
trulens
Evaluation and Tracking for LLM Experiments and AI Agents
Stars: 2798
TruLens provides a set of tools for developing and monitoring neural nets, including large language models. This includes both tools for evaluation of LLMs and LLM-based applications with _TruLens-Eval_ and deep learning explainability with _TruLens-Explain_. _TruLens-Eval_ and _TruLens-Explain_ are housed in separate packages and can be used independently.
README:





Don't just vibe-check your LLM app! Systematically evaluate and track your LLM experiments with TruLens. As you develop your app including prompts, models, retrievers, knowledge sources and more, TruLens is the tool you need to understand its performance.
Fine-grained, stack-agnostic instrumentation and comprehensive evaluations help you to identify failure modes & systematically iterate to improve your application.
Read more about the core concepts behind TruLens including Feedback Functions, The RAG Triad, and Honest, Harmless and Helpful Evals.
Build your first prototype then connect instrumentation and logging with TruLens. Decide what feedbacks you need, and specify them with TruLens to run alongside your app. Then iterate and compare versions of your app in an easy-to-use user interface 👇
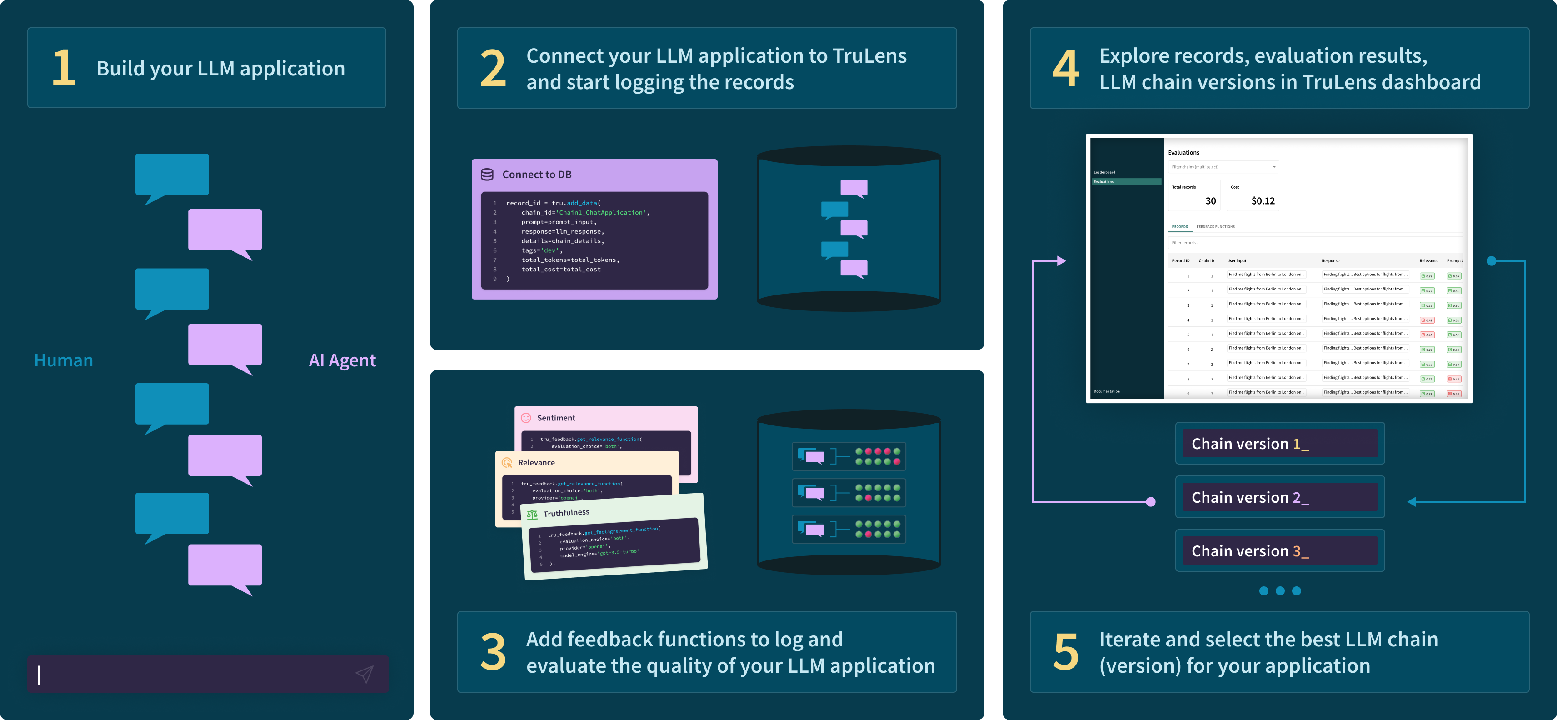
Install the trulens pip package from PyPI.
pip install trulensWalk through how to instrument and evaluate a RAG built from scratch with TruLens.
Interested in contributing? See our contributing guide for more details.
The best way to support TruLens is to give us a ⭐ on GitHub and join our discourse community!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for trulens
Similar Open Source Tools
trulens
TruLens provides a set of tools for developing and monitoring neural nets, including large language models. This includes both tools for evaluation of LLMs and LLM-based applications with _TruLens-Eval_ and deep learning explainability with _TruLens-Explain_. _TruLens-Eval_ and _TruLens-Explain_ are housed in separate packages and can be used independently.

dxos
DXOS is an open-source platform that offers Composer, an extensible app platform for developers to organize and sync their knowledge across devices. It enables real-time or offline collaboration with others, emphasizing a local-first and private approach. The DXOS SDK facilitates peer-to-peer collaboration for local-first apps without relying on central sync servers.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.
skyflo
Skyflo.ai is an AI agent designed for Cloud Native operations, providing seamless infrastructure management through natural language interactions. It serves as a safety-first co-pilot with a human-in-the-loop design. The tool offers flexible deployment options for both production and local Kubernetes environments, supporting various LLM providers and self-hosted models. Users can explore the architecture of Skyflo.ai and contribute to its development following the provided guidelines and Code of Conduct. The community engagement includes Discord, Twitter, YouTube, and GitHub Discussions.

koordinator
Koordinator is a QoS based scheduling system for hybrid orchestration workloads on Kubernetes. It aims to improve runtime efficiency and reliability of latency sensitive workloads and batch jobs, simplify resource-related configuration tuning, and increase pod deployment density. It enhances Kubernetes user experience by optimizing resource utilization, improving performance, providing flexible scheduling policies, and easy integration into existing clusters.
agent-evaluation
Agent Evaluation is a generative AI-powered framework for testing virtual agents. It implements an LLM agent (evaluator) to orchestrate conversations with your own agent (target) and evaluate responses. It supports popular AWS services, allows concurrent multi-turn conversations, defines hooks for additional tasks, and can be used in CI/CD pipelines for faster delivery and stable production environments.

cloudberry
Apache Cloudberry (Incubating) is an advanced and mature open-source Massively Parallel Processing (MPP) database, evolving from the open-source version of the Pivotal Greenplum Database®️. It features a newer PostgreSQL kernel and advanced enterprise capabilities, serving as a data warehouse for large-scale analytics and AI/ML workloads. The main repository includes ecosystem repositories for the website, extensions, connectors, adapters, and utilities.
DotRecast
DotRecast is a C# port of Recast & Detour, a navigation library used in many AAA and indie games and engines. It provides automatic navmesh generation, fast turnaround times, detailed customization options, and is dependency-free. Recast Navigation is divided into multiple modules, each contained in its own folder: - DotRecast.Core: Core utils - DotRecast.Recast: Navmesh generation - DotRecast.Detour: Runtime loading of navmesh data, pathfinding, navmesh queries - DotRecast.Detour.TileCache: Navmesh streaming. Useful for large levels and open-world games - DotRecast.Detour.Crowd: Agent movement, collision avoidance, and crowd simulation - DotRecast.Detour.Dynamic: Robust support for dynamic nav meshes combining pre-built voxels with dynamic objects which can be freely added and removed - DotRecast.Detour.Extras: Simple tool to import navmeshes created with A* Pathfinding Project - DotRecast.Recast.Toolset: All modules - DotRecast.Recast.Demo: Standalone, comprehensive demo app showcasing all aspects of Recast & Detour's functionality - Tests: Unit tests Recast constructs a navmesh through a multi-step mesh rasterization process: 1. First Recast rasterizes the input triangle meshes into voxels. 2. Voxels in areas where agents would not be able to move are filtered and removed. 3. The walkable areas described by the voxel grid are then divided into sets of polygonal regions. 4. The navigation polygons are generated by re-triangulating the generated polygonal regions into a navmesh. You can use Recast to build a single navmesh, or a tiled navmesh. Single meshes are suitable for many simple, static cases and are easy to work with. Tiled navmeshes are more complex to work with but better support larger, more dynamic environments. Tiled meshes enable advanced Detour features like re-baking, hierarchical path-planning, and navmesh data-streaming.

trainer
Kubeflow Trainer is a Kubernetes-native project for fine-tuning large language models (LLMs) and enabling scalable, distributed training of machine learning (ML) models across various frameworks. It allows integration with ML libraries like HuggingFace, DeepSpeed, or Megatron-LM to orchestrate ML training on Kubernetes. Develop LLMs effortlessly with the Kubeflow Python SDK and build Kubernetes-native Training Runtimes with Kubernetes Custom Resources APIs.

machine-learning
Ocademy is an AI learning community dedicated to Python, Data Science, Machine Learning, Deep Learning, and MLOps. They promote equal opportunities for everyone to access AI through open-source educational resources. The repository contains curated AI courses, tutorials, books, tools, and resources for learning and creating Generative AI. It also offers an interactive book to help adults transition into AI. Contributors are welcome to join and contribute to the community by following guidelines. The project follows a code of conduct to ensure inclusivity and welcomes contributions from those passionate about Data Science and AI.
ragna
Ragna is a RAG orchestration framework designed for managing workflows and orchestrating tasks. It provides a comprehensive set of features for users to streamline their processes and automate repetitive tasks. With Ragna, users can easily create, schedule, and monitor workflows, making it an ideal tool for teams and individuals looking to improve their productivity and efficiency. The framework offers extensive documentation, community support, and a user-friendly interface, making it accessible to users of all skill levels. Whether you are a developer, data scientist, or project manager, Ragna can help you simplify your workflow management and boost your overall performance.

Vento
Vento is an AI-driven machine automation platform that utilizes a Large Language Model (LLM) to automate the control of physical devices and machines. It features a natural language autopilot system for smart and industrial devices, providing a continuous decision loop for sensor states evaluation and actuator triggering. The platform offers a user-friendly UI for device onboarding, rule configuration, and real-time monitoring. Vento supports connected devices (IoT) based on ESP32 with ESPHome, allowing users to program, deploy, and manage IoT networks visually. Additionally, it provides AI assistance for creating rules and system management through automatic context transfer and prompt cascading.
buildel
Buildel is an AI automation platform that empowers users to create versatile workflows without writing code. It supports multiple providers and interfaces, offers pre-built use cases, and allows users to bring their own API keys. Ideal for AI-powered document retrieval, conversational interfaces, and data integration. Users can get started at app.buildel.ai or run Buildel locally with Node.js, Elixir/Erlang, Docker, Git, and JQ installed. Join the community on Discord for support and discussions.

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.
MaixCDK
MaixCDK (Maix C/CPP Development Kit) is a C/C++ development kit that integrates practical functions such as AI, machine vision, and IoT. It provides easy-to-use encapsulation for quickly building projects in vision, artificial intelligence, IoT, robotics, industrial cameras, and more. It supports hardware-accelerated execution of AI models, common vision algorithms, OpenCV, and interfaces for peripheral operations. MaixCDK offers cross-platform support, easy-to-use API, simple environment setup, online debugging, and a complete ecosystem including MaixPy and MaixVision. Supported devices include Sipeed MaixCAM, Sipeed MaixCAM-Pro, and partial support for Common Linux.
devopness
Devopness is a tool that simplifies the management of cloud applications and multi-cloud infrastructure for both AI agents and humans. It provides role-based access control, permission management, cost control, and visibility into DevOps and CI/CD workflows. The tool allows provisioning and deployment to major cloud providers like AWS, Azure, DigitalOcean, and GCP. Devopness aims to make software deployment and cloud infrastructure management accessible and affordable to all involved in software projects.
For similar tasks
trulens
TruLens provides a set of tools for developing and monitoring neural nets, including large language models. This includes both tools for evaluation of LLMs and LLM-based applications with _TruLens-Eval_ and deep learning explainability with _TruLens-Explain_. _TruLens-Eval_ and _TruLens-Explain_ are housed in separate packages and can be used independently.

litgpt
LitGPT is a command-line tool designed to easily finetune, pretrain, evaluate, and deploy 20+ LLMs **on your own data**. It features highly-optimized training recipes for the world's most powerful open-source large-language-models (LLMs).

torchtune
Torchtune is a PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. It provides native-PyTorch implementations of popular LLMs using composable and modular building blocks, easy-to-use and hackable training recipes for popular fine-tuning techniques, YAML configs for easily configuring training, evaluation, quantization, or inference recipes, and built-in support for many popular dataset formats and prompt templates to help you quickly get started with training.

agenta
Agenta is an open-source LLM developer platform for prompt engineering, evaluation, human feedback, and deployment of complex LLM applications. It provides tools for prompt engineering and management, evaluation, human annotation, and deployment, all without imposing any restrictions on your choice of framework, library, or model. Agenta allows developers and product teams to collaborate in building production-grade LLM-powered applications in less time.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.
evals
Evals provide a framework for evaluating large language models (LLMs) or systems built using LLMs. We offer an existing registry of evals to test different dimensions of OpenAI models and the ability to write your own custom evals for use cases you care about. You can also use your data to build private evals which represent the common LLMs patterns in your workflow without exposing any of that data publicly.
Play-with-LLMs
This repository provides a comprehensive guide to training, evaluating, and building applications with Large Language Models (LLMs). It covers various aspects of LLMs, including pretraining, fine-tuning, reinforcement learning from human feedback (RLHF), and more. The repository also includes practical examples and code snippets to help users get started with LLMs quickly and easily.

llm-foundry
LLM Foundry is a codebase for training, finetuning, evaluating, and deploying LLMs for inference with Composer and the MosaicML platform. It is designed to be easy-to-use, efficient _and_ flexible, enabling rapid experimentation with the latest techniques. You'll find in this repo: * `llmfoundry/` - source code for models, datasets, callbacks, utilities, etc. * `scripts/` - scripts to run LLM workloads * `data_prep/` - convert text data from original sources to StreamingDataset format * `train/` - train or finetune HuggingFace and MPT models from 125M - 70B parameters * `train/benchmarking` - profile training throughput and MFU * `inference/` - convert models to HuggingFace or ONNX format, and generate responses * `inference/benchmarking` - profile inference latency and throughput * `eval/` - evaluate LLMs on academic (or custom) in-context-learning tasks * `mcli/` - launch any of these workloads using MCLI and the MosaicML platform * `TUTORIAL.md` - a deeper dive into the repo, example workflows, and FAQs
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.