
semantic-cache
A fuzzy key value store based on semantic similarity rather lexical equality.
Stars: 171
Semantic Cache is a tool for caching natural text based on semantic similarity. It allows for classifying text into categories, caching AI responses, and reducing API latency by responding to similar queries with cached values. The tool stores cache entries by meaning, handles synonyms, supports multiple languages, understands complex queries, and offers easy integration with Node.js applications. Users can set a custom proximity threshold for filtering results. The tool is ideal for tasks involving querying or retrieving information based on meaning, such as natural language classification or caching AI responses.
README:
[!NOTE]
This project is in the Experimental Stage.We declare this project experimental to set clear expectations for your usage. There could be known or unknown bugs, the API could evolve, or the project could be discontinued if it does not find community adoption. While we cannot provide professional support for experimental projects, we’d be happy to hear from you if you see value in this project!
Semantic Cache is a tool for caching natural text based on semantic similarity. It's ideal for any task that involves querying or retrieving information based on meaning, such as natural language classification or caching AI responses. Two pieces of text can be similar but not identical (e.g., "great places to check out in Spain" vs. "best places to visit in Spain"). Traditional caching doesn't recognize this semantic similarity and misses opportunities for reuse.
Semantic Cache allows you to:
- Easily classify natural text into predefined categories
- Avoid redundant LLM work by caching AI responses
- Reduce API latency by responding to similar queries with already cached values

- Uses semantic similarity: Stores cache entries by their meaning, not just the literal characters
- Handles synonyms: Recognizes and handles synonyms
- Multi-language support: Works across different languages (if configured with multilingual vector models)
- Complex query support: Understands long and nested user queries
- Easy integration: Simple API for usage in Node.js applications
- Customizable: Set a custom proximity threshold to filter out less relevant results
- An Upstash Vector database (create one here)
Install the package:
npm install @upstash/semantic-cache @upstash/vectorFirst, create an Upstash Vector database here. You'll need the url and token credentials to connect your semantic cache. Important: Choose any pre-made embedding model when creating your database.
[!NOTE]
Different embedding models are great for different use cases. For example, if low latency is a priority, choose a model with a smaller dimension size likebge-small-en-v1.5. If accuracy is important, choose a model with more dimensions.
Create a .env file in the root directory of your project and add your Upstash Vector URL and token:
UPSTASH_VECTOR_REST_URL=https://example.upstash.io
UPSTASH_VECTOR_REST_TOKEN=your_secret_token_here
Here’s how you can use Semantic Cache in your Node.js application:
import { SemanticCache } from "@upstash/semantic-cache";
import { Index } from "@upstash/vector";
// 👇 your vector database
const index = new Index();
// 👇 your semantic cache
const semanticCache = new SemanticCache({ index, minProximity: 0.95 });
async function runDemo() {
await semanticCache.set("Capital of Turkey", "Ankara");
await delay(1000);
// 👇 outputs: "Ankara"
const result = await semanticCache.get("What is Turkey's capital?");
console.log(result);
}
function delay(ms: number) {
return new Promise((resolve) => setTimeout(resolve, ms));
}
runDemo();The minProximity parameter ranges from 0 to 1. It lets you define the minimum relevance score to determine a cache hit. The higher this number, the more similar your user input must be to the cached content to be a hit. In practice, a score of 0.95 indicates a very high similarity, while a score of 0.75 already indicates a low similarity. For example, a value of 1.00, the highest possible, would only accept an exact match of your user query and cache content as a cache hit.
You can seperate your data into partitions with namespaces.
import { SemanticCache } from "@upstash/semantic-cache";
import { Index } from "@upstash/vector";
// 👇 your vector database
const index = new Index();
// 👇 your semantic cache
const semanticCache = new SemanticCache({ index, minProximity: 0.95, namespace: "user1" });
await semanticCache.set("Capital of Turkey", "Ankara");The following examples demonstrate how you can utilize Semantic Cache in various use cases:
[!NOTE]
We add a 1-second delay after setting the data to allow time for the vector index to update. This delay is necessary to ensure that the data is available for retrieval.
await semanticCache.set("Capital of France", "Paris");
await delay(1000);
// 👇 outputs "Paris"
const result = await semanticCache.get("What's the capital of France?");await semanticCache.set("largest city in USA by population", "New York");
await delay(1000);
// 👇 outputs "New York"
const result = await semanticCache.get("which is the most populated city in the USA?");Note: Your embedding model needs to support the languages you intend to use.
await semanticCache.set("German Chancellor", "Olaf Scholz");
await delay(1000);
// 👇 "Who is the chancellor of Germany?" -> outputs "Olaf Scholz"
const result = await semanticCache.get("Wer ist der Bundeskanzler von Deutschland?");await semanticCache.set("year in which the Berlin wall fell", "1989");
await delay(1000);
// 👇 outputs "1989"
const result = await semanticCache.get("what's the year the Berlin wall destroyed?");await semanticCache.set("the chemical formula for water", "H2O");
await semanticCache.set("the healthiest drink on a hot day", "water");
await delay(1000);
// 👇 outputs "water"
const result = await semanticCache.get("what should i drink when it's hot outside?");
// 👇 outputs "H2O"
const result = await semanticCache.get("tell me water's chemical formula");We appreciate your contributions! If you'd like to contribute to this project, please fork the repository, make your changes, and submit a pull request.
Distributed under the MIT License. See LICENSE for more information.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for semantic-cache
Similar Open Source Tools
semantic-cache
Semantic Cache is a tool for caching natural text based on semantic similarity. It allows for classifying text into categories, caching AI responses, and reducing API latency by responding to similar queries with cached values. The tool stores cache entries by meaning, handles synonyms, supports multiple languages, understands complex queries, and offers easy integration with Node.js applications. Users can set a custom proximity threshold for filtering results. The tool is ideal for tasks involving querying or retrieving information based on meaning, such as natural language classification or caching AI responses.

cortex
Cortex is a tool that simplifies and accelerates the process of creating applications utilizing modern AI models like chatGPT and GPT-4. It provides a structured interface (GraphQL or REST) to a prompt execution environment, enabling complex augmented prompting and abstracting away model connection complexities like input chunking, rate limiting, output formatting, caching, and error handling. Cortex offers a solution to challenges faced when using AI models, providing a simple package for interacting with NL AI models.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.

azure-functions-openai-extension
Azure Functions OpenAI Extension is a project that adds support for OpenAI LLM (GPT-3.5-turbo, GPT-4) bindings in Azure Functions. It provides NuGet packages for various functionalities like text completions, chat completions, assistants, embeddings generators, and semantic search. The project requires .NET 6 SDK or greater, Azure Functions Core Tools v4.x, and specific settings in Azure Function or local settings for development. It offers features like text completions, chat completion, assistants with custom skills, embeddings generators for text relatedness, and semantic search using vector databases. The project also includes examples in C# and Python for different functionalities.

siftrank
siftrank is an implementation of the Sift Rank document ranking algorithm that uses Large Language Models (LLMs) to efficiently find the most relevant items in any dataset based on a given prompt. It addresses issues like non-determinism, limited context, output constraints, and scoring subjectivity encountered when using LLMs directly. siftrank allows users to rank anything without fine-tuning or domain-specific models, running in seconds and costing pennies. It supports JSON input, Go template syntax for customization, and various advanced options for configuration and optimization.

instructor-js
Instructor is a Typescript library for structured extraction in Typescript, powered by llms, designed for simplicity, transparency, and control. It stands out for its simplicity, transparency, and user-centric design. Whether you're a seasoned developer or just starting out, you'll find Instructor's approach intuitive and steerable.

invariant
Invariant Analyzer is an open-source scanner designed for LLM-based AI agents to find bugs, vulnerabilities, and security threats. It scans agent execution traces to identify issues like looping behavior, data leaks, prompt injections, and unsafe code execution. The tool offers a library of built-in checkers, an expressive policy language, data flow analysis, real-time monitoring, and extensible architecture for custom checkers. It helps developers debug AI agents, scan for security violations, and prevent security issues and data breaches during runtime. The analyzer leverages deep contextual understanding and a purpose-built rule matching engine for security policy enforcement.
agentlang
AgentLang is an open-source programming language and framework designed for solving complex tasks with the help of AI agents. It allows users to build business applications rapidly from high-level specifications, making it more efficient than traditional programming languages. The language is data-oriented and declarative, with a syntax that is intuitive and closer to natural languages. AgentLang introduces innovative concepts such as first-class AI agents, graph-based hierarchical data model, zero-trust programming, declarative dataflow, resolvers, interceptors, and entity-graph-database mapping.
redisvl
Redis Vector Library (RedisVL) is a Python client library for building AI applications on top of Redis. It provides a high-level interface for managing vector indexes, performing vector search, and integrating with popular embedding models and providers. RedisVL is designed to make it easy for developers to build and deploy AI applications that leverage the speed, flexibility, and reliability of Redis.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

bedrock-claude-chat
This repository is a sample chatbot using the Anthropic company's LLM Claude, one of the foundational models provided by Amazon Bedrock for generative AI. It allows users to have basic conversations with the chatbot, personalize it with their own instructions and external knowledge, and analyze usage for each user/bot on the administrator dashboard. The chatbot supports various languages, including English, Japanese, Korean, Chinese, French, German, and Spanish. Deployment is straightforward and can be done via the command line or by using AWS CDK. The architecture is built on AWS managed services, eliminating the need for infrastructure management and ensuring scalability, reliability, and security.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

ActionWeaver
ActionWeaver is an AI application framework designed for simplicity, relying on OpenAI and Pydantic. It supports both OpenAI API and Azure OpenAI service. The framework allows for function calling as a core feature, extensibility to integrate any Python code, function orchestration for building complex call hierarchies, and telemetry and observability integration. Users can easily install ActionWeaver using pip and leverage its capabilities to create, invoke, and orchestrate actions with the language model. The framework also provides structured extraction using Pydantic models and allows for exception handling customization. Contributions to the project are welcome, and users are encouraged to cite ActionWeaver if found useful.
langgraph4j
Langgraph4j is a Java library for language processing tasks such as text classification, sentiment analysis, and named entity recognition. It provides a set of tools and algorithms for analyzing text data and extracting useful information. The library is designed to be efficient and easy to use, making it suitable for both research and production applications.

axar
AXAR AI is a lightweight framework designed for building production-ready agentic applications using TypeScript. It aims to simplify the process of creating robust, production-grade LLM-powered apps by focusing on familiar coding practices without unnecessary abstractions or steep learning curves. The framework provides structured, typed inputs and outputs, familiar and intuitive patterns like dependency injection and decorators, explicit control over agent behavior, real-time logging and monitoring tools, minimalistic design with little overhead, model agnostic compatibility with various AI models, and streamed outputs for fast and accurate results. AXAR AI is ideal for developers working on real-world AI applications who want a tool that gets out of the way and allows them to focus on shipping reliable software.
For similar tasks
semantic-cache
Semantic Cache is a tool for caching natural text based on semantic similarity. It allows for classifying text into categories, caching AI responses, and reducing API latency by responding to similar queries with cached values. The tool stores cache entries by meaning, handles synonyms, supports multiple languages, understands complex queries, and offers easy integration with Node.js applications. Users can set a custom proximity threshold for filtering results. The tool is ideal for tasks involving querying or retrieving information based on meaning, such as natural language classification or caching AI responses.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
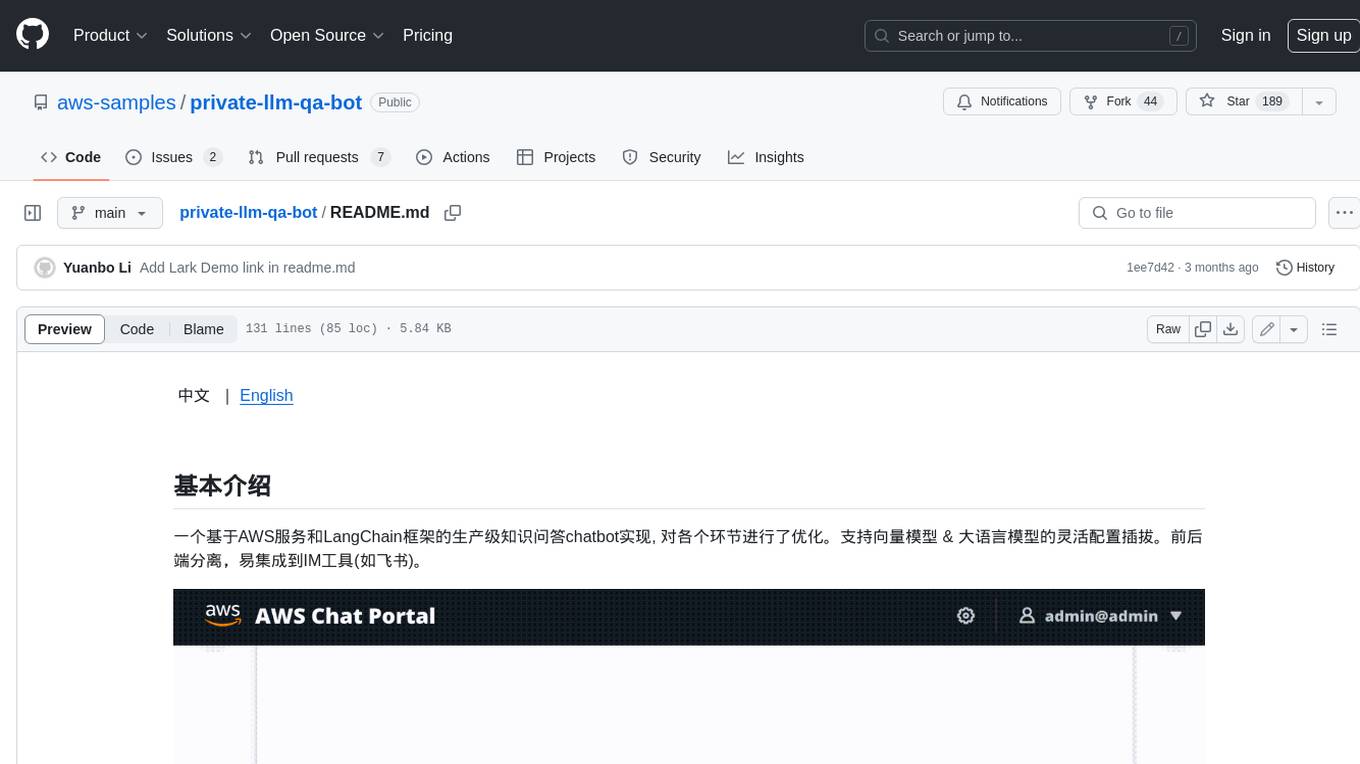
private-llm-qa-bot
This is a production-grade knowledge Q&A chatbot implementation based on AWS services and the LangChain framework, with optimizations at various stages. It supports flexible configuration and plugging of vector models and large language models. The front and back ends are separated, making it easy to integrate with IM tools (such as Feishu).

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.