
AddaxAI
Simplify camera trap image analysis with AI species recognition models based around the MegaDetector model
Stars: 132

AddaxAI is an application designed to streamline the work of ecologists dealing with camera trap images. It's an AI platform that allows you to analyse images with machine learning models for automatic detection, offering ecologists a way to save time and focus on conservation efforts.
README:
![]()





AddaxAI is an application designed to streamline the work of ecologists dealing with camera trap images. It’s an AI platform that allows you to analyse images with machine learning models for automatic detection, offering ecologists a way to save time and focus on conservation efforts.




To avoid any legal concerns, we have renamed our project from EcoAssist to AddaxAI. The project itself remains the same—only the name has changed.
![]()
If you used AddaxAI in your research, please include the following citation, along with the models used to analyze your data.
@article{van Lunteren2023,
title = {AddaxAI: A no-code platform to train and deploy custom YOLOv5 object detection models},
author = {Peter van Lunteren},
journal = {Journal of Open Source Software},
doi = {10.21105/joss.05581},
url = {https://doi.org/10.21105/joss.05581},
year = {2023},
publisher = {The Open Journal},
volume = {8},
number = {88},
pages = {5581}
}Interested in contributing to this project? There are always things to do. The list of to-do items, bug reports, and feature requests is always evolving. I try to keep a semi-structured list here. Is there something you would be interested in? Get in touch and I will guide you in the right direction. Thanks!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AddaxAI
Similar Open Source Tools
AddaxAI
AddaxAI is an application designed to streamline the work of ecologists dealing with camera trap images. It's an AI platform that allows you to analyse images with machine learning models for automatic detection, offering ecologists a way to save time and focus on conservation efforts.
omnihuman
OmniHuman is an AI model designed to understand humanoids and text. It provides functionalities to process images and videos, generating text descriptions for human actions depicted in the visual content. The tool offers support for various tasks related to human pose recognition and action understanding. Users can easily integrate OmniHuman into their projects to enhance the capabilities of their applications in recognizing and interpreting human actions in images and videos.
vertex-ai-mlops
Vertex AI is a platform for end-to-end model development. It consist of core components that make the processes of MLOps possible for design patterns of all types.
EuroEval
EuroEval is a robust European language model benchmark tool, formerly known as ScandEval. It provides a platform to benchmark pretrained models on various tasks across different languages. Users can evaluate models, datasets, and metrics both online and offline. The tool supports benchmarking from the command line, script, and Docker. Additionally, users can reproduce datasets used in the project using provided scripts. EuroEval welcomes contributions and offers guidelines for general contributions and adding new datasets.
LMCache
LMCache is a serving engine extension designed to reduce time to first token (TTFT) and increase throughput, particularly in long-context scenarios. It stores key-value caches of reusable texts across different locations like GPU, CPU DRAM, and Local Disk, allowing the reuse of any text in any serving engine instance. By combining LMCache with vLLM, significant delay savings and GPU cycle reduction are achieved in various large language model (LLM) use cases, such as multi-round question answering and retrieval-augmented generation (RAG). LMCache provides integration with the latest vLLM version, offering both online serving and offline inference capabilities. It supports sharing key-value caches across multiple vLLM instances and aims to provide stable support for non-prefix key-value caches along with user and developer documentation.

transformers
Transformers is a state-of-the-art pretrained models library that acts as the model-definition framework for machine learning models in text, computer vision, audio, video, and multimodal tasks. It centralizes model definition for compatibility across various training frameworks, inference engines, and modeling libraries. The library simplifies the usage of new models by providing simple, customizable, and efficient model definitions. With over 1M+ Transformers model checkpoints available, users can easily find and utilize models for their tasks.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.
webots
Webots is an open-source robot simulator that provides a complete development environment to model, program, and simulate robots, vehicles, and mechanical systems. It was originally designed at EPFL in 1996 and further developed and commercialized by Cyberbotics since 1998. Webots was open-sourced in December 2018 and continues to be developed by Cyberbotics with paid customer support, training, and consulting services for industry and academic research projects.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

lanarky
Lanarky is a Python web framework designed for building microservices using Large Language Models (LLMs). It is LLM-first, fast, modern, supports streaming over HTTP and WebSockets, and is open-source. The framework provides an abstraction layer for developers to easily create LLM microservices. Lanarky guarantees zero vendor lock-in and is free to use. It is built on top of FastAPI and offers features familiar to FastAPI users. The project is now in maintenance mode, with no active development planned, but community contributions are encouraged.

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.
SuperCoder
SuperCoder is an open-source autonomous software development system that leverages advanced AI tools and agents to streamline and automate coding, testing, and deployment tasks, enhancing efficiency and reliability. It supports a variety of languages and frameworks for diverse development needs. Users can set up the environment variables, build and run the Go server, Asynq worker, and Postgres using Docker and Docker Compose. The project is under active development and may still have issues, but users can seek help and support from the Discord community or by creating new issues on GitHub.
Scrapegraph-LabLabAI-Hackathon
ScrapeGraphAI is a web scraping Python library that utilizes LangChain, LLM, and direct graph logic to create scraping pipelines. Users can specify the information they want to extract, and the library will handle the extraction process. The tool is designed to simplify web scraping tasks by providing a streamlined and efficient approach to data extraction.
Anima
Anima is the first open-source 33B Chinese large language model based on QLoRA, supporting DPO alignment training and open-sourcing a 100k context window model. The latest update includes AirLLM, a library that enables inference of 70B LLM from a single GPU with just 4GB memory. The tool optimizes memory usage for inference, allowing large language models to run on a single 4GB GPU without the need for quantization or other compression techniques. Anima aims to democratize AI by making advanced models accessible to everyone and contributing to the historical process of AI democratization.

RD-Agent
RD-Agent is a tool designed to automate critical aspects of industrial R&D processes, focusing on data-driven scenarios to streamline model and data development. It aims to propose new ideas ('R') and implement them ('D') automatically, leading to solutions of significant industrial value. The tool supports scenarios like Automated Quantitative Trading, Data Mining Agent, Research Copilot, and more, with a framework to push the boundaries of research in data science. Users can create a Conda environment, install the RDAgent package from PyPI, configure GPT model, and run various applications for tasks like quantitative trading, model evolution, medical prediction, and more. The tool is intended to enhance R&D processes and boost productivity in industrial settings.
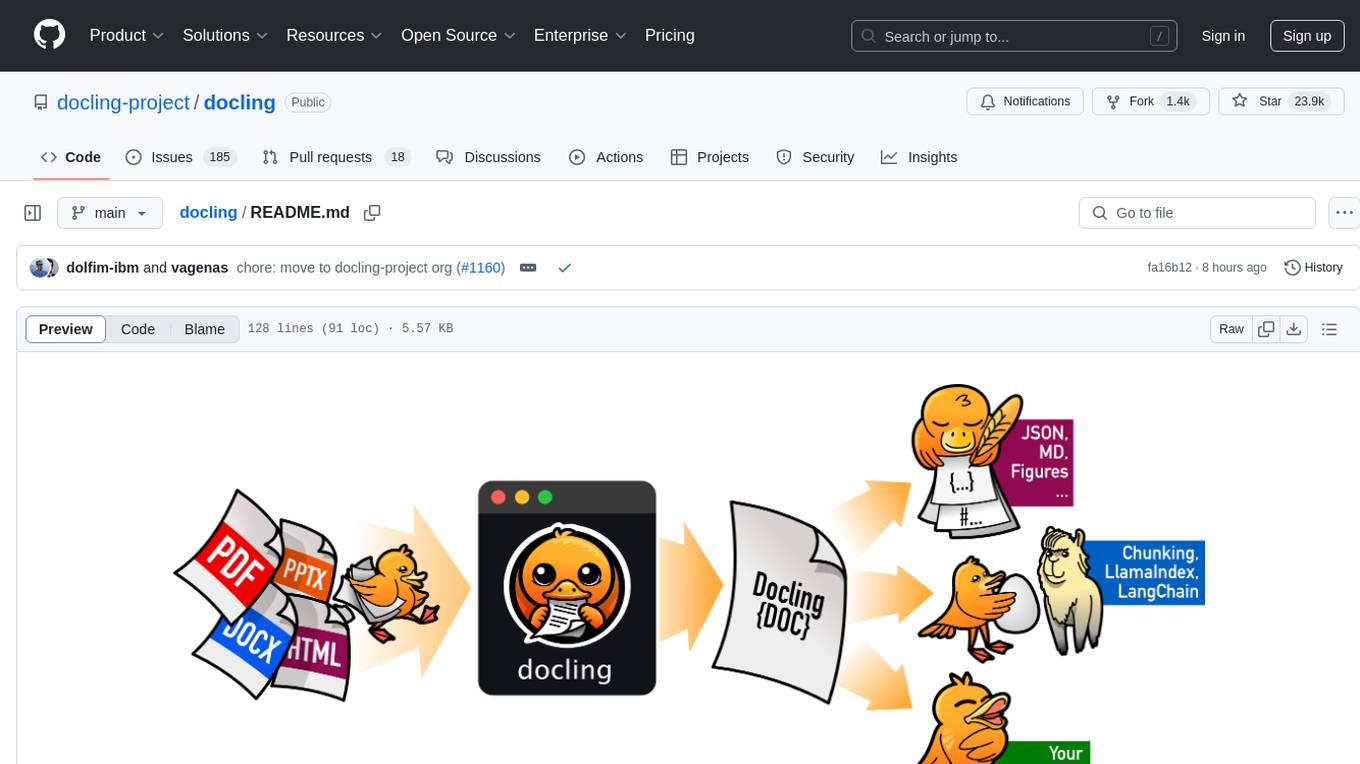
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.
For similar tasks

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.

spark-free-api
Spark AI Free 服务 provides high-speed streaming output, multi-turn dialogue support, AI drawing support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository includes multiple free-api projects for various AI services. Users can access the API for tasks such as chat completions, AI drawing, document interpretation, image analysis, and ssoSessionId live checking. The project also provides guidelines for deployment using Docker, Docker-compose, Render, Vercel, and native deployment methods. It recommends using custom clients for faster and simpler access to the free-api series projects.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.

horde-worker-reGen
This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.

geospy
Geospy is a Python tool that utilizes Graylark's AI-powered geolocation service to determine the location where photos were taken. It allows users to analyze images and retrieve information such as country, city, explanation, coordinates, and Google Maps links. The tool provides a seamless way to integrate geolocation services into various projects and applications.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.
For similar jobs
AddaxAI
AddaxAI is an application designed to streamline the work of ecologists dealing with camera trap images. It's an AI platform that allows you to analyse images with machine learning models for automatic detection, offering ecologists a way to save time and focus on conservation efforts.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.