Best AI tools for< Train Transformers >
20 - AI tool Sites
Ferhat Erata
Ferhat Erata is an AI application developed by a Computer Science PhD graduate from Yale University. The application focuses on training transformers to solve NP-complete problems using reinforcement learning and improving test-time compute strategies for reasoning. It also explores learning randomized reductions and program properties for security, privacy, and side-channel resilience. Ferhat Erata is currently an Applied Scientist at the Automated Reasoning Group at AWS, working on Neuro-Symbolic AI to prevent factual errors caused by LLM hallucinations using mathematically sound Automated Reasoning checks.
Sentence Transformers
Sentence Transformers is a Python module that provides access to state-of-the-art embedding and reranker models. It allows users to compute embeddings, calculate similarity scores, and generate sparse embeddings for various applications such as semantic search, semantic textual similarity, and paraphrase mining. The module offers a wide selection of pre-trained models and enables users to train or finetune their own models for specific use cases.
AGENT
AGENT is an AI chatbot powered by OpenAI and Anthropic, designed to handle customer inquiries, qualify leads, and enhance customer engagement. Developed by I Need Leads Ltd, AGENT combines advanced natural language processing, intelligent chatbots, and machine learning to empower businesses of all sizes in generating and managing leads efficiently. The platform adapts, learns, and grows with businesses, ensuring they stay ahead in the competitive digital landscape.
StoryFile
StoryFile is an AI-powered video platform that transforms interviews into interactive conversations for museums and institutions. It allows visitors to ask real questions and receive authentic video responses in real time. The technology preserves firsthand history through carefully structured interviews, providing a unique and engaging experience for users.
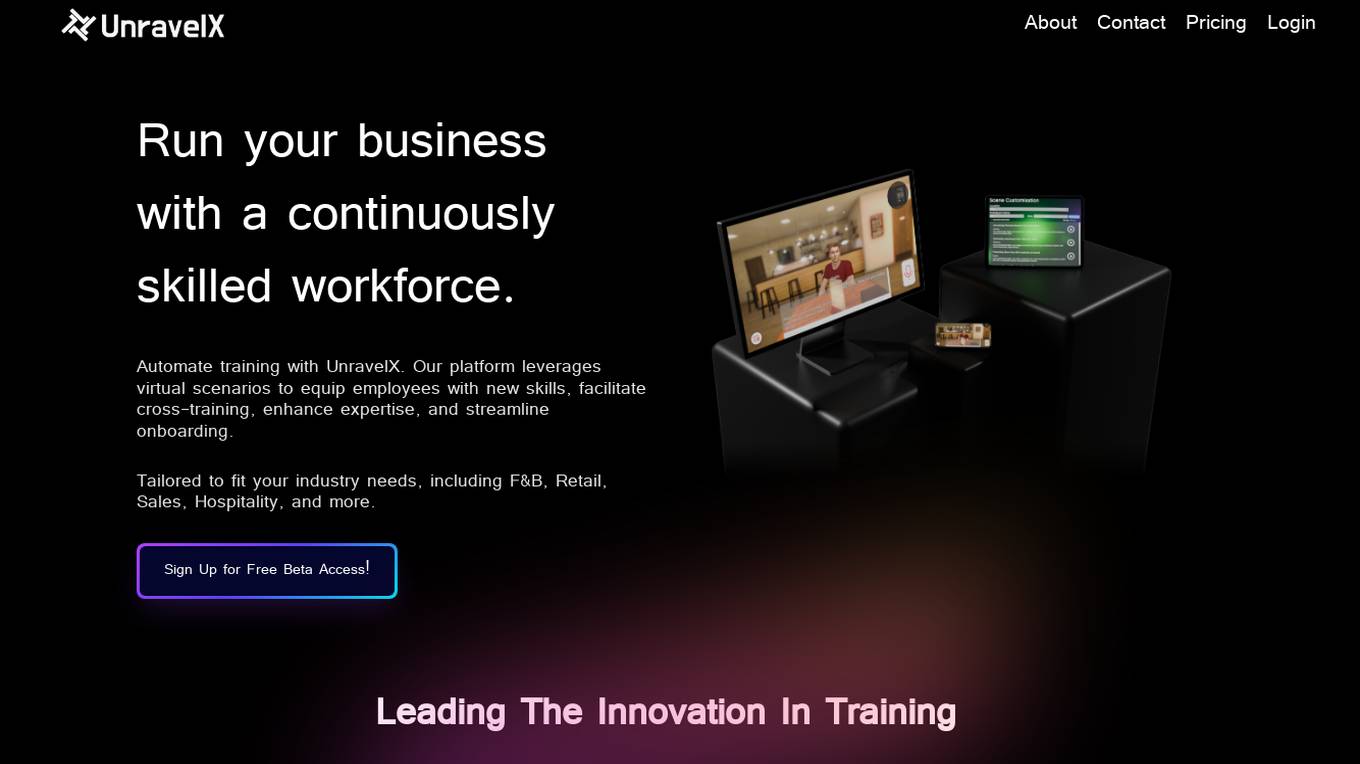
UnravelX
UnravelX is an AI-powered platform that transforms documents into 3D interactive virtual scenarios for training purposes. It automates training processes by using generative AI to create immersive learning experiences. The platform caters to various industries such as F&B, Retail, Sales, and Hospitality, offering a cost-effective and efficient solution for upskilling employees. With over 60 years of combined AI and training expertise, UnravelX leads the innovation in scenario-based learning, providing a seamless onboarding experience for organizations.

Kayyo
Kayyo is a personal MMA trainer application that offers interactive lessons for beginners and experts. It provides challenges, personalized feedback, and a variety of games to enhance punching and kicking prowess. With AI personal trainers, Kayyo transforms workouts into dynamic and entertaining sessions that adapt to the user's pace. The app aims to help users master their moves, engage in virtual fights, and improve their overall fitness performance. Kayyo is free to use and currently focuses on building its features for martial arts enthusiasts.
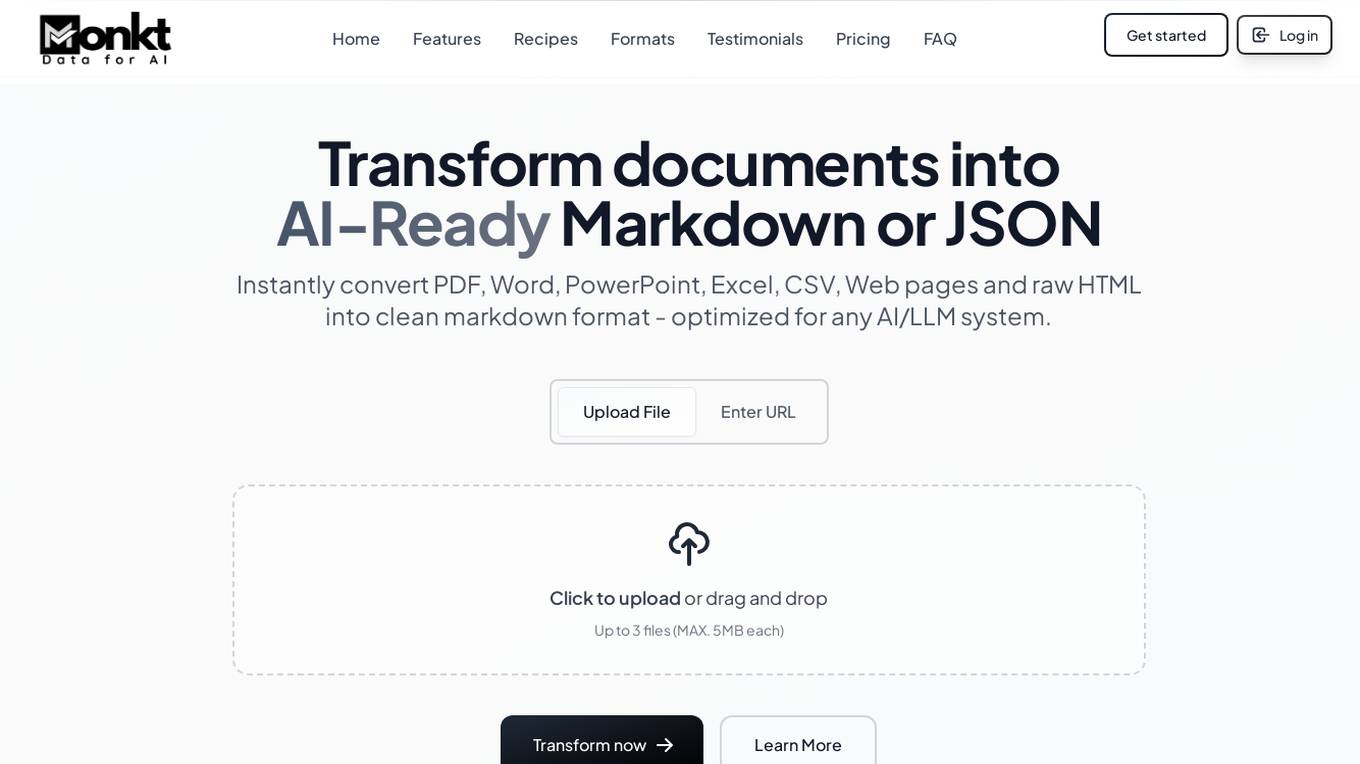
Monkt
Monkt is a powerful document processing platform that transforms various document formats into AI-ready Markdown or structured JSON. It offers features like instant conversion of PDF, Word, PowerPoint, Excel, CSV, web pages, and raw HTML into clean markdown format optimized for AI/LLM systems. Monkt enables users to create intelligent applications, custom AI chatbots, knowledge bases, and training datasets. It supports batch processing, image understanding, LLM optimization, and API integration for seamless document processing. The platform is designed to handle document transformation at scale, with support for multiple file formats and custom JSON schemas.
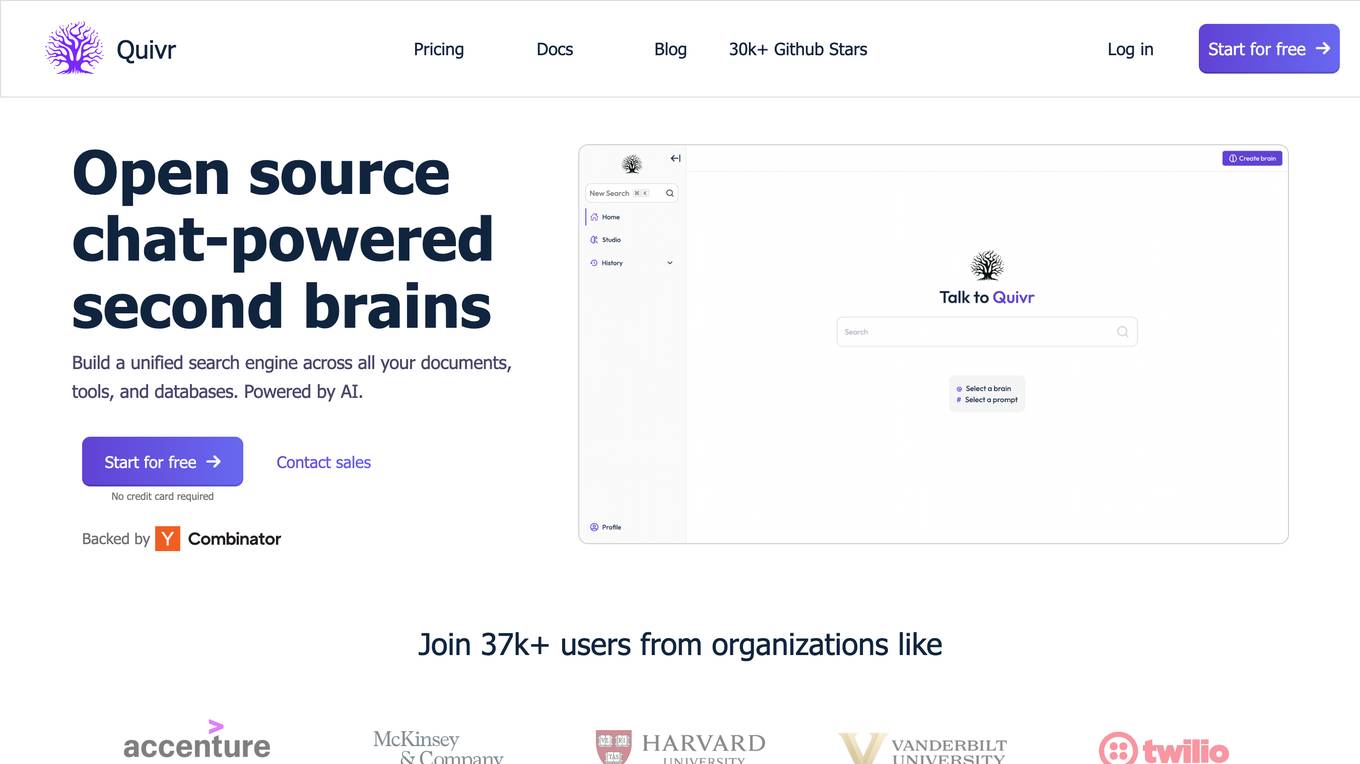
Quivr
Quivr is an open-source chat-powered second brain application that transforms private and enterprise knowledge into a personal AI assistant. It continuously learns and improves at every interaction, offering AI-powered workplace search synced with user data. Quivr allows users to connect with their favorite tools, databases, and applications, and configure their 'second brain' to train on their company's unique context for improved search relevance and knowledge discovery.
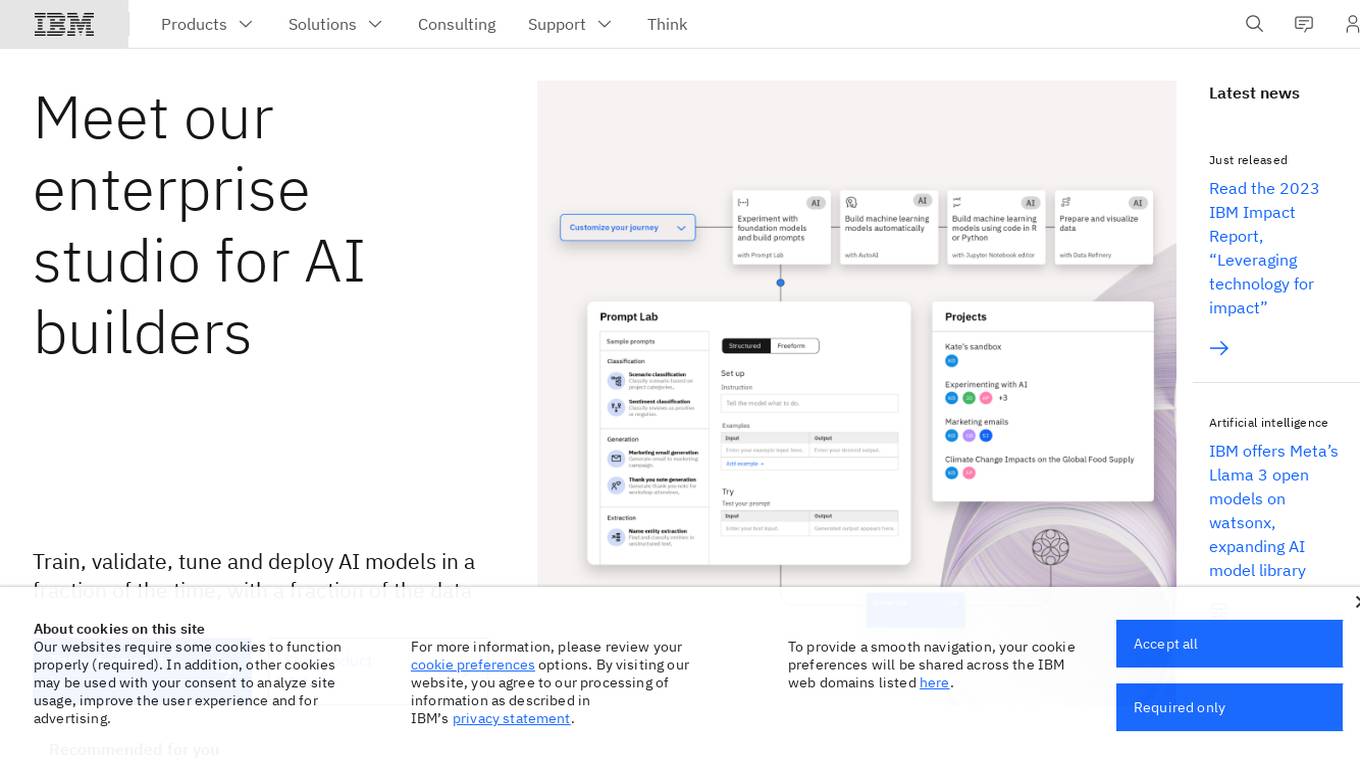
IBM Watsonx
IBM Watsonx is an enterprise studio for AI builders. It provides a platform to train, validate, tune, and deploy AI models quickly and efficiently. With Watsonx, users can access a library of pre-trained AI models, build their own models, and deploy them to the cloud or on-premises. Watsonx also offers a range of tools and services to help users manage and monitor their AI models.
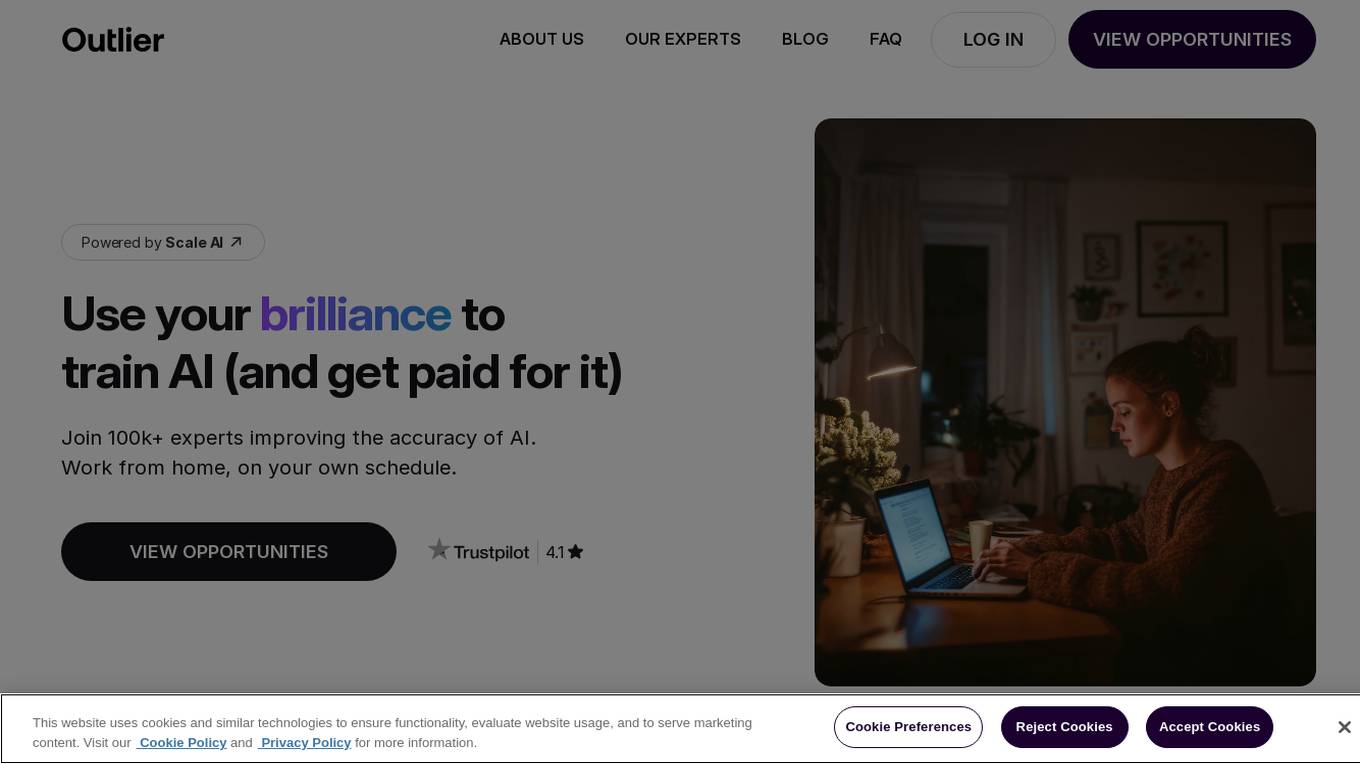
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
Athletica AI
Athletica AI is an AI-powered athletic training and personalized fitness application that offers tailored coaching and training plans for various sports like cycling, running, duathlon, triathlon, and rowing. It adapts to individual fitness levels, abilities, and availability, providing daily step-by-step training plans and comprehensive session analyses. Athletica AI integrates seamlessly with workout data from platforms like Garmin, Strava, and Concept 2 to craft personalized training plans and workouts. The application aims to help athletes train smarter, not harder, by leveraging the power of AI to optimize performance and achieve fitness goals.
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
Kaiden AI
Kaiden AI is an AI-powered training platform that offers personalized, immersive simulations to enhance skills and performance across various industries and roles. It provides feedback-rich scenarios, voice-enabled interactions, and detailed performance insights. Users can create custom training scenarios, engage with AI personas, and receive real-time feedback to improve communication skills. Kaiden AI aims to revolutionize training solutions by combining AI technology with real-world practice.
Endurance
Endurance is a platform designed for runners, swimmers, and cyclists to engage in group training activities with friends or local communities. Users can create or join teams, share structured workouts, and benefit from collective motivation and accountability. The platform aims to make training fun and effective by leveraging the power of group workouts and social connections.
ChatCube
ChatCube is an AI-powered chatbot maker that allows users to create chatbots for their websites without coding. It uses advanced AI technology to train chatbots on any document or website within 60 seconds. ChatCube offers a range of features, including a user-friendly visual editor, lightning-fast integration, fine-tuning on specific data sources, data encryption and security, and customizable chatbots. By leveraging the power of AI, ChatCube helps businesses improve customer support efficiency and reduce support ticket reductions by up to 28%.
Workout Tools
Workout Tools is an AI-powered personal trainer that helps you train smarter and reach your fitness goals faster. It takes into account different parameters, such as your physics, the type of workout you're interested in, your available equipment, and comes up with a suggested workout. Don't like the workout? Just generate another one. It's that simple.
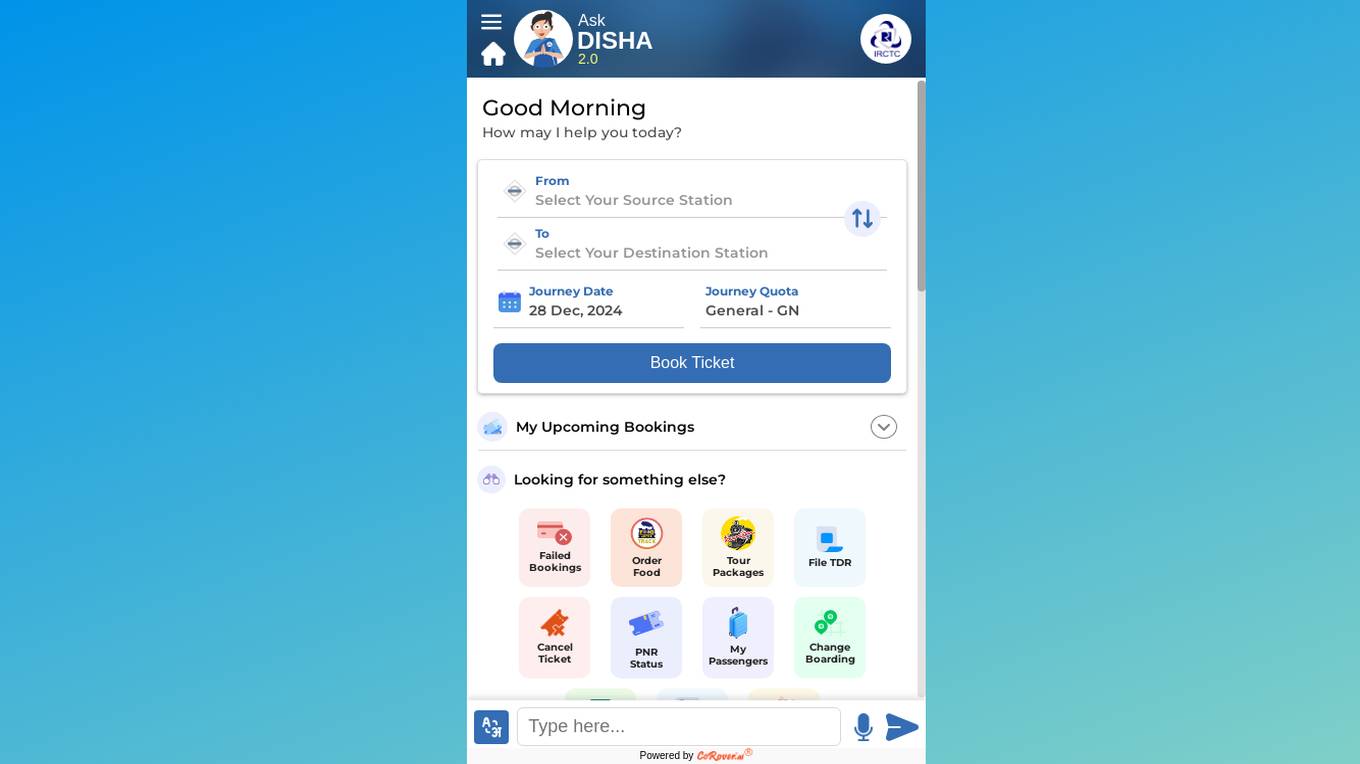
CoRover.ai
CoRover.ai is an AI-powered chatbot designed to help users book train tickets seamlessly through conversation. The chatbot, named AskDISHA, is integrated with the IRCTC platform, allowing users to inquire about train schedules, ticket availability, and make bookings effortlessly. CoRover.ai leverages artificial intelligence to provide personalized assistance and streamline the ticket booking process for users, enhancing their overall experience.
IllumiDesk
IllumiDesk is a generative AI platform for instructors and content developers that helps teams create and monetize content tailored 10X faster. With IllumiDesk, you can automate grading tasks, collaborate with your learners, create awesome content at the speed of AI, and integrate with the services you know and love. IllumiDesk's AI will help you create, maintain, and structure your content into interactive lessons. You can also leverage IllumiDesk's flexible integration options using the RESTful API and/or LTI v1.3 to leverage existing content and flows. IllumiDesk is trusted by training agencies and universities around the world.
Tovuti LMS
Tovuti LMS is an adaptive, people-first learning platform that helps organizations create engaging courses, train teams, and track progress. With its easy-to-use interface and powerful features, Tovuti LMS makes learning fun and easy. Tovuti LMS is trusted by leading organizations around the world to provide their employees with the training they need to succeed.

Kaba
Kaba is an open-source digital laboratory that empowers users to build their own AI models easily. It emphasizes privacy, security, and user control over data. The platform enables users to observe their attention and create brain-like mechanisms for intelligent systems based on their observable context. Kaba offers multi-modal, multi-input, and multi-context capabilities to enhance user experiences. The team behind Kaba comprises experts in design, technical advancements, innovation, security, and privacy, aiming to revolutionize technology interactions.
1 - Open Source AI Tools
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
20 - OpenAI Gpts
How to Train a Chessie
Comprehensive training and wellness guide for Chesapeake Bay Retrievers.
The Train Traveler
Friendly train travel guide focusing on the best routes, essential travel information, and personalized travel insights, for both experienced and novice travelers.
How to Train Your Dog (or Cat, or Dragon, or...)
Expert in pet training advice, friendly and engaging.
TrainTalk
Your personal advisor for eco-friendly train travel. Let's plan your next journey together!
Monster Battle - RPG Game
Train monsters, travel the world, earn Arena Tokens and become the ultimate monster battling champion of earth!
Hero Master AI: Superhero Training
Train to become a superhero or a supervillain. Master your powers, make pivotal choices. Each decision you make in this action-packed game not only shapes your abilities but also your moral alignment in the battle between good and evil. Another GPT Simulator by Dave Lalande

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch

Design Recruiter
Job interview coach for product designers. Train interviews and say stop when you need a feedback. You got this!!
Pocket Training Activity Expert
Expert in engaging, interactive training methods and activities.

RailwayGPT
Technical expert on locomotives, trains, signalling, and railway technology. Can answer questions and draw designs specific to transportation domain.
Railroad Conductors and Yardmasters Roadmap
Don’t know where to even begin? Let me help create a roadmap towards the career of your dreams! Type "help" for More Information

Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.