
oterm
a text-based terminal client for Ollama
Stars: 1541
Oterm is a text-based terminal client for Ollama, a large language model. It provides an intuitive and simple terminal UI, allowing users to interact with Ollama without running servers or frontends. Oterm supports multiple persistent chat sessions, which are stored along with context embeddings and system prompt customizations in a SQLite database. Users can easily customize the model's system prompt and parameters, and select from any of the models they have pulled in Ollama or their own custom models. Oterm also supports keyboard shortcuts for creating new chat sessions, editing existing sessions, renaming sessions, exporting sessions as markdown, deleting sessions, toggling between dark and light themes, quitting the application, switching to multiline input mode, selecting images to include with messages, and navigating through the history of previous prompts. Oterm is licensed under the MIT License.
README:
the text-based terminal client for Ollama.
- intuitive and simple terminal UI, no need to run servers, frontends, just type
otermin your terminal. - multiple persistent chat sessions, stored together with system prompt & parameter customizations in sqlite.
- support for Model Context Protocol (MCP) tools & prompts integration.
- can use any of the models you have pulled in Ollama, or your own custom models.
- allows for easy customization of the model's system prompt and parameters.
- supports tools integration for providing external information to the model.
uvx otermSee Installation for more details.
- Support sixel graphics for displaying images in the terminal.
- Support for Model Context Protocol (MCP) tools & prompts!
- Create custom commands that can be run from the terminal using oterm. Each of these commands is a chat, customized to your liking and connected to the tools of your choice.
 The splash screen animation that greets users when they start oterm.
The splash screen animation that greets users when they start oterm.
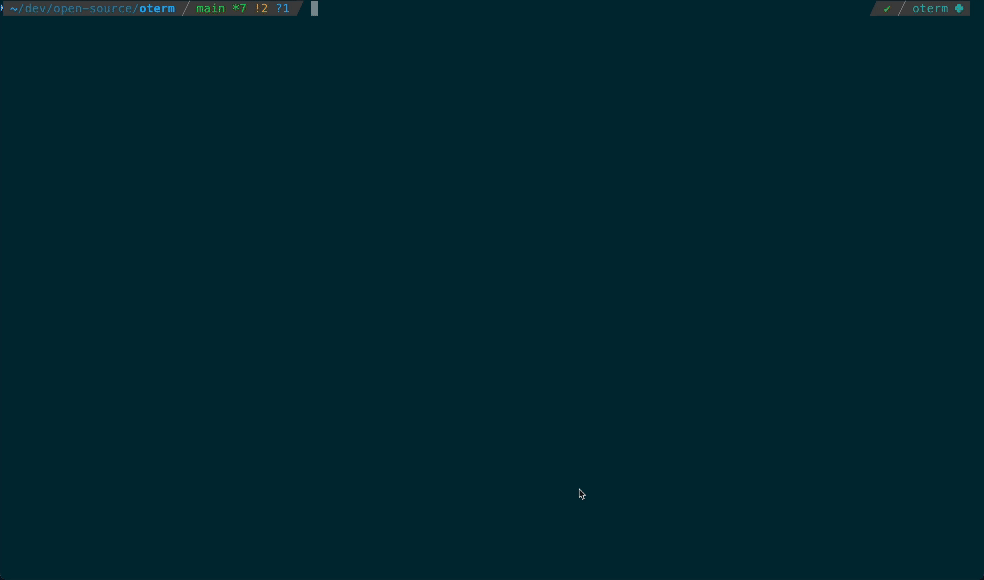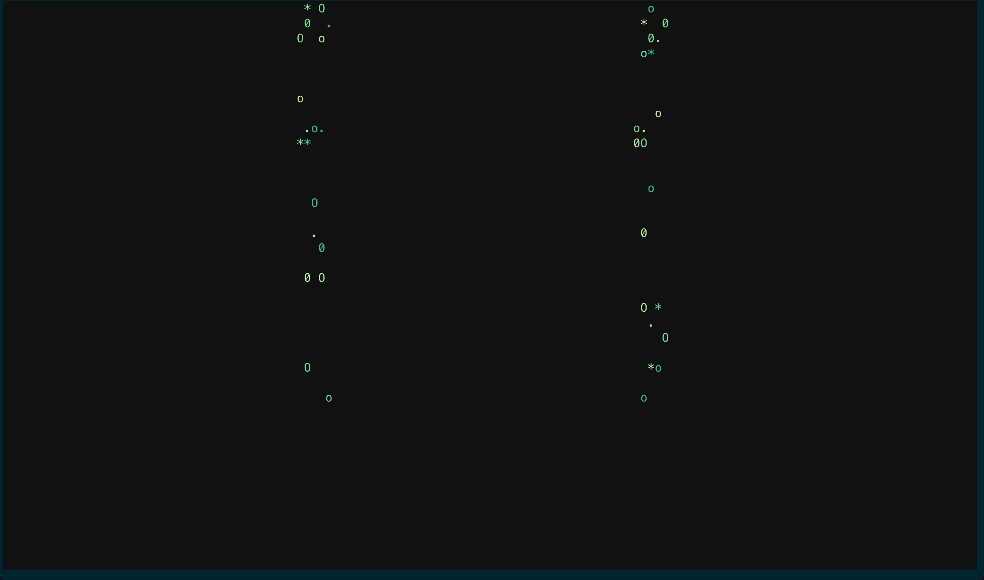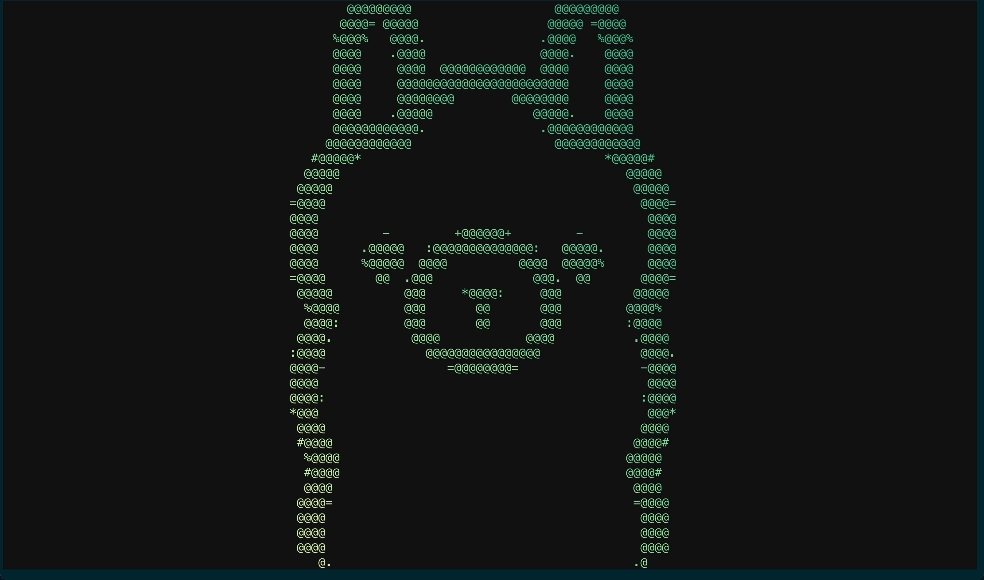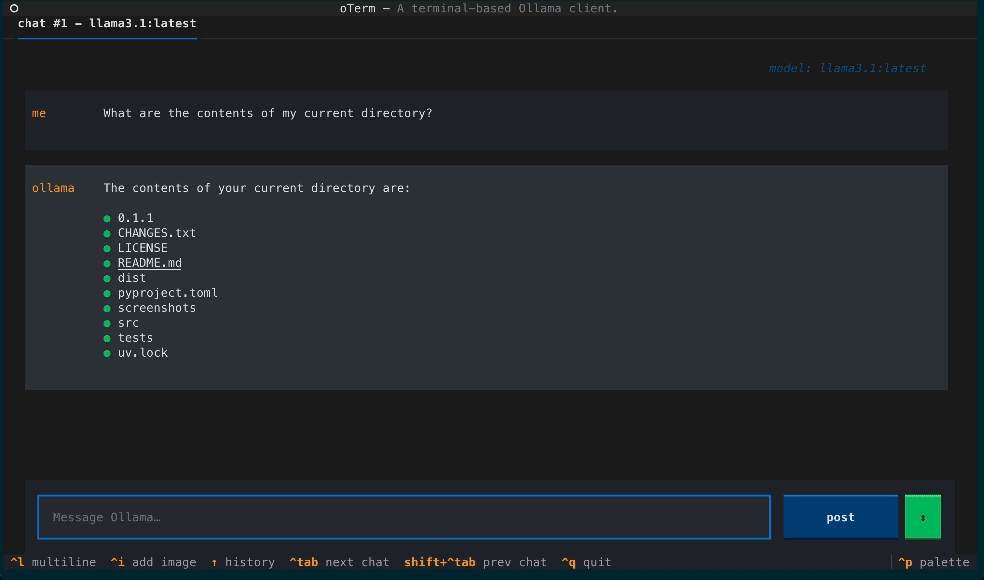
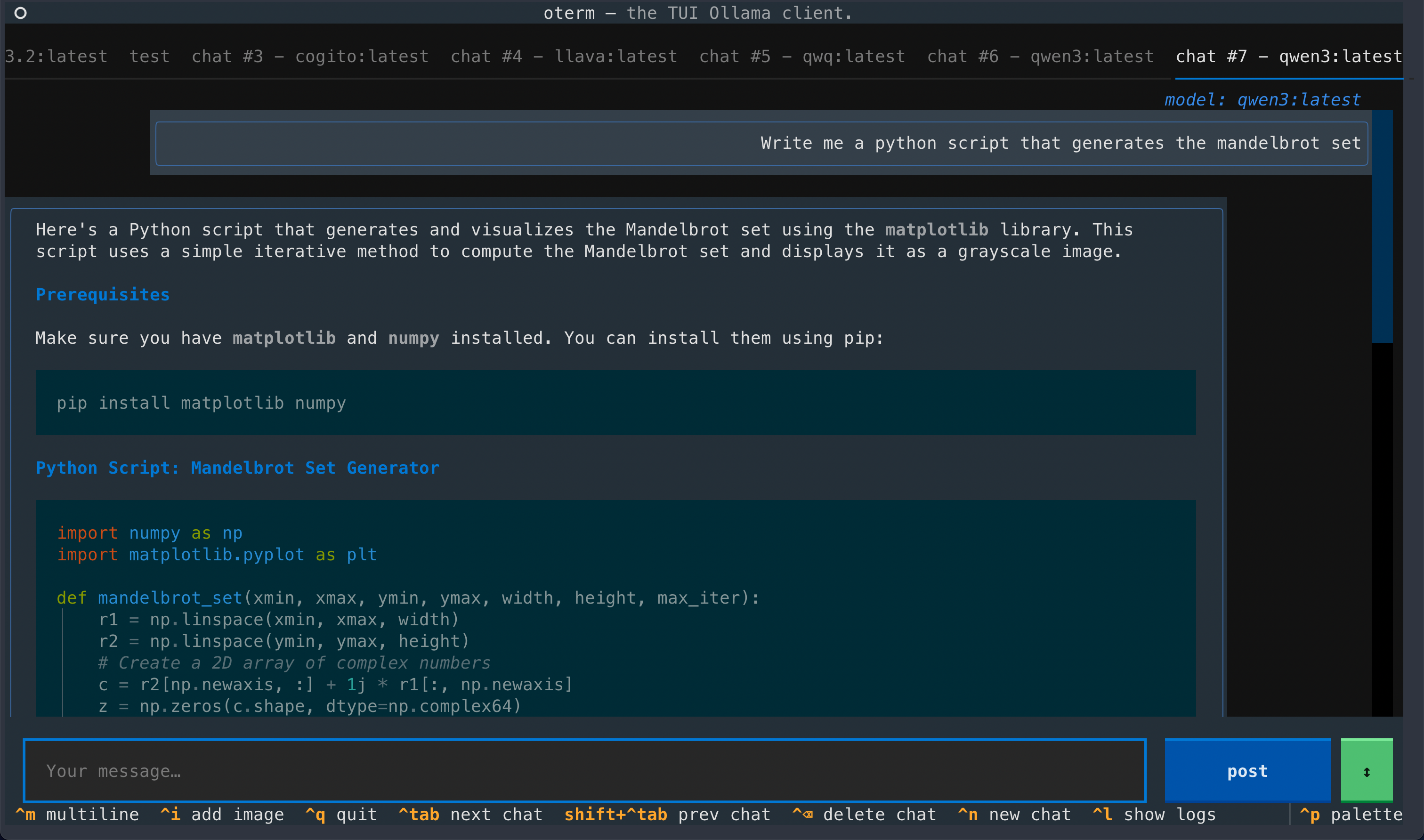 A view of the chat interface, showcasing the conversation between the user and the model.
A view of the chat interface, showcasing the conversation between the user and the model.
 The model selection screen, allowing users to choose and customize available models.
The model selection screen, allowing users to choose and customize available models.
 oterm using the
oterm using the git MCP server to access its own repo.
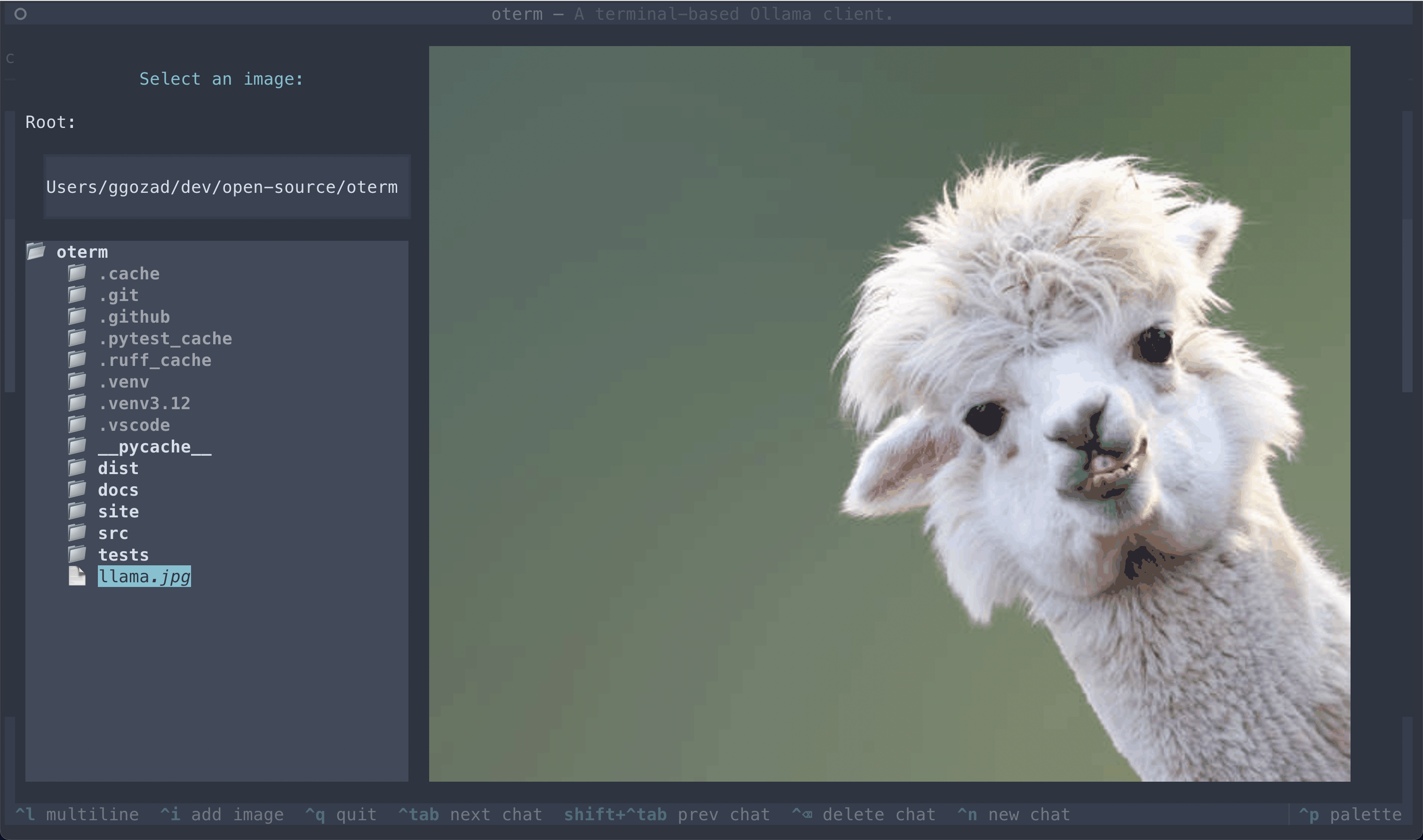 The image selection interface, demonstrating how users can include images in their conversations.
The image selection interface, demonstrating how users can include images in their conversations.
 oterm supports multiple themes, allowing users to customize the appearance of the interface.
oterm supports multiple themes, allowing users to customize the appearance of the interface.
This project is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for oterm
Similar Open Source Tools
oterm
Oterm is a text-based terminal client for Ollama, a large language model. It provides an intuitive and simple terminal UI, allowing users to interact with Ollama without running servers or frontends. Oterm supports multiple persistent chat sessions, which are stored along with context embeddings and system prompt customizations in a SQLite database. Users can easily customize the model's system prompt and parameters, and select from any of the models they have pulled in Ollama or their own custom models. Oterm also supports keyboard shortcuts for creating new chat sessions, editing existing sessions, renaming sessions, exporting sessions as markdown, deleting sessions, toggling between dark and light themes, quitting the application, switching to multiline input mode, selecting images to include with messages, and navigating through the history of previous prompts. Oterm is licensed under the MIT License.
prompty
Prompty is an asset class and format for LLM prompts designed to enhance observability, understandability, and portability for developers. The primary goal is to accelerate the developer inner loop. This repository contains the Prompty Language Specification and a documentation site. The Visual Studio Code extension offers a prompt playground to streamline the prompt engineering process.
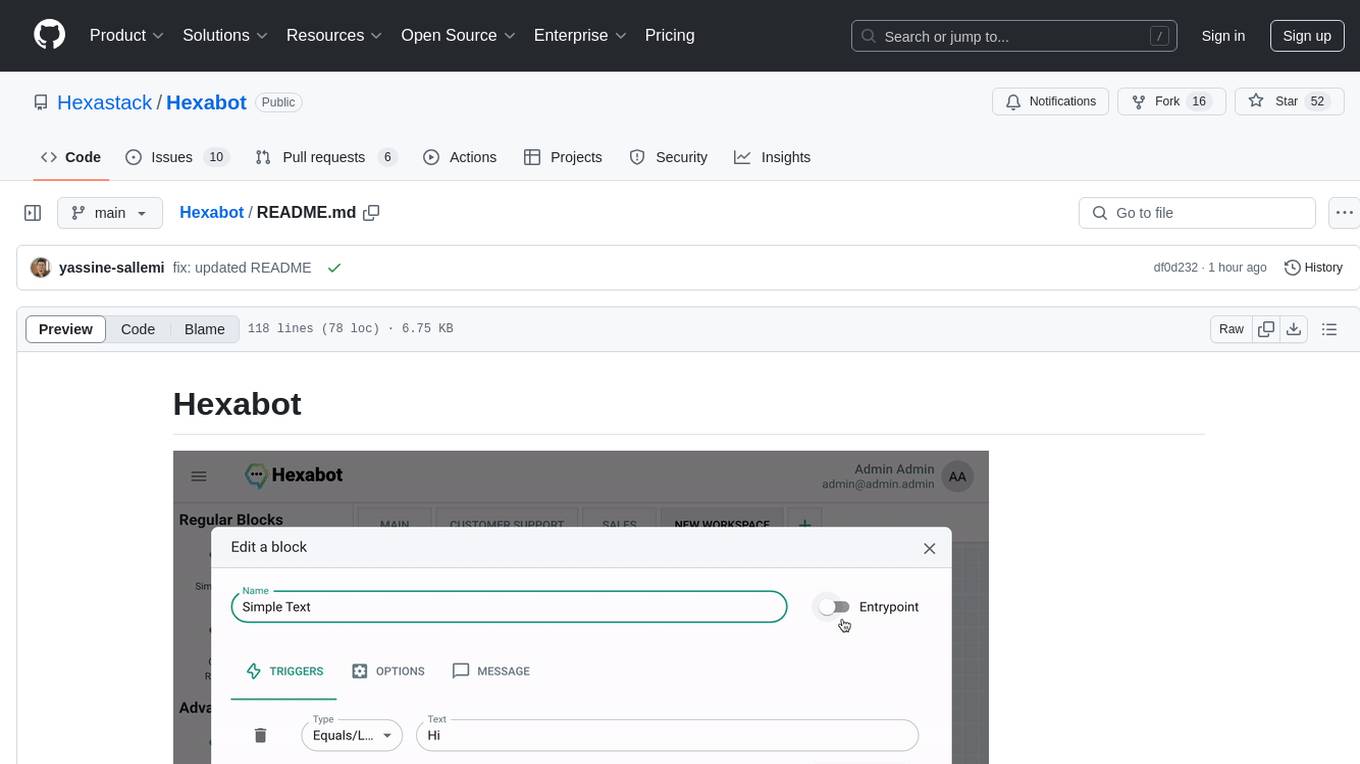
Hexabot
Hexabot Community Edition is an open-source chatbot solution designed for flexibility and customization, offering powerful text-to-action capabilities. It allows users to create and manage AI-powered, multi-channel, and multilingual chatbots with ease. The platform features an analytics dashboard, multi-channel support, visual editor, plugin system, NLP/NLU management, multi-lingual support, CMS integration, user roles & permissions, contextual data, subscribers & labels, and inbox & handover functionalities. The directory structure includes frontend, API, widget, NLU, and docker components. Prerequisites for running Hexabot include Docker and Node.js. The installation process involves cloning the repository, setting up the environment, and running the application. Users can access the UI admin panel and live chat widget for interaction. Various commands are available for managing the Docker services. Detailed documentation and contribution guidelines are provided for users interested in contributing to the project.

poml
POML (Prompt Orchestration Markup Language) is a novel markup language designed to bring structure, maintainability, and versatility to advanced prompt engineering for Large Language Models (LLMs). It addresses common challenges in prompt development, such as lack of structure, complex data integration, format sensitivity, and inadequate tooling. POML provides a systematic way to organize prompt components, integrate diverse data types seamlessly, and manage presentation variations, empowering developers to create more sophisticated and reliable LLM applications.
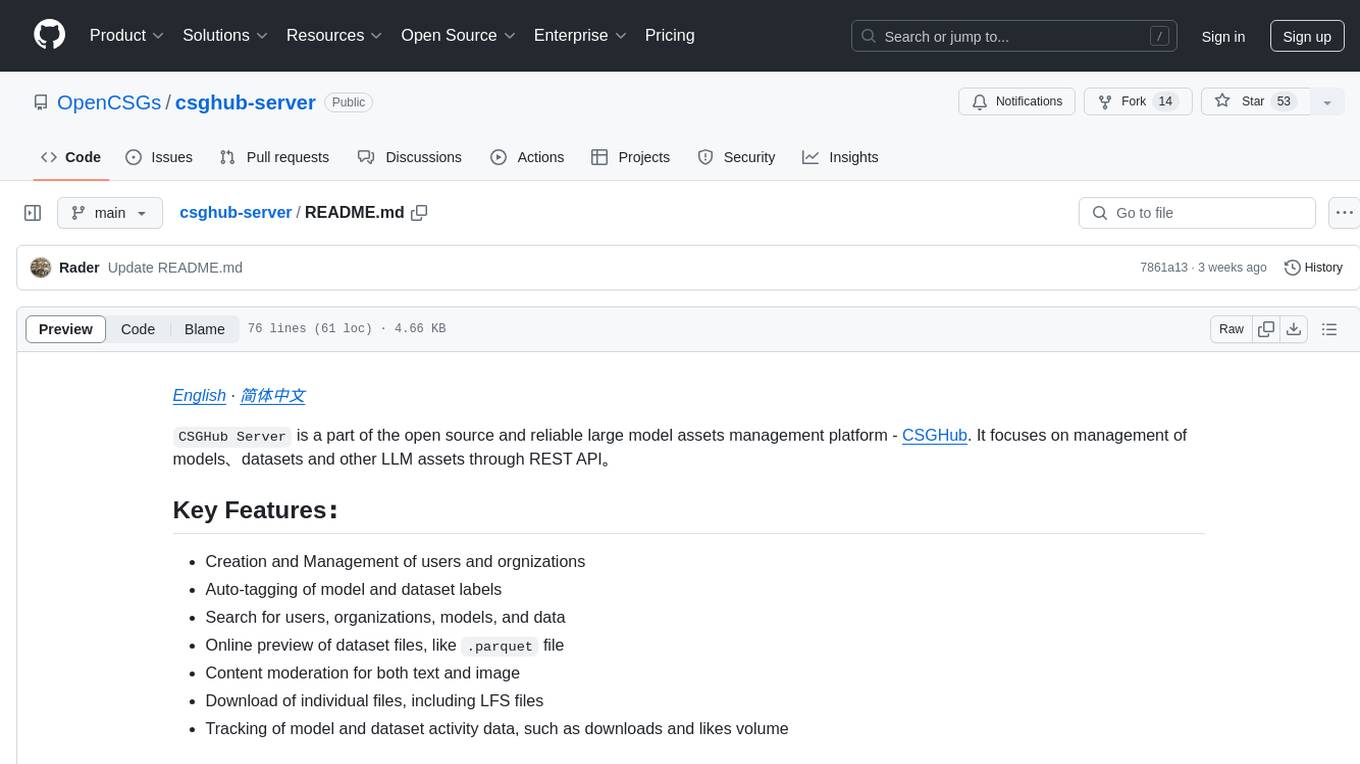
csghub-server
CSGHub Server is a part of the open source and reliable large model assets management platform - CSGHub. It focuses on management of models, datasets, and other LLM assets through REST API. Key features include creation and management of users and organizations, auto-tagging of model and dataset labels, search functionality, online preview of dataset files, content moderation for text and image, download of individual files, tracking of model and dataset activity data. The tool is extensible and customizable, supporting different git servers, flexible LFS storage system configuration, and content moderation options. The roadmap includes support for more Git servers, Git LFS, dataset online viewer, model/dataset auto-tag, S3 protocol support, model format conversion, and model one-click deploy. The project is licensed under Apache 2.0 and welcomes contributions.

domino
Domino is an open source workflow management platform that provides an intuitive GUI for creating, editing, and monitoring workflows. It also offers a standard way of writing and publishing functional pieces that can be reused in multiple workflows. Domino is powered by Apache Airflow for top-tier workflows scheduling and monitoring.
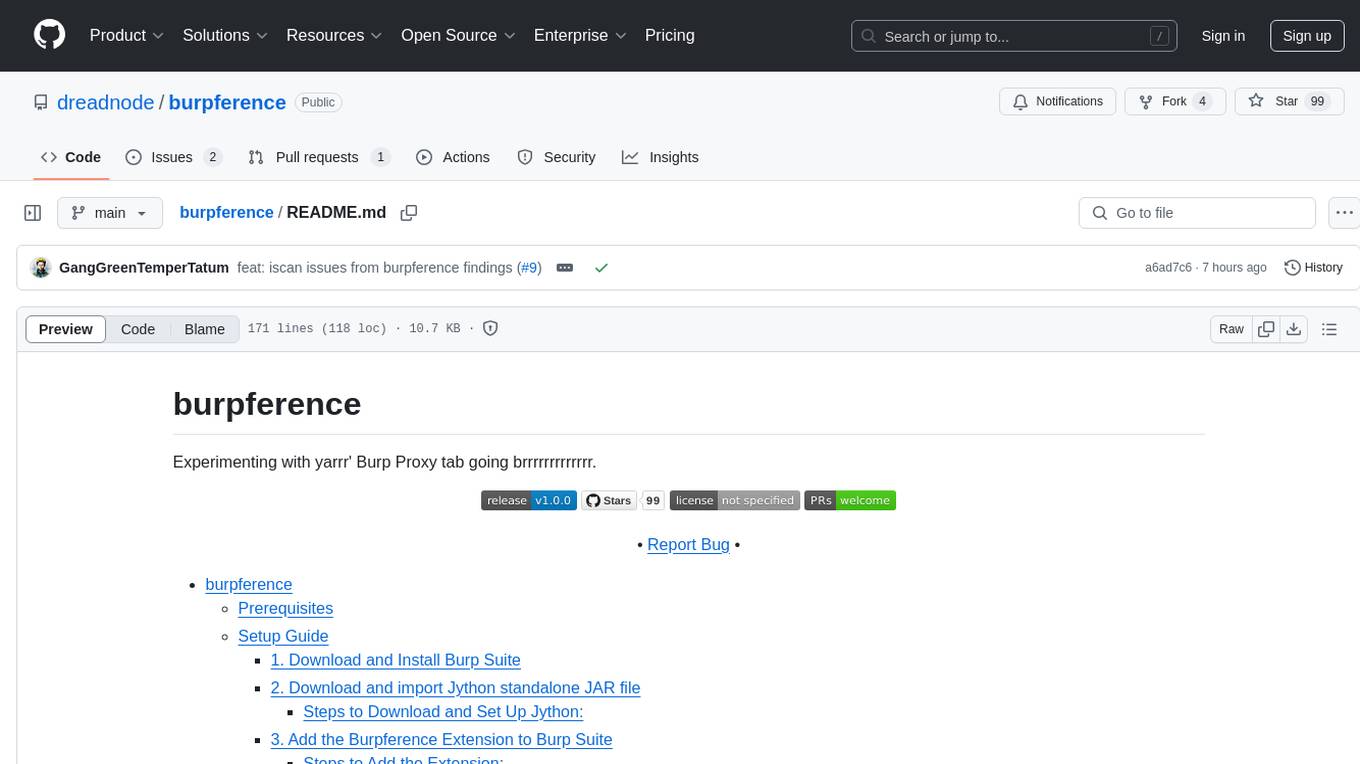
burpference
Burpference is an open-source extension designed to capture in-scope HTTP requests and responses from Burp's proxy history and send them to a remote LLM API in JSON format. It automates response capture, integrates with APIs, optimizes resource usage, provides color-coded findings visualization, offers comprehensive logging, supports native Burp reporting, and allows flexible configuration. Users can customize system prompts, API keys, and remote hosts, and host models locally to prevent high inference costs. The tool is ideal for offensive web application engagements to surface findings and vulnerabilities.

ProxyAI
ProxyAI is an open-source AI copilot for JetBrains, offering advanced code assistance features powered by top-tier language models. Users can customize their coding experience, receive AI-suggested code changes, autocomplete suggestions, and context-aware naming suggestions. The tool also allows users to chat with images, reference project files and folders, web docs, git history, and search the web. ProxyAI prioritizes user privacy by not collecting sensitive information and only gathering anonymous usage data with consent.

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.
devchat
DevChat is an open-source workflow engine that enables developers to create intelligent, automated workflows for engaging with users through a chat panel within their IDEs. It combines script writing flexibility, latest AI models, and an intuitive chat GUI to enhance user experience and productivity. DevChat simplifies the integration of AI in software development, unlocking new possibilities for developers.
eShopSupport
eShopSupport is a sample .NET application showcasing common use cases and development practices for building AI solutions in .NET, specifically Generative AI. It demonstrates a customer support application for an e-commerce website using a services-based architecture with .NET Aspire. The application includes support for text classification, sentiment analysis, text summarization, synthetic data generation, and chat bot interactions. It also showcases development practices such as developing solutions locally, evaluating AI responses, leveraging Python projects, and deploying applications to the Cloud.

client
DagsHub is a platform for machine learning and data science teams to build, manage, and collaborate on their projects. With DagsHub you can: 1. Version code, data, and models in one place. Use the free provided DagsHub storage or connect it to your cloud storage 2. Track Experiments using Git, DVC or MLflow, to provide a fully reproducible environment 3. Visualize pipelines, data, and notebooks in and interactive, diff-able, and dynamic way 4. Label your data directly on the platform using Label Studio 5. Share your work with your team members 6. Stream and upload your data in an intuitive and easy way, while preserving versioning and structure. DagsHub is built firmly around open, standard formats for your project. In particular: * Git * DVC * MLflow * Label Studio * Standard data formats like YAML, JSON, CSV Therefore, you can work with DagsHub regardless of your chosen programming language or frameworks.
letmedoit
LetMeDoIt AI is a virtual assistant designed to revolutionize the way you work. It goes beyond being a mere chatbot by offering a unique and powerful capability - the ability to execute commands and perform computing tasks on your behalf. With LetMeDoIt AI, you can access OpenAI ChatGPT-4, Google Gemini Pro, and Microsoft AutoGen, local LLMs, all in one place, to enhance your productivity.
chatlas
Chatlas is a Python tool that provides a simple and unified interface across various large language model providers. It helps users prototype faster by abstracting complexity from tasks like streaming chat interfaces, tool calling, and structured output. Users can easily switch providers by changing one line of code and access provider-specific features when needed. Chatlas focuses on developer experience with typing support, rich console output, and extension points.
Visual-Code-Space
Visual Code Space is a modern code editor designed specifically for Android devices. It offers a seamless and efficient coding environment with features like blazing fast file explorer, multi-language syntax highlighting, tabbed editor, integrated terminal emulator, ad-free experience, and plugin support. Users can enhance their mobile coding experience with this cutting-edge editor that allows customization through custom plugins written in BeanShell. The tool aims to simplify coding on the go by providing a user-friendly interface and powerful functionalities.
BotServer
General Bot is a chat bot server that accelerates bot development by providing code base, resources, deployment to the cloud, and templates for creating new bots. It allows modification of bot packages without code through a database and service backend. Users can develop bot packages using custom code in editors like Visual Studio Code, Atom, or Brackets. The tool supports creating bots by copying and pasting files and using favorite tools from Office or Photoshop. It also enables building custom dialogs with BASIC for extending bots.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.