
vectorflow
VectorFlow is a high volume vector embedding pipeline that ingests raw data, transforms it into vectors and writes it to a vector DB of your choice.
Stars: 639

VectorFlow is an open source, high throughput, fault tolerant vector embedding pipeline. It provides a simple API endpoint for ingesting large volumes of raw data, processing, and storing or returning the vectors quickly and reliably. The tool supports text-based files like TXT, PDF, HTML, and DOCX, and can be run locally with Kubernetes in production. VectorFlow offers functionalities like embedding documents, running chunking schemas, custom chunking, and integrating with vector databases like Pinecone, Qdrant, and Weaviate. It enforces a standardized schema for uploading data to a vector store and supports features like raw embeddings webhook, chunk validation webhook, S3 endpoint, and telemetry. The tool can be used with the Python client and provides detailed instructions for running and testing the functionalities.
README:
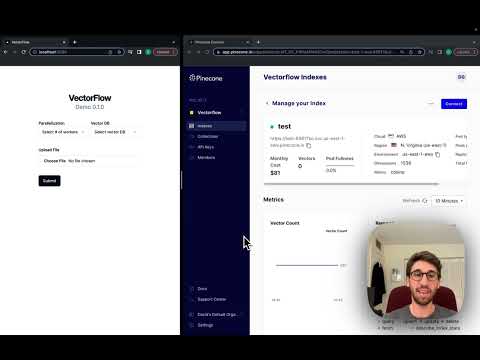
VectorFlow is an open source, high throughput, fault tolerant vector embedding pipeline. With a simple API request, you can send raw data that will be chunked, embedded and stored in any vector database or returned back to you.
This current version is an MVP. We recommend using it with Kubernetes in production (see below for details). For text-based files, it supports TXT, PDF, HTML and DOCX.
With three commands you can run VectorFlow locally:
git clone https://github.com/dgarnitz/vectorflow.git
cd vectorflow
./setup.sh
To start embedding documents locally, install the VectorFlow Client python library in your python application's virtual environment.
pip install vectorflow-client
then run the following
from vectorflow-client.client.vectorflow import Vectorflow
vectorflow = Vectorflow()
vectorflow.embeddings_api_key = os.getenv("OPEN_AI_KEY")
paths = ['path_to_your_file1', 'path_to_your_file2', ...]
response = vectorflow.upload(paths)
You do not need to clone the VectorFlow repo to utilize the client functionality via pip. For more instructions see the README.md in the client directory.
See the appendix for details on how to use the testing_clients scripts.
The best way to run VectorFlow is via docker compose. If you are running this on Mac, please grant Docker permissions to read from your Documents folder as instructed here. If this fails, remove the volume section from the docker-compose.yml.
First create a folder, env_scripts, in the root for all the environment variables, then create env_vars.env in the env_scripts folder to add all the environment variables mentioned below. You only need to set the LOCAL_VECTOR_DB variable if you are running qdrant, Milvus or Weaviate locally.
INTERNAL_API_KEY=your-choice
POSTGRES_USERNAME=postgres
POSTGRES_PASSWORD=your-choice
POSTGRES_DB=vectorflow
POSTGRES_HOST=postgres
RABBITMQ_USERNAME=guest
RABBITMQ_PASSWORD=guest
RABBITMQ_HOST=rabbitmq
LOCAL_VECTOR_DB=qdrant | weaviate
API_STORAGE_DIRECTORY=/tmp
MINIO_ACCESS_KEY=minio99
MINIO_SECRET_KEY=minio123
MINIO_ENDPOINT=minio:9000
MINIO_BUCKET=vectorflow
You can choose a variable for INTERNAL_API_KEY, POSTGRES_PASSWORD, and POSTGRES_DB, but they must be set.
Make sure you pull Rabbit MQ, Postgres, Min.io into your local docker repo. We also recommend running a vector DB in locally, so make sure to pull the image of the one you are using. Our docker-compose file will spin up qdrant by default and create two index/collections. If you plan to run Milvus or Weaviate, you will have to configure them on your own.
docker pull rabbitmq
docker pull postgres
docker pull qdrant/qdrant | docker pull semitechnologies/weaviate
docker pull minio/minio
Then run:
docker-compose build --no-cache
docker-compose up -d
Note that the init containers are running a script that sets up the database schema, vector DB and Min.io object store. These containers stop after the script completes. For qdrant, make sure to pull version 1.9.1 since that is the version the qdrant client python package is supposed to work with.
The best way to use VectorFlow is with the python client.
To use VectorFlow for development, make an HTTP request to your API's URL - for example, localhost:8000 from your development machine, or vectorflow_api:8000 from within another docker container.
All requests require an HTTP Header with Authorization key which is the same as your INTERNAL_API_KEY env var that you defined before (see above). You must pass your vector database api key with the HTTP Header X-VectorDB-Key if you are running a connecting to a cloud-based instance of a vector DB, and the embedding api key with X-EmbeddingAPI-Key if you are using OpenAI. HuggingFace Sentence Transformer embeddings do not require an api key, but you must follow the above steps to run the container with the model you need.
VectorFlow currently supports Pinecone, Qdrant and Weaviate vector databases.
To submit a single file for embedding, make a POST request to the /embed endpoint with a file attached, the 'Content-Type: multipart/form-data' header and the following payload:
{
'SourceData=path_to_txt_file'
'LinesPerBatch=4096'
'EmbeddingsMetadata={
"embeddings_type": "OPEN_AI",
"chunk_size": 512,
"chunk_overlap": 128,
"chunk_strategy": "EXACT | PARAGRAPH | SENTENCE | CUSTOM",
"model": "text-embedding-3-small | text-embedding-3-large | text-embedding-ada-002"
}'
'VectorDBMetadata={
"vector_db_type": "PINECONE | QDRANT | WEAVIATE",
"index_name": "index_name",
"environment": "env_name"
}'
'DocumentID=your-optional-internal-tracking-id'
}
This will create a job and you will get the following payload back:
{
'message': f"Successfully added {batch_count} batches to the queue",
'JobID': job_id
}
Right now this endpoint only supports uploading single files at a time, up to 25 MB due to timeout issues. Note that it may be deprecated.
To submit multiple files for embedding, make a POST request to the /jobs endpoint. The payload is the same as for single file embedding except the way you attach multiple files is different:
{
'files=[
('file', ('test_pdf.pdf', open(file1_path, 'rb'), 'application/octet-stream')),
('file', ('test_medium_text.txt', open(file2_path, 'rb'), 'application/octet-stream'))
]'
}
NOTE: You must stream the files to the endpoint, not send it as a conventional post request or it will fail.
This endpoint will create one job per file uploaded. You will get the following JSON payload back:
{
'successful_uploads': successfully_uploaded_files,
'failed_uploads': failed_uploads,
'empty_files_count': empty_files_count,
'duplicate_files_count': duplicate_files_count
}
Where successfully_uploaded_files is a list of tuples containing (file name, job id) and failed_uploads is a list of file names that failed to upload so you can retry them.
To check the status of a job, make a GET request to this endpoint: /jobs/<int:job_id>/status. The response will be in the form:
{
'JobStatus': job_status
}
To check the status of multiples job, make a POST request to this endpoint: /jobs/status. The request body will be in the form:
{
'JobIDs': job_ids
}
and the response will be in the form
{
'Jobs': [{'JobID': job_id, 'JobStatus': job_status}, ...]}
There is an example in testing_clients/get_jobs_by_ids.py.
VectorFlow enforces a standardized schema for uploading data to a vector store:
id: string
source_data: string
source_document: string
embeddings: float array
The id can be used for deduplication and idempotency. Please note for Weaviate, the id is called vectorflow_id.
We plan deprecicate this in the near futuer to support dynamically detected and/or configurable schemas down the road.
VectorFlow's built in chunkers count by token not by character. A chunk in vectorflow is a dictionary that has the following keys:
text: str
vector: list[float]
You may run a custom chunker by adding a file, custom_chunker.py, with a method, chunker(source_data: list[str]) to the src/worker directory prior to build the docker image for the worker. This chunker must return a list of chunk dictionaries that conform to the standard above.
You can add any keys you want to the chunk dictionary as long as its JSON serializable, meaning no custom classes or function, datetimes types or circular code references. You can use this custom chunk to then upload metadata to the vector DB with whatever schema you desire.
If you wish to use VectorFlow only for chunking and generating embeddings, pass a WebhookURL parameter in the body of the /embed request and a X-Webhook-Key as a header. VectorFlow assumes a webhook key is required for writing back to any endpoint. The embeddings are sent back along with the source chunks in the chunk dictionary outlined above. This is sent as json with the following form:
{
'Embeddings': list[dict],
'DocumentID': str,
'JobID': int
}
If you wish to validate which chunks you wish to embed, pass a ChunkValidationURL parameter in the body of the /embed request. This will send the request with the following json payload, {"chunks": chunked_data}, where chunked_data is a list of chunk dictionaries. It will expected back json containing key valid_chunks with a list of valid chunks for embedding. This endpoint will timeout after 30 seconds by default but can be configured in the application code.
VectorFlow is integrated with AWS s3. You can pass a pre-signed s3 URL in the body of the HTTP instead of a file. Use the form field PreSignedURL and hit the endpoint /s3. This endpoint has the same configuration and restrictions as the /embed endpoint.
VectorFlow uses PostHog to anonymously collect data about usage. This does not collect any personally identifiable information. If you want to disable it though, add the following enviroment variable to your env_vars.env:
TELEMETRY_DISABLED=True
You can run VectorFlow locally in Kubernetes with minikube using ./kube/scripts/deploy-local-k8s.sh, which will apply all the yaml files located in kube/. This script will not work if you have not installed docker, minikube and kubectl.
This script will first build the images locally, then transfer them into minikube. If you want to check what images are available in minikube, run the following:
eval $(minikube docker-env)
docker images
You will need to run minikube tunnel to access the resources located in the cluster from your development machine. The setup script will load the images from your local docker context into minikube's.
You can use the yaml files in kube/ as a basis for a production deployment but you will need to customize slightly to the needs of your specific cluster. Contact us if you need help.
We love feedback from the community. If you have an idea of how to make this project better, we encourage you to open an issue or join our Discord. Please tag dgarnitz and danmeier2.
Our roadmap is outlined in the section below and we would love help in building it out. Our open issues are a great place to start and can be viewed here. If you want to work on something not listed there, we recommend you open an issue with a proposed approach in mind before submitting a PR.
Please tag dgarnitz on all PRs and update the README to reflect your changes.
When submitting a PR, please add units tests to cover the functionality you have added. Please re-run existing tests to ensure there are no regressive bugs. Run from the src directory. To run an individual test use:
python -m unittest module.tests.test_file.TestClass.test_method
To run all the tests in the file use:
python -m unittest module.tests.test_file
For end-to-end testing, it is recommend to build and run using the docker-compose, but take down the container you are altering and run it locally on your development machine. This will avoid the need to constantly rebuild the images and re-run the containers. Make sure to change the environment variables in your development machine terminal to the correct values (i.e. localhost instead of rabbitmq or postgres) so that the docker containers can communicate with your development machine. Once it works locally you can perform a final test with everything in docker-compose.
Please verify that all changes work with docker-compose before opening a PR.
We also recommend you add verification evidence, such as screenshots, that show that your code works in an end to end flow.
- [ ] Support for multi-file, directory data ingestion from sources such as Salesforce, Google Drive, etc
- [ ] Retry mechanism
- [ ] Langchain integrations
- [ ] Support callbacks for writing object metadata to a separate store
- [ ] Dynamically configurable vector DB schemas
- [ ] Deduplication capabilities
- [ ] Vector version control
- [ ] "Smart" chunker
- [ ] "Smart" metadata extractor
One easy way to use VectorFlow is with the our testing clients, located in testing_clients/ directory. There are several scripts, with different configurations for qickly uploading data. We recommmend starting with the testing_clients/standard_upload_client.py - Running this script will submit a single document to VectorFlow for embedding with Open AI ADA and upload to the local qdrant instance. You can change the values to match your configuration. To upload multiple files at once, use the testing_clients/streaming_upload_client.py
Note that the TESTING_ENV variable is the equivalent of the environment field in the VectorDBMetadata, which corresponds to an environment in Pincone, a class in Weaviate, a collection in qdrant, etc.
The testing_clients directory has sample scripts you can follow to run vectorflow. Add your embedding and database keys to the env_scrips/env_vars.sh script that was generated and set the filepath variable in testing_clients/standard_upload_client.py to point to the file you want to embed. Then run:
source env_scrips/env_vars.sh
python testing-clients/standard_upload_client.py
To upload multiple files at once, use the testing_clients/streaming_upload_client.py
See above for a more detailed description of how to manually set up and configure the system. Please note that the setup script will not create a development environment on your machine, it only sets up and runs the docker-compose. We do not advise using VectorFlow on Windows.
To perform a search, send a POST request to /images/search endpoint with an image file attached, the 'Content-Type: multipart/form-data' header and the following body:
{
'ReturnVectors': boolean,
'TopK': integer, less than 1000,
'VectorDBMetadata={
"vector_db_type": "PINECONE | QDRANT | WEAVIATE",
"index_name": "index_name",
"environment": "env_name"
}'
}
All requests require an HTTP Header with Authorization key which is the same as your INTERNAL_API_KEY env var that you defined before (see above). You must pass your vector database api key with the HTTP Header X-VectorDB-Key if you are running a connecting to a cloud-based instance of a vector DB.
An image similarity search will return a response object containing the top K matches, plus the raw vectors if requested, with of the following form:
{
"similar_images": list of match objects
"vectors": list of list of floats
}
where `match`` objects are defined as:
{
"id": str,
"score": float,
"metadata": {"source_document" : str}
}
If you want to use docker build and docker run to build and run individual images instead of docker-compose follow these steps:
cd src/-
docker build --file api/Dockerfile -t vectorflow_api:latest .to build - don't forget the period at the end -
docker run --network=vectorflow --name=vectorflow_api -d --env-file=../env_scripts/env_vars.env -p 8000:8000 vectorflow_api:latestto run the api. you don't need the port argument to run the worker
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for vectorflow
Similar Open Source Tools
vectorflow
VectorFlow is an open source, high throughput, fault tolerant vector embedding pipeline. It provides a simple API endpoint for ingesting large volumes of raw data, processing, and storing or returning the vectors quickly and reliably. The tool supports text-based files like TXT, PDF, HTML, and DOCX, and can be run locally with Kubernetes in production. VectorFlow offers functionalities like embedding documents, running chunking schemas, custom chunking, and integrating with vector databases like Pinecone, Qdrant, and Weaviate. It enforces a standardized schema for uploading data to a vector store and supports features like raw embeddings webhook, chunk validation webhook, S3 endpoint, and telemetry. The tool can be used with the Python client and provides detailed instructions for running and testing the functionalities.

smartcat
Smartcat is a CLI interface that brings language models into the Unix ecosystem, allowing power users to leverage the capabilities of LLMs in their daily workflows. It features a minimalist design, seamless integration with terminal and editor workflows, and customizable prompts for specific tasks. Smartcat currently supports OpenAI, Mistral AI, and Anthropic APIs, providing access to a range of language models. With its ability to manipulate file and text streams, integrate with editors, and offer configurable settings, Smartcat empowers users to automate tasks, enhance code quality, and explore creative possibilities.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

hordelib
horde-engine is a wrapper around ComfyUI designed to run inference pipelines visually designed in the ComfyUI GUI. It enables users to design inference pipelines in ComfyUI and then call them programmatically, maintaining compatibility with the existing horde implementation. The library provides features for processing Horde payloads, initializing the library, downloading and validating models, and generating images based on input data. It also includes custom nodes for preprocessing and tasks such as face restoration and QR code generation. The project depends on various open source projects and bundles some dependencies within the library itself. Users can design ComfyUI pipelines, convert them to the backend format, and run them using the run_image_pipeline() method in hordelib.comfy.Comfy(). The project is actively developed and tested using git, tox, and a specific model directory structure.

debug-gym
debug-gym is a text-based interactive debugging framework designed for debugging Python programs. It provides an environment where agents can interact with code repositories, use various tools like pdb and grep to investigate and fix bugs, and propose code patches. The framework supports different LLM backends such as OpenAI, Azure OpenAI, and Anthropic. Users can customize tools, manage environment states, and run agents to debug code effectively. debug-gym is modular, extensible, and suitable for interactive debugging tasks in a text-based environment.
illume
Illume is a scriptable command line program designed for interfacing with an OpenAI-compatible LLM API. It acts as a unix filter, sending standard input to the LLM and streaming its response to standard output. Users can interact with the LLM through text editors like Vim or Emacs, enabling seamless communication with the AI model for various tasks.

vectara-answer
Vectara Answer is a sample app for Vectara-powered Summarized Semantic Search (or question-answering) with advanced configuration options. For examples of what you can build with Vectara Answer, check out Ask News, LegalAid, or any of the other demo applications.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.
ain
Ain is a terminal HTTP API client designed for scripting input and processing output via pipes. It allows flexible organization of APIs using files and folders, supports shell-scripts and executables for common tasks, handles url-encoding, and enables sharing the resulting curl, wget, or httpie command-line. Users can put things that change in environment variables or .env-files, and pipe the API output for further processing. Ain targets users who work with many APIs using a simple file format and uses curl, wget, or httpie to make the actual calls.

chat-ai
A Seamless Slurm-Native Solution for HPC-Based Services. This repository contains the stand-alone web interface of Chat AI, which can be set up independently to act as a wrapper for an OpenAI-compatible API endpoint. It consists of two Docker containers, 'front' and 'back', providing a ReactJS app served by ViteJS and a wrapper for message requests to prevent CORS errors. Configuration files allow setting port numbers, backend paths, models, user data, default conversation settings, and more. The 'back' service interacts with an OpenAI-compatible API endpoint using configurable attributes in 'back.json'. Customization options include creating a path for available models and setting the 'modelsPath' in 'front.json'. Acknowledgements to contributors and the Chat AI community are included.

garak
Garak is a free tool that checks if a Large Language Model (LLM) can be made to fail in a way that is undesirable. It probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. Garak's a free tool. We love developing it and are always interested in adding functionality to support applications.

safety-tooling
This repository, safety-tooling, is designed to be shared across various AI Safety projects. It provides an LLM API with a common interface for OpenAI, Anthropic, and Google models. The aim is to facilitate collaboration among AI Safety researchers, especially those with limited software engineering backgrounds, by offering a platform for contributing to a larger codebase. The repo can be used as a git submodule for easy collaboration and updates. It also supports pip installation for convenience. The repository includes features for installation, secrets management, linting, formatting, Redis configuration, testing, dependency management, inference, finetuning, API usage tracking, and various utilities for data processing and experimentation.

qb
QANTA is a system and dataset for question answering tasks. It provides a script to download datasets, preprocesses questions, and matches them with Wikipedia pages. The system includes various datasets, training, dev, and test data in JSON and SQLite formats. Dependencies include Python 3.6, `click`, and NLTK models. Elastic Search 5.6 is needed for the Guesser component. Configuration is managed through environment variables and YAML files. QANTA supports multiple guesser implementations that can be enabled/disabled. Running QANTA involves using `cli.py` and Luigi pipelines. The system accesses raw Wikipedia dumps for data processing. The QANTA ID numbering scheme categorizes datasets based on events and competitions.

MultiPL-E
MultiPL-E is a system for translating unit test-driven neural code generation benchmarks to new languages. It is part of the BigCode Code Generation LM Harness and allows for evaluating Code LLMs using various benchmarks. The tool supports multiple versions with improvements and new language additions, providing a scalable and polyglot approach to benchmarking neural code generation. Users can access a tutorial for direct usage and explore the dataset of translated prompts on the Hugging Face Hub.

WindowsAgentArena
Windows Agent Arena (WAA) is a scalable Windows AI agent platform designed for testing and benchmarking multi-modal, desktop AI agents. It provides researchers and developers with a reproducible and realistic Windows OS environment for AI research, enabling testing of agentic AI workflows across various tasks. WAA supports deploying agents at scale using Azure ML cloud infrastructure, allowing parallel running of multiple agents and delivering quick benchmark results for hundreds of tasks in minutes.
seer
Seer is a service that provides AI capabilities to Sentry by running inference on Sentry issues and providing user insights. It is currently in early development and not yet compatible with self-hosted Sentry instances. The tool requires access to internal Sentry resources and is intended for internal Sentry employees. Users can set up the environment, download model artifacts, integrate with local Sentry, run evaluations for Autofix AI agent, and deploy to a sandbox staging environment. Development commands include applying database migrations, creating new migrations, running tests, and more. The tool also supports VCRs for recording and replaying HTTP requests.
For similar tasks
vectorflow
VectorFlow is an open source, high throughput, fault tolerant vector embedding pipeline. It provides a simple API endpoint for ingesting large volumes of raw data, processing, and storing or returning the vectors quickly and reliably. The tool supports text-based files like TXT, PDF, HTML, and DOCX, and can be run locally with Kubernetes in production. VectorFlow offers functionalities like embedding documents, running chunking schemas, custom chunking, and integrating with vector databases like Pinecone, Qdrant, and Weaviate. It enforces a standardized schema for uploading data to a vector store and supports features like raw embeddings webhook, chunk validation webhook, S3 endpoint, and telemetry. The tool can be used with the Python client and provides detailed instructions for running and testing the functionalities.
paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.
bellman
Bellman is a unified interface to interact with language and embedding models, supporting various vendors like VertexAI/Gemini, OpenAI, Anthropic, VoyageAI, and Ollama. It consists of a library for direct interaction with models and a service 'bellmand' for proxying requests with one API key. Bellman simplifies switching between models, vendors, and common tasks like chat, structured data, tools, and binary input. It addresses the lack of official SDKs for major players and differences in APIs, providing a single proxy for handling different models. The library offers clients for different vendors implementing common interfaces for generating and embedding text, enabling easy interchangeability between models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.