Best AI tools for< Voice Dubbing >
20 - AI tool Sites
Soca AI
Soca AI is a company that specializes in language and voice technology. They offer a variety of products and services for both consumers and enterprises, including a custom LLM for enterprise, a speech and audio API, and a voice and dubbing studio. Soca AI's mission is to democratize creativity and productivity through AI, and they are committed to developing multimodal AI systems that unleash superhuman potential.
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.
Dubbing AI
Dubbing AI is a free real-time AI voice changer that allows you to change your voice in real-time while speaking. It offers a variety of voice effects, including male, female, child, robot, and more. You can also use Dubbing AI to add sound effects and music to your recordings. Dubbing AI is perfect for creating funny videos, voiceovers, and other creative projects.

Dubbing AI
Dubbing AI is a free real-time AI voice changer that allows you to change your voice in real-time while speaking. It offers a variety of voice effects and filters that you can use to customize your voice. You can also use Dubbing AI to create funny or unique voiceovers for your videos or presentations.
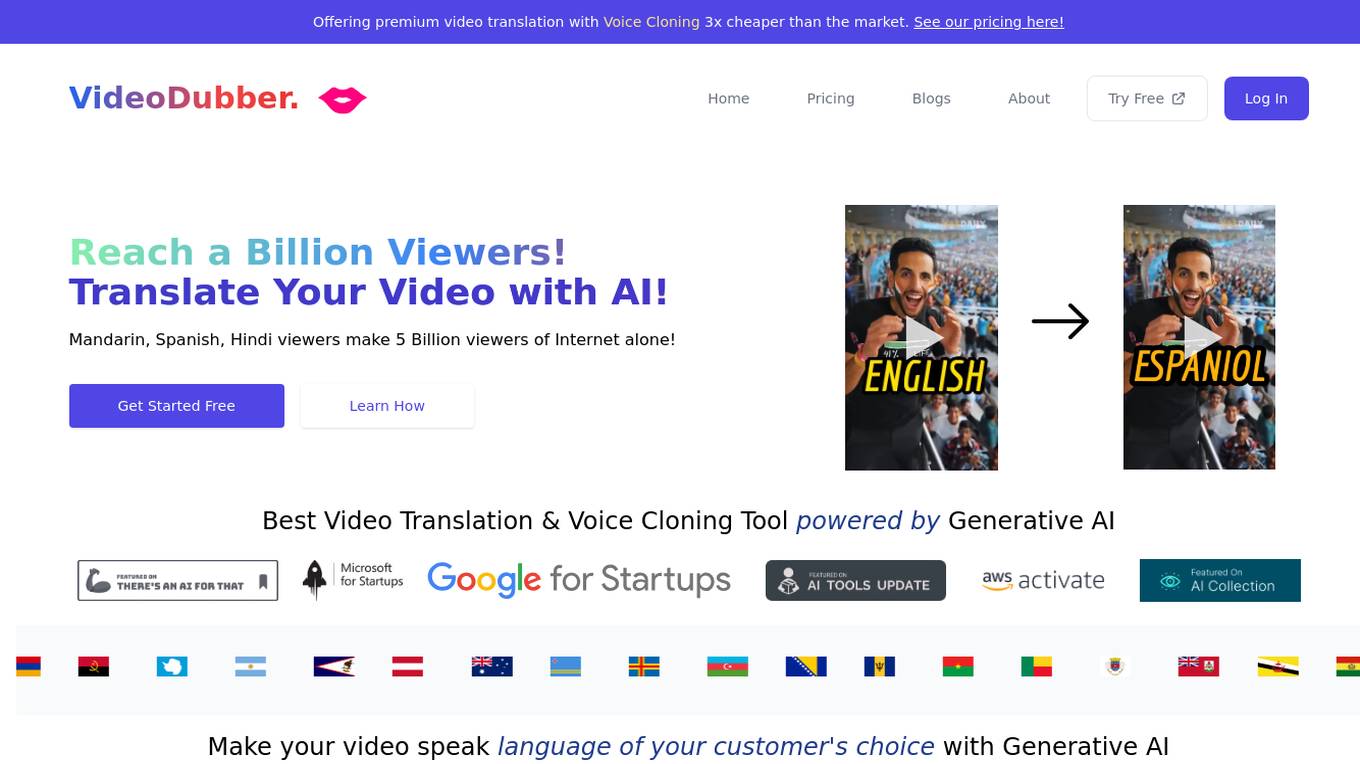
VideoDubber
VideoDubber is an AI-powered video translation and voice cloning tool that allows users to translate videos into over 150 languages with just one click. It also offers features such as voice cloning, text-to-speech, and subtitling. VideoDubber is designed to help businesses and content creators reach a global audience by making their videos accessible to viewers who speak different languages.
VideoDubber
VideoDubber is an AI-powered video translation and voice cloning tool that allows users to translate videos into over 150 languages with just one click. It also offers features such as voice cloning, text-to-speech, and subtitling. VideoDubber is a valuable tool for businesses and content creators who want to reach a global audience with their videos.
VideoDubber
VideoDubber is an AI-powered video translation and text-to-speech tool that offers premium video translation with voice cloning at a fraction of the market price. It enables users to make their videos speak in the language of their audience's choice using Generative AI. The platform supports translation to over 150 languages and accents, providing features like voice cloning, subtitles modification, and dubbing minutes. VideoDubber caters to a wide range of users, including Youtubers, businesses, and content creators, helping them reach a global audience and enhance viewer engagement through multilingual content.
Unmixr AI
Unmixr AI is a suite of AI products that includes AI Voiceover, Audio/Video Dubbing, AI Chat & Copywriting tools (AI Templates, AI Writing Editor, AI Chat, and AI Image Generator). With Unmixr AI, you can create realistic voiceovers, dub audio/video files, engage in dynamic chat conversations, refine your writing with AI assistance, generate stunning visuals, and more. Unmixr AI is designed to streamline your creative workflow and enhance your content effortlessly. It empowers your creativity and opens doors to endless possibilities, allowing you to unleash your imagination and captivate your audience.
UniDub
UniDub is a multi-lingual AI dubbing platform that allows users to create or dub videos in over 40 languages. It is cost-effective, expressive, super fast, and easy to use. UniDub can be used for a variety of purposes, including dubbing videos, creating animated videos, making audiobooks, and creating custom avatars and voices.
Celebrity AI Voice Generator
Celebrity AI Voice Generator is a free online tool that allows you to create realistic AI-generated voices of celebrities. With just a short audio clip of the person you want to replicate, you can generate voices that sound incredibly real. The tool is easy to use and offers a variety of features, including the ability to control voice styles, emotions, and accents. You can also use the tool to generate voices in different languages. Celebrity AI Voice Generator is a powerful tool that can be used for a variety of purposes, including creating voiceovers, dubbing videos, and developing video games.
DubVid
DubVid is a revolutionary AI-powered video translation tool that empowers you to break language barriers and captivate global audiences. With just a single click, you can translate videos into over 25 languages, clone your voice, and seamlessly lip-sync the translated audio, ensuring a natural and engaging viewing experience. Whether you're looking to expand your reach, enhance accessibility, or create multilingual marketing campaigns, DubVid has got you covered.
Rask AI
Rask AI is a leading tool for video localization and dubbing with artificial intelligence. It offers a wide range of features such as transcribing YouTube videos, video translation, transcription, adding subtitles, audio translation, text-to-speech conversion, and more. The platform is used for educational videos, marketing, multilingual audio on YouTube, content creation and distribution, employee and customer training, explainer videos, various children's content, game development, and sales videos. Rask AI provides innovative solutions for businesses and creators worldwide, enabling them to localize and reuse videos for marketing, conferences, podcasts, and more.
Speechify
Speechify is the #1 rated AI text to speech app in its category with over 250,000 5 star reviews. It is available as a Chrome extension, iOS app, Android app, Microsoft Edge Add-on, and web app. Speechify can convert any text into natural-sounding AI voice in over 50 languages and accents. It can also read aloud any PDF, doc, or web page. Speechify is used by students, professionals, readers, and those who struggle to read. It can help with reading comprehension, focus, and retention. Speechify is also a great tool for people with disabilities such as dyslexia, ADHD, and dry eyes.
Fineshare
Fineshare is an online AI audio creator tool that offers a wide range of features for voice, music, and sound generation. Users can transform their voice, create AI covers, generate audio from videos, transcribe audio to text, and more. The tool provides advanced AI technology to simplify audio creation and unlock creativity. Fineshare is trusted by over 10 million customers worldwide and offers personalized AI voice and professional-grade video voiceover capabilities.
Dubformer
Dubformer is an AI-powered dubbing and video localization provider that offers a secure and end-to-end solution for the media industry. With a focus on quality and speed, Dubformer's technology enables the creation of realistic and natural-sounding voice-overs in multiple languages, making video content more accessible and engaging for diverse audiences. The platform combines AI-driven processes with human quality control to ensure broadcast-quality results. Dubformer's services include AI dubbing, accurate and culturally sensitive translations, AI mixing for immersive soundscapes, and AI-powered subtitles and closed captions.
LangSwap
LangSwap is a cutting-edge video translation and dubbing platform that empowers users to translate their videos into multiple languages while preserving the original voice. With its advanced algorithms, LangSwap eliminates the need for time-consuming and expensive voice actors, allowing users to save significant time and money. The platform is incredibly user-friendly, making it accessible to anyone who needs to translate and dub videos. Whether you're an e-commerce marketer, a YouTube blogger, or a business looking to expand into new markets, LangSwap has the solution for you.
CloneDub
CloneDub is an AI-powered video dubbing platform that allows users to quickly and easily translate videos into over 20 languages. The platform uses a combination of machine learning and human expertise to create high-quality dubbed videos that maintain the original speaker's voice and the music and sounds of the original video. CloneDub is easy to use and offers a variety of features that make it a great choice for businesses and individuals who need to create dubbed videos.
Rask AI
Rask AI is an AI-powered video localization and dubbing tool that helps businesses and creators translate and adapt their video content for global audiences. With over 1,500,000 happy users, Rask AI offers a range of features to streamline the video localization process, including automatic transcription, translation, voice cloning, and multi-speaker support. The platform also provides access to a team of professional translators and voice actors to ensure the highest quality results.
Typecast
Typecast is an online AI voice generator and content creation tool that offers advanced AI voice models for creating natural and expressive voiceovers. With over 530 unique voices to choose from, Typecast's AI voice actors excel in narrating audiobooks, enhancing video games, creating rap music, delivering announcements, and crafting compelling marketing messages. The tool utilizes machine learning to produce lifelike speech with correct intonation, pausing, and breathing between words. Users can effortlessly create professional voice content, clone their own AI voice actors, and integrate voiceovers with video files for quick and easy content production.

Resemble AI
Resemble AI is a cutting-edge generative voice AI platform that empowers enterprises with advanced voice cloning, deepfake detection, and AI watermarking capabilities. Our suite of tools enables the creation of realistic synthetic voices, detection of AI-generated content, and protection of intellectual property. With Resemble AI, businesses can enhance customer service, elevate gaming experiences, revolutionize entertainment, and safeguard their digital assets.
1 - Open Source AI Tools
ShortGPT
ShortGPT is a powerful framework for automating content creation, simplifying video creation, footage sourcing, voiceover synthesis, and editing tasks. It offers features like automated editing framework, scripts and prompts, voiceover support in multiple languages, caption generation, asset sourcing, and persistency of editing variables. The tool is designed for youtube automation, Tiktok creativity program automation, and offers customization options for efficient and creative content creation.
20 - OpenAI Gpts
Dubbing Translator
Translator for video dubbing, focusing on timing, cultural nuances, and clarity.
Anime Voice Match
Anime Voice Match, identifies anime characters similar to the user's voice.
Voice/Style/Tone AI Prompt Snippet Generator
Analyzes your writing and produces a prompt snippet you can use in any other prompt to guide AI in replicating your voice, style, and tone. Just provide the text in the prompt box or in a document (don't use a link or image). You don't need to write any additional prompt language with your text.


Voice Memo
Record your thoughts with ChatGPT Voice Conversations 💡. Get started by clicking the 🎧 icon right to the chat input. Available on mobile only. Ask 'how do you work?' to learn more.
Vedic Voice
A scholar in Hindu literature providing positive, brief insights against negativity.

Skillful Voice
Premier expert in household management, offering unparalleled advice and guidance.


Earth Conscious Voice
Hi ;) Ask me for data & insights gathered from an environmentally aware global community
Bring Your Writing Voice to Every Task
This GPT will help you recreate your writing voice across multiple tasks. All you need is a prior writing sample (email, blog, article, tweet) and a new task.
Passive to Active Voice Text Converter AI
I convert and rewrite passive voice text into active voice tone and language. Simply put your passive voice text below! Perfect for sentences, paragraphs, daily emails, and longer texts.