
AI-and-competition
这里用来存储做人工智能项目的代码和参加数据挖掘比赛的代码
Stars: 51
This repository provides baselines for various competitions, a few top solutions for some competitions, and independent deep learning projects. Baselines serve as entry guides for competitions, suitable for beginners to make their first submission. Top solutions are more complex and refined versions of baselines, with limited quantity but enhanced quality. The repository is maintained by a single author, yunsuxiaozi, offering code improvements and annotations for better understanding. Users can support the repository by learning from it and providing feedback.
README:
该仓库主要是各种比赛的baseline和少量比赛的topline,还有一些独立于比赛的深度学习项目。
baseline是各场比赛的入门指南,各位选手可以用baseline完成比赛的第一次提交。baseline相对简单,容易上手,适合初学者学习。
topline是各场比赛的前排方案。由于是topline,方案相比baseline会更加复杂,整理起来也更加不易,所以目前仓库topline的数量也比较有限。目前仓库里的topline都是作者在各场比赛中在原作者代码的基础上完善而来,修正了原作者的一些错误,删除了无用的代码,并给代码添加了一定的注释方便各位理解。如果你需要学习各场比赛的topline,来我的仓库会比看原作者的代码更加容易理解。
如果你从中学到了东西不要忘记动动发财的小手支持一下本仓库。
目前该仓库只有作者1人维护,难免会存在疏忽。如果你发现任何问题或者有任何建议欢迎联系。
作者的github和Kaggle名都为yunsuxiaozi,即:匀速小子。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AI-and-competition
Similar Open Source Tools
AI-and-competition
This repository provides baselines for various competitions, a few top solutions for some competitions, and independent deep learning projects. Baselines serve as entry guides for competitions, suitable for beginners to make their first submission. Top solutions are more complex and refined versions of baselines, with limited quantity but enhanced quality. The repository is maintained by a single author, yunsuxiaozi, offering code improvements and annotations for better understanding. Users can support the repository by learning from it and providing feedback.
awesome-LLM-resources
This repository is a curated list of resources for learning and working with Large Language Models (LLMs). It includes a collection of articles, tutorials, tools, datasets, and research papers related to LLMs such as GPT-3, BERT, and Transformer models. Whether you are a researcher, developer, or enthusiast interested in natural language processing and artificial intelligence, this repository provides valuable resources to help you understand, implement, and experiment with LLMs.

God-Level-AI
A drill of scientific methods, processes, algorithms, and systems to build stories & models. An in-depth learning resource for humans. This repository is designed for individuals aiming to excel in the field of Data and AI, providing video sessions and text content for learning. It caters to those in leadership positions, professionals, and students, emphasizing the need for dedicated effort to achieve excellence in the tech field. The content covers various topics with a focus on practical application.
cs-self-learning
This repository serves as an archive for computer science learning notes, codes, and materials. It covers a wide range of topics including basic knowledge, AI, backend & big data, tools, and other related areas. The content is organized into sections and subsections for easy navigation and reference. Users can find learning resources, programming practices, and tutorials on various subjects such as languages, data structures & algorithms, AI, frameworks, databases, development tools, and more. The repository aims to support self-learning and skill development in the field of computer science.
ai-engineering-hub
The AI Engineering Hub is a repository that provides in-depth tutorials on LLMs and RAGs, real-world AI agent applications, and examples to implement, adapt, and scale in projects. It caters to beginners, practitioners, and researchers, offering resources for all skill levels to experiment and succeed in AI engineering.

OpenAI
OpenAI is a Swift community-maintained implementation over OpenAI public API. It is a non-profit artificial intelligence research organization founded in San Francisco, California in 2015. OpenAI's mission is to ensure safe and responsible use of AI for civic good, economic growth, and other public benefits. The repository provides functionalities for text completions, chats, image generation, audio processing, edits, embeddings, models, moderations, utilities, and Combine extensions.

llm-on-openshift
This repository provides resources, demos, and recipes for working with Large Language Models (LLMs) on OpenShift using OpenShift AI or Open Data Hub. It includes instructions for deploying inference servers for LLMs, such as vLLM, Hugging Face TGI, Caikit-TGIS-Serving, and Ollama. Additionally, it offers guidance on deploying serving runtimes, such as vLLM Serving Runtime and Hugging Face Text Generation Inference, in the Single-Model Serving stack of Open Data Hub or OpenShift AI. The repository also covers vector databases that can be used as a Vector Store for Retrieval Augmented Generation (RAG) applications, including Milvus, PostgreSQL+pgvector, and Redis. Furthermore, it provides examples of inference and application usage, such as Caikit, Langchain, Langflow, and UI examples.
GenAiGuidebook
GenAiGuidebook is a comprehensive resource for individuals looking to begin their journey in GenAI. It serves as a detailed guide providing insights, tips, and information on various aspects of GenAI technology. The guidebook covers a wide range of topics, including introductory concepts, practical applications, and best practices in the field of GenAI. Whether you are a beginner or an experienced professional, this resource aims to enhance your understanding and proficiency in GenAI.

open-ai
Open AI is a powerful tool for artificial intelligence research and development. It provides a wide range of machine learning models and algorithms, making it easier for developers to create innovative AI applications. With Open AI, users can explore cutting-edge technologies such as natural language processing, computer vision, and reinforcement learning. The platform offers a user-friendly interface and comprehensive documentation to support users in building and deploying AI solutions. Whether you are a beginner or an experienced AI practitioner, Open AI offers the tools and resources you need to accelerate your AI projects and stay ahead in the rapidly evolving field of artificial intelligence.
Awesome-RAG
Awesome-RAG is a repository that lists recent developments in Retrieval-Augmented Generation (RAG) for large language models (LLM). It includes accepted papers, evaluation datasets, latest news, and papers from various conferences like NIPS, EMNLP, ACL, ICML, and ICLR. The repository is continuously updated and aims to build a general framework for RAG. Researchers are encouraged to submit pull requests to update information in their papers. The repository covers a wide range of topics related to RAG, including knowledge-enhanced generation, contrastive reasoning, self-alignment, mobile agents, and more.
GEN-AI
GEN-AI is a versatile Python library for implementing various artificial intelligence algorithms and models. It provides a wide range of tools and functionalities to support machine learning, deep learning, natural language processing, computer vision, and reinforcement learning tasks. With GEN-AI, users can easily build, train, and deploy AI models for diverse applications such as image recognition, text classification, sentiment analysis, object detection, and game playing. The library is designed to be user-friendly, efficient, and scalable, making it suitable for both beginners and experienced AI practitioners.

BrowserGym
BrowserGym is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides benchmarks like MiniWoB, WebArena, VisualWebArena, WorkArena, AssistantBench, and WebLINX. Users can design new web benchmarks by inheriting the AbstractBrowserTask class. The tool allows users to install different packages for core functionalities, experiments, and specific benchmarks. It supports the development setup and offers boilerplate code for running agents on various tasks. BrowserGym is not a consumer product and should be used with caution.

ai
This repository contains a collection of AI algorithms and models for various machine learning tasks. It provides implementations of popular algorithms such as neural networks, decision trees, and support vector machines. The code is well-documented and easy to understand, making it suitable for both beginners and experienced developers. The repository also includes example datasets and tutorials to help users get started with building and training AI models. Whether you are a student learning about AI or a professional working on machine learning projects, this repository can be a valuable resource for your development journey.

lemonai
LemonAI is a versatile machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and algorithms for data preprocessing, model training, and evaluation. With LemonAI, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is well-documented and beginner-friendly, making it suitable for both novice and experienced data scientists. LemonAI aims to streamline the development of AI applications and empower users to create innovative solutions using state-of-the-art machine learning methods.

enterprise-h2ogpte
Enterprise h2oGPTe - GenAI RAG is a repository containing code examples, notebooks, and benchmarks for the enterprise version of h2oGPTe, a powerful AI tool for generating text based on the RAG (Retrieval-Augmented Generation) architecture. The repository provides resources for leveraging h2oGPTe in enterprise settings, including implementation guides, performance evaluations, and best practices. Users can explore various applications of h2oGPTe in natural language processing tasks, such as text generation, content creation, and conversational AI.

pdr_ai_v2
pdr_ai_v2 is a Python library for implementing machine learning algorithms and models. It provides a wide range of tools and functionalities for data preprocessing, model training, evaluation, and deployment. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists. With pdr_ai_v2, users can easily build and deploy machine learning models for various applications, such as classification, regression, clustering, and more.
For similar tasks
AI-and-competition
This repository provides baselines for various competitions, a few top solutions for some competitions, and independent deep learning projects. Baselines serve as entry guides for competitions, suitable for beginners to make their first submission. Top solutions are more complex and refined versions of baselines, with limited quantity but enhanced quality. The repository is maintained by a single author, yunsuxiaozi, offering code improvements and annotations for better understanding. Users can support the repository by learning from it and providing feedback.
DeGPT
DeGPT is a tool designed to optimize decompiler output using Large Language Models (LLM). It requires manual installation of specific packages and setting up API key for OpenAI. The tool provides functionality to perform optimization on decompiler output by running specific scripts.
OpenDevin
OpenDevin is an open-source project aiming to replicate Devin, an autonomous AI software engineer capable of executing complex engineering tasks and collaborating actively with users on software development projects. The project aspires to enhance and innovate upon Devin through the power of the open-source community. Users can contribute to the project by developing core functionalities, frontend interface, or sandboxing solutions, participating in research and evaluation of LLMs in software engineering, and providing feedback and testing on the OpenDevin toolset.
Comfyui-Aix-NodeMap
Comfyui-Aix-NodeMap is a project by the Aix team to organize and annotate the latest nodes in Comfyui. It aims to address the challenge of finding nodes effectively as their number increases. The project is continuously updated every 7 days, with the opportunity for users to provide feedback on any omissions or errors. The team respects developers' opinions and strives to make corrections promptly. The project is part of Aix's vision to make humanity more efficient through open-source contributions, including daily updates on workflow, AI information, and node introductions.
ai-tag
AI tag generator that combines 40,000 tags from Bilibili UP main Twelve Today is also very cute with Chinese translations from Novelai, providing Chinese search and tag generation services. It offers a tag community for magicians to directly copy and generate spells. Always free, no ads, no commercial use. The project includes a pure tag parsing library, independent spell parsing library, tag data repository, and a new gallery page with waterfall flow for viewing community images.

gemini-ai-code-reviewer
Gemini AI Code Reviewer is a GitHub Action that automatically reviews pull requests using Google's Gemini AI. It analyzes code changes, consults the Gemini model, provides feedback, and delivers review comments directly to pull requests on GitHub. Users need a Gemini API key and can trigger the workflow by commenting '/gemini-review' in the PR. The tool helps improve source code quality by giving suggestions and comments for enhancement.
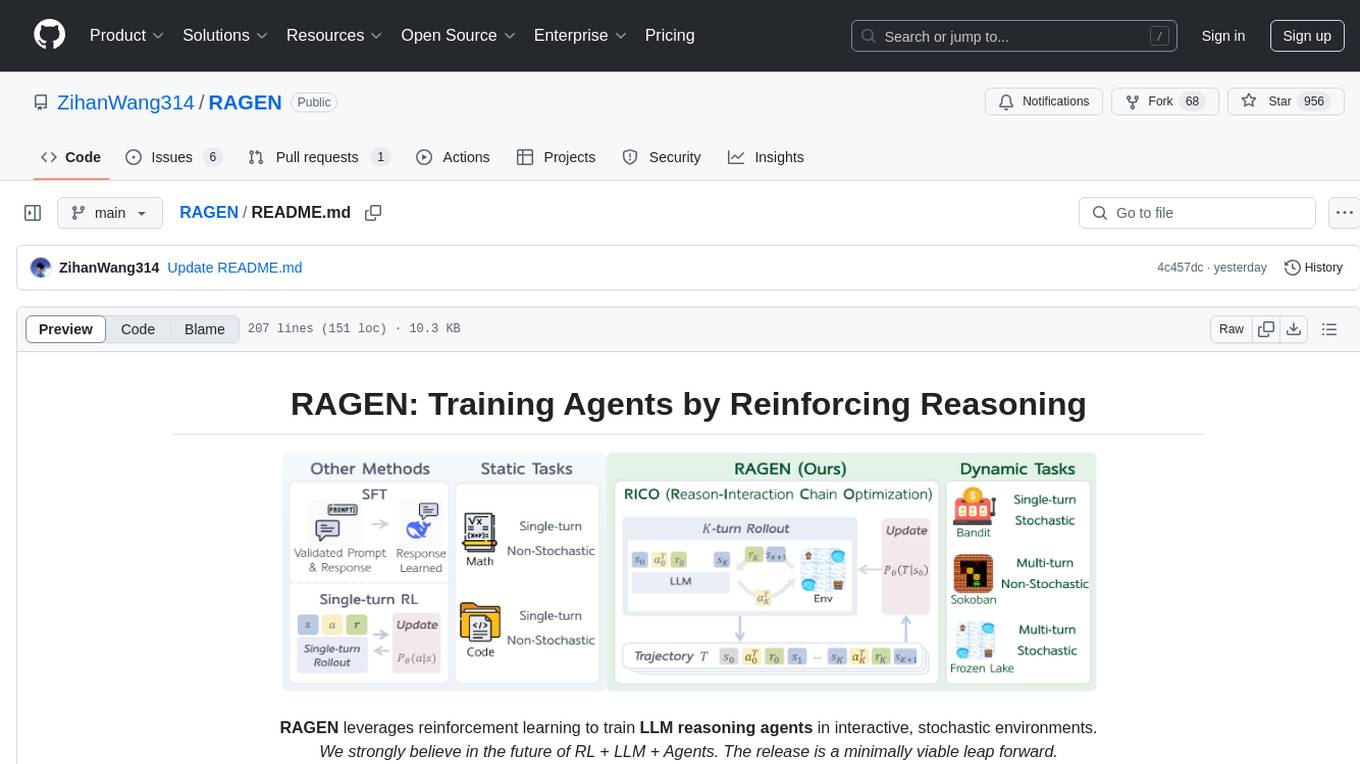
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.
Comfyui-Aix-NodeMap
Comfyui-Aix-NodeMap is a project by the Aix team to organize and annotate the latest nodes in Comfyui. It aims to address the challenge of finding nodes effectively due to the increasing number of nodes. The project is updated every 7 days to provide the most recent node information. Users can provide feedback for any omissions or errors, and corrections will be made promptly. The project respects every developer and values community collaboration in improving node exposure and accessibility.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.