
OpenDevin
🐚 OpenDevin: Code Less, Make More
Stars: 30160
OpenDevin is an open-source project aiming to replicate Devin, an autonomous AI software engineer capable of executing complex engineering tasks and collaborating actively with users on software development projects. The project aspires to enhance and innovate upon Devin through the power of the open-source community. Users can contribute to the project by developing core functionalities, frontend interface, or sandboxing solutions, participating in research and evaluation of LLMs in software engineering, and providing feedback and testing on the OpenDevin toolset.
README:






Welcome to OpenDevin, a platform for autonomous software engineers, powered by AI and LLMs.
OpenDevin agents collaborate with human developers to write code, fix bugs, and ship features.

OpenDevin works best with Docker version 26.0.0+ (Docker Desktop 4.31.0+). You must be using Linux, Mac OS, or WSL on Windows.
To start OpenDevin in a docker container, run the following commands in your terminal:
[!WARNING] When you run the following command, files in
./workspacemay be modified or deleted.
WORKSPACE_BASE=$(pwd)/workspace
docker run -it \
--pull=always \
-e SANDBOX_USER_ID=$(id -u) \
-e WORKSPACE_MOUNT_PATH=$WORKSPACE_BASE \
-v $WORKSPACE_BASE:/opt/workspace_base \
-v /var/run/docker.sock:/var/run/docker.sock \
-p 3000:3000 \
--add-host host.docker.internal:host-gateway \
--name opendevin-app-$(date +%Y%m%d%H%M%S) \
ghcr.io/opendevin/opendevin:0.8[!NOTE] By default, this command pulls the
latesttag, which represents the most recent release of OpenDevin. You have other options as well:
- For a specific release version, use
ghcr.io/opendevin/opendevin:<OpenDevin_version>(replace <OpenDevin_version> with the desired version number).- For the most up-to-date development version, use
ghcr.io/opendevin/opendevin:main. This version may be (unstable!) and is recommended for testing or development purposes only.Choose the tag that best suits your needs based on stability requirements and desired features.
You'll find OpenDevin running at http://localhost:3000 with access to ./workspace. To have OpenDevin operate on your code, place it in ./workspace.
OpenDevin will only have access to this workspace folder. The rest of your system will not be affected as it runs in a secured docker sandbox.
Upon opening OpenDevin, you must select the appropriate Model and enter the API Key within the settings that should pop up automatically. These can be set at any time by selecting
the Settings button (gear icon) in the UI. If the required Model does not exist in the list, you can manually enter it in the text box.
For the development workflow, see Development.md.
Are you having trouble? Check out our Troubleshooting Guide.
To learn more about the project, and for tips on using OpenDevin, check out our documentation.
There you'll find resources on how to use different LLM providers (like ollama and Anthropic's Claude), troubleshooting resources, and advanced configuration options.
OpenDevin is a community-driven project, and we welcome contributions from everyone. Whether you're a developer, a researcher, or simply enthusiastic about advancing the field of software engineering with AI, there are many ways to get involved:
- Code Contributions: Help us develop new agents, core functionality, the frontend and other interfaces, or sandboxing solutions.
- Research and Evaluation: Contribute to our understanding of LLMs in software engineering, participate in evaluating the models, or suggest improvements.
- Feedback and Testing: Use the OpenDevin toolset, report bugs, suggest features, or provide feedback on usability.
For details, please check CONTRIBUTING.md.
Whether you're a developer, a researcher, or simply enthusiastic about OpenDevin, we'd love to have you in our community. Let's make software engineering better together!
- Slack workspace - Here we talk about research, architecture, and future development.
- Discord server - This is a community-run server for general discussion, questions, and feedback.
Distributed under the MIT License. See LICENSE for more information.
OpenDevin is built by a large number of contributors, and every contribution is greatly appreciated! We also build upon other open source projects, and we are deeply thankful for their work.
For a list of open source projects and licenses used in OpenDevin, please see our CREDITS.md file.
@misc{opendevin,
title={{OpenDevin: An Open Platform for AI Software Developers as Generalist Agents}},
author={Xingyao Wang and Boxuan Li and Yufan Song and Frank F. Xu and Xiangru Tang and Mingchen Zhuge and Jiayi Pan and Yueqi Song and Bowen Li and Jaskirat Singh and Hoang H. Tran and Fuqiang Li and Ren Ma and Mingzhang Zheng and Bill Qian and Yanjun Shao and Niklas Muennighoff and Yizhe Zhang and Binyuan Hui and Junyang Lin and Robert Brennan and Hao Peng and Heng Ji and Graham Neubig},
year={2024},
eprint={2407.16741},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2407.16741},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for OpenDevin
Similar Open Source Tools
OpenDevin
OpenDevin is an open-source project aiming to replicate Devin, an autonomous AI software engineer capable of executing complex engineering tasks and collaborating actively with users on software development projects. The project aspires to enhance and innovate upon Devin through the power of the open-source community. Users can contribute to the project by developing core functionalities, frontend interface, or sandboxing solutions, participating in research and evaluation of LLMs in software engineering, and providing feedback and testing on the OpenDevin toolset.

ChatDev
ChatDev is a virtual software company powered by intelligent agents like CEO, CPO, CTO, programmer, reviewer, tester, and art designer. These agents collaborate to revolutionize the digital world through programming. The platform offers an easy-to-use, highly customizable, and extendable framework based on large language models, ideal for studying collective intelligence. ChatDev introduces innovative methods like Iterative Experience Refinement and Experiential Co-Learning to enhance software development efficiency. It supports features like incremental development, Docker integration, Git mode, and Human-Agent-Interaction mode. Users can customize ChatChain, Phase, and Role settings, and share their software creations easily. The project is open-source under the Apache 2.0 License and utilizes data licensed under CC BY-NC 4.0.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.
companion-vscode
Quack Companion is a VSCode extension that provides smart linting, code chat, and coding guideline curation for developers. It aims to enhance the coding experience by offering a new tab with features like curating software insights with the team, code chat similar to ChatGPT, smart linting, and upcoming code completion. The extension focuses on creating a smooth contribution experience for developers by turning contribution guidelines into a live pair coding experience, helping developers find starter contribution opportunities, and ensuring alignment between contribution goals and project priorities. Quack collects limited telemetry data to improve its services and products for developers, with options for anonymization and disabling telemetry available to users.
Sanmill
Sanmill is a free, powerful UCI-like N men's morris program with CUI, Flutter GUI and Qt GUI. Nine men's morris is a strategy board game for two players dating at least to the Roman Empire. The game is also known as nine-man morris , mill , mills , the mill game , merels , merrills , merelles , marelles , morelles , and ninepenny marl in English.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.
chainlit
Chainlit is an open-source async Python framework which allows developers to build scalable Conversational AI or agentic applications. It enables users to create ChatGPT-like applications, embedded chatbots, custom frontends, and API endpoints. The framework provides features such as multi-modal chats, chain of thought visualization, data persistence, human feedback, and an in-context prompt playground. Chainlit is compatible with various Python programs and libraries, including LangChain, Llama Index, Autogen, OpenAI Assistant, and Haystack. It offers a range of examples and a cookbook to showcase its capabilities and inspire users. Chainlit welcomes contributions and is licensed under the Apache 2.0 license.
ocular
Ocular is a set of modules and tools that allow you to build rich, reliable, and performant Generative AI-Powered Search Platforms without the need to reinvent Search Architecture. We help you build you spin up customized internal search in days not months.
slidev-ai
Slidev AI is a web app that leverages LLM (Large Language Model) technology to make creating Slidev-based online presentations elegant and effortless. It is designed to help engineers and academics quickly produce content-focused, minimalist PPTs that are easily shareable online. This project serves as a reference implementation for OpenMCP agent development, a production-ready presentation generation solution, and a template for creating domain-specific AI agents.
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.

superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.

letsql
LETSQL is a data processing library built on top of Ibis and DataFusion to write multi-engine data workflows. It is currently in development and does not have a stable release. Users can install LETSQL from PyPI and use it to connect to data sources, read data, filter, group, and aggregate data for analysis. Contributions to the project are welcome, and the library is actively maintained with support available for any issues. LETSQL heavily relies on Ibis and DataFusion for its functionality.
For similar tasks
OpenDevin
OpenDevin is an open-source project aiming to replicate Devin, an autonomous AI software engineer capable of executing complex engineering tasks and collaborating actively with users on software development projects. The project aspires to enhance and innovate upon Devin through the power of the open-source community. Users can contribute to the project by developing core functionalities, frontend interface, or sandboxing solutions, participating in research and evaluation of LLMs in software engineering, and providing feedback and testing on the OpenDevin toolset.
AI-and-competition
This repository provides baselines for various competitions, a few top solutions for some competitions, and independent deep learning projects. Baselines serve as entry guides for competitions, suitable for beginners to make their first submission. Top solutions are more complex and refined versions of baselines, with limited quantity but enhanced quality. The repository is maintained by a single author, yunsuxiaozi, offering code improvements and annotations for better understanding. Users can support the repository by learning from it and providing feedback.
Comfyui-Aix-NodeMap
Comfyui-Aix-NodeMap is a project by the Aix team to organize and annotate the latest nodes in Comfyui. It aims to address the challenge of finding nodes effectively as their number increases. The project is continuously updated every 7 days, with the opportunity for users to provide feedback on any omissions or errors. The team respects developers' opinions and strives to make corrections promptly. The project is part of Aix's vision to make humanity more efficient through open-source contributions, including daily updates on workflow, AI information, and node introductions.
ai-tag
AI tag generator that combines 40,000 tags from Bilibili UP main Twelve Today is also very cute with Chinese translations from Novelai, providing Chinese search and tag generation services. It offers a tag community for magicians to directly copy and generate spells. Always free, no ads, no commercial use. The project includes a pure tag parsing library, independent spell parsing library, tag data repository, and a new gallery page with waterfall flow for viewing community images.

gemini-ai-code-reviewer
Gemini AI Code Reviewer is a GitHub Action that automatically reviews pull requests using Google's Gemini AI. It analyzes code changes, consults the Gemini model, provides feedback, and delivers review comments directly to pull requests on GitHub. Users need a Gemini API key and can trigger the workflow by commenting '/gemini-review' in the PR. The tool helps improve source code quality by giving suggestions and comments for enhancement.
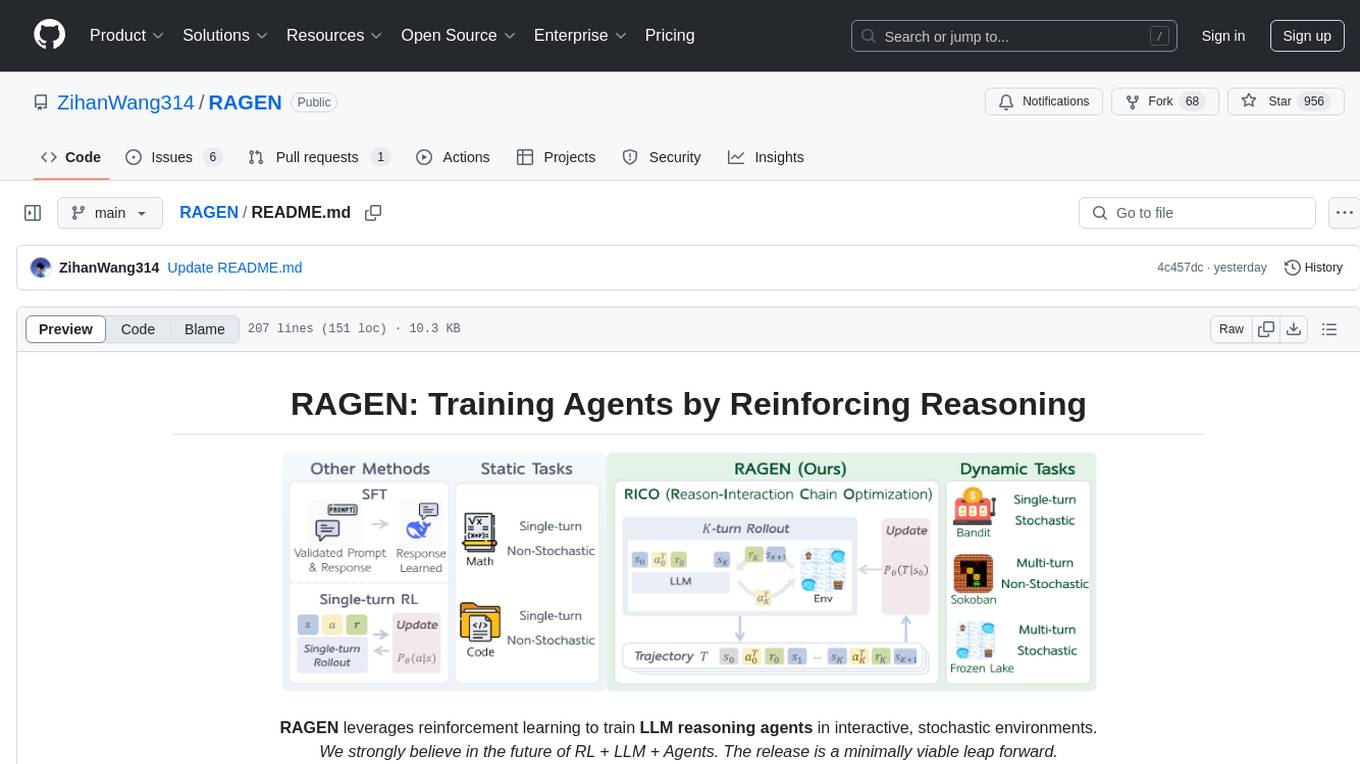
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.
Comfyui-Aix-NodeMap
Comfyui-Aix-NodeMap is a project by the Aix team to organize and annotate the latest nodes in Comfyui. It aims to address the challenge of finding nodes effectively due to the increasing number of nodes. The project is updated every 7 days to provide the most recent node information. Users can provide feedback for any omissions or errors, and corrections will be made promptly. The project respects every developer and values community collaboration in improving node exposure and accessibility.
xiaozhi-sharp
xiaozhi-sharp is a meticulously crafted XiaoZhi client in C#, serving as a code learning example and enabling intelligent interaction with XiaoZhi AI without related hardware. It connects to xiaozhi.me server for stable services. The tool includes a debugging feature to understand XiaoZhi's commands and a console client for interaction. Users need .NET Core SDK to run the project smoothly, ensuring stable network connection for optimal usage. Contributions and feedback are welcome for project improvement and community engagement.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.