
LotteryAi
LotteryAi is a lottery prediction artificial intelligence that uses machine learning to predict the winning numbers of a lottery.
Stars: 108

LotteryAi is a lottery prediction artificial intelligence that uses machine learning to predict the winning numbers of any lottery game. It requires Python 3.x and specific libraries like numpy, tensorflow, keras, and art for installation. Users need a data file with past lottery results in a comma-separated format to train the model and generate predictions. The tool comes with no guarantee of accuracy in predicting lottery numbers and is meant for educational and research purposes only.
README:

LotteryAi is a advanced lottery prediction artificial intelligence that uses state-of-the-art machine learning to predict the winning numbers of ANY lottery game.
If you need powerfull and advanced AI's with GUI, you can get the compiled standalone applications from here:
https://www.buymeacoffee.com/CorvusCodex/e/155047?from_page=extras
https://buymeacoffee.com/corvuscodex/e/367859
Other lottery versions (Windows 10,11):
PowerBall AI with GUI https://buymeacoffee.com/corvuscodex/e/320434
MegaMillions AI with GUI https://buymeacoffee.com/corvuscodex/e/325420
To install LotteryAi, you will need to have or download Python 3.x and the following libraries installed:
- numpy
- tensorflow
- keras
- art
You can install these libraries using pip by running the following command:
''pip install numpy tensorflow keras art''
To use LotteryAi, you will need to have a data file containing past lottery results. This file should be in a comma-separated format, with each row representing a single draw and the numbers in ascending order, rows are in new line without comma. Dont use white spaces. Last row number must have nothing after last number. With more data the model will be precise.
Once you have the data file, you can run the LotteryAi.py script to train the model and generate predictions. The script will print the generated ASCII art and the first ten rows of predicted numbers to the console.
Documentation is included in the standalone version.
If generated dataset is needed you can buy one generated from here https://www.buymeacoffee.com/CorvusCodex/e/154462
or order custom from here: https://buymeacoffee.com/corvuscodex/commissions
Support my work:
BTC: bc1q7wth254atug2p4v9j3krk9kauc0ehys2u8tgg3
POL/ETH/BNB: 0x68B6D33Ad1A3e0aFaDA60d6ADf8594601BE492F0
SOL: FsX3CsTFkRjzne2KiD8gjw3PEW2bYqezKfydAP55BVj7
Buy me a coffee: https://www.buymeacoffee.com/CorvusCodex
Buy me some equipment (To develop/train more powerfull versions and to develop standalone versions for MacOS):
https://www.buymeacoffee.com/corvuscodex/
The code within this repository comes with no guarantee, the use of this code is your responsibility. I take NO responsibility and/or liability for how you choose to use any of the source code available here. By using any of the files available in this repository, you understand that you are AGREEING TO USE AT YOUR OWN RISK. Once again, ALL files available here are for EDUCATION and/or RESEARCH purposes ONLY. Please keep in mind that while LotteryAi.py uses advanced machine learning techniques to predict lottery numbers, there is no guarantee that its predictions will be accurate. Lottery results are inherently random and unpredictable, so it is important to use LotteryAi responsibly and not rely solely on its predictions.
Copyright (c) 2025 - CorvusCodex
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LotteryAi
Similar Open Source Tools
LotteryAi
LotteryAi is a lottery prediction artificial intelligence that uses machine learning to predict the winning numbers of any lottery game. It requires Python 3.x and specific libraries like numpy, tensorflow, keras, and art for installation. Users need a data file with past lottery results in a comma-separated format to train the model and generate predictions. The tool comes with no guarantee of accuracy in predicting lottery numbers and is meant for educational and research purposes only.
PythonDataScienceFullThrottle
PythonDataScienceFullThrottle is a comprehensive repository containing various Python scripts, libraries, and tools for data science enthusiasts. It includes a wide range of functionalities such as data preprocessing, visualization, machine learning algorithms, and statistical analysis. The repository aims to provide a one-stop solution for individuals looking to dive deep into the world of data science using Python.
ClipboardConqueror
Clipboard Conqueror is a multi-platform omnipresent copilot alternative. Currently requiring a kobold united or openAI compatible back end, this software brings powerful LLM based tools to any text field, the universal copilot you deserve. It simply works anywhere. No need to sign in, no required key. Provided you are using local AI, CC is a data secure alternative integration provided you trust whatever backend you use. *Special thank you to the creators of KoboldAi, KoboldCPP, llamma, openAi, and the communities that made all this possible to figure out.
lfai-landscape
LF AI & Data Landscape is a map to explore open source projects in the AI & Data domains, highlighting companies that are members of LF AI & Data. It showcases members of the Foundation and is modelled after the Cloud Native Computing Foundation landscape. The landscape includes current version, interactive version, new entries, logos, proper SVGs, corrections, external data, best practices badge, non-updated items, license, formats, installation, vulnerability reporting, and adjusting the landscape view.

gpdb
Greenplum Database (GPDB) is an advanced, fully featured, open source data warehouse, based on PostgreSQL. It provides powerful and rapid analytics on petabyte scale data volumes. Uniquely geared toward big data analytics, Greenplum Database is powered by the world’s most advanced cost-based query optimizer delivering high analytical query performance on large data volumes.
Build-your-own-AI-Assistant-Solution-Accelerator
Build-your-own-AI-Assistant-Solution-Accelerator is a pre-release and preview solution that helps users create their own AI assistants. It leverages Azure Open AI Service, Azure AI Search, and Microsoft Fabric to identify, summarize, and categorize unstructured information. Users can easily find relevant articles and grants, generate grant applications, and export them as PDF or Word documents. The solution accelerator provides reusable architecture and code snippets for building AI assistants with enterprise data. It is designed for researchers looking to explore flu vaccine studies and grants to accelerate grant proposal submissions.
claudine
Claudine is an AI agent designed to reason and act autonomously, leveraging the Anthropic API, Unix command line tools, HTTP, local hard drive data, and internet data. It can administer computers, analyze files, implement features in source code, create new tools, and gather contextual information from the internet. Users can easily add specialized tools. Claudine serves as a blueprint for implementing complex autonomous systems, with potential for customization based on organization-specific needs. The tool is based on the anthropic-kotlin-sdk and aims to evolve into a versatile command line tool similar to 'git', enabling branching sessions for different tasks.
wave-apps
Wave Apps is a directory of sample applications built on H2O Wave, allowing users to build AI apps faster. The apps cover various use cases such as explainable hotel ratings, human-in-the-loop credit risk assessment, mitigating churn risk, online shopping recommendations, and sales forecasting EDA. Users can download, modify, and integrate these sample apps into their own projects to learn about app development and AI model deployment.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
AutoGroq
AutoGroq is a revolutionary tool that dynamically generates tailored teams of AI agents based on project requirements, eliminating manual configuration. It enables users to effortlessly tackle questions, problems, and projects by creating expert agents, workflows, and skillsets with ease and efficiency. With features like natural conversation flow, code snippet extraction, and support for multiple language models, AutoGroq offers a seamless and intuitive AI assistant experience for developers and users.

WilmerAI
WilmerAI is a middleware system designed to process prompts before sending them to Large Language Models (LLMs). It categorizes prompts, routes them to appropriate workflows, and generates manageable prompts for local models. It acts as an intermediary between the user interface and LLM APIs, supporting multiple backend LLMs simultaneously. WilmerAI provides API endpoints compatible with OpenAI API, supports prompt templates, and offers flexible connections to various LLM APIs. The project is under heavy development and may contain bugs or incomplete code.
aiverify
AI Verify is an AI governance testing framework and software toolkit that validates the performance of AI systems against a set of internationally recognised principles through standardised tests. AI Verify is consistent with international AI governance frameworks such as those from European Union, OECD and Singapore. It is a single integrated toolkit that operates within an enterprise environment. It can perform technical tests on common supervised learning classification and regression models for most tabular and image datasets. It however does not define AI ethical standards and does not guarantee that any AI system tested will be free from risks or biases or is completely safe.

deep-seek
DeepSeek is a new experimental architecture for a large language model (LLM) powered internet-scale retrieval engine. Unlike current research agents designed as answer engines, DeepSeek aims to process a vast amount of sources to collect a comprehensive list of entities and enrich them with additional relevant data. The end result is a table with retrieved entities and enriched columns, providing a comprehensive overview of the topic. DeepSeek utilizes both standard keyword search and neural search to find relevant content, and employs an LLM to extract specific entities and their associated contents. It also includes a smaller answer agent to enrich the retrieved data, ensuring thoroughness. DeepSeek has the potential to revolutionize research and information gathering by providing a comprehensive and structured way to access information from the vastness of the internet.
HybridAGI
HybridAGI is the first Programmable LLM-based Autonomous Agent that lets you program its behavior using a **graph-based prompt programming** approach. This state-of-the-art feature allows the AGI to efficiently use any tool while controlling the long-term behavior of the agent. Become the _first Prompt Programmers in history_ ; be a part of the AI revolution one node at a time! **Disclaimer: We are currently in the process of upgrading the codebase to integrate DSPy**
llm_agents
LLM Agents is a small library designed to build agents controlled by large language models. It aims to provide a better understanding of how such agents work in a concise manner. The library allows agents to be instructed by prompts, use custom-built components as tools, and run in a loop of Thought, Action, Observation. The agents leverage language models to generate Thought and Action, while tools like Python REPL, Google search, and Hacker News search provide Observations. The library requires setting up environment variables for OpenAI API and SERPAPI API keys. Users can create their own agents by importing the library and defining tools accordingly.
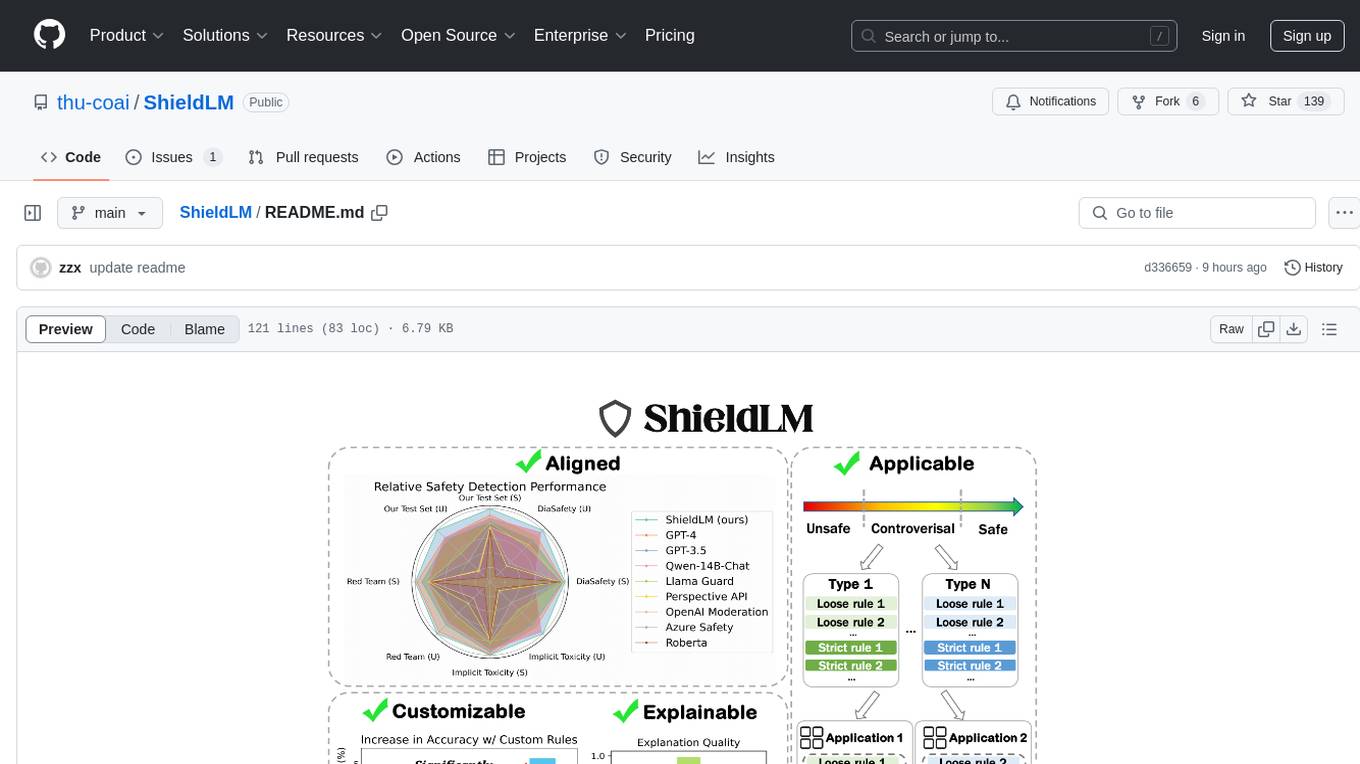
ShieldLM
ShieldLM is a bilingual safety detector designed to detect safety issues in LLMs' generations. It aligns with human safety standards, supports customizable detection rules, and provides explanations for decisions. Outperforming strong baselines, ShieldLM is impressive across 4 test sets.
For similar tasks
LotteryAi
LotteryAi is a lottery prediction artificial intelligence that uses machine learning to predict the winning numbers of any lottery game. It requires Python 3.x and specific libraries like numpy, tensorflow, keras, and art for installation. Users need a data file with past lottery results in a comma-separated format to train the model and generate predictions. The tool comes with no guarantee of accuracy in predicting lottery numbers and is meant for educational and research purposes only.

LongRAG
This repository contains the code for LongRAG, a framework that enhances retrieval-augmented generation with long-context LLMs. LongRAG introduces a 'long retriever' and a 'long reader' to improve performance by using a 4K-token retrieval unit, offering insights into combining RAG with long-context LLMs. The repo provides instructions for installation, quick start, corpus preparation, long retriever, and long reader.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.

llm_processes
This repository contains code for LLM Processes, which focuses on generating numerical predictive distributions conditioned on natural language. It supports various LLMs through Hugging Face transformer APIs and includes experiments on prompt engineering, 1D synthetic data, comparison to LLMTime, Fashion MNIST, black-box optimization, weather regression, in-context learning, and text conditioning. The code requires Python 3.9+, PyTorch 2.3.0+, and other dependencies for running experiments and reproducing results.
spring-ai-tutorial
Spring AI Tutorial is a comprehensive guide for beginners to learn about integrating artificial intelligence capabilities into Spring Boot applications. The tutorial covers various AI concepts such as machine learning, natural language processing, and computer vision, and demonstrates how to implement them using popular AI libraries and tools within the Spring framework. By following this tutorial, users will gain a solid understanding of how to leverage AI technologies to enhance the functionality and intelligence of their Spring applications.

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.