
Train-llm-from-scratch
使用deepspeed从头开始训练一个LLM,经过pretrain和sft阶段,验证llm学习知识、理解语言、回答问题的能力
Stars: 85
Train-llm-from-scratch is a repository that guides users through training a Large Language Model (LLM) from scratch. The model size can be adjusted based on available computing power. The repository utilizes deepspeed for distributed training and includes detailed explanations of the code and key steps at each stage to facilitate learning. Users can train their own tokenizer or use pre-trained tokenizers like ChatGLM2-6B. The repository provides information on preparing pre-training data, processing training data, and recommended SFT data for fine-tuning. It also references other projects and books related to LLM training.
README:
从头开始训练一个LLM,模型大小为6B(可以通过配置参数根据自己的算力调节模型大小),会使用deepspeed进行分布式训练 经过pretrain和sft 验证llm学习知识、理解语言、回答问题的能力 在每个步骤会有一个document解释代码和关键步骤,解析原理,方便学习
cuda 版本 12.1 依赖见requirements
LLM分词器的构建方式有两种: 一种是自己构造词表并训练一个分词器custom tokenizers,自己训练一个分词器的代码在generate_tokenizer 另一种是选择开源模型训练好的分词器,例如ChatGLM2-6B,Llama2等。 本次使用ChatGLM2-6B的tokenizer
预训练数据推荐
MNBVC
地址:https://github.com/esbatmop/MNBVC
数据集说明:里面有大佬整理的33T 预计达到GPT3.5的40T数据
超大规模中文语料集,不但包括主流文化,也包括各个小众文化甚至火星文的数据。MNBVC数据集包括新闻、作文、小说、书籍、杂志、论文、台词、帖子、wiki、古诗、歌词、商品介绍、笑话、糗事、聊天记录等一切形式的纯文本中文数据。数据均来源于互联网收集,且在持续更新中。
data_process/spark.py 使用spark将MNBVC数据处理成训练格式
WuDaoCorporaText
地址:https://data.baai.ac.cn/details/WuDaoCorporaText
数据集说明:WuDaoCorpora是北京智源人工智能研究院(智源研究院)构建的大规模、高质量数据集,用于支撑大模型训练研究。目前由文本、对话、图文对、视频文本对四部分组成,分别致力于构建微型语言世界、提炼对话核心规律、打破图文模态壁垒、建立视频文字关联,为大模型训练提供坚实的数据支撑。
Awesome Chinese LLM
地址:https://github.com/HqWu-HITCS/Awesome-Chinese-LLM
SKYWORK
数据集说明:天工开源的150B数据,质量很高
地址:https://huggingface.co/datasets/Skywork/SkyPile-150B
说明:训练数据质量是影响模型性能最大的因素
不做会导致的后果:存在语义相似的训练数据会导致模型的生成重复,即重复生成同一个字
地址:https://github.com/aplmikex/deduplication_mnbvc
作用: 语料去重
清除从不同来源提交给MNBVC项目的文件中,文件完全一致的。
找出不同来源,不同渠道导致有细微差别的同一文件,并打上标签,如在不同盗版网站上的同一个小说。
通过Word2Vec或Sentence2Vec将语料在句子层面进行向量聚类,找到重复率较高的句子,进行人工或深度学习进行分类,生成政治敏感,色情,广告等黑名单。
清洗语料中较长的内部重复,或内部重复出现较多次的情况。
网页语料清洗
基于规则对commoncrawl数据做初步清洗,包括:
过滤页眉页脚,标签栏等
过滤乱码
不相关的网页标识符
过滤中文占比<70%的网页
过滤中文字符少于10个的段落
敏感词过滤带有脏话、色情、赌博等非法内容的页面
从数据集中删除隐私内容,如身份证号、电话号码、qq号码、电子邮件地址
截断段落的最后一句没有结束标点的句子
繁体转简体
删除了每个句子中的所有多余空格和标点
用空格替换句子中连续空白字符(即选项卡、空格、不可见字符等)
收集正负样本训练fasttext,对低质量文本进行分类,主要去除了赌博广告,色情广告等
基于规则对wudao数据进行清洗,收集wudao正负样本作为低质量语料数据,目前优化中
小说数据清洗,目前基本清洗完成
基于规则进行清洗
去除连载小说各小节前后与内容不相关的作者的碎碎念
去除小说网站的插入广告
去除特殊字符
去除中文占比低的段落
去除编码异常段落
alpaca-zh
地址:https://huggingface.co/datasets/shibing624/alpaca-zh
BelleGroup
地址:https://huggingface.co/datasets/BelleGroup/train_1M_CN
firefly
地址:https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
COIG-CQIA
地址:https://huggingface.co/datasets/m-a-p/COIG-CQIA
https://github.com/DLLXW/baby-llama2-chinese
https://github.com/LlamaFamily/Llama-Chinese
https://github.com/SkyworkAI/Skywork
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Train-llm-from-scratch
Similar Open Source Tools
Train-llm-from-scratch
Train-llm-from-scratch is a repository that guides users through training a Large Language Model (LLM) from scratch. The model size can be adjusted based on available computing power. The repository utilizes deepspeed for distributed training and includes detailed explanations of the code and key steps at each stage to facilitate learning. Users can train their own tokenizer or use pre-trained tokenizers like ChatGLM2-6B. The repository provides information on preparing pre-training data, processing training data, and recommended SFT data for fine-tuning. It also references other projects and books related to LLM training.
KB-Builder
KB Builder is an open-source knowledge base generation system based on the LLM large language model. It utilizes the RAG (Retrieval-Augmented Generation) data generation enhancement method to provide users with the ability to enhance knowledge generation and quickly build knowledge bases based on RAG. It aims to be the central hub for knowledge construction in enterprises, offering platform-based intelligent dialogue services and document knowledge base management functionality. Users can upload docx, pdf, txt, and md format documents and generate high-quality knowledge base question-answer pairs by invoking large models through the 'Parse Document' feature.
ai-self-coding-book
The 'ai-self-coding-book' repository is a guidebook that aims to teach how to create complex applications with commercial value using natural language and AI, rather than simple toy projects. It provides insights on AI programming concepts and practical applications, emphasizing real-world use cases and best practices for development.
FinVeda
FinVeda is a dynamic financial literacy app that aims to solve the problem of low financial literacy rates in India by providing a platform for financial education. It features an AI chatbot, finance blogs, market trends analysis, SIP calculator, and finance quiz to help users learn finance with finesse. The app is free and open-source, licensed under the GNU General Public License v3.0. FinVeda was developed at IIT Jammu's Udyamitsav'24 Hackathon, where it won first place in the GenAI track and third place overall.
Tutorial-of-AI-Kit-with-Raspberry-Pi-From-Zero-to-Hero
This course is designed to teach you how to harness the power of AI on the Raspberry Pi, with a focus on using an AI kit for computer vision tasks. Learn to integrate AI into IoT applications, from object detection to visual recognition. Suitable for hobbyists, students, and professionals to bring AI-driven solutions to life on resource-constrained devices like the Raspberry Pi.
Chat2DB
Chat2DB is an AI-driven data development and analysis platform that enables users to communicate with databases using natural language. It supports a wide range of databases, including MySQL, PostgreSQL, Oracle, SQLServer, SQLite, MariaDB, ClickHouse, DM, Presto, DB2, OceanBase, Hive, KingBase, MongoDB, Redis, and Snowflake. Chat2DB provides a user-friendly interface that allows users to query databases, generate reports, and explore data using natural language commands. It also offers a variety of features to help users improve their productivity, such as auto-completion, syntax highlighting, and error checking.
amd-shark-ai
The amdshark-ai repository contains the amdshark Modeling and Serving Libraries, which include sub-projects like shortfin for high performance inference, amdsharktank for model recipes and conversion tools, and amdsharktuner for tuning program performance. Developers can find API documentation, programming guides, and support matrix for various models within the repository.
TEN-Agent
TEN Agent is an open-source multimodal agent powered by the world’s first real-time multimodal framework, TEN Framework. It offers high-performance real-time multimodal interactions, multi-language and multi-platform support, edge-cloud integration, flexibility beyond model limitations, and real-time agent state management. Users can easily build complex AI applications through drag-and-drop programming, integrating audio-visual tools, databases, RAG, and more.
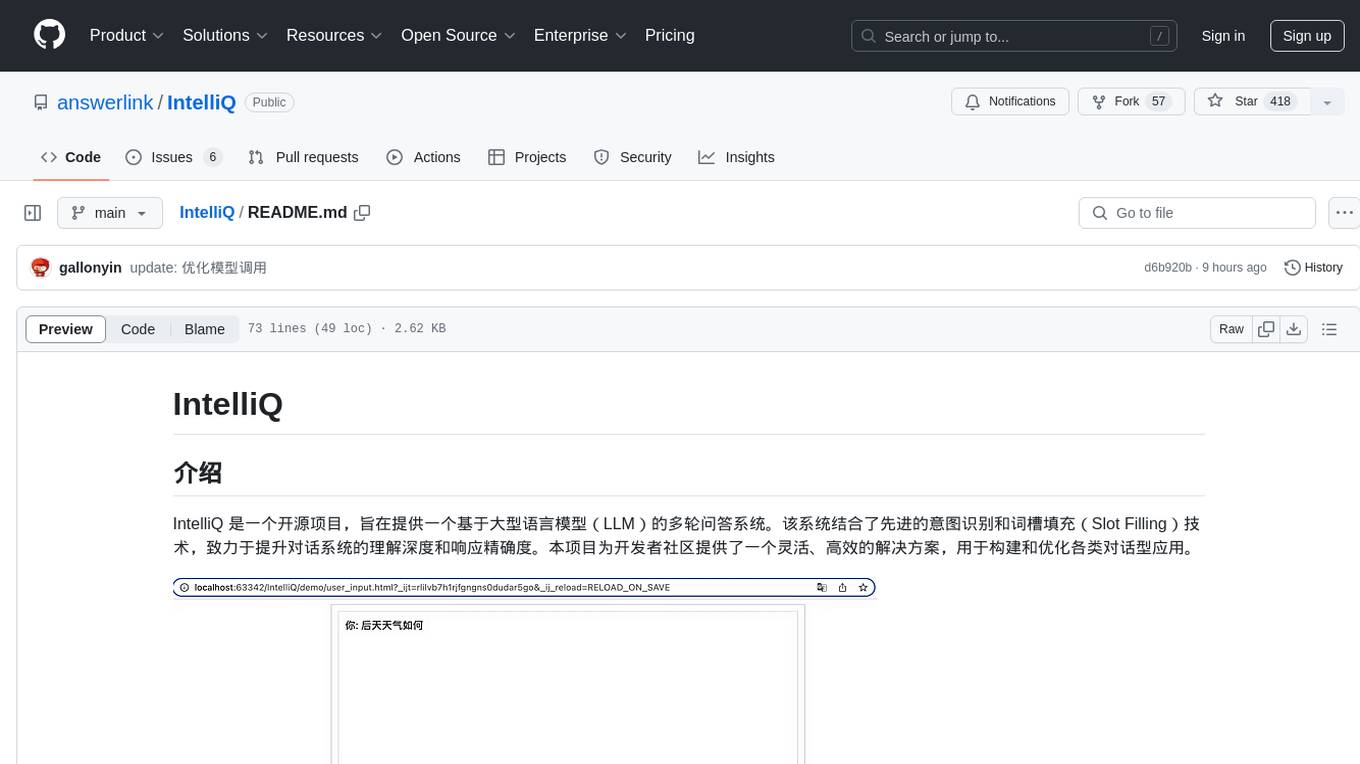
IntelliQ
IntelliQ is an open-source project aimed at providing a multi-turn question-answering system based on a large language model (LLM). The system combines advanced intent recognition and slot filling technology to enhance the depth of understanding and accuracy of responses in conversation systems. It offers a flexible and efficient solution for developers to build and optimize various conversational applications. The system features multi-turn dialogue management, intent recognition, slot filling, interface slot technology for real-time data retrieval and processing, adaptive learning for improving response accuracy and speed, and easy integration with detailed API documentation supporting multiple programming languages and platforms.
ST-LLM
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.
speakeasy
Speakeasy is a tool that helps developers create production-quality SDKs, Terraform providers, documentation, and more from OpenAPI specifications. It supports a wide range of languages, including Go, Python, TypeScript, Java, and C#, and provides features such as automatic maintenance, type safety, and fault tolerance. Speakeasy also integrates with popular package managers like npm, PyPI, Maven, and Terraform Registry for easy distribution.
xpert
Xpert is a powerful tool for data analysis and visualization. It provides a user-friendly interface to explore and manipulate datasets, perform statistical analysis, and create insightful visualizations. With Xpert, users can easily import data from various sources, clean and preprocess data, analyze trends and patterns, and generate interactive charts and graphs. Whether you are a data scientist, analyst, researcher, or student, Xpert simplifies the process of data analysis and visualization, making it accessible to users with varying levels of expertise.

AceCoder
AceCoder is a tool that introduces a fully automated pipeline for synthesizing large-scale reliable tests used for reward model training and reinforcement learning in the coding scenario. It curates datasets, trains reward models, and performs RL training to improve coding abilities of language models. The tool aims to unlock the potential of RL training for code generation models and push the boundaries of LLM's coding abilities.
denser-retriever
Denser Retriever is an enterprise-grade AI retriever designed to streamline AI integration into applications, combining keyword-based searches, vector databases, and machine learning rerankers using xgboost. It provides state-of-the-art accuracy on MTEB Retrieval benchmarking and supports various heterogeneous retrievers for end-to-end applications like chatbots and semantic search.
autoflow
AutoFlow is an open source graph rag based knowledge base tool built on top of TiDB Vector and LlamaIndex and DSPy. It features a Perplexity-style Conversational Search page and an Embeddable JavaScript Snippet for easy integration into websites. The tool allows for comprehensive coverage and streamlined search processes through sitemap URL scraping.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.
For similar tasks
Train-llm-from-scratch
Train-llm-from-scratch is a repository that guides users through training a Large Language Model (LLM) from scratch. The model size can be adjusted based on available computing power. The repository utilizes deepspeed for distributed training and includes detailed explanations of the code and key steps at each stage to facilitate learning. Users can train their own tokenizer or use pre-trained tokenizers like ChatGLM2-6B. The repository provides information on preparing pre-training data, processing training data, and recommended SFT data for fine-tuning. It also references other projects and books related to LLM training.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.

starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.
enhance_llm
The enhance_llm repository contains three main parts: 1. Vector model domain fine-tuning based on llama_index and qwen fine-tuning BGE vector model. 2. Large model domain fine-tuning based on PEFT fine-tuning qwen1.5-7b-chat, with sft and dpo. 3. High-order retrieval enhanced generation (RAG) system based on the above domain work, implementing a two-stage RAG system. It includes query rewriting, recall reordering, retrieval reordering, multi-turn dialogue, and more. The repository also provides hardware and environment configurations along with star history and licensing information.
fms-fsdp
The 'fms-fsdp' repository is a companion to the Foundation Model Stack, providing a (pre)training example to efficiently train FMS models, specifically Llama2, using native PyTorch features like FSDP for training and SDPA implementation of Flash attention v2. It focuses on leveraging FSDP for training efficiently, not as an end-to-end framework. The repo benchmarks training throughput on different GPUs, shares strategies, and provides installation and training instructions. It trained a model on IBM curated data achieving high efficiency and performance metrics.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.