Best AI tools for< Convert Documents >
20 - AI tool Sites
CreateMyTest
CreateMyTest is an online tool that uses artificial intelligence to automatically convert documents and YouTube videos into tests. It offers various question types, including multiple choice, true/false, matching, and fill in the blank. The platform aims to enhance studying by helping users retain knowledge through practice testing and reduce test anxiety.

goPDF
goPDF is a comprehensive PDF management platform that offers a suite of tools for creating, converting, capturing, and interacting with PDFs. With its advanced features and user-friendly API, goPDF simplifies the handling of PDF documents for various purposes, including collaborative work, quick assistance, and engaging training. The platform's AI capabilities enhance the user experience by providing interactive reading, content summarization, and chatbot functionality.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
AIConvert
AIConvert is a web-based application that allows users to convert various types of files into different formats. It supports a wide range of file formats, including documents, images, videos, and audio files. AIConvert is easy to use and does not require any software installation. Users simply need to upload the file they want to convert and select the desired output format. AIConvert will then automatically convert the file and provide a download link.
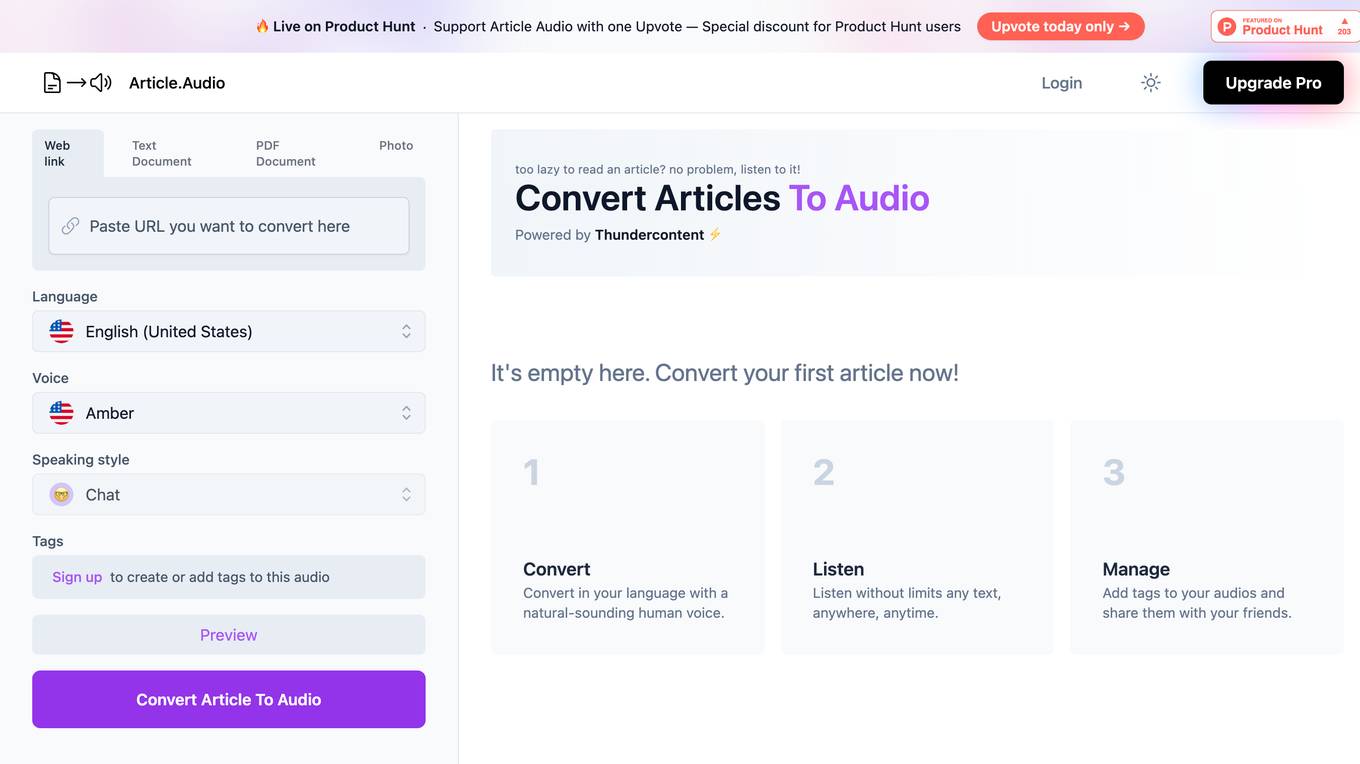
Article.Audio
Article.Audio is a web application that allows users to convert articles into audio files, enabling them to listen to the content instead of reading it. Users can easily convert text documents, PDFs, and web links into audio format, with the option to choose from a variety of languages and speaking styles. The application is powered by Thundercontent and offers a user-friendly interface for a seamless experience. With features like natural-sounding human voices, unlimited listening, and audio management with tags, Article.Audio aims to enhance accessibility and convenience for users who prefer audio content consumption.
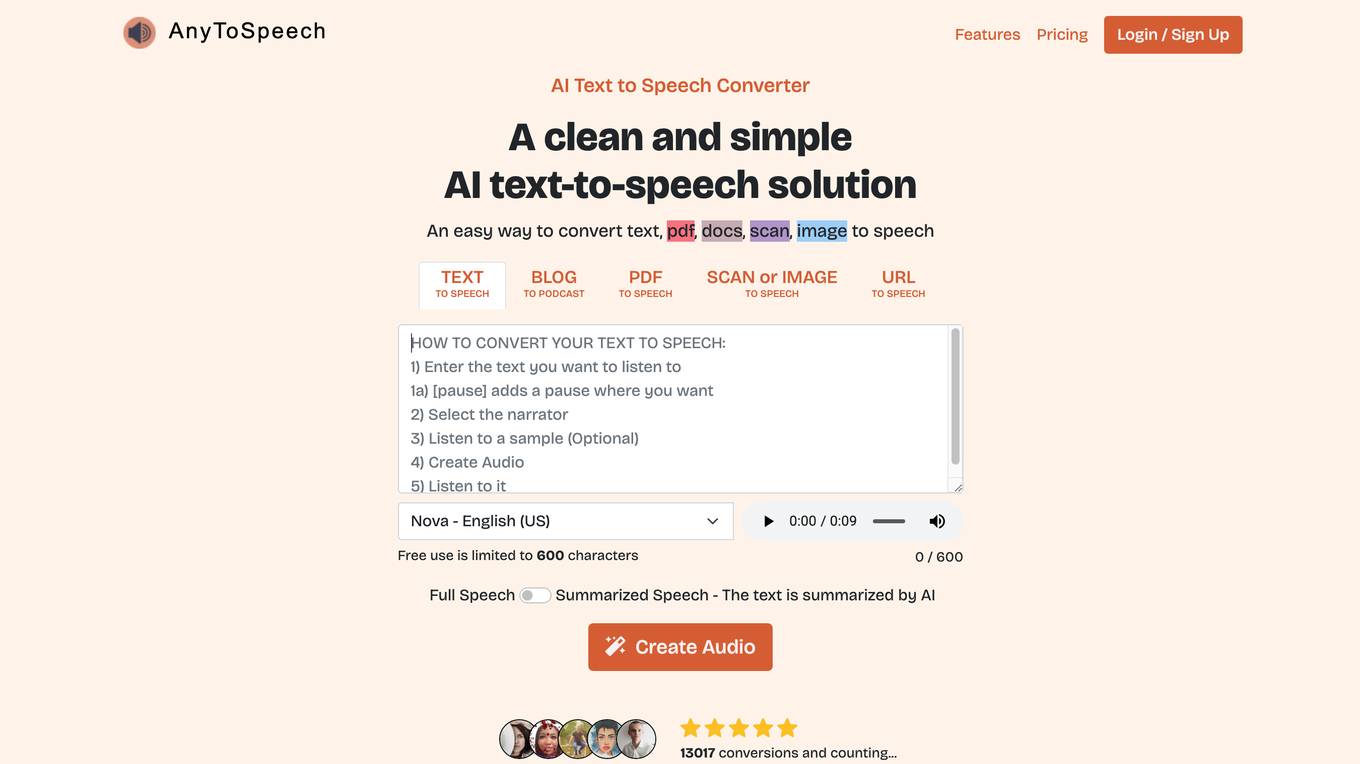
AnyToSpeech
AnyToSpeech is an AI text-to-speech and PDF to Audiobook solution that offers a clean and simple way to convert text, PDFs, documents, scans, and images to speech. It provides a variety of realistic voices in multiple languages for users to choose from. The platform also allows users to convert URLs to speech and offers a library to save and access their generated audio files at any time.
Slice Knowledge
Slice Knowledge is an AI-powered content creation platform designed for learning purposes. It offers fast and simple creation of learning units using AI technology. The platform is a perfect solution for course creators, HR and L&D teams, education experts, and enterprises looking to enhance their employee training programs. Slice Knowledge provides AI-powered creation, compliance templates, assistant bots, SCORM tracking integration, and multilingual support. It allows users to convert documents into interactive, responsive, SCORM-compliant learning materials with features like unlimited designer CSS, interactive video, multi-lingual support, and responsive design.
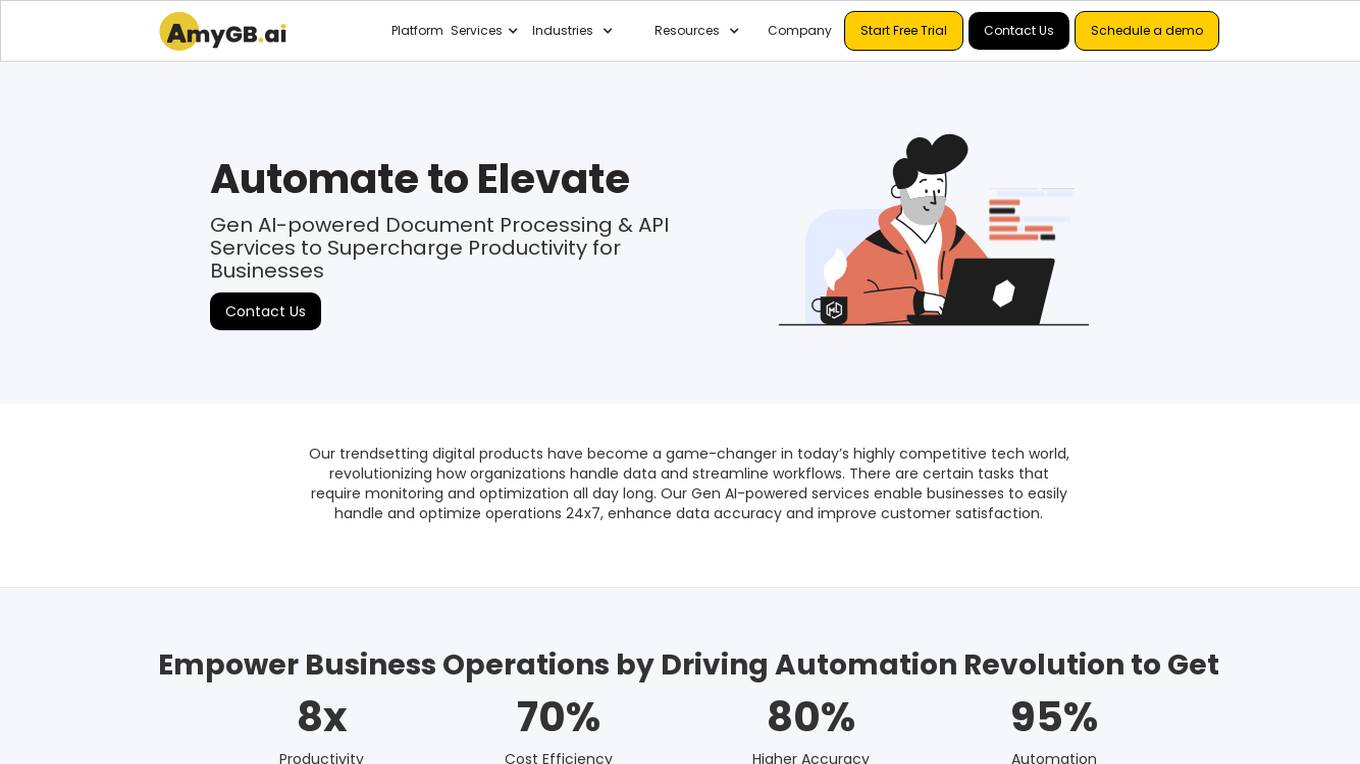
AmyGB Platform Services
AmyGB Platform Services offers Gen AI-powered Document Processing and API Services to supercharge productivity for businesses. Their trendsetting digital products have revolutionized how organizations handle data and streamline workflows, enabling businesses to easily optimize operations 24x7, enhance data accuracy, and improve customer satisfaction. The platform empowers business operations by driving automation revolution, providing 8x productivity, 70% cost efficiency, 80% higher accuracy, and 95% automation. AmyGB's AI-powered document processing solutions help convert documents into digital assets, extract data, and enhance customer fulfillment through automated software solutions.
SlidesPilot
SlidesPilot is an AI-powered presentation tool that helps users create, convert, and edit PowerPoint presentations quickly and easily. With its advanced AI capabilities, SlidesPilot can generate informative and professional presentations from scratch, add relevant images, convert PDF and Word documents to PPT, and provide real-time assistance through its built-in AI co-pilot. The tool offers a wide range of features, including customizable templates, automatic slide creation, text rewriting, grammar correction, and image generation. SlidesPilot is designed for both business professionals and educators, and it supports multiple languages, making it accessible to users worldwide.
AI PowerPoint Maker
AI PowerPoint Maker is a free application that leverages advanced AI technology to create PowerPoint presentations quickly and efficiently. It allows users to convert text and existing documents into visually appealing slides with professional templates. The tool is designed to streamline the presentation creation process, enabling users to focus on content rather than formatting. With features like working directly in PowerPoint, converting documents into presentations, using professional templates, and customizing presentations with AI, AI PowerPoint Maker is a valuable resource for individuals and teams looking to enhance their presentation skills.
Autoppt
Autoppt is an AI PowerPoint maker that allows users to create stunning slide presentations effortlessly. It offers a user-friendly platform where you can input your topic or upload documents to generate beautifully designed AI slideshows. With Autoppt, you can convert PDF and Word files into PowerPoint presentations, choose from a variety of templates, customize your slides, and share your work seamlessly. The application leverages Artificial Intelligence to streamline the presentation creation process, making it ideal for professionals, educators, and anyone looking to enhance their presentations with AI technology.
Klarity
Klarity is an AI-powered platform that automates accounting and compliance workflows traditionally offshored. It leverages AI to streamline documentation processes, enhance compliance, and drive real-world impact and sustainable scaling. Klarity helps businesses evolve into Exponential Organizations by optimizing functions, scaling efficiently, and driving innovation with AI-powered automation.
LitStudy
LitStudy is an AI study assistant designed to enhance learning efficiency for students. It offers features such as real-time audio note generation, converting various content types into structured notes, personalized quiz and flashcard generation, report writing, media upload support, web link processing, language translation, and more. LitStudy aims to help busy individuals learn effectively by providing AI-structured notes in minutes, saving time and optimizing learning between commitments.
DrLambda
DrLambda is an AI-powered tool that helps users create professional-looking slides quickly and easily. With DrLambda, you can choose from a variety of templates and themes, and then add your own text, images, and videos. DrLambda will automatically format your slides and ensure that they look polished and professional.
PDF2Quiz
PDF2Quiz is an AI-powered tool that allows users to convert PDF documents into interactive quizzes. Users can upload a PDF, specify the number of questions, select the language, and set the difficulty level to transform the PDF into an engaging quiz. The tool utilizes Optical Character Recognition (OCR) to create quizzes from PDFs with non-selectable text, making it easy for users to assess their knowledge and share quizzes with others. With multilingual quiz conversion capabilities, PDF2Quiz caters to users from various linguistic backgrounds. The tool also offers features such as reviewing scores and answers, challenging users with automatically generated multiple-choice questions, and enabling offline use by saving quizzes and answers as PDFs.
Scanner Go
Scanner Go is a free PDF tool that offers easy-to-use features for high-quality scanning and conversion of various documents into PDF format. With powerful OCR technology, it allows users to extract text from PDFs and images, making it convenient to edit and share documents. The tool also provides options for managing, editing, printing, and sharing documents, enhancing productivity. Additionally, Scanner Go offers a range of popular tools for converting, optimizing, and securing PDF files, catering to diverse user needs.
GetSearchablePDF
GetSearchablePDF is an online tool that allows users to convert scanned or image-based PDF documents into searchable PDFs. With its advanced OCR (Optical Character Recognition) technology, the tool accurately extracts text from images, making the resulting PDFs easy to search, edit, and share. The process is simple and straightforward: users simply connect their Dropbox or OneDrive account, drag and drop their PDF files into the designated folder, and the tool automatically converts them into searchable PDFs.
Woy AI Tools
Woy AI Tools is an online tool that offers free image to text conversion with over 99% accuracy and automatic recognition of more than 100 languages. Users can easily upload an image and receive the textual information contained within it. The tool supports multiple languages, prioritizes user privacy and data protection, has a simple and user-friendly interface, and is available for free usage. It utilizes advanced machine learning and OCR technology to continuously optimize recognition algorithms for clear and high-resolution images.
PDF.ai
PDF.ai is a powerful AI-powered tool that allows you to chat with your PDF documents. With PDF.ai, you can ask questions about your PDF, get summaries, translate text, and more. PDF.ai is the perfect tool for anyone who works with PDFs on a regular basis.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
5 - Open Source AI Tools
docling
Docling is a tool that bundles PDF document conversion to JSON and Markdown in an easy, self-contained package. It can convert any PDF document to JSON or Markdown format, understand detailed page layout, reading order, recover table structures, extract metadata such as title, authors, references, and language, and optionally apply OCR for scanned PDFs. The tool is designed to be stable, lightning fast, and suitable for macOS and Linux environments.
characterfile
The Characterfile project aims to create a simple format for generating and transmitting character files, compatible with Eliza and other LLM agents. Users can convert their Twitter archive into a character file using the provided scripts. The project also includes examples, JSON schema, and TypeScript types for the character file. Scripts like tweets2character, folder2knowledge, and knowledge2character facilitate the conversion of tweets, documents, and knowledge files into character files for use with AI agents.
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.
markpdfdown
MarkPDFDown is a powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format. It simplifies the process of converting PDF documents into clean, editable Markdown text by accurately extracting text, preserving formatting, and handling complex document structures including tables, formulas, and diagrams.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
20 - OpenAI Gpts
LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.
Law Document
Convert simple documents and notes into supported legal terminology. Copyright (C) 2024, Sourceduty - All Rights Reserved.
Automated Knowledge Distillation
For strategic knowledge distillation, upload the document you need to analyze and use !start. ENSURE the uploaded file shows DOCUMENT and NOT PDF. This workflow requires leveraging RAG to operate. Only a small amount of PDFs are supported, convert to txt or doc. For timeout, refresh & !continue

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Formal to Informal Text Converter AI
I convert and turn formal text to informal style instantly. Simply put your formal text below and click Enter! Perfect for sentences, paragraphs, and daily messages.
ConvertAnything
The ultimate tool for converting files, whether they are images, audio, video, documents, or other types. It can process single files or multiple files in bulk, accepts ZIP files, and offers a download link [Updated version].
Passive to Active Voice Text Converter AI
I convert and rewrite passive voice text into active voice tone and language. Simply put your passive voice text below! Perfect for sentences, paragraphs, daily emails, and longer texts.

MarkDown変換くん
入力した文章をMarkdown形式にコードとして正しく変換してくれます。文章を入力するだけでOKです!更に、読み手が読みやすいようにレイアウトも考えてくれます!途中で止まっても「続けてください」といえば大丈夫です。




Table to JSON
我們經常在看 REST API 參考文件,文件中呈現 Request/Response 參數通常都是用表格的形式,開發人員都要手動轉換成 JSON 結構,有點小麻煩,但透過這個 GPT 只要上傳截圖就可以自動產生 JSON 範例與 JSON Schema 結構。