
characterfile
A simple file format for character data
Stars: 302
The Characterfile project aims to create a simple format for generating and transmitting character files, compatible with Eliza and other LLM agents. Users can convert their Twitter archive into a character file using the provided scripts. The project also includes examples, JSON schema, and TypeScript types for the character file. Scripts like tweets2character, folder2knowledge, and knowledge2character facilitate the conversion of tweets, documents, and knowledge files into character files for use with AI agents.
README:
The goal of this project is to create a simple, easy-to-use format for generating and transmitting character files. You can use these character files out of the box with Eliza or other LLM agents.
- Open Terminal. On Mac, you can press Command + Spacebar and search for "Terminal". If you're using Windows, use WSL2
- Type
npx tweets2characterand run it. If you get an error about npx not existing, you'll need to install Node.js - If you need to install node, you can do that by pasting
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.1/install.sh | bashinto your terminal to install Node Version Manager (nvm) - Once that runs, make a new terminal window (the old one will not have the new software linked) and run
nvm install nodefollowed bynvm use node - Now copy and paste
npx tweets2characterinto your terminal again. - NOTE: You will need to get a Claude or OpenAI API key. Paste that in when prompted
- You will need to get the path of your Twitter archive. If it's in your Downloads folder on a Mac, that's ~/Downloads/.zip
- If everything is correct, you'll see a loading bar as the script processes your tweets and generates a character file. This will be output at character.json in the directory where you run
npx tweets2character. If you run the commandcdin the terminal before or after generating the file, you should see where you are.
The JSON schema for the character file is here. This also matches the expected format for OpenAI function calling.
Typescript types for the character file are here.
Basic example of a character file, with values that are instructional examples/example.character.json
Read the example character file and print the contents examples/example.py
Read the example character file and validate it against the JSON schema examples/validate.py
Read the example character file and print the contents examples/example.mjs
Read the example character file and validate it against the JSON schema examples/validate.mjs
You can use the scripts the generate a character file from your tweets, convert a folder of documents into a knowledge file, and add knowledge to your character file.
Most of these scripts require an OpenAI or Anthropic API key.
Convert your twitter archive into a .character.json
First, download your Twitter archive here: https://help.x.com/en/managing-your-account/how-to-download-your-x-archive
You can run tweets2character directly from your command line with no downloads:
npx tweets2characterNote: you will need node.js installed. The easiest way is with nvm.
Then clone this repo and run these commands:
npm install
node scripts/tweets2character.js twitter-2024-07-22-aed6e84e05e7976f87480bc36686bd0fdfb3c96818c2eff2cebc4820477f4da3.zip # path to your zip archiveNote that the arguments are optional and will be prompted for if not provided.
Convert a folder of images and videos into a .knowledge file which you can use with Eliza. Will convert text, markdown and PDF into normalized text in JSON format.
You can run folder2knowledge directly from your command line with no downloads:
npx folder2knowledge <path/to/folder>npm install
node scripts/folder2knowledge.js path/to/folder # path to your folderNote that the arguments are optional and will be prompted for if not provided.
Add knowledge to your .character file from a generated knowledge.json file.
You can run knowledge2character directly from your command line with no downloads:
npx knowledge2character <path/to/character.character> <path/to/knowledge.knowledge>npm install
node scripts/knowledge2character.js path/to/character.character path/to/knowledge.knowledge # path to your character file and knowledge fileNote that the arguments are optional and will be prompted for if not provided.
Process WhatsApp chat exports to create character profiles.
You can run chats2character directly from your command line with no downloads:
npx chats2character -f path/to/chat.txt -u "Username" npx chats2character -d path/to/chats/dir -u "John Doe"
Or if you have cloned the repo:
npm install node scripts/chats2character.js -f path/to/chat.txt -u "Username" node scripts/chats2character.js -d path/to/chats/dir -u "John Doe"
Options: -u, --user Target username as it appears in chats (use quotes for names with spaces) -f, --file Path to single chat export file -d, --dir Path to directory containing chat files -i, --info Path to JSON file containing additional user information -l, --list List all users found in chats --openai [api_key] Use OpenAI model (optionally provide API key) --claude [api_key] Use Claude model (default, optionally provide API key)
Examples:
npx chats2character -d whatsapp/chats --openai sk-... npx chats2character -d whatsapp/chats --claude sk-...
npx chats2character -d whatsapp/chats --openai npx chats2character -d whatsapp/chats --claude
The script will look for API keys in the following order:
- Command line argument if provided
- Environment variables (OPENAI_API_KEY or CLAUDE_API_KEY)
- Cached keys in ~/.eliza/.env
- Prompt for key if none found
Example user info file (info.txt): The user is a mother of two, currently living in Madrid. She works as a high school teacher and has been teaching mathematics for over 15 years. She's very active in the school's parent association and often organizes educational events. In her free time, she enjoys gardening and cooking traditional Spanish recipes.
The file should be a plain text file with descriptive information about the user. This information helps provide context to better understand and analyze the chat messages.
The script will:
- Extract messages from the specified user
- Process content in chunks
- Generate a character profile
- Save results to character.json
Note: WhatsApp chat exports should be in .txt format with standard WhatsApp export formatting: [timestamp] Username: message
For usernames with spaces, make sure to use quotes: [timestamp] John Doe: message
The license is the MIT license, with slight modifications so that users are not required to include the full license in their own software. See LICENSE for more details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for characterfile
Similar Open Source Tools
characterfile
The Characterfile project aims to create a simple format for generating and transmitting character files, compatible with Eliza and other LLM agents. Users can convert their Twitter archive into a character file using the provided scripts. The project also includes examples, JSON schema, and TypeScript types for the character file. Scripts like tweets2character, folder2knowledge, and knowledge2character facilitate the conversion of tweets, documents, and knowledge files into character files for use with AI agents.
RepoToText
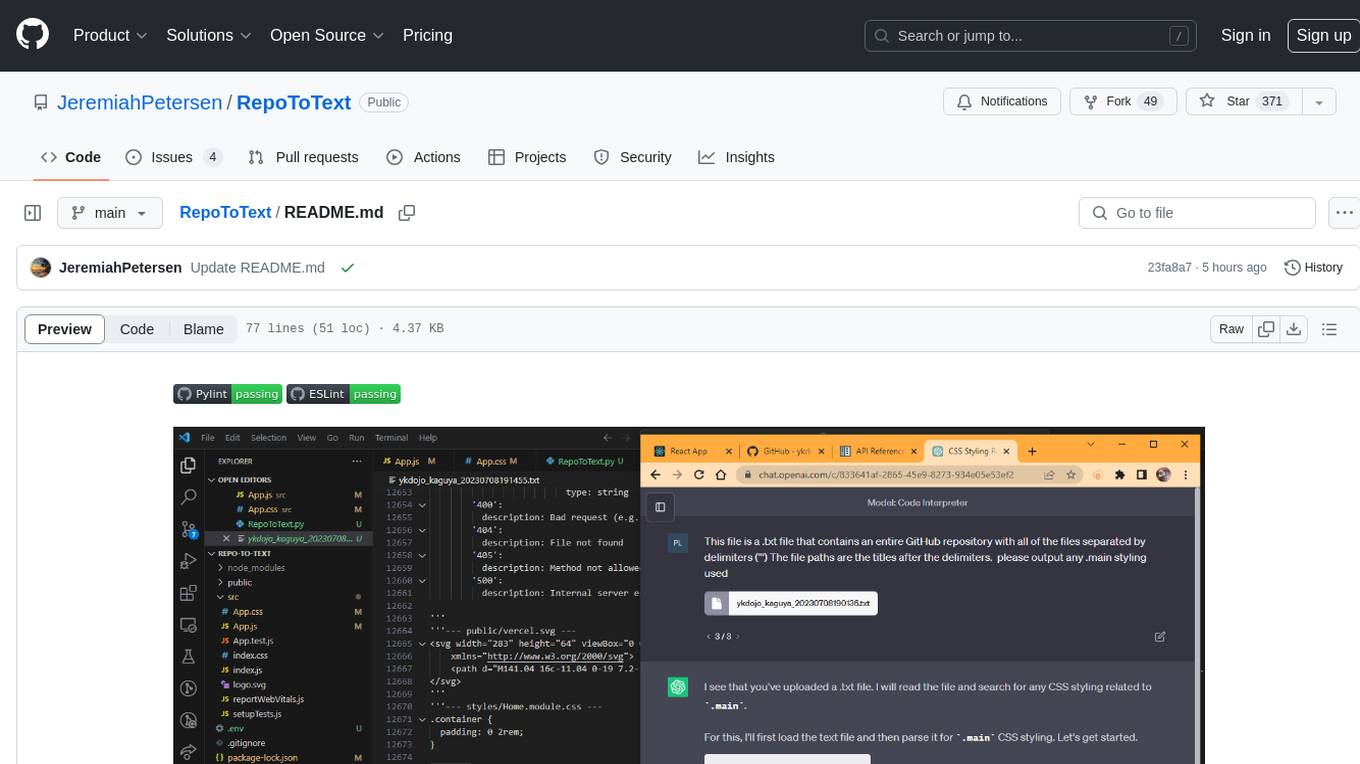
RepoToText is a web app that scrapes a GitHub repository and converts its files into a single organized .txt. It allows users to enter the URL of a GitHub repository and an optional documentation URL, retrieves the contents of the repository and documentation, and saves them in a structured text file. The tool can be used to interact with the repository using chatbots like GPT-4 or Claude Opus. Users can run the application with Docker, set up environment variables, choose specific file types for scraping, and copy the generated text to the clipboard. Additionally, FolderToText.py script allows converting local folders or files into a .txt file with customizable options.
vault-ai
OP Vault is a tool that leverages the OP Stack (OpenAI + Pinecone Vector Database) to allow users to upload custom knowledgebase files and ask questions about their contents. It provides a user-friendly Golang server and React frontend for querying human-readable content like books and documents, making it valuable for knowledge extraction and question-answering. Users can upload entire libraries, receive specific answers with file and section references, and explore the power of the OP Stack in a practical interface.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.
CLI
Bito CLI provides a command line interface to the Bito AI chat functionality, allowing users to interact with the AI through commands. It supports complex automation and workflows, with features like long prompts and slash commands. Users can install Bito CLI on Mac, Linux, and Windows systems using various methods. The tool also offers configuration options for AI model type, access key management, and output language customization. Bito CLI is designed to enhance user experience in querying AI models and automating tasks through the command line interface.
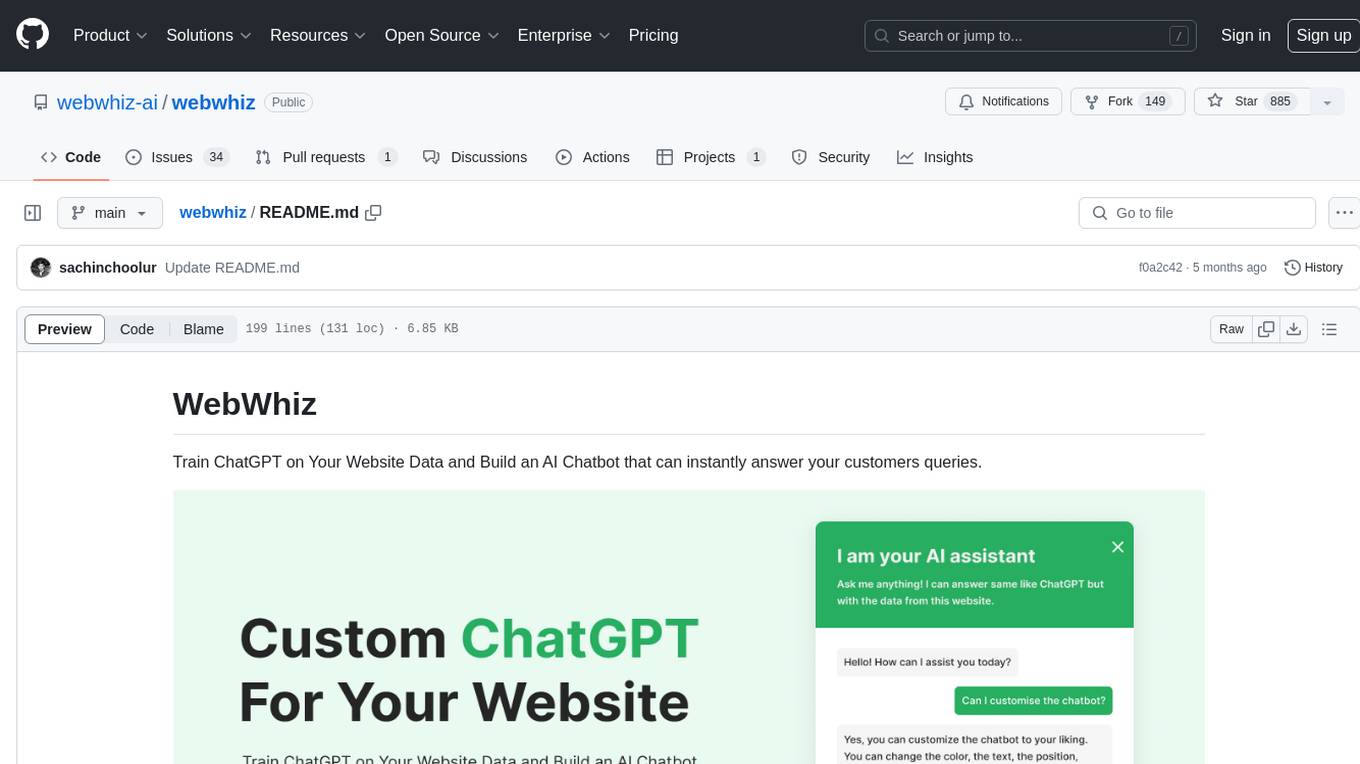
webwhiz
WebWhiz is an open-source tool that allows users to train ChatGPT on website data to build AI chatbots for customer queries. It offers easy integration, data-specific responses, regular data updates, no-code builder, chatbot customization, fine-tuning, and offline messaging. Users can create and train chatbots in a few simple steps by entering their website URL, automatically fetching and preparing training data, training ChatGPT, and embedding the chatbot on their website. WebWhiz can crawl websites monthly, collect text data and metadata, and process text data using tokens. Users can train custom data, but bringing custom open AI keys is not yet supported. The tool has no limitations on context size but may limit the number of pages based on the chosen plan. WebWhiz SDK is available on NPM, CDNs, and GitHub, and users can self-host it using Docker or manual setup involving MongoDB, Redis, Node, Python, and environment variables setup. For any issues, users can contact [email protected].
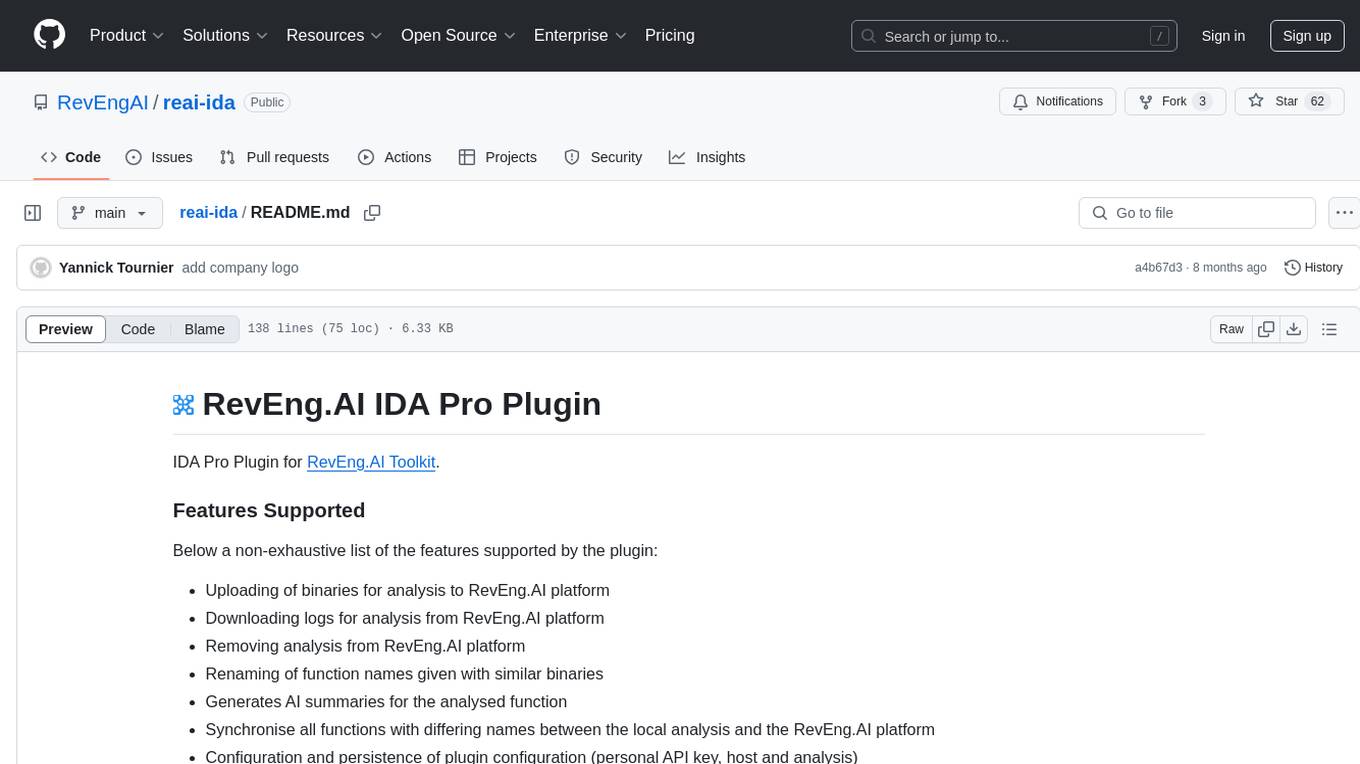
reai-ida
RevEng.AI IDA Pro Plugin is a tool that integrates with the RevEng.AI platform to provide various features such as uploading binaries for analysis, downloading analysis logs, renaming function names, generating AI summaries, synchronizing functions between local analysis and the platform, and configuring plugin settings. Users can upload files for analysis, synchronize function names, rename functions, generate block summaries, and explain function behavior using this plugin. The tool requires IDA Pro v8.0 or later with Python 3.9 and higher. It relies on the 'reait' package for functionality.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.
ai-clone-whatsapp
This repository provides a tool to create an AI chatbot clone of yourself using your WhatsApp chats as training data. It utilizes the Torchtune library for finetuning and inference. The code includes preprocessing of WhatsApp chats, finetuning models, and chatting with the AI clone via a command-line interface. Supported models are Llama3-8B-Instruct and Mistral-7B-Instruct-v0.2. Hardware requirements include approximately 16 GB vRAM for QLoRa Llama3 finetuning with a 4k context length. The repository addresses common issues like adjusting parameters for training and preprocessing non-English chats.
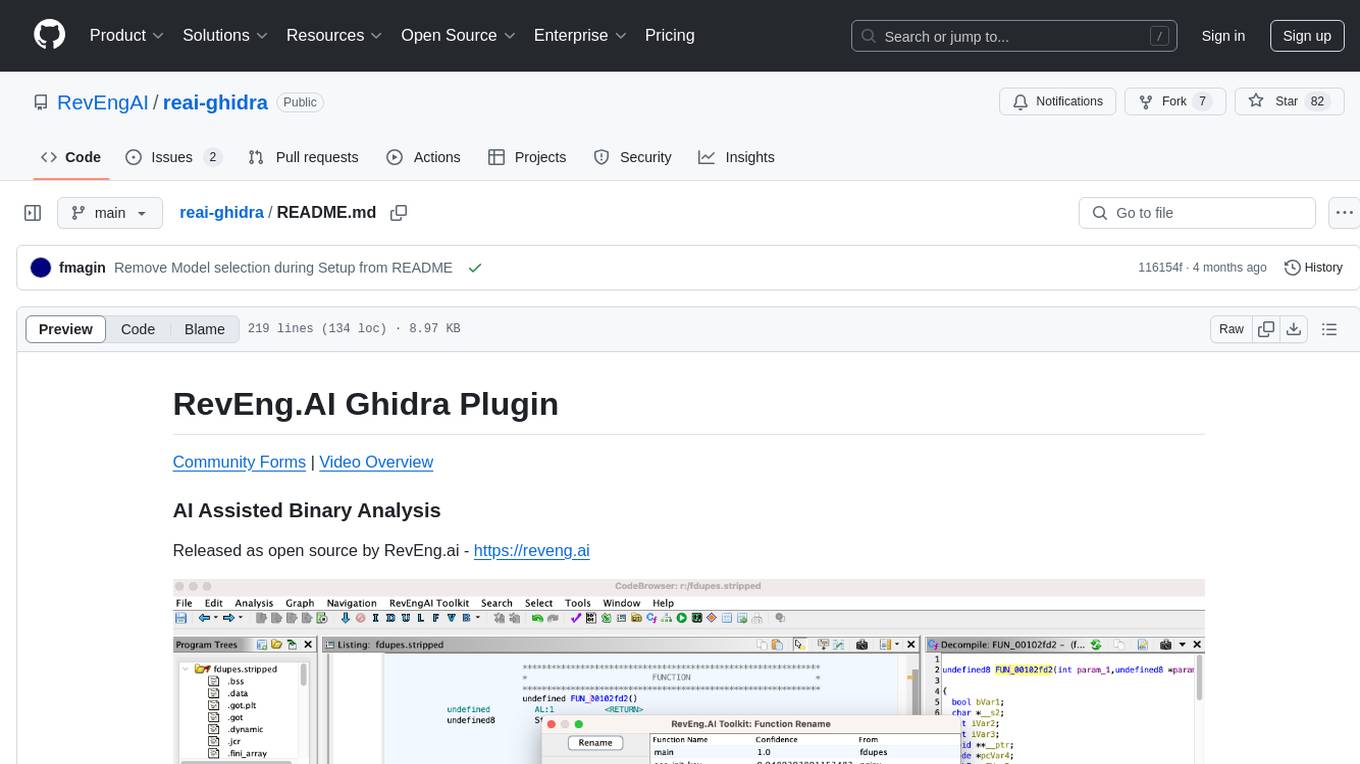
reai-ghidra
The RevEng.AI Ghidra Plugin by RevEng.ai allows users to interact with their API within Ghidra for Binary Code Similarity analysis to aid in Reverse Engineering stripped binaries. Users can upload binaries, rename functions above a confidence threshold, and view similar functions for a selected function.
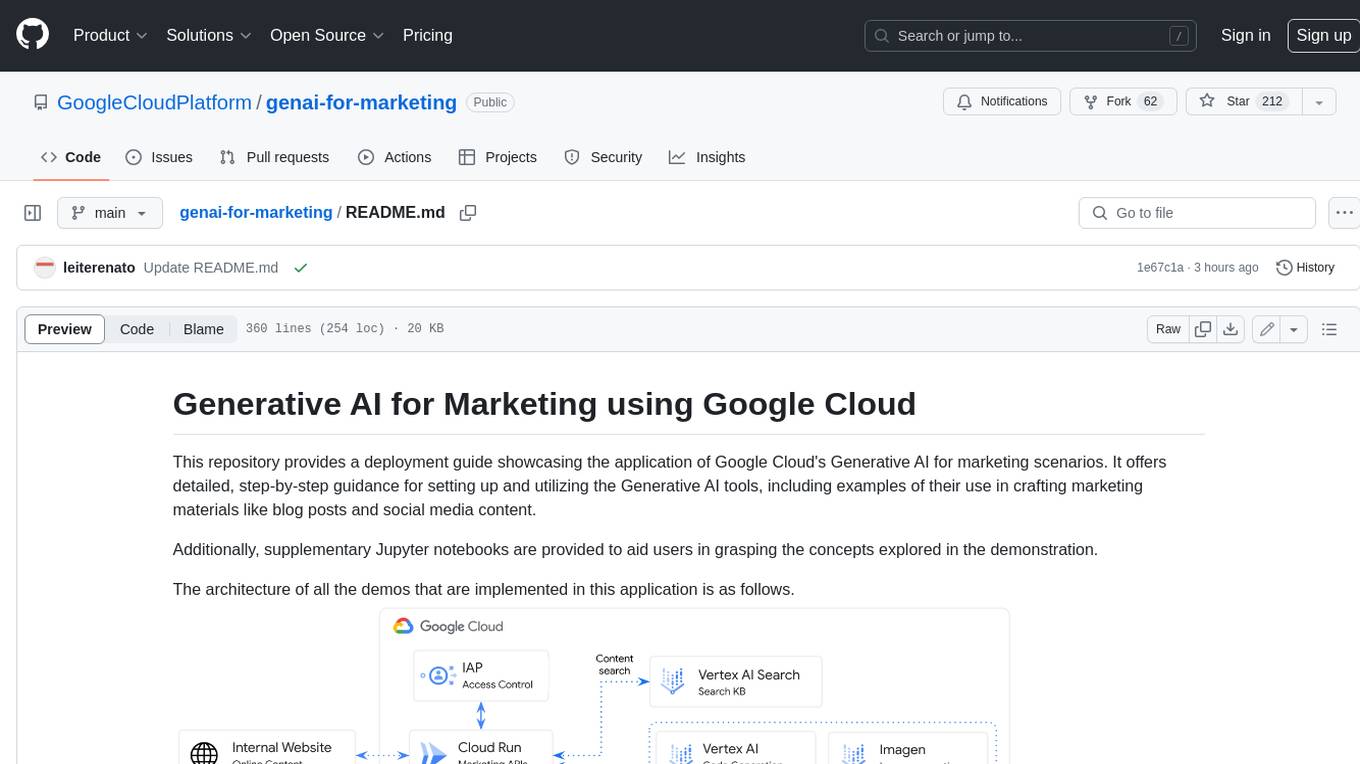
genai-for-marketing
This repository provides a deployment guide for utilizing Google Cloud's Generative AI tools in marketing scenarios. It includes step-by-step instructions, examples of crafting marketing materials, and supplementary Jupyter notebooks. The demos cover marketing insights, audience analysis, trendspotting, content search, content generation, and workspace integration. Users can access and visualize marketing data, analyze trends, improve search experience, and generate compelling content. The repository structure includes backend APIs, frontend code, sample notebooks, templates, and installation scripts.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.
For similar tasks
characterfile
The Characterfile project aims to create a simple format for generating and transmitting character files, compatible with Eliza and other LLM agents. Users can convert their Twitter archive into a character file using the provided scripts. The project also includes examples, JSON schema, and TypeScript types for the character file. Scripts like tweets2character, folder2knowledge, and knowledge2character facilitate the conversion of tweets, documents, and knowledge files into character files for use with AI agents.
docling
Docling is a tool that bundles PDF document conversion to JSON and Markdown in an easy, self-contained package. It can convert any PDF document to JSON or Markdown format, understand detailed page layout, reading order, recover table structures, extract metadata such as title, authors, references, and language, and optionally apply OCR for scanned PDFs. The tool is designed to be stable, lightning fast, and suitable for macOS and Linux environments.
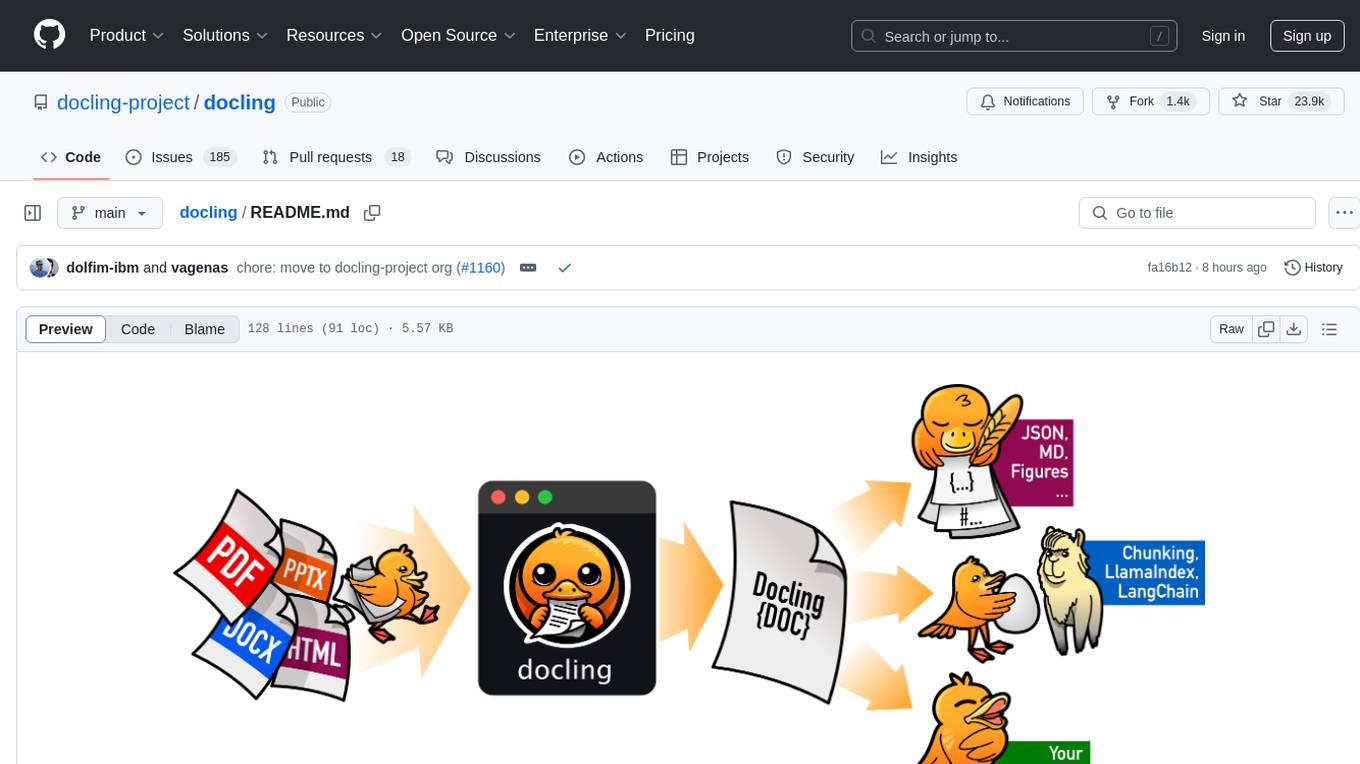
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.
markpdfdown
MarkPDFDown is a powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format. It simplifies the process of converting PDF documents into clean, editable Markdown text by accurately extracting text, preserving formatting, and handling complex document structures including tables, formulas, and diagrams.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.