
ShortGPT
🚀🎬 ShortGPT - Experimental AI framework for youtube shorts / tiktok channel automation
Stars: 5548
ShortGPT is a powerful framework for automating content creation, simplifying video creation, footage sourcing, voiceover synthesis, and editing tasks. It offers features like automated editing framework, scripts and prompts, voiceover support in multiple languages, caption generation, asset sourcing, and persistency of editing variables. The tool is designed for youtube automation, Tiktok creativity program automation, and offers customization options for efficient and creative content creation.
README:

Follow the installation steps below for running the web app locally (running the google Colab is highly recommanded). Please read "installation-notes.md" for more details.
🎥 Showcase (Full video on YouTube)
https://github.com/RayVentura/ShortGPT/assets/121462835/a802faad-0fd7-4fcb-aa82-6365c27ea5fe
https://github.com/RayVentura/ShortGPT/assets/121462835/06f51b2d-f8b1-4a23-b299-55e0e18902ef
We hope you find ShortGPT helpful! If you do, let us know by giving us a star ⭐ on the repo. It's easy, just click on the 'Star' button at the top right of the page. Your support means a lot to us and keeps us motivated to improve and expand ShortGPT. Thank you and happy content creating! 🎉
ShortGPT is a powerful framework for automating content creation. It simplifies video creation, footage sourcing, voiceover synthesis, and editing tasks. Of the most popular use-cases of ShortGPT is youtube automation and Tiktok creativity program automation.
-
🎞️ Automated editing framework: Streamlines the video creation process with an LLM oriented video editing language.
-
📃 Scripts and Prompts: Provides ready-to-use scripts and prompts for various LLM automated editing processes.
-
🗣️ Voiceover / Content Creation: Supports multiple languages including English 🇺🇸, Spanish 🇪🇸, Arabic 🇦🇪, French 🇫🇷, Polish 🇵🇱, German 🇩🇪, Italian 🇮🇹, Portuguese 🇵🇹, Russian 🇷🇺, Mandarin Chinese 🇨🇳, Japanese 🇯🇵, Hindi 🇮🇳,Korean 🇰🇷, and way over 30 more languages (with EdgeTTS)
-
🔗 Caption Generation: Automates the generation of video captions.
-
🌐🎥 Asset Sourcing: Sources images and video footage from the internet, connecting with the web and Pexels API as necessary.
-
🧠 Memory and persistency: Ensures long-term persistency of automated editing variables with TinyDB.
🚀 Quick Start: Run ShortGPT on Google Colab (https://colab.research.google.com/drive/1_2UKdpF6lqxCqWaAcZb3rwMVQqtbisdE?usp=sharing)
If you prefer not to install the prerequisites on your local system, you can use the Google Colab notebook. This option is free and requires no installation setup.
-
Click on the link to the Google Colab notebook: https://colab.research.google.com/drive/1_2UKdpF6lqxCqWaAcZb3rwMVQqtbisdE?usp=sharing
-
Once you're in the notebook, simply run the cells in order from top to bottom. You can do this by clicking on each cell and pressing the 'Play' button, or by using the keyboard . Enjoy using ShortGPT!
This guide provides step-by-step instructions for installing shortGPT and its dependencies. To run ShortGPT locally, you need Docker.
To run ShortGPT, you need to have docker. Follow the instructions "installation-notes.md" for more details.
- For running the Dockerfile, do this:
docker build -t short_gpt_docker:latest .
docker run -p 31415:31415 --env-file .env short_gpt_docker:latest- After running the script, a Gradio interface should open at your local host on port 31415 (http://localhost:31415)
-
🎬 The
ContentShortEngineis designed for creating shorts, handling tasks from script generation to final rendering, including adding YouTube metadata. -
🎥 The
ContentVideoEngineis ideal for longer videos, taking care of tasks like generating audio, automatically sourcing background video footage, timing captions, and preparing background assets. -
🗣️ The
ContentTranslationEngineis designed to dub and translate entire videos, from mainstream languages to more specific target languages. It takes a video file, or youtube link, transcribe it's audio, translates the content, voices it in a target language, adds captions , and gives back a new video, in a totally different language. -
🎞️ The automated
EditingEngine, using Editing Markup Language and JSON, breaks down the editing process into manageable and customizable blocks, comprehensible to Large Language Models.
💡 ShortGPT offers customization options to suit your needs, from language selection to watermark addition.
🔧 As a framework, ShortGPT is adaptable and flexible, offering the potential for efficient, creative content creation.
More documentation incomming, please be patient.
ShortGPT utilizes the following technologies to power its functionality:
-
Moviepy: Moviepy is used for video editing, allowing ShortGPT to make video editing and rendering
-
Openai: Openai is used for automating the entire process, including generating scripts and prompts for LLM automated editing processes.
-
ElevenLabs: ElevenLabs is used for voice synthesis, supporting multiple languages for voiceover creation.
-
EdgeTTS: Microsoft's FREE EdgeTTS is used for voice synthesis, supporting way many more language than ElevenLabs currently.
-
Pexels: Pexels is used for sourcing background footage, allowing ShortGPT to connect with the web and access a wide range of images and videos.
-
Bing Image: Bing Image is used for sourcing images, providing a comprehensive database for ShortGPT to retrieve relevant visuals.
These technologies work together to provide a seamless and efficient experience in automating video and short content creation with AI.
As an open-source project in a rapidly developing field, we are extremely open to contributions, whether it would be in the form of a new feature, improved infrastructure, or better documentation.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ShortGPT
Similar Open Source Tools
ShortGPT
ShortGPT is a powerful framework for automating content creation, simplifying video creation, footage sourcing, voiceover synthesis, and editing tasks. It offers features like automated editing framework, scripts and prompts, voiceover support in multiple languages, caption generation, asset sourcing, and persistency of editing variables. The tool is designed for youtube automation, Tiktok creativity program automation, and offers customization options for efficient and creative content creation.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.
OpenCAGE
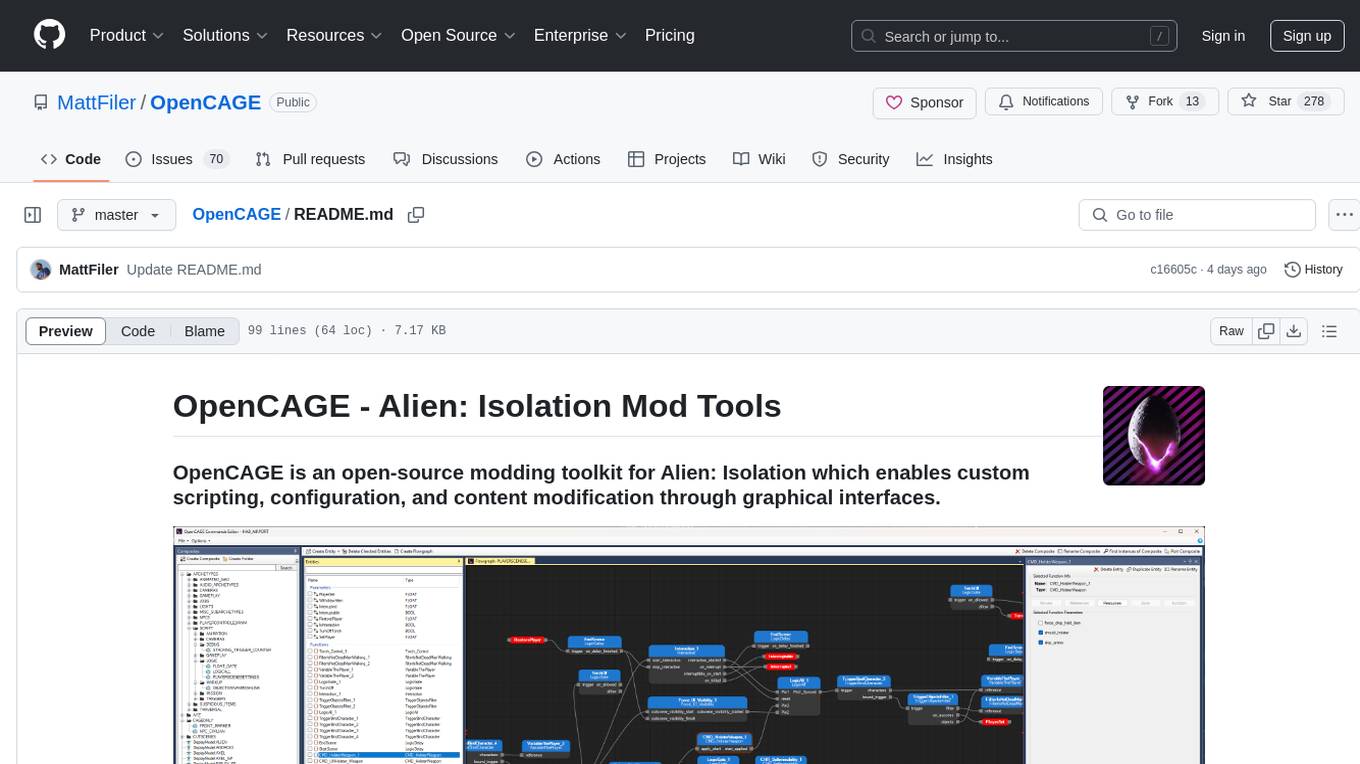
OpenCAGE is an open-source modding toolkit for Alien: Isolation, enabling custom scripting, configuration, and content modification through graphical interfaces. It includes tools for editing assets, configurations, scripts, behaviour trees, launching the game, and managing backups. The project is constantly evolving with a roadmap that includes features like contextual script editing, content porter, new level creator, mod installers, 3D viewer improvements, navmesh generation, skinned meshes support, sound import/export, and more. OpenCAGE is supported financially by the community and welcomes code contributions.
img-prompt
IMGPrompt is an AI prompt editor tailored for image and video generation tools like Stable Diffusion, Midjourney, DALL·E, FLUX, and Sora. It offers a clean interface for viewing and combining prompts with translations in multiple languages. The tool includes features like smart recommendations, translation, random color generation, prompt tagging, interactive editing, categorized tag display, character count, and localization. Users can enhance their creative workflow by simplifying prompt creation and boosting efficiency.

studio-b3
Studio B3 (B-3 Bomber) is a sophisticated editor designed for content creation, catering to various formats such as blogs, articles, user stories, and more. It provides an immersive content generation experience with local AI capabilities for intelligent search and recommendation functions. Users can define custom actions and variables for flexible content generation. The editor includes interactive tools like Bubble Menu, Slash Command, and Quick Insert for enhanced user experience in editing, searching, and navigation. The design principles focus on intelligent embedding of AI, local optimization for efficient writing experience, and context flexibility for better control over AI-generated content.

meilisearch
Meilisearch is a lightning-fast search engine that seamlessly integrates into apps, websites, and workflows. It offers features like hybrid search, search-as-you-type, typo tolerance, filtering, sorting, synonym support, geosearch, extensive language support, security management, multi-tenancy, RESTful API, AI-readiness, easy installation, deployment, and maintenance.
Symposium2023
Symposium2023 is a project aimed at enabling Delphi users to incorporate AI technology into their applications. It provides generalized interfaces to different AI models, making them easily accessible. The project showcases AI's versatility in tasks like language translation, human-like conversations, image generation, data analysis, and more. Users can experiment with different AI models, change providers easily, and avoid vendor lock-in. The project supports various AI features like vision support and function calling, utilizing providers like Google, Microsoft Azure, Amazon, OpenAI, and more. It includes example programs demonstrating tasks such as text-to-speech, language translation, face detection, weather querying, audio transcription, voice recognition, image generation, invoice processing, and API testing. The project also hints at potential future research areas like using embeddings for data search and integrating Python AI libraries with Delphi.
awesome-generative-ai
Awesome Generative AI is a curated list of modern Generative Artificial Intelligence projects and services. Generative AI technology creates original content like images, sounds, and texts using machine learning algorithms trained on large data sets. It can produce unique and realistic outputs such as photorealistic images, digital art, music, and writing. The repo covers a wide range of applications in art, entertainment, marketing, academia, and computer science.

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"
ChatGPT-Shortcut
ChatGPT Shortcut is an AI tool designed to maximize efficiency and productivity by providing a concise list of AI instructions. Users can easily find prompts suitable for various scenarios, boosting productivity and work efficiency. The tool offers one-click prompts, optimization for non-English languages, prompt saving and sharing, and a community voting system. It includes a browser extension compatible with Chrome, Edge, Firefox, and other Chromium-based browsers, as well as a Tampermonkey script for custom domain use. The tool is open-source, allowing users to modify the website's nomenclature, usage directives, and prompts for different languages.
CodeGPT
CodeGPT is an extension for JetBrains IDEs that provides access to state-of-the-art large language models (LLMs) for coding assistance. It offers a range of features to enhance the coding experience, including code completions, a ChatGPT-like interface for instant coding advice, commit message generation, reference file support, name suggestions, and offline development support. CodeGPT is designed to keep privacy in mind, ensuring that user data remains secure and private.
BloxAI
Blox AI is a platform that allows users to effortlessly create flowcharts and diagrams, collaborate with teams, and receive explanations from the Google Gemini model. It offers rich text editing, versatile visualizations, secure workspaces, and limited files allotment. Users can install it as an app and use it for wireframes, mind maps, and algorithms. The platform is built using Next.Js, Typescript, ShadCN UI, TailwindCSS, Convex, Kinde, EditorJS, and Excalidraw.

awesome-ai-tools
Awesome AI Tools is a curated list of popular tools and resources for artificial intelligence enthusiasts. It includes a wide range of tools such as machine learning libraries, deep learning frameworks, data visualization tools, and natural language processing resources. Whether you are a beginner or an experienced AI practitioner, this repository aims to provide you with a comprehensive collection of tools to enhance your AI projects and research. Explore the list to discover new tools, stay updated with the latest advancements in AI technology, and find the right resources to support your AI endeavors.

ProxyAI
ProxyAI is an open-source AI copilot for JetBrains, offering advanced code assistance features powered by top-tier language models. Users can customize their coding experience, receive AI-suggested code changes, autocomplete suggestions, and context-aware naming suggestions. The tool also allows users to chat with images, reference project files and folders, web docs, git history, and search the web. ProxyAI prioritizes user privacy by not collecting sensitive information and only gathering anonymous usage data with consent.

ZetaForge
ZetaForge is an open-source AI platform designed for rapid development of advanced AI and AGI pipelines. It allows users to assemble reusable, customizable, and containerized Blocks into highly visual AI Pipelines, enabling rapid experimentation and collaboration. With ZetaForge, users can work with AI technologies in any programming language, easily modify and update AI pipelines, dive into the code whenever needed, utilize community-driven blocks and pipelines, and share their own creations. The platform aims to accelerate the development and deployment of advanced AI solutions through its user-friendly interface and community support.
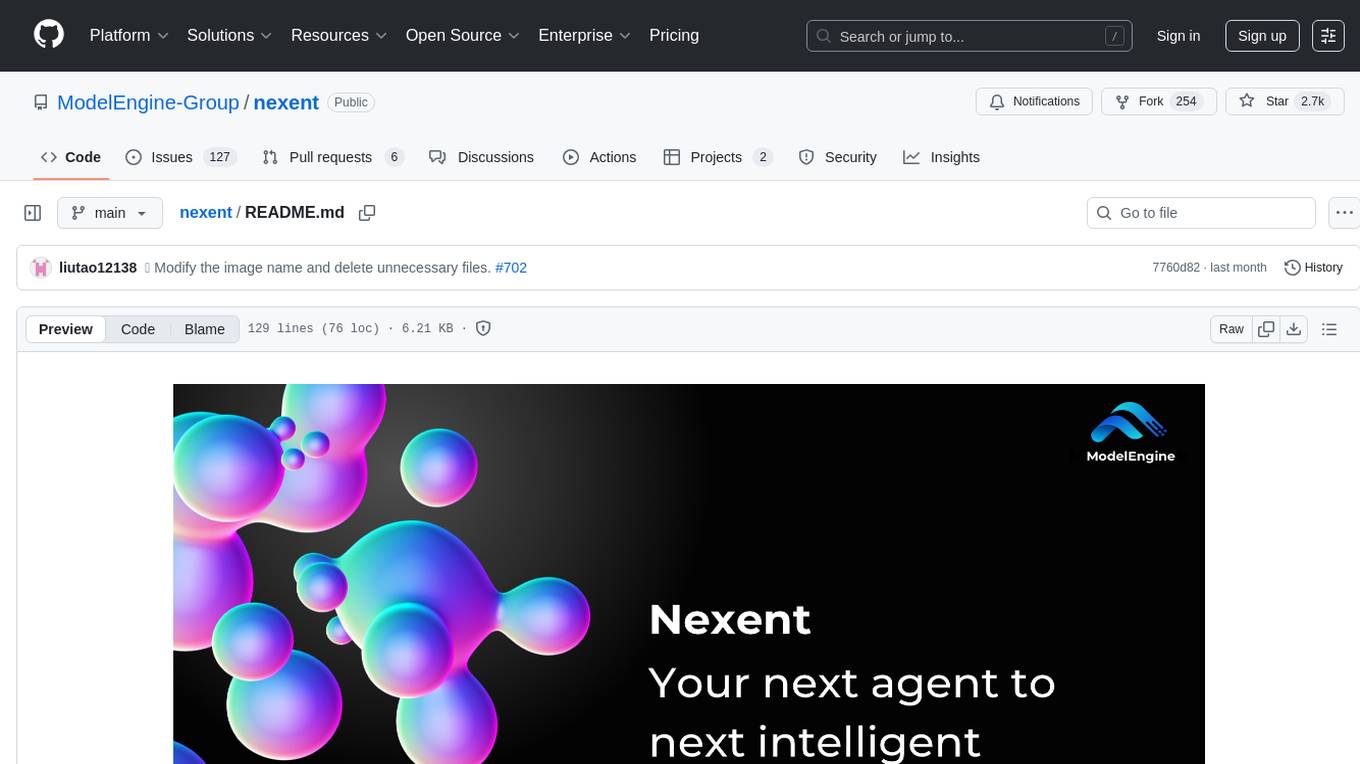
nexent
Nexent is a powerful tool for analyzing and visualizing network traffic data. It provides comprehensive insights into network behavior, helping users to identify patterns, anomalies, and potential security threats. With its user-friendly interface and advanced features, Nexent is suitable for network administrators, cybersecurity professionals, and anyone looking to gain a deeper understanding of their network infrastructure.
For similar tasks
ShortGPT
ShortGPT is a powerful framework for automating content creation, simplifying video creation, footage sourcing, voiceover synthesis, and editing tasks. It offers features like automated editing framework, scripts and prompts, voiceover support in multiple languages, caption generation, asset sourcing, and persistency of editing variables. The tool is designed for youtube automation, Tiktok creativity program automation, and offers customization options for efficient and creative content creation.
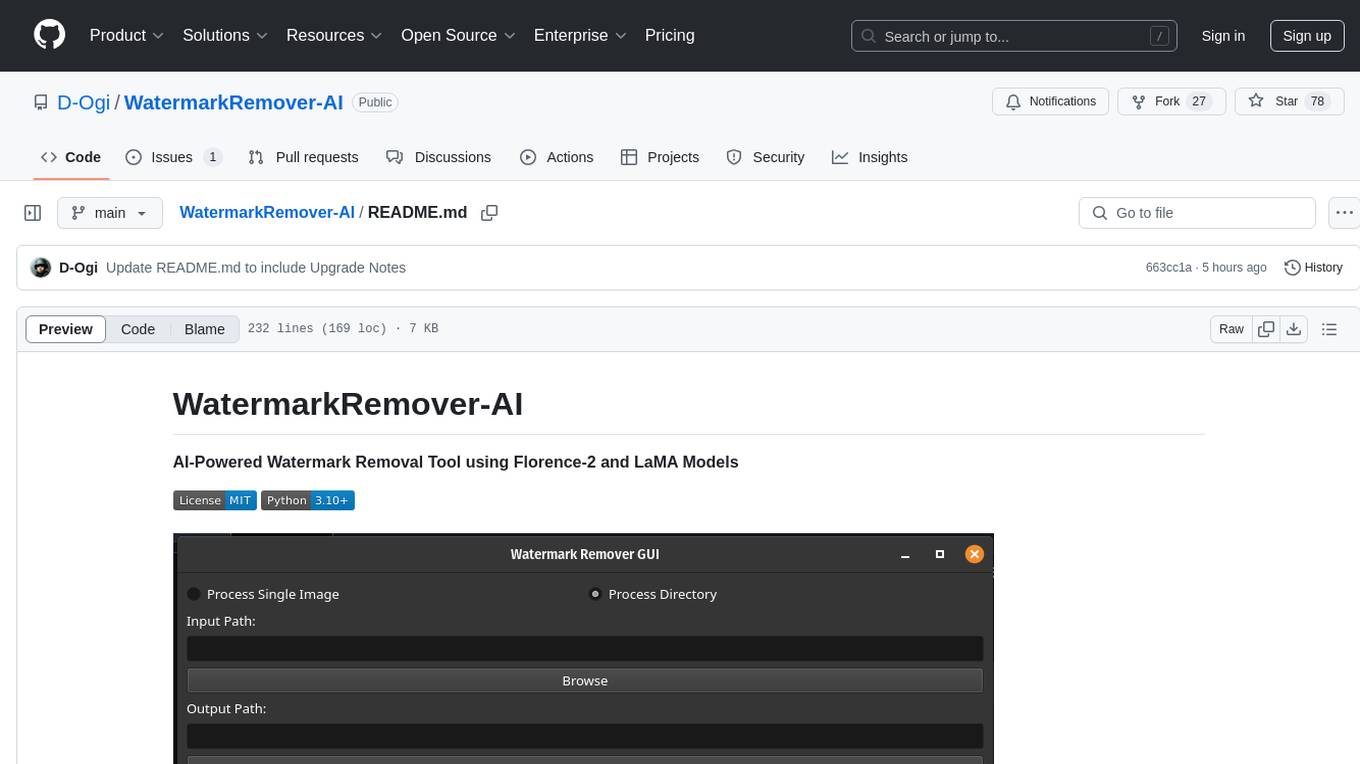
WatermarkRemover-AI
WatermarkRemover-AI is an advanced application that utilizes AI models for precise watermark detection and seamless removal. It leverages Florence-2 for watermark identification and LaMA for inpainting. The tool offers both a command-line interface (CLI) and a PyQt6-based graphical user interface (GUI), making it accessible to users of all levels. It supports dual modes for processing images, advanced watermark detection, seamless inpainting, customizable output settings, real-time progress tracking, dark mode support, and efficient GPU acceleration using CUDA.

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
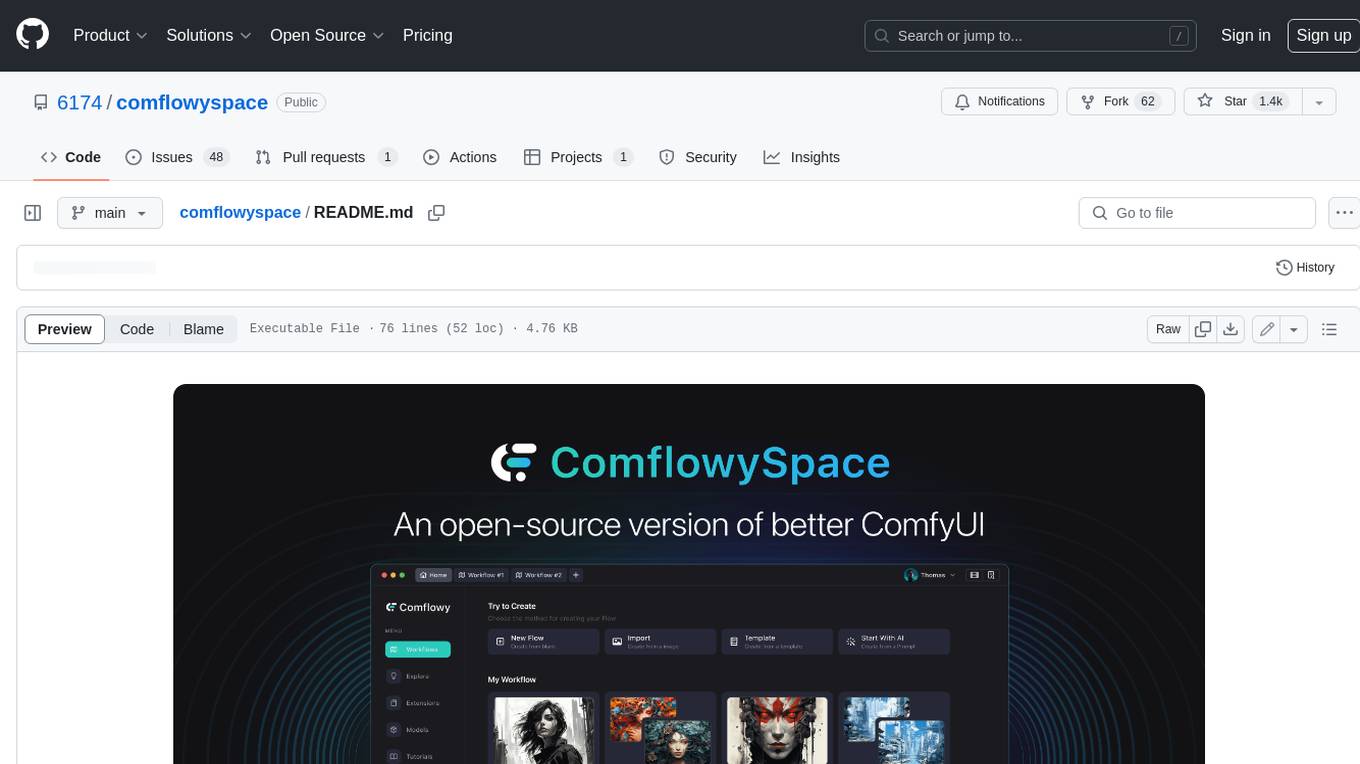
comflowyspace
Comflowyspace is an open-source AI image and video generation tool that aims to provide a more user-friendly and accessible experience than existing tools like SDWebUI and ComfyUI. It simplifies the installation, usage, and workflow management of AI image and video generation, making it easier for users to create and explore AI-generated content. Comflowyspace offers features such as one-click installation, workflow management, multi-tab functionality, workflow templates, and an improved user interface. It also provides tutorials and documentation to lower the learning curve for users. The tool is designed to make AI image and video generation more accessible and enjoyable for a wider range of users.
Rewind-AI-Main
Rewind AI is a free and open-source AI-powered video editing tool that allows users to easily create and edit videos. It features a user-friendly interface, a wide range of editing tools, and support for a variety of video formats. Rewind AI is perfect for beginners and experienced video editors alike.
MoneyPrinterTurbo
MoneyPrinterTurbo is a tool that can automatically generate video content based on a provided theme or keyword. It can create video scripts, materials, subtitles, and background music, and then compile them into a high-definition short video. The tool features a web interface and an API interface, supporting AI-generated video scripts, customizable scripts, multiple HD video sizes, batch video generation, customizable video segment duration, multilingual video scripts, multiple voice synthesis options, subtitle generation with font customization, background music selection, access to high-definition and copyright-free video materials, and integration with various AI models like OpenAI, moonshot, Azure, and more. The tool aims to simplify the video creation process and offers future plans to enhance voice synthesis, add video transition effects, provide more video material sources, offer video length options, include free network proxies, enable real-time voice and music previews, support additional voice synthesis services, and facilitate automatic uploads to YouTube platform.
Dough
Dough is a tool for crafting videos with AI, allowing users to guide video generations with precision using images and example videos. Users can create guidance frames, assemble shots, and animate them by defining parameters and selecting guidance videos. The tool aims to help users make beautiful and unique video creations, providing control over the generation process. Setup instructions are available for Linux and Windows platforms, with detailed steps for installation and running the app.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.