
dataline
Chat with your data - AI data analysis and visualization on CSV, Postgres, MySQL, Snowflake, SQLite...
Stars: 1163

DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
README:
💬 Chat with your data using natural language 📊
Introducing DataLine, the simplest and fastest way⚡️ to analyze and visualize your data!
Generate and export charts, tables, reports in seconds with DataLine - Your AI-driven data analysis and visualization tool 🤓


- Who is this for
- What is it
- Roadmap
- Feature Support
- Getting started
- Upgrading
- Running manually
- Authentication
- Startup Quest
- Supported Databases
- Deployment
Technical or non-technical people who want to explore data, fast. ⚡️⚡️
It also works for backend developers to speed up drafting queries and explore new DBs with ease. 😎
It's especially well-suited for businesses given its security-first 🔒 and open-source 📖 nature.
DataLine is an AI-driven data analysis and visualization tool.
It's privacy-focused, storing everything on your device. No ☁️, only ☀️!
It hides your data from the LLMs used by default, but this can be disabled if the data is not deemed sensitive.
It can connect to a variety of data sources (Postgres, Snowflake, MySQL, Azure SQL Server, Microsoft SQL Server, Excel, SQLite, CSV, sas7bdat, and more), execute queries, generate charts, and allow for copying the results to build reports quickly.
For now, we're trying to help people get insights out of their data, fast.
This is meant to enable non-technical folks to query data and aid data analysts in getting their jobs done 10x as fast.
But you can still influence the direction we go in. We're building this for you, so you have the biggest say.
- [x] Broad DB support: Postgres, MySQL, Snowflake, Excel, CSV, SQLite, and more
- [x] Generating and executing SQL from natural language
- [x] Ability to modify SQL results, save them, and re-run
- [x] Better support for explorative questions
- [x] Querying data files like CSV, Excel, SQLite, sas7bdat (more connection types)
- [x] Charting via natural language
- [x] Modifying chart queries and re-rendering/refreshing charts
- [ ] Dashboards and triggers
- [ ] Knowledge base and 'trainable' examples (flavor of RAG)
- [ ] More advanced charting options (bubble, stacks, etc.)
With a lot more coming soon. You can still influence what we build, so if you're a user and you're down for it, we'd love to interview you! Book some time with one of us here:
There are multiple ways of setting up DataLine, simplest being using a binary executable. This allows you to download a file and run it to get started.
A more flexible option is using our hosted Docker image. This allows you to setup authentication and other features if you need them.
Head over to our releases page, and open the most recent one. There you should find a windows-exe.zip file. Download it, unzip it, and run the DataLine.exe file.
You might get a "Windows protected your PC" message, which is normal (more info -> run anyway). Finally, open http://localhost:7377/ in your browser.
Homebrew
# install dataline
brew tap ramiawar/dataline
brew install dataline
# run dataline
datalineIf you don't like Homebrew, a binary can be found in the latest release!
DataLine should then be running on port 7377 accessible from your browser: http://localhost:7377
You can use Homebrew, see the Mac section.
You may also wish to use the binary instead, to do so, follow the instructions in the Windows section, and use the dataline-linux.tar.zip file instead.
You can also use our official docker image and get started in one command. This is more suitable for business use:
docker run -p 7377:7377 -v dataline:/home/.dataline --name dataline ramiawar/dataline:latestYou can manage this as you would any other container. docker start dataline, docker stop dataline
For updating to a new version, just remove the container and rerun the command. This way the volume is persisted across updates.
docker rm dataline
docker run -p 7377:7377 -v dataline:/home/.dataline --name dataline ramiawar/dataline:latestTo connect to the frontend, you can then visit: http://localhost:7377
Same as installation, just replace old exe with new exe! Your data will still be there across versions.
Homebrew (retains your data, don't worry about that!)
brew update && brew upgrade datalineIf you don't like Homebrew, a binary can be found in the latest release! Data will still be retained there as well.
If using Homebrew, same as above. Otherwise simply replace the old binary with the new one!
For updating to a new version, just remove the container and rerun the command. This way the volume is persisted across updates.
docker rm dataline
docker run -p 7377:7377 -v dataline:/home/.dataline --name dataline ramiawar/dataline:latestFeeling spicy are we? 🌶️ There are a few things you should know. DataLine is split into two parts: the backend and the frontend.
The backend is a Python FastAPI server, and the frontend is a React app. The frontend also includes our landing page, so you need to set up an env var first!
Check the backend and frontend readmes.
DataLine also supports basic auth 🔒 in self-hosted mode 🥳 in case you're hosting it and would like to secure it with a username/password.
Auth is NOT supported ❌ when running the DataLine executable.
To enable authentication on the self-hosted version, add the environment variables AUTH_USERNAME and AUTH_PASSWORD while launching the service. ✅
Inject the env vars with the docker run command as follows:
docker run -p 7377:7377 -v dataline:/home/.dataline --name dataline -e AUTH_USERNAME=admin -e AUTH_PASSWORD=admin ramiawar/dataline:latest
We plan on supporting multiple user auth in the future, but for now it supports a single user by default.
Go through the following checklist to explore DataLine's features!
- [ ] Create a sample database connection
- [ ] Create a new chat and rename it
- [ ] Start asking questions about your data and getting answers
- [ ] Refresh the page and re-run some SQL queries
- [ ] Click inside an SQL query, modify it, and save your modification for later!
- [ ] Try to modify your sample DB connection and explore the connection editor page
- [ ] Try asking for a chart!
- [ ] To really challenge it, ask a question that is answered with multiple results (charts, tables, etc.) - example
- [ ] Add a profile picture
See instructions file for more details.
The one thing you must configure when deploying DataLine to a custom domain is CORS allowed origins.
To do this, add the environment variable ALLOWED_ORIGINS (comma separated list of origins) to your domain name(s).
By default, it is set to http://localhost:7377,http://0.0.0.0:7377 to make it work with local Docker and local binaries.
For example, running the docker image on a remote server with IP 123.123.12.34:
docker run -p 7377:7377 -v dataline:/home/.dataline --name dataline -e ALLOWED_ORIGINS="http://123.123.12.34:7377,https://123.123.12.34:7377" ramiawar/dataline:latestWe support excel files, but they will have to conform to some structure for the time being. We also support multiple sheets - each sheet will be ingested as a separate table.
Right now, we will try to automatically detect the 'header row' and the first column based on some manual data processing (so as to keep things secure). This means that we might detect the wrong things if you have extra rows on top / logos / branding elements.
To ensure the best quality, make sure your first row is the column names, and remove any padding rows/columns from all the sheets. If any sheet fails, the import will fail.
Future improvements to this include optionally allowing LLMs to figure out what the header row is to reduce user effort.
Thanks goes to these wonderful people (emoji key):
 Rami Awar 💻 🎨 📖 🚇 📦 📝 🐛 |
 anthony2261 💻 🤔 🚇 📦 🧑🏫 🚧 🐛 |
 Walusimbi Mahad 💻 🤔 |
 Péter Gyarmati 💻 📖 |
 Joe Haddad 💻 📖 |
 maryamalki 💻 📖 |
 Filip Katušin 💻 🐛 |
This project follows the all-contributors specification. Contributions of any kind welcome!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for dataline
Similar Open Source Tools
dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
lluminous
lluminous is a fast and light open chat UI that supports multiple providers such as OpenAI, Anthropic, and Groq models. Users can easily plug in their API keys locally to access various models for tasks like multimodal input, image generation, multi-shot prompting, pre-filled responses, and more. The tool ensures privacy by storing all conversation history and keys locally on the user's device. Coming soon features include memory tool, file ingestion/embedding, embeddings-based web search, and prompt templates.
SeaGOAT
SeaGOAT is a local search tool that leverages vector embeddings to enable you to search your codebase semantically. It is designed to work on Linux, macOS, and Windows and can process files in various formats, including text, Markdown, Python, C, C++, TypeScript, JavaScript, HTML, Go, Java, PHP, and Ruby. SeaGOAT uses a vector database called ChromaDB and a local vector embedding engine to provide fast and accurate search results. It also supports regular expression/keyword-based matches. SeaGOAT is open-source and licensed under an open-source license, and users are welcome to examine the source code, raise concerns, or create pull requests to fix problems.
OpenCopilot
OpenCopilot allows you to have your own product's AI copilot. It integrates with your underlying APIs and can execute API calls whenever needed. It uses LLMs to determine if the user's request requires calling an API endpoint. Then, it decides which endpoint to call and passes the appropriate payload based on the given API definition.
open-source-slack-ai
This repository provides a ready-to-run basic Slack AI solution that allows users to summarize threads and channels using OpenAI. Users can generate thread summaries, channel overviews, channel summaries since a specific time, and full channel summaries. The tool is powered by GPT-3.5-Turbo and an ensemble of NLP models. It requires Python 3.8 or higher, an OpenAI API key, Slack App with associated API tokens, Poetry package manager, and ngrok for local development. Users can customize channel and thread summaries, run tests with coverage using pytest, and contribute to the project for future enhancements.

Sentient
Sentient is a personal, private, and interactive AI companion developed by Existence. The project aims to build a completely private AI companion that is deeply personalized and context-aware of the user. It utilizes automation and privacy to create a true companion for humans. The tool is designed to remember information about the user and use it to respond to queries and perform various actions. Sentient features a local and private environment, MBTI personality test, integrations with LinkedIn, Reddit, and more, self-managed graph memory, web search capabilities, multi-chat functionality, and auto-updates for the app. The project is built using technologies like ElectronJS, Next.js, TailwindCSS, FastAPI, Neo4j, and various APIs.
llocal
LLocal is an Electron application focused on providing a seamless and privacy-driven chatting experience using open-sourced technologies, particularly open-sourced LLM's. It allows users to store chats locally, switch between models, pull new models, upload images, perform web searches, and render responses as markdown. The tool also offers multiple themes, seamless integration with Ollama, and upcoming features like chat with images, web search improvements, retrieval augmented generation, multiple PDF chat, text to speech models, community wallpapers, lofi music, speech to text, and more. LLocal's builds are currently unsigned, requiring manual builds or using the universal build for stability.
nobodywho
NobodyWho is a plugin for the Godot game engine that enables interaction with local LLMs for interactive storytelling. Users can install it from Godot editor or GitHub releases page, providing their own LLM in GGUF format. The plugin consists of `NobodyWhoModel` node for model file, `NobodyWhoChat` node for chat interaction, and `NobodyWhoEmbedding` node for generating embeddings. It offers a programming interface for sending text to LLM, receiving responses, and starting the LLM worker.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.
superflows
Superflows is an open-source alternative to OpenAI's Assistant API. It allows developers to easily add an AI assistant to their software products, enabling users to ask questions in natural language and receive answers or have tasks completed by making API calls. Superflows can analyze data, create plots, answer questions based on static knowledge, and even write code. It features a developer dashboard for configuration and testing, stateful streaming API, UI components, and support for multiple LLMs. Superflows can be set up in the cloud or self-hosted, and it provides comprehensive documentation and support.
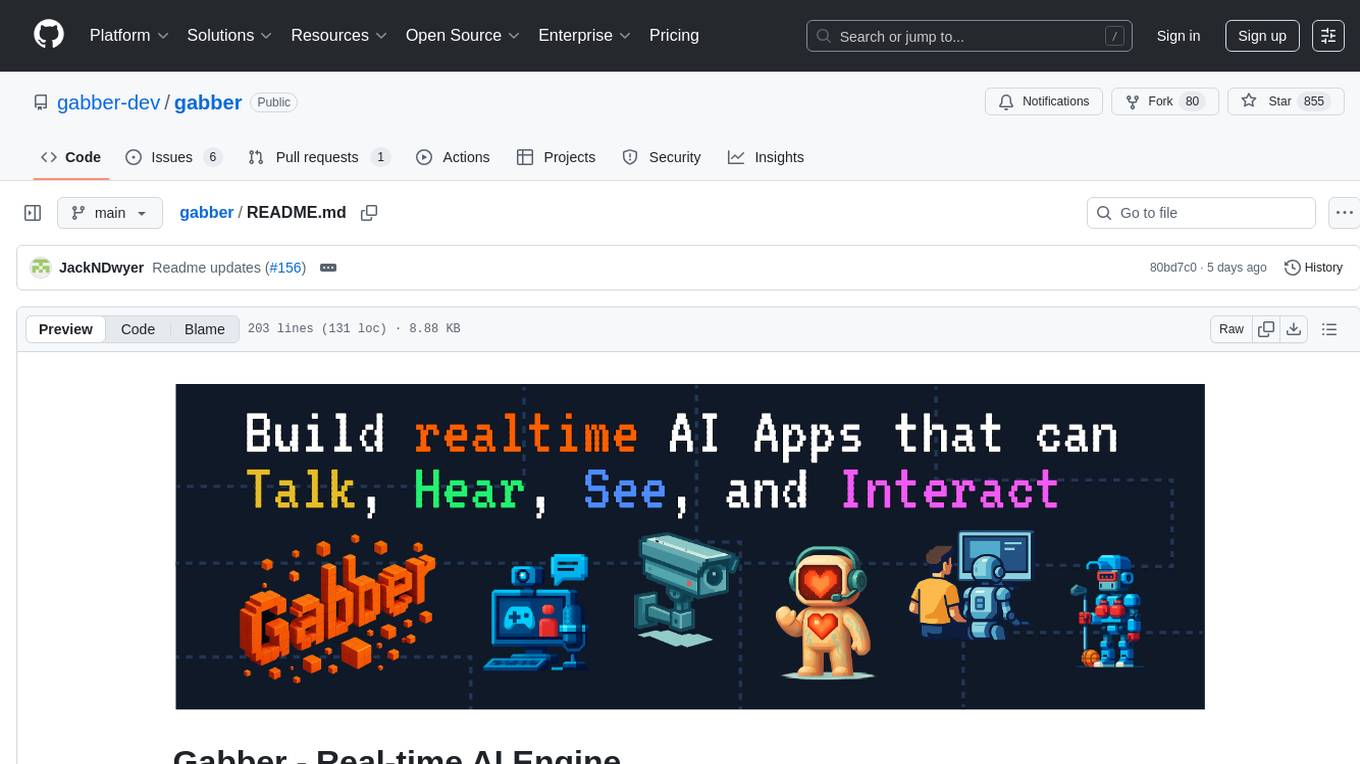
gabber
Gabber is a real-time AI engine that supports graph-based apps with multiple participants and simultaneous media streams. It allows developers to build powerful and developer-friendly AI applications across voice, text, video, and more. The engine consists of frontend and backend services including an editor, engine, and repository. Gabber provides SDKs for JavaScript/TypeScript, React, Python, Unity, and upcoming support for iOS, Android, React Native, and Flutter. The roadmap includes adding more nodes and examples, such as computer use nodes, Unity SDK with robotics simulation, SIP nodes, and multi-participant turn-taking. Users can create apps using nodes, pads, subgraphs, and state machines to define application flow and logic.
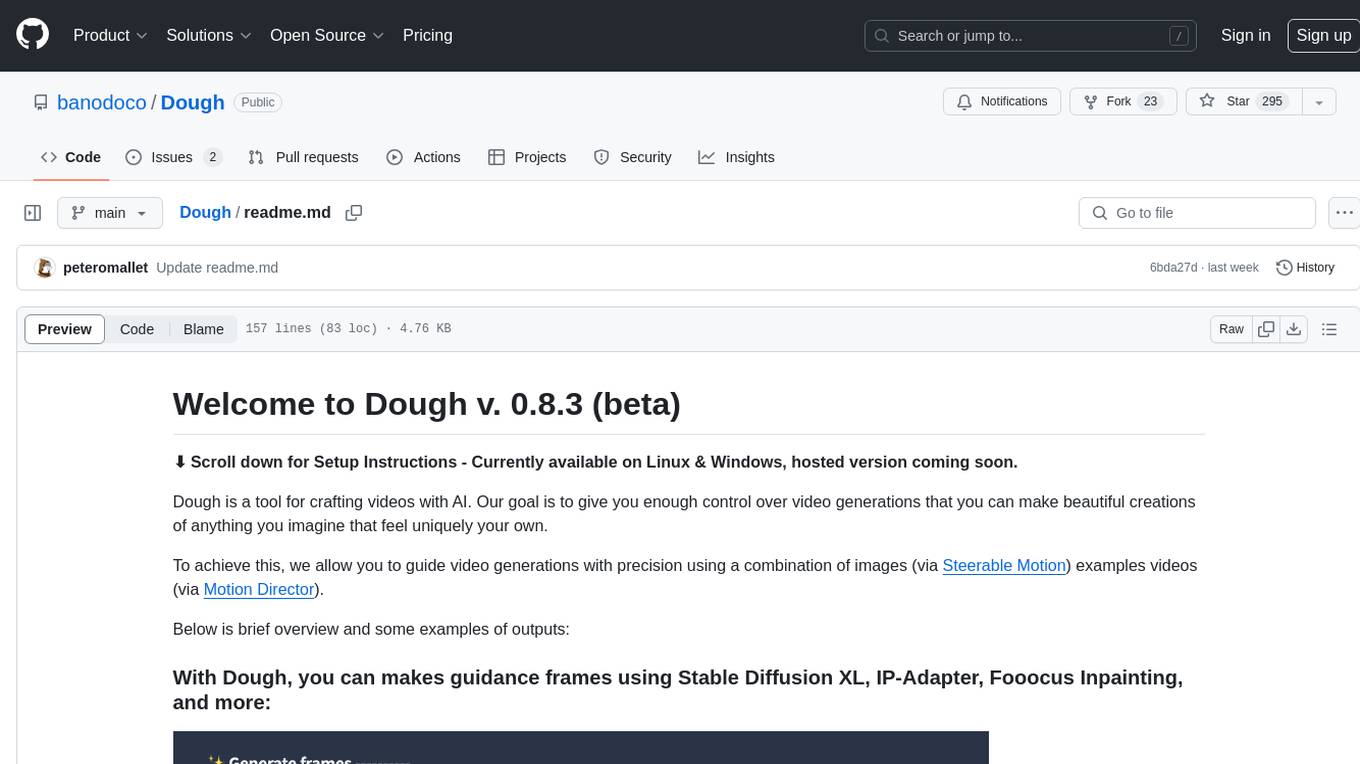
Dough
Dough is a tool for crafting videos with AI, allowing users to guide video generations with precision using images and example videos. Users can create guidance frames, assemble shots, and animate them by defining parameters and selecting guidance videos. The tool aims to help users make beautiful and unique video creations, providing control over the generation process. Setup instructions are available for Linux and Windows platforms, with detailed steps for installation and running the app.

azure-search-openai-demo
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access a GPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval. The repo includes sample data so it's ready to try end to end. In this sample application we use a fictitious company called Contoso Electronics, and the experience allows its employees to ask questions about the benefits, internal policies, as well as job descriptions and roles.
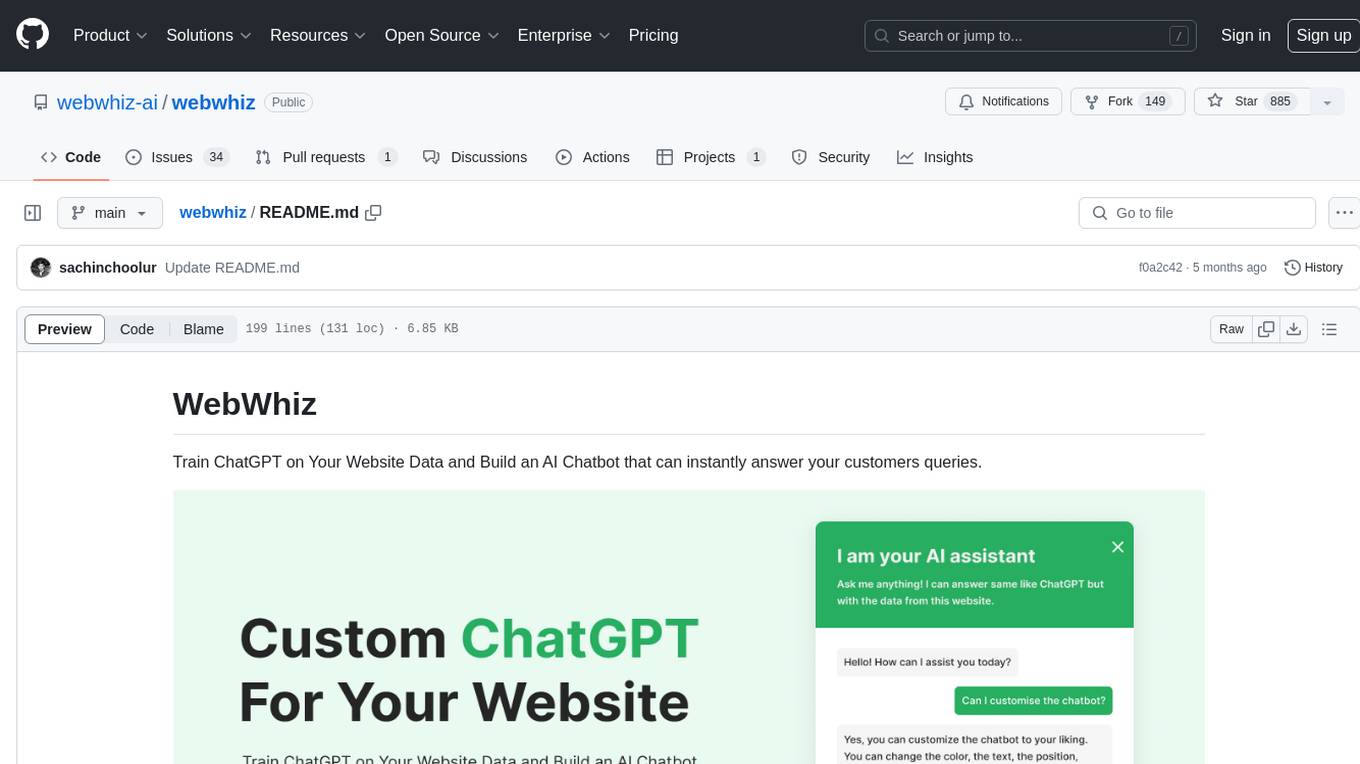
webwhiz
WebWhiz is an open-source tool that allows users to train ChatGPT on website data to build AI chatbots for customer queries. It offers easy integration, data-specific responses, regular data updates, no-code builder, chatbot customization, fine-tuning, and offline messaging. Users can create and train chatbots in a few simple steps by entering their website URL, automatically fetching and preparing training data, training ChatGPT, and embedding the chatbot on their website. WebWhiz can crawl websites monthly, collect text data and metadata, and process text data using tokens. Users can train custom data, but bringing custom open AI keys is not yet supported. The tool has no limitations on context size but may limit the number of pages based on the chosen plan. WebWhiz SDK is available on NPM, CDNs, and GitHub, and users can self-host it using Docker or manual setup involving MongoDB, Redis, Node, Python, and environment variables setup. For any issues, users can contact [email protected].
For similar tasks
dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
aiosql
aiosql is a Python module that allows you to organize SQL statements in .sql files and load them into your Python application as methods to call. It supports various database drivers like SQLite, PostgreSQL, MySQL, MariaDB, and DuckDB. The project is an implementation of Kris Jenkins' yesql library to the Python ecosystem, allowing users to easily reuse SQL code in SQL GUIs or CLI tools. With aiosql, you can write, version control, comment, and run SQL code using files without losing the ability to use them as you would any other SQL file. It provides support for PEP 249 and asyncio based drivers, enabling users to execute parametric SQL queries from Python methods.

dbhub
DBHub is a universal database gateway that implements the Model Context Protocol (MCP) server interface. It allows MCP-compatible clients to connect to and explore different databases. The gateway supports various database resources and tools, providing capabilities such as executing queries, listing connectors, generating SQL, and explaining database elements. Users can easily configure their database connections and choose between different transport modes like stdio and sse. DBHub also offers a demo mode with a sample employee database for testing purposes.
mcp-llm-bridge
The MCP LLM Bridge is a tool that acts as a bridge connecting Model Context Protocol (MCP) servers to OpenAI-compatible LLMs. It provides a bidirectional protocol translation layer between MCP and OpenAI's function-calling interface, enabling any OpenAI-compatible language model to leverage MCP-compliant tools through a standardized interface. The tool supports primary integration with the OpenAI API and offers additional compatibility for local endpoints that implement the OpenAI API specification. Users can configure the tool for different endpoints and models, facilitating the execution of complex queries and tasks using cloud-based or local models like Ollama and LM Studio.
mysql_mcp_server
A Model Context Protocol (MCP) server that enables secure interaction with MySQL databases. This server allows AI assistants to list tables, read data, and execute SQL queries through a controlled interface, making database exploration and analysis safer and more structured. It provides features such as listing available MySQL tables as resources, reading table contents, executing SQL queries with proper error handling, secure database access through environment variables, and comprehensive logging. The tool ensures security best practices by never committing environment variables or credentials, using a database user with minimal required permissions, implementing query whitelisting for production use, and monitoring and logging all database operations.
mcp-graphql
mcp-graphql is a Model Context Protocol server that enables Large Language Models (LLMs) to interact with GraphQL APIs. It provides schema introspection and query execution capabilities, allowing models to dynamically discover and use GraphQL APIs. The server offers tools for retrieving the GraphQL schema and executing queries against the endpoint. Mutations are disabled by default for security reasons. Users can install mcp-graphql via Smithery or manually to Claude Desktop. It is recommended to carefully consider enabling mutations in production environments to prevent unauthorized data modifications.

boost
Laravel Boost accelerates AI-assisted development by providing essential context and structure for generating high-quality, Laravel-specific code. It includes an MCP server with specialized tools, AI guidelines, and a Documentation API. Boost is designed to streamline AI-assisted coding workflows by offering precise, context-aware results and extensive Laravel-specific information.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.
For similar jobs
resonance
Resonance is a framework designed to facilitate interoperability and messaging between services in your infrastructure and beyond. It provides AI capabilities and takes full advantage of asynchronous PHP, built on top of Swoole. With Resonance, you can: * Chat with Open-Source LLMs: Create prompt controllers to directly answer user's prompts. LLM takes care of determining user's intention, so you can focus on taking appropriate action. * Asynchronous Where it Matters: Respond asynchronously to incoming RPC or WebSocket messages (or both combined) with little overhead. You can set up all the asynchronous features using attributes. No elaborate configuration is needed. * Simple Things Remain Simple: Writing HTTP controllers is similar to how it's done in the synchronous code. Controllers have new exciting features that take advantage of the asynchronous environment. * Consistency is Key: You can keep the same approach to writing software no matter the size of your project. There are no growing central configuration files or service dependencies registries. Every relation between code modules is local to those modules. * Promises in PHP: Resonance provides a partial implementation of Promise/A+ spec to handle various asynchronous tasks. * GraphQL Out of the Box: You can build elaborate GraphQL schemas by using just the PHP attributes. Resonance takes care of reusing SQL queries and optimizing the resources' usage. All fields can be resolved asynchronously.
aiogram_bot_template
Aiogram bot template is a boilerplate for creating Telegram bots using Aiogram framework. It provides a solid foundation for building robust and scalable bots with a focus on code organization, database integration, and localization.

pluto
Pluto is a development tool dedicated to helping developers **build cloud and AI applications more conveniently** , resolving issues such as the challenging deployment of AI applications and open-source models. Developers are able to write applications in familiar programming languages like **Python and TypeScript** , **directly defining and utilizing the cloud resources necessary for the application within their code base** , such as AWS SageMaker, DynamoDB, and more. Pluto automatically deduces the infrastructure resource needs of the app through **static program analysis** and proceeds to create these resources on the specified cloud platform, **simplifying the resources creation and application deployment process**.
pinecone-ts-client
The official Node.js client for Pinecone, written in TypeScript. This client library provides a high-level interface for interacting with the Pinecone vector database service. With this client, you can create and manage indexes, upsert and query vector data, and perform other operations related to vector search and retrieval. The client is designed to be easy to use and provides a consistent and idiomatic experience for Node.js developers. It supports all the features and functionality of the Pinecone API, making it a comprehensive solution for building vector-powered applications in Node.js.
aiohttp-pydantic
Aiohttp pydantic is an aiohttp view to easily parse and validate requests. You define using function annotations what your methods for handling HTTP verbs expect, and Aiohttp pydantic parses the HTTP request for you, validates the data, and injects the parameters you want. It provides features like query string, request body, URL path, and HTTP headers validation, as well as Open API Specification generation.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.
aioconsole
aioconsole is a Python package that provides asynchronous console and interfaces for asyncio. It offers asynchronous equivalents to input, print, exec, and code.interact, an interactive loop running the asynchronous Python console, customization and running of command line interfaces using argparse, stream support to serve interfaces instead of using standard streams, and the apython script to access asyncio code at runtime without modifying the sources. The package requires Python version 3.8 or higher and can be installed from PyPI or GitHub. It allows users to run Python files or modules with a modified asyncio policy, replacing the default event loop with an interactive loop. aioconsole is useful for scenarios where users need to interact with asyncio code in a console environment.
aiosqlite
aiosqlite is a Python library that provides a friendly, async interface to SQLite databases. It replicates the standard sqlite3 module but with async versions of all the standard connection and cursor methods, along with context managers for automatically closing connections and cursors. It allows interaction with SQLite databases on the main AsyncIO event loop without blocking execution of other coroutines while waiting for queries or data fetches. The library also replicates most of the advanced features of sqlite3, such as row factories and total changes tracking.