's parent's outputs. For example, the ProductsOpenSearchTool could convert messages into OpenSearch queries, execute them, and return the results. Sub classes can implement the answered() function to control the output. In this case, the output would be an OpenSearch query and the tools outputs now contain the results of that LLM-generated query.
async answered(output) {
const args = JSON.parse(output);
return await this.opensearchQuery(args);
}Alternatively, LLM backed Tools could opt to redirect their own tool outputs back to their parent Assistant or Tool. Thus ignoring the LLM output. This also allows for all of a Tools tool outputs to be submitted as the parent's output. More on why this is important in the product catalog example below.
class ProductsTool extends Tool {
constructor() {
super({
// ...
temperature: 0.1,
tools: [{ type: "code_interpreter" }],
outputs: "tools",
parentsTools: [...],
});
this.addAssistantTool(ProductsOpenSearchTool);
this.on("imageFileDoneAsync", this.imageFileDoneAsync.bind(this));
}
}OpenAI's Assistants API introduces a new resource called Threads which messages & files are stored within. Essentially, threads are a managed context window (memory) for your agents. Creating a new thread with Experts.js is as easy as:
const thread = await Thread.create();
console.log(thread.id) // thread_abc123You can also create a thread with messages, files, or tool resources to start a conversation. We support OpenAI's thread create request body outlined in their Threads API reference.
const thread = await Thread.create({
messages: [
{ role: "user", content: "My name is Ken" },
{ role: "user", content: "Oh, my last name is Collins" },
],
});
const output = await assistant.ask("What is my full name?", thread.id);
console.log(output) // Ken CollinsBy default, each Tool in Experts.js has its own thread & context. This avoids a potential thread locking issue which happens if a Tool were to share an Assistant's thread still waiting for tool outputs to be submitted. The following diagram illustrates how Experts.js manages threads on your behalf to avoid this problem:

All questions to your experts require a thread ID. For chat applications, the ID would be stored on the client. Such as a URL path parameter. With Expert.js, no other client-side IDs are needed. As each Assistant calls an LLM backed Tool, it will find or create a thread for that tool as needed. Experts.js stores this parent -> child thread relationship for you using OpenAI's thread metadata.
Runs are managed for you behind the Assistant's ask function. However, you can still pass options that will be used when creating a Run in one of two ways.
First, you can specify run_options in the Assistant's constructor. These options will be used for all Runs created by the Assistant. This is a great way to force the model to use a tool via the tool_choice option.
class CarpenterAssistant extends Assistant {
constructor() {
super({
// ...
run_options: {
tool_choice: {
type: "function",
function: { name: "my_tool_name" },
},
},
});
this.addAssistantTool(MyTool);
}
}Alternatively, you can pass an options object to the ask method to be used for the current Run. This is a great way to create single Run options.
await assistant.ask("...", "thread_abc123", {
run: {
tool_choice: { type: "function", function: { name: "my_tool_name" } },
additional_instructions: "...",
additional_messages: [...],
},
});To see code examples of these and more in action, please take a look at our test suite.
In the Overview section we showed a three-tiered agent system that can answer the following types of questions. The examples uses most, if not all, the features of the Experts.js framework.
- What is the total amount of products available?
- Show me a bar chart image with totals of all top level categories.
- Find men's accessories for a sophisticated comic book enthusiast.
Basic example using the textDelta event to stream responses from an Express route.
import express from "express";
import { MainAssistant } from "../experts/main.js";
const assistant = await MainAssistant.create();
messagesRouter.post("", async (req, res, next) => {
res.setHeader("Content-Type", "text/plain");
res.setHeader("Transfer-Encoding", "chunked");
assistant.on("textDelta", (delta, _snapshot) => {
res.write(delta.value);
});
await assistant.ask(req.body.message.content, req.body.threadID);
res.end();
});The Assistant's API supports messages with images using either the image_url or image_file content types. Since our ask() function supports strings or native OpenAI message objects.
const output = await assistant.ask(
{
role: "user",
content: [
{ type: "text", text: "Tell me about this image." },
{ type: "image_file", image_file: { file_id: file.id detail: "high" } },
],
},
threadID
);Using a Vector Store for file search is easy using OpenAI's interface via our third configuration option. You could alternatively create your vector store on-demand using our beforeInit() function described in Advanced Features.
class VectorSearchAssistant extends Assistant {
constructor() {
super({
name: "Vector Search Assistant",
instructions: "...",
tools: [{ type: "file_search" }],
temperature: 0.1,
tool_resources: {
file_search: {
vector_store_ids: [process.env.VECTOR_STORE_ID],
},
},
});
}
}Using the Streaming & Events feature to report token usage allows you to have per-assistant metrics.
class MyAssistant extends Assistant {
constructor() {
super({
// ...
});
this.on("runStepDone", this.#reportUsage.bind(this));
}
#reportUsage(runStep) {
if (!runStep?.usage?.total_tokens) return;
const iT = runStep.usage.prompt_tokens;
const oT = runStep.usage.completion_tokens;
const tT = runStep.usage.total_tokens;
console.log({ InTokens: iT, OutTokens: oT, TotalTokens: tT });
}
}In order for an Assistant to be deployed to a production environment, we recommend the following configurations. First, create or find your assistant's id. The string will be in the format of asst_abc123. Then pass this id into the Assistant's or Tools's constructor. This will ensure that the same assistant is used across all deployments.
class MyAssistant extends Assistant {
constructor() {
super({
// ...
id: process.env.MY_ASSISTANT_ID
});
}
}Once an Assistant or Tool is found by id, any remote configurations that are different present are overwritten by the local configurations. If required, for example in a staging environment, you can bypass this behavior by setting the skipUpdate option to true.
You can globally set the model for all Assistants using the EXPERTS_DEFAULT_MODEL environment variable. This only works if you have not explicitly set the model in your Assistant's constructor.
To debug your assistant, you can set the DEBUG=1 environment variable. This will output verbose logging of all API calls and server-send events. Delta events can be somewhat verbose and are disabled by default. Please also use the DEBUG_DELTAS=1 environment variable to turn those on.
This project leverages Dev Containers meaning you can open it in any supporting IDE to get started right away. This includes using VS Code with Dev Containers which is the recommended approach.
Once opened in your development container, create a .env.development.local file with your OpenAI API key and postimage.org API key:
OPENAI_API_KEY=sk-...
POST_IMAGES_API_KEY=...
Now you can run the following commands:
./bin/setup
./bin/testFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for experts
Similar Open Source Tools
experts
Experts.js is a tool that simplifies the creation and deployment of OpenAI's Assistants, allowing users to link them together as Tools to create a Panel of Experts system with expanded memory and attention to detail. It leverages the new Assistants API from OpenAI, which offers advanced features such as referencing attached files & images as knowledge sources, supporting instructions up to 256,000 characters, integrating with 128 tools, and utilizing the Vector Store API for efficient file search. Experts.js introduces Assistants as Tools, enabling the creation of Multi AI Agent Systems where each Tool is an LLM-backed Assistant that can take on specialized roles or fulfill complex tasks.

ActionWeaver
ActionWeaver is an AI application framework designed for simplicity, relying on OpenAI and Pydantic. It supports both OpenAI API and Azure OpenAI service. The framework allows for function calling as a core feature, extensibility to integrate any Python code, function orchestration for building complex call hierarchies, and telemetry and observability integration. Users can easily install ActionWeaver using pip and leverage its capabilities to create, invoke, and orchestrate actions with the language model. The framework also provides structured extraction using Pydantic models and allows for exception handling customization. Contributions to the project are welcome, and users are encouraged to cite ActionWeaver if found useful.

py-vectara-agentic
The `vectara-agentic` Python library is designed for developing powerful AI assistants using Vectara and Agentic-RAG. It supports various agent types, includes pre-built tools for domains like finance and legal, and enables easy creation of custom AI assistants and agents. The library provides tools for summarizing text, rephrasing text, legal tasks like summarizing legal text and critiquing as a judge, financial tasks like analyzing balance sheets and income statements, and database tools for inspecting and querying databases. It also supports observability via LlamaIndex and Arize Phoenix integration.
agent-mimir
Agent Mimir is a command line and Discord chat client 'agent' manager for LLM's like Chat-GPT that provides the models with access to tooling and a framework with which accomplish multi-step tasks. It is easy to configure your own agent with a custom personality or profession as well as enabling access to all tools that are compatible with LangchainJS. Agent Mimir is based on LangchainJS, every tool or LLM that works on Langchain should also work with Mimir. The tasking system is based on Auto-GPT and BabyAGI where the agent needs to come up with a plan, iterate over its steps and review as it completes the task.

axar
AXAR AI is a lightweight framework designed for building production-ready agentic applications using TypeScript. It aims to simplify the process of creating robust, production-grade LLM-powered apps by focusing on familiar coding practices without unnecessary abstractions or steep learning curves. The framework provides structured, typed inputs and outputs, familiar and intuitive patterns like dependency injection and decorators, explicit control over agent behavior, real-time logging and monitoring tools, minimalistic design with little overhead, model agnostic compatibility with various AI models, and streamed outputs for fast and accurate results. AXAR AI is ideal for developers working on real-world AI applications who want a tool that gets out of the way and allows them to focus on shipping reliable software.
Tools4AI
Tools4AI is a Java-based Agentic Framework for building AI agents to integrate with enterprise Java applications. It enables the conversion of natural language prompts into actionable behaviors, streamlining user interactions with complex systems. By leveraging AI capabilities, it enhances productivity and innovation across diverse applications. The framework allows for seamless integration of AI with various systems, such as customer service applications, to interpret user requests, trigger actions, and streamline workflows. Prompt prediction anticipates user actions based on input prompts, enhancing user experience by proactively suggesting relevant actions or services based on context.

cortex
Cortex is a tool that simplifies and accelerates the process of creating applications utilizing modern AI models like chatGPT and GPT-4. It provides a structured interface (GraphQL or REST) to a prompt execution environment, enabling complex augmented prompting and abstracting away model connection complexities like input chunking, rate limiting, output formatting, caching, and error handling. Cortex offers a solution to challenges faced when using AI models, providing a simple package for interacting with NL AI models.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.

airflow-ai-sdk
This repository contains an SDK for working with LLMs from Apache Airflow, based on Pydantic AI. It allows users to call LLMs and orchestrate agent calls directly within their Airflow pipelines using decorator-based tasks. The SDK leverages the familiar Airflow `@task` syntax with extensions like `@task.llm`, `@task.llm_branch`, and `@task.agent`. Users can define tasks that call language models, orchestrate multi-step AI reasoning, change the control flow of a DAG based on LLM output, and support various models in the Pydantic AI library. The SDK is designed to integrate LLM workflows into Airflow pipelines, from simple LLM calls to complex agentic workflows.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.

ash_ai
Ash AI is a tool that provides a Model Context Protocol (MCP) server for exposing tool definitions to an MCP client. It allows for the installation of dev and production MCP servers, and supports features like OAuth2 flow with AshAuthentication, tool data access, tool execution callbacks, prompt-backed actions, and vectorization strategies. Users can also generate a chat feature for their Ash & Phoenix application using `ash_oban` and `ash_postgres`, and specify LLM API keys for OpenAI. The tool is designed to help developers experiment with tools and actions, monitor tool execution, and expose actions as tool calls.

npcsh
`npcsh` is a python-based command-line tool designed to integrate Large Language Models (LLMs) and Agents into one's daily workflow by making them available and easily configurable through the command line shell. It leverages the power of LLMs to understand natural language commands and questions, execute tasks, answer queries, and provide relevant information from local files and the web. Users can also build their own tools and call them like macros from the shell. `npcsh` allows users to take advantage of agents (i.e. NPCs) through a managed system, tailoring NPCs to specific tasks and workflows. The tool is extensible with Python, providing useful functions for interacting with LLMs, including explicit coverage for popular providers like ollama, anthropic, openai, gemini, deepseek, and openai-like providers. Users can set up a flask server to expose their NPC team for use as a backend service, run SQL models defined in their project, execute assembly lines, and verify the integrity of their NPC team's interrelations. Users can execute bash commands directly, use favorite command-line tools like VIM, Emacs, ipython, sqlite3, git, pipe the output of these commands to LLMs, or pass LLM results to bash commands.
crb
CRB (Composable Runtime Blocks) is a unique framework that implements hybrid workloads by seamlessly combining synchronous and asynchronous activities, state machines, routines, the actor model, and supervisors. It is ideal for building massive applications and serves as a low-level framework for creating custom frameworks, such as AI-agents. The core idea is to ensure high compatibility among all blocks, enabling significant code reuse. The framework allows for the implementation of algorithms with complex branching, making it suitable for building large-scale applications or implementing complex workflows, such as AI pipelines. It provides flexibility in defining structures, implementing traits, and managing execution flow, allowing users to create robust and nonlinear algorithms easily.
LLMUnity
LLM for Unity enables seamless integration of Large Language Models (LLMs) within the Unity engine, allowing users to create intelligent characters for immersive player interactions. The tool supports major LLM models, runs locally without internet access, offers fast inference on CPU and GPU, and is easy to set up with a single line of code. It is free for both personal and commercial use, tested on Unity 2021 LTS, 2022 LTS, and 2023. Users can build multiple AI characters efficiently, use remote servers for processing, and customize model settings for text generation.
auto-playwright
Auto Playwright is a tool that allows users to run Playwright tests using AI. It eliminates the need for selectors by determining actions at runtime based on plain-text instructions. Users can automate complex scenarios, write tests concurrently with or before functionality development, and benefit from rapid test creation. The tool supports various Playwright actions and offers additional options for debugging and customization. It uses HTML sanitization to reduce costs and improve text quality when interacting with the OpenAI API.
For similar tasks
experts
Experts.js is a tool that simplifies the creation and deployment of OpenAI's Assistants, allowing users to link them together as Tools to create a Panel of Experts system with expanded memory and attention to detail. It leverages the new Assistants API from OpenAI, which offers advanced features such as referencing attached files & images as knowledge sources, supporting instructions up to 256,000 characters, integrating with 128 tools, and utilizing the Vector Store API for efficient file search. Experts.js introduces Assistants as Tools, enabling the creation of Multi AI Agent Systems where each Tool is an LLM-backed Assistant that can take on specialized roles or fulfill complex tasks.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
cherry-studio
Cherry Studio is a desktop client that supports multiple Large Language Model (LLM) providers, available on Windows, Mac, and Linux. It allows users to create multiple Assistants and topics, use multiple models to answer questions in the same conversation, and supports drag-and-drop sorting, code highlighting, and Mermaid chart. The tool is designed to enhance productivity and streamline the process of interacting with various language models.
com.openai.unity
com.openai.unity is an OpenAI package for Unity that allows users to interact with OpenAI's API through RESTful requests. It is independently developed and not an official library affiliated with OpenAI. Users can fine-tune models, create assistants, chat completions, and more. The package requires Unity 2021.3 LTS or higher and can be installed via Unity Package Manager or Git URL. Various features like authentication, Azure OpenAI integration, model management, thread creation, chat completions, audio processing, image generation, file management, fine-tuning, batch processing, embeddings, and content moderation are available.
llmchat
LLMChat is an all-in-one AI chat interface that supports multiple language models, offers a plugin library for enhanced functionality, enables web search capabilities, allows customization of AI assistants, provides text-to-speech conversion, ensures secure local data storage, and facilitates data import/export. It also includes features like knowledge spaces, prompt library, personalization, and can be installed as a Progressive Web App (PWA). The tech stack includes Next.js, TypeScript, Pglite, LangChain, Zustand, React Query, Supabase, Tailwind CSS, Framer Motion, Shadcn, and Tiptap. The roadmap includes upcoming features like speech-to-text and knowledge spaces.
kelivo
Kelivo is a Flutter LLM Chat Client with modern design, dark mode, multi-language support, multi-provider support, custom assistants, multimodal input, markdown rendering, voice functionality, MCP support, web search integration, prompt variables, QR code sharing, data backup, and custom requests. It is built with Flutter and Dart, utilizes Provider for state management, Hive for local data storage, and supports dynamic theming and Markdown rendering. Kelivo is a versatile tool for creating and managing personalized AI assistants, supporting various input formats, and integrating with multiple search engines and AI providers.
airavata
Apache Airavata is a software framework for executing and managing computational jobs on distributed computing resources. It supports local clusters, supercomputers, national grids, academic and commercial clouds. Airavata utilizes service-oriented computing, distributed messaging, and workflow composition. It includes a server package with an API, client SDKs, and a general-purpose UI implementation called Apache Airavata Django Portal.
GenAIComps
GenAIComps is an initiative aimed at building enterprise-grade Generative AI applications using a microservice architecture. It simplifies the scaling and deployment process for production, abstracting away infrastructure complexities. GenAIComps provides a suite of containerized microservices that can be assembled into a mega-service tailored for real-world Enterprise AI applications. The modular approach of microservices allows for independent development, deployment, and scaling of individual components, promoting modularity, flexibility, and scalability. The mega-service orchestrates multiple microservices to deliver comprehensive solutions, encapsulating complex business logic and workflow orchestration. The gateway serves as the interface for users to access the mega-service, providing customized access based on user requirements.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.