
langchain-decorators
syntactic sugar 🍭 for langchain
Stars: 234
LangChain Decorators is a layer on top of LangChain that provides syntactic sugar for writing custom langchain prompts and chains. It offers a more pythonic way of writing code, multiline prompts without breaking code flow, IDE support for hinting and type checking, leveraging LangChain ecosystem, support for optional parameters, and sharing parameters between prompts. It simplifies streaming, automatic LLM selection, defining custom settings, debugging, and passing memory, callback, stop, etc. It also provides functions provider, dynamic function schemas, binding prompts to objects, defining custom settings, and debugging options. The project aims to enhance the LangChain library by making it easier to use and more efficient for writing custom prompts and chains.
README:
LangChain Decorators is a lightweight layer built on top of LangChain that provides syntactic sugar 🍭 for writing custom prompts and chains.
Note: This is an unofficial add-on to the LangChain library. It is not trying to compete—just to make using it easier. Many ideas here are opinionated.
Here is a simple example using LangChain Decorators ✨:
@llm_prompt
def write_me_short_post(topic: str, platform: str = "twitter", audience: str = "developers") -> str:
"""
Write a short header for my post about {topic} for the {platform} platform.
It should be for a {audience} audience.
(Max 15 words)
"""
return
# Run it naturally
write_me_short_post(topic="starwars")
# or
write_me_short_post(topic="starwars", platform="reddit")Main principles and benefits:
- A more Pythonic way to write prompts
- Write multi-line prompts without breaking your code’s indentation
- Leverage IDE support for hints, type checking, and doc popups to quickly see prompts and parameters
- Keep the power of the 🦜🔗 LangChain ecosystem
- Add support for optional parameters
- Easily share parameters between prompts by binding them to a class
Binding the prompt to an object
pip install langchain_decoratorsA good way to start is to review the examples here:
Define a prompt by creating a function with arguments as inputs and the function docstring as the prompt template:
@llm_prompt
def write_me_short_post(topic: str, platform: str = "twitter", audience: str = "developers"):
"""
Write a short header for my post about {topic} for the {platform} platform.
It should be for a {audience} audience.
(Max 15 words)
"""This default declaration is translated into a chat with a single user message.
If you want to define a prompt with multiple messages (common for chat models), add special code blocks inside the function docstring:
@llm_prompt
def write_me_short_post(topic: str, platform: str = "twitter", audience: str = "developers"):
"""
```<prompt:system>
You are a social media manager.
```
```<prompt:user>
Write a short header for my post about {topic} for the {platform} platform.
It should be for a {audience} audience.
(Max 15 words)
```
```<prompt:assistant>
I need to think about it.
```
"""The pattern is a series of consecutive code blocks with a “language” tag in this format: <prompt:[message-role]>.
You can specify which part of your docstring is the prompt by using a code block with the <prompt> tag:
@llm_prompt
def write_me_short_post(topic: str, platform: str = "twitter", audience: str = "developers"):
"""
Here is a good way to write a prompt as part of a function docstring, with additional documentation for developers.
It needs to be a code block marked with `<prompt>`.
```<prompt:user>
Write a short header for my post about {topic} for the {platform} platform.
It should be for a {audience} audience.
(Max 15 words)
```
Only the code block above will be used as a prompt; the rest of the docstring is documentation for developers.
It also has a nice benefit in IDEs (like VS Code), which will display the prompt properly (without trying to parse it as Markdown).
"""
returnFor chat models, it’s useful to define the prompt as a set of message templates. Here’s how:
@llm_prompt
def simulate_conversation(human_input: str, agent_role: str = "a pirate"):
"""
## System message
- Note the `:system` suffix inside the <prompt:_role_> tag
```<prompt:system>
You are a {agent_role} hacker. You must act like one.
Always reply in code, using Python or JavaScript code blocks only.
for example:
```
```<prompt:user>
Hello, who are you?
```
A reply:
```<prompt:assistant>
\```python
def hello():
print("Argh... hello you pesky pirate")
\```
```
We can also add some history using a placeholder:
```<prompt:placeholder>
{history}
```
```<prompt:user>
{human_input}
```
Only the code blocks above will be used as a prompt; the rest of the docstring is documentation for developers.
"""
passThe roles here are the model’s native roles (assistant, user, system for ChatGPT-compatible models).
- Define a section of your prompt that should be optional.
- If any referenced input in the section is missing or empty (None or ""), the whole section will not be rendered.
Syntax:
@llm_prompt
def prompt_with_optional_partials():
"""
This text will always be rendered, but
{? anything inside this block will be rendered only if all referenced {value}s
are not empty (None | "") ?}
You can also place it inline:
this too will be rendered{?, but
this block will be rendered only if {this_value} and {that_value}
are not empty ?}!
"""- The llm_prompt decorator tries to detect the best output parser based on the return type (if not set, it returns the raw string).
- list, dict, and Pydantic model outputs are supported natively.
# this example should run as-is
from langchain_decorators import llm_prompt
@llm_prompt
def write_name_suggestions(company_business: str, count: int) -> list:
"""Write {count} good name suggestions for a company that {company_business}."""
pass
write_name_suggestions(company_business="sells cookies", count=5)For agent-style workflows, you often need to keep track of messages in a single session/thread. Wrap calls in LlmChatSession:
from langchain_decorators import llm_prompt, LlmChatSession
@llm_prompt
def my_prompt(user_input):
"""
```<prompt:system>
Be a pirate assistant that can reply with 5 words max.
```
```<prompt:placeholder>
{messages}
```
```<prompt:user>
{user_input}
```
"""
with LlmChatSession() as session:
while True:
response = my_prompt(user_input=input("Enter your message: "))
print(response)Implementing tool calling with LangChain can be a hassle: you need to manage chat history, collect tool response messages, and add them back to history.
Decorators offer a simplified variant that manages this for you.
You can use either the native LangChain @tool decorator or @llm_function, which adds conveniences such as handling bound methods and allowing dynamic tool schema generation (especially useful for passing dynamic argument domain values).
import datetime
from pydantic import BaseModel
from langchain_decorators import llm_prompt, llm_function, LlmChatSession
# from langchain.tools import tool as langchain_tool # example placeholder if needed
class Agent(BaseModel):
customer_name: str # bound properties/fields on instances are accessible in the prompt
@property
def current_time(self):
return datetime.datetime.now().isoformat()
@llm_function
def express_emotion(self, emoji: str) -> str:
"""Use this tool to express your emotion as an emoji."""
return print(emoji)
@llm_prompt
def main_prompt(self, user_input: str):
"""
```<prompt:system>
You are a friendly but shy assistant. Try to reply with the fewest words possible.
Context:
customer name is {customer_name}
current time is {current_time}
```
```<prompt:placeholder>
{messages}
```
```<prompt:user>
{user_input}
```
"""
def start(self):
with LlmChatSession(tools=[self.express_emotion]): # add additional tools like `langchain_tool` if needed
while True:
print(self.main_prompt(user_input=input("Enter your message: ")))
# Automatically call tools and add tool responses to history:
# session.execute_tool_calls() is handled by the session context if availableThe simplest way to define an enum is via type annotation using Literal:
from typing import Literal
@llm_function
def do_magic(spell: str, strength: Literal["light", "medium", "strong"]):
"""
Do some kind of magic.
Args:
spell (str): spell text
strength (str): the strength of the spell
"""For dynamic domain values, use:
@llm_function(dynamic_schema=True)
def do_magic(spell: str, strength: Literal["light", "medium", "strong"]):
"""
Do some kind of magic.
Args:
spell (Literal{spells_unlocked}): spell text
strength (Literal["light","medium","strong"]): the strength of the spell
"""
with LlmChatSession(tools=[do_magic], context={"spells_unlocked": spells_unlocked}):
my_prompt(user_message="Make it levitate")Info: this works by parsing any list of values ["val1", "val2"]. You can also use | as a separator and quotes. The Literal prefix in docs is optional and used for clarity.
To use streaming:
- Define the prompt as an async function.
- Turn on streaming in the decorator (or via a PromptType).
- Capture the stream using StreamingContext.
This lets you mark which prompts should be streamed without wiring LLMs and callbacks throughout your code. Streaming happens only if the call is executed inside a StreamingContext.
# this example should run as-is
from langchain_decorators import StreamingContext, llm_prompt
# Mark the prompt for streaming (only async functions support streaming)
@llm_prompt(capture_stream=True)
async def write_me_short_post(topic: str, platform: str = "twitter", audience: str = "developers"):
"""
Write a short header for my post about {topic} for the {platform} platform.
It should be for a {audience} audience.
(Max 15 words)
"""
pass
# Simple function to demonstrate streaming; replace with websockets in a real app
tokens = []
def capture_stream_func(new_token: str):
tokens.append(new_token)
# Capture the stream from prompts marked with capture_stream
async def run():
with StreamingContext(stream_to_stdout=True, callback=capture_stream_func):
result = await write_me_short_post(topic="cookies")
print("Stream finished ... tokens are colorized alternately")
print("\nWe've captured", len(tokens), "tokens 🎉\n")
print("Here is the result:")
print(result)To get structured output, annotate your prompt with a return type:
from langchain_decorators import llm_prompt
from pydantic import BaseModel, Field
class TheOutputStructureWeExpect(BaseModel):
name: str = Field(description="The name of the company")
headline: str = Field(description="The description of the company (for the landing page)")
employees: list[str] = Field(description="5–8 fake employee names with their positions")
@llm_prompt()
def fake_company_generator(company_business: str) -> TheOutputStructureWeExpect:
"""
Generate a fake company that {company_business}
{FORMAT_INSTRUCTIONS}
"""
return
company = fake_company_generator(company_business="sells cookies")
# print the result nicely formatted
print("Company name:", company.name)
print("Company headline:", company.headline)
print("Company employees:", company.employees)Using prompts bound to a class as methods brings several advantages:
- cleaner code organization
- access to object fields/properties as prompt arguments
from pydantic import BaseModel
from langchain_decorators import llm_prompt
class AssistantPersonality(BaseModel):
assistant_name: str
assistant_role: str
field: str
@property
def a_property(self):
return "whatever"
def hello_world(self, function_kwarg: str | None = None):
"""
We can reference any {field} or {a_property} inside our prompt and combine it with {function_kwarg}.
"""
@llm_prompt
def introduce_your_self(self) -> str:
"""
```<prompt:system>
You are an assistant named {assistant_name}.
Your role is to act as {assistant_role}.
```
```<prompt:user>
Introduce yourself (in fewer than 20 words).
```
"""
personality = AssistantPersonality(assistant_name="John", assistant_role="a pirate", field="N/A")
print(personality.introduce_your_self())We often need to format or preprocess some prompt inputs. While you can prepare this before calling your prompt, it can be tedious to repeat the same preprocessing everywhere. There are two main ways to preprocess inputs more elegantly:
a) Using nested functions
def my_func(input1:list, other_input:str):
@llm_prompt
def my_func_prompt(input1_str:str, other_input):
"""
Do something with {input1_str} and {other_input}
"""
my_func_prompt(input1_str=",".join(input1), other_input=other_input)b) Preprocessing inputs directly in the function
@llm_prompt
def my_func_prompt(input1:list, other_input:str):
"""
Current time: {current_time}
Do something with {input1} and {other_input}
"""
# We can override values of any kwarg by returning a dict with overrides.
# We can also enrich the args to add prompt input from broader context
# that is not passed as a function argument.
return {
"input1": ",".join(input1),
"current_time": datetime.datetime.now().isoformat()
}The latter approach is useful when prompts are bound to classes, allowing you to preprocess inputs while preserving access to self fields and variables.
Mark a function as a prompt with the llm_prompt decorator, effectively turning it into an LLMChain.
A standard LLMChain takes more init parameters than just input variables and a prompt; the decorator hides those details. You can control it in several ways:
- Global settings:
from langchain_decorators import GlobalSettings
from langchain.chat_models import ChatOpenAI
GlobalSettings.define_settings(
default_llm=ChatOpenAI(temperature=0.0), # default for non-streaming prompts
default_streaming_llm=ChatOpenAI(temperature=0.0, streaming=True), # default for streaming
)- Predefined prompt types:
from langchain_decorators import PromptTypes, PromptTypeSettings
from langchain.chat_models import ChatOpenAI
PromptTypes.AGENT_REASONING.llm = ChatOpenAI()
# Or define your own:
class MyCustomPromptTypes(PromptTypes):
GPT4 = PromptTypeSettings(llm=ChatOpenAI(model="gpt-4"))
@llm_prompt(prompt_type=MyCustomPromptTypes.GPT4)
def write_a_complicated_code(app_idea: str) -> str:
...- Settings directly in the decorator:
from langchain.llms import OpenAI
@llm_prompt(
llm=OpenAI(temperature=0.7),
stop_tokens=["\nObservation"],
# ...
)
def creative_writer(book_title: str) -> str:
...You can control console logging in several ways:
- Set the ENV variable
LANGCHAIN_DECORATORS_VERBOSE=true - Define global settings (see Defining custom settings)
- Turn on verbose mode on a specific prompt:
@llm_prompt(verbose=True)
def your_prompt(param1):
...Using langchain_decorators turns your prompts into first-class citizens in LangSmith. It creates chains named after your functions, making traces easier to interpret. Additionally, you can add tags:
@llm_prompt(tags=["my_tag"])
def my_prompt(input_arg=...):
"""
...Feedback, contributions, and PRs are welcome 🙏
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for langchain-decorators
Similar Open Source Tools
langchain-decorators
LangChain Decorators is a layer on top of LangChain that provides syntactic sugar for writing custom langchain prompts and chains. It offers a more pythonic way of writing code, multiline prompts without breaking code flow, IDE support for hinting and type checking, leveraging LangChain ecosystem, support for optional parameters, and sharing parameters between prompts. It simplifies streaming, automatic LLM selection, defining custom settings, debugging, and passing memory, callback, stop, etc. It also provides functions provider, dynamic function schemas, binding prompts to objects, defining custom settings, and debugging options. The project aims to enhance the LangChain library by making it easier to use and more efficient for writing custom prompts and chains.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.
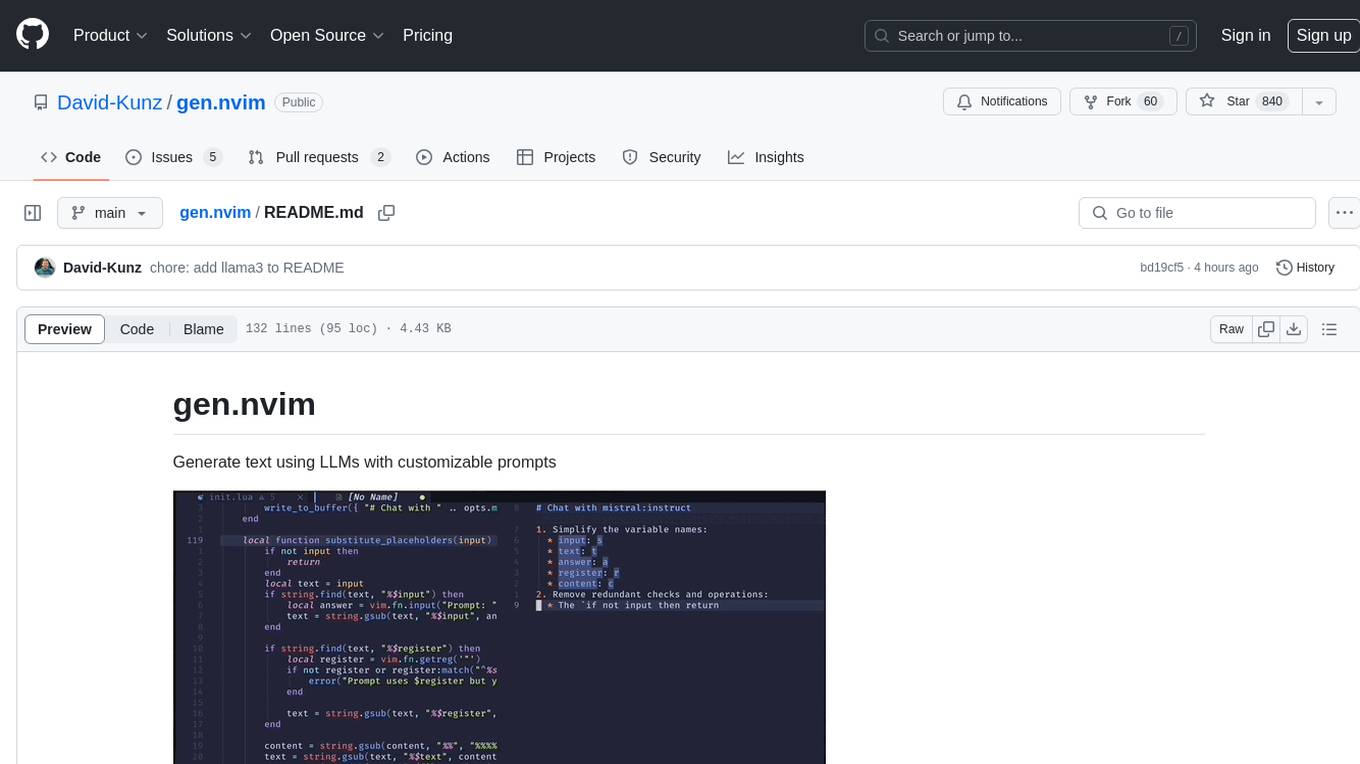
gen.nvim
gen.nvim is a tool that allows users to generate text using Language Models (LLMs) with customizable prompts. It requires Ollama with models like `llama3`, `mistral`, or `zephyr`, along with Curl for installation. Users can use the `Gen` command to generate text based on predefined or custom prompts. The tool provides key maps for easy invocation and allows for follow-up questions during conversations. Additionally, users can select a model from a list of installed models and customize prompts as needed.

neocodeium
NeoCodeium is a free AI completion plugin powered by Codeium, designed for Neovim users. It aims to provide a smoother experience by eliminating flickering suggestions and allowing for repeatable completions using the `.` key. The plugin offers performance improvements through cache techniques, displays suggestion count labels, and supports Lua scripting. Users can customize keymaps, manage suggestions, and interact with the AI chat feature. NeoCodeium enhances code completion in Neovim, making it a valuable tool for developers seeking efficient coding assistance.
banks
Banks is a linguist professor tool that helps generate meaningful LLM prompts using a template language. It provides a user-friendly way to create prompts for various tasks such as blog writing, summarizing documents, lemmatizing text, and generating text using a LLM. The tool supports async operations and comes with predefined filters for data processing. Banks leverages Jinja's macro system to create prompts and interact with OpenAI API for text generation. It also offers a cache mechanism to avoid regenerating text for the same template and context.

langchainrb
Langchain.rb is a Ruby library that makes it easy to build LLM-powered applications. It provides a unified interface to a variety of LLMs, vector search databases, and other tools, making it easy to build and deploy RAG (Retrieval Augmented Generation) systems and assistants. Langchain.rb is open source and available under the MIT License.

simpleAI
SimpleAI is a self-hosted alternative to the not-so-open AI API, focused on replicating main endpoints for LLM such as text completion, chat, edits, and embeddings. It allows quick experimentation with different models, creating benchmarks, and handling specific use cases without relying on external services. Users can integrate and declare models through gRPC, query endpoints using Swagger UI or API, and resolve common issues like CORS with FastAPI middleware. The project is open for contributions and welcomes PRs, issues, documentation, and more.
aiocsv
aiocsv is a Python module that provides asynchronous CSV reading and writing. It is designed to be a drop-in replacement for the Python's builtin csv module, but with the added benefit of being able to read and write CSV files asynchronously. This makes it ideal for use in applications that need to process large CSV files efficiently.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.
parea-sdk-py
Parea AI provides a SDK to evaluate & monitor AI applications. It allows users to test, evaluate, and monitor their AI models by defining and running experiments. The SDK also enables logging and observability for AI applications, as well as deploying prompts to facilitate collaboration between engineers and subject-matter experts. Users can automatically log calls to OpenAI and Anthropic, create hierarchical traces of their applications, and deploy prompts for integration into their applications.
top_secret
Top Secret is a Ruby gem designed to filter sensitive information from free text before sending it to external services or APIs, such as chatbots and LLMs. It provides default filters for credit cards, emails, phone numbers, social security numbers, people's names, and locations, with the ability to add custom filters. Users can configure the tool to handle sensitive information redaction, scan for sensitive data, batch process messages, and restore filtered text from external services. Top Secret uses Regex and NER filters to detect and redact sensitive information, allowing users to override default filters, disable specific filters, and add custom filters globally. The tool is suitable for applications requiring data privacy and security measures.

minja
Minja is a minimalistic C++ Jinja templating engine designed specifically for integration with C++ LLM projects, such as llama.cpp or gemma.cpp. It is not a general-purpose tool but focuses on providing a limited set of filters, tests, and language features tailored for chat templates. The library is header-only, requires C++17, and depends only on nlohmann::json. Minja aims to keep the codebase small, easy to understand, and offers decent performance compared to Python. Users should be cautious when using Minja due to potential security risks, and it is not intended for producing HTML or JavaScript output.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.
For similar tasks

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.
continue
Continue is an open-source autopilot for VS Code and JetBrains that allows you to code with any LLM. With Continue, you can ask coding questions, edit code in natural language, generate files from scratch, and more. Continue is easy to use and can help you save time and improve your coding skills.
anterion
Anterion is an open-source AI software engineer that extends the capabilities of `SWE-agent` to plan and execute open-ended engineering tasks, with a frontend inspired by `OpenDevin`. It is designed to help users fix bugs and prototype ideas with ease. Anterion is equipped with easy deployment and a user-friendly interface, making it accessible to users of all skill levels.
sglang
SGLang is a structured generation language designed for large language models (LLMs). It makes your interaction with LLMs faster and more controllable by co-designing the frontend language and the runtime system. The core features of SGLang include: - **A Flexible Front-End Language**: This allows for easy programming of LLM applications with multiple chained generation calls, advanced prompting techniques, control flow, multiple modalities, parallelism, and external interaction. - **A High-Performance Runtime with RadixAttention**: This feature significantly accelerates the execution of complex LLM programs by automatic KV cache reuse across multiple calls. It also supports other common techniques like continuous batching and tensor parallelism.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.
aider
Aider is a command-line tool that lets you pair program with GPT-3.5/GPT-4 to edit code stored in your local git repository. Aider will directly edit the code in your local source files and git commit the changes with sensible commit messages. You can start a new project or work with an existing git repo. Aider is unique in that it lets you ask for changes to pre-existing, larger codebases.
chatgpt-web
ChatGPT Web is a web application that provides access to the ChatGPT API. It offers two non-official methods to interact with ChatGPT: through the ChatGPTAPI (using the `gpt-3.5-turbo-0301` model) or through the ChatGPTUnofficialProxyAPI (using a web access token). The ChatGPTAPI method is more reliable but requires an OpenAI API key, while the ChatGPTUnofficialProxyAPI method is free but less reliable. The application includes features such as user registration and login, synchronization of conversation history, customization of API keys and sensitive words, and management of users and keys. It also provides a user interface for interacting with ChatGPT and supports multiple languages and themes.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.