
strwythura
Construct knowledge graphs from unstructured data sources, use graph algorithms for enhanced GraphRAG with a DSPy-based chat bot locally, and curate semantics for optimizing AI app outcomes within a specific domain.
Stars: 173
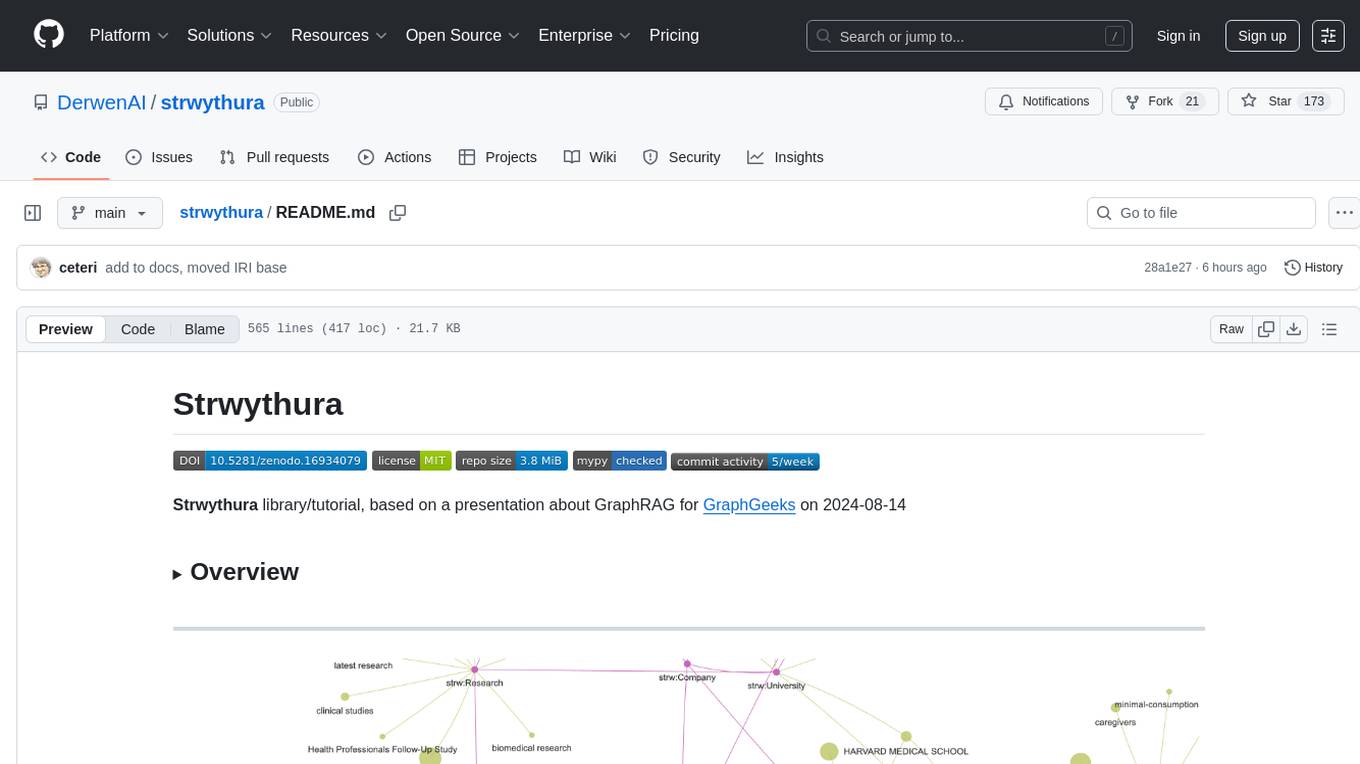
Strwythura is a library and tutorial focused on constructing a knowledge graph from unstructured data sources using state-of-the-art models for named entity recognition. It implements an enhanced GraphRAG approach and curates semantics for optimizing AI application outcomes within a specific domain. The tutorial emphasizes the use of sophisticated NLP pipelines based on spaCy, GLiNER, TextRank, and related libraries to provide better/faster/cheaper results with more control over the intentional arrangement of the knowledge graph. It leverages neurosymbolic AI methods and combines practices from natural language processing, graph data science, entity resolution, ontology pipeline, context engineering, and human-in-the-loop processes.
README:



Strwythura library/tutorial, based on a presentation about GraphRAG for GraphGeeks on 2024-08-14
How to construct a knowledge graph (KG) from unstructured data sources using state of the art (SOTA) models for named entity recognition (NER), then implement an enhanced GraphRAG approach, and curate semantics for optimizing AI app outcomes within a specific domain.
- videos: https://youtu.be/B6_NfvQL-BE, https://senzing.com/gph-graph-rag-llm-knowledge-graphs/
- slides: https://derwen.ai/s/2njz#1
Motivation for this tutorial comes from the stark fact that the term "GraphRAG" means many things, based on multiple conflicting definitions. Several popular implementations reveal a relatively cursory understanding about either natural language processing (NLP) or graph algorithms, plus a vendor bias toward their own query language.
See this article for more details and history: "Unbundling the Graph in GraphRAG".
Instead of delegating KG construction to a large language model
(LLM), this tutorial shows the use of sophisticated NLP pipelines
based on spaCy, GLiNER, TextRank, and related libraries.
Results are better/faster/cheaper, plus this provides more control
and oversight for intentional arrangement of the KG. Then for
downstream usage in a question/answer chat bot, an enhanced GraphRAG
approach leverages graph algorithms (e.g., semantic random walk)
to optimize retrieval of text chunks which ultimately get presented
to an LLM for summarization to produce responses.
For more detailed discussions, see:
- enhanced GraphRAG: "GraphRAG to enhance LLM-based apps"
- ontology pipeline: "Intentional Arrangement" by Jessica Talisman
- Ontology Engineering by Elisa Kendall, Deborah McGuiness, Ying Ding
-
spaCy: https://spacy.io/ -
GLiNER: https://huggingface.co/urchade/gliner_base - TextRank: https://www.derwen.ai/docs/ptr/explain_algo/
Some key issues regarding KG construction with LLMs which don't get addressed much by the graph community and AI community in general:
- LLMs tend to mangle cross-domain semantics when used for building graphs; see Mai2024 referenced in the "GraphRAG to enhance LLM-based apps" talk above.
- You need to introduce a semantic layer for representing the domain context, which follows more of a neurosymbolic AI approach.
- Most all LLMs perform question rewriting in ways which cannot be disabled, even when the
temperatureparameter is set to zero; this leads to relative degrees of "hallucinated questions" for which there are no clear workarounds. - Any model used for prediction introduces reasoning based on generalization, even more so when the model uses a loss function for training; this tends to be the point where KG structure and semantics turn into crap; see the "Let's talk about ..." articles linked below.
- The approach outlined here is faster and less expensive, and produces better results than if you'd delegated KG construction to an LLM.
Of course, YMMV.
This approach leverages neurosymbolic AI methods, combining practices from:
- natural language processing
- graph data science
- entity resolution
- ontology pipeline
- context engineering
- human-in-the-loop
Overall, this illustrates a reference implementation for entity-resolved retrieval-augmented generation (ER-RAG).

This runs with Python 3.11, though the range of versions may be extended soon.
To pip install from PyPi:
python3 -m pip install strwathura
python3 -m spacy download en_core_web_mdThen to integrate this library within an application:
- Copy settings in
config.tomlinto a custom configuration file. - Subclass
DomainContextto extend it for the use case. - Define semantics in
domain.ttlfor the domain context. - Run entity resolution to merge the structured datasets.
- Run
Ollamaand have already downloaded the Gemma3 LLM as described below. - Instantiate new
DomainContext,Strwythura,VisHTML, andGraphRAGobjects or their subclassed extensions. - ...
- Profit
Follow the patterns in the build.py and errag.py example scripts.
Feel free to swap in different spaCy models, different LLMs, etc.
If you're working with documents in a language other than English, well that's absolutely fantastic, though you will need to:
- Update model settings in the
config.tomlfile. - Change the
spaCymodel downloaded here. - Also change the language tags used in
domain.ttlas needed.
This library uses poetry for
package management and you need to install it to get things running:
poetry update
poetry run python3 -m spacy download en_core_web_md
Run entity resolution (ER) to produce entities and relations from structured data sources, which tend to be more reliable than those extracted from unstructured content.
What does this ER step buy us? ER allows us to merge multiple structured data sets, even without consistent foreign keys being available, producing an overlay of entities and relations among them. This is quite useful as a "backbone" for constructing a KG. Morever when there are judgements being made from the KG about people or organizations, ER provides accountability for the merge decisions.
This approach becomes especially important in public sector, healthcare, banking, insurance -- i.e., in use cases where you might need to "send flowers" when automated judgements about identity go wrong. For example, someone gets denied a loan, has a medical insurance claim blocked, gets a tax audit, has their voter registration voided, becomes the subject of an arrest warrant, and so on.
In other words, people and organizations tend to take legal actions when someone else causes them harm by mangling identity managment. You'll want an audit trail of decisions based on evidence, whenever your software systems make these kinds of judgements.
For the domain context in this tutorial, say we have two hypothetical datasets which provide business directory listings:
-
sz_er/acme_biz.json-- "ACME Business Directory" -
sz_er/corp_home.json-- "Corporates Home UK"
Plus we have slices from datasets which provide listings about researchers and scientific authors:
The JSONL format of these datasests is based on data mapping, i.e., providing the entity resolution process with heuristics about features available the the structured dataset.
These four datasets get merged using ER, where the results produce a domain-specific thesaurus. This thesaurus generates instances of graph elements: entities, relations, properties. We'll blend this into our semantic layer used for organizing the KG later.
The following steps are optional, since these ER results have already
been pre-computed and provided in the sz_er/export.json file.
If you want to run Senzing
to produce these ER results, use the following steps.
Senzing SDK runs in Python or Java, and can also be run as batch using a container from DockerHub:
docker pull senzing/demo-senzingOnce this container is available, run:
docker run -it --rm --volume ./sz_er:/tmp/data senzing/demo-senzingThis brings up a Linux command line prompt I have no name! and the
local subdirectory sz_er will be mapped to the /tmp/data directory
Type the following commands for batch ER into the command line prompt.
Set up the Senzing configuration for merging these datasets:
G2ConfigTool.pyWithin the configuration tool, register the names of the data sources being used:
addDataSource ACME_BIZ
addDataSource CORP_HOME
addDataSource ORCID
addDataSource SCOPUS
save
exit
Load each file and run ER on its data records:
G2Loader.py -f /tmp/data/acme_biz.json
G2Loader.py -f /tmp/data/corp_home.json
G2Loader.py -f /tmp/data/orcid.json
G2Loader.py -f /tmp/data/scopus.jsonExport the ER results to the sz_er/export.json file, then exit the
container:
G2Export.py -F JSON -o /tmp/data/export.json
exitThis later gets parsed to produce the data/thesaurus.ttl file
(as RDF in "Turtle" format) during the next part of the demo to
augment the semantic layer.
Given as input:
-
domain.ttl-- semantics for the domain context -
sz_er/export.json-- a domain-specific thesaurus based on ER - a list of structured datasets used in ER
- a list of URLs from which to scrape content
The domain.ttl file provides a basis for iterating with an ontology
pipeline process, to represent the semantics for the given domain.
It specifies metadata in terms of vocabulary, taxonomy, and
thesaurus -- to use in representing the core entities and relations
in the KG.
The curate.py script described below then will introduce the
human-in-the-loop part of this process, where you can review
entities extracted from documents. Based on this analysis, decide
where to refine the domain context to be able to extract,
classify, and connect more of what gets extracted from
unstructured data sources and linked into the KG. Overall, this
process distills elements of the lexical graph, linking them with
elements from the data graph, to produce a more abstracted (i.e.,
less noisy) semantic layer as the resulting KG.
Meanwhle, let's get started. The build.py script scrapes text
sources and constructs a knowledge graph plus entity embeddings,
with nodes linked to chunks in a vector store:
poetry run python3 build.pyDemo data used in this case includes articles about the linkage between eating processed red meat frequently and the risks of dementia later in life, based on long-term studies.
The approach in this tutorial iterates through multiple steps to produce the assets needed for GraphRAG downstream:
- Scrape each URL using
requestsandBeautifulSoup - Split the text into chunks
- Build vector embeddings for each chunk, in
LanceDB - Parse each text chunk using
spaCy, iterating per sentence - Extract entities from each sentence using
GLiNER - Build a lexical graph from the parse trees in
NetworkX - Run a textrank algorithm to rank important entities
- Build an embedding model for entities using
gensim.Word2Vec - Generate an interactive visualization using
PyVis
Note: processing may take a few extra minutes the first time it runs
since PyTorch must download a large (~2GB) file.
The assets get serialized into these files:
-
data/lancedb-- vector database tables inLanceDB -
data/kg.json-- serialization ofNetworkXgraph -
data/sem.csv-- entity semantics fromcurate.py -
data/entity.w2v-- entity embeddings inGensim -
data/url_cache.sqlite-- URL cache inSQLite -
kg.html-- interactive graph visualization inPyVis
A good downstream use case for exploring a newly constructed KG is GraphRAG, used for grounding the responses by an LLM in a question/answer chat.
This implementation uses DSPy https://dspy.ai/ and leverages
the KG for enhanced GraphRAG by using semantic expansion and
semantic random walks.
With a bit of imagination, an interation on this approach could
leverage DSPy plus its sister project MLflow https://mlflow.org/
to develop much more sophisticated agentic workflows downstream.
To set up, download/install Ollama https://ollama.com/ and pull
the gemma3:12b model https://huggingface.co/google/gemma-3-12b-it
ollama pull gemma3:12bThen run the errag.py script for an interactive GraphRAG example:
poetry run python3 errag.pyThis approach uses a semantic layer -- in other words, a "backbone" for the KG -- to organize the entities and relations which get abstracted from the lexical graph.
For now, run the curate.py script to generate a view of the ranked
NER results, serialized as the data/sem.csv file. This can be
viewed in a spreadsheet to understand how to iterate on the semantic
definitions for more effective graph organization in the domain of the
scraped documents.
poetry run python3 curate.py
Objective:
Construct a knowledge graph (KG) using open source libraries where deep learning models provide narrowly-focused point solutions to generate components for a graph: nodes, edges, properties.
These steps define a generalized process, where this tutorial picks up at the lexical graph, without the entity linking (EL) part yet:
Semantic layer:
- Load any semantics for domain context from pre-defined controlled vocabularies, taxonomies, thesauri, ontologies, etc., directly into the KG.
Data graph:
- Load the structured data sources or updates into a data graph.
- Perform entity resolution (ER) on PII extracted from the data graph.
- Blend the ER results into the semantic layer as a "backbone" for structuring the KG.
Lexical graph:
- Parse the text chunks, using lemmatization to normalize token spans.
- Construct a lexical graph from parse trees, e.g., using a textgraph algorithm.
- Analyze named entity recognition (NER) to extract candidate entities from noun phrase spans.
- Analyze relation extraction (RE) to extract relations between pairwise entities.
- Perform entity linking (EL) leveraging the ER results.
- Promote the extracted entities and relations up to the semantic layer.
Of course many vendors suggest using a large language model (LLM) as a one-size-fits-all (OSFA) "black box" approach for extracting entities and generating an entire graph automagically.
However, the business process of resolution -- for both entities and relations -- requires judgements. If the entities getting resolved are low-risk, low-effort in nature, then yeah knock yourself out. If the entities represent people or organizations, these have agency and may take actions when misrepresented in applications which have consequences.
Whenever judgements get delegated to model-based approaches, generalization becomes a form of reasoning employed. When the technology within the model is based on loss functions, then generalization becomes dominant -- regardless of any marketing claims about "AI reasoning" made by tech firms.
Fortunately, decisions can be made without models, even in AI applications. Shock, horror!!! Please, say it isn't so!?! Brace yourselves, using models is a thing, but not the only thing. For more detailed discussion, see:
- Part 1: Let's talk about "Today's AI" https://www.linkedin.com/pulse/lets-talk-todays-ai-paco-nathan-co60c/
- Part 2: Let's talk about "Resolution" https://www.linkedin.com/pulse/lets-talk-resolution-paco-nathan-ryjhc/
Also keep in mind that black box approaches don't work especially well for regulated environments, where audits, explanations, evidence, data provenance, etc., are required.
Moreover, KGs used in mission-critical apps, such as investigations, generally require periodic data updates, so construction isn't a one-step process. By producing a KG based on the approach sketched above, updates can be handled more effectively. Any downstream use cases, such as AI applications, also benefit from improved quality of semantics and representation.
- Q:
- "Have you tried this with
langextractyet?" - A:
- "I'll take
How does an instructor know a student ignored the README?from the What is FAFO? category, for $200 ... but yes of course, it's an interesting package, which builds on other interesting work used here. Except that key parts of it miss the point entirely, in ways that only a hyperscaler could possibly fuck up so badly."
- Q:
- "What the hell is the name of this repo about?"
- A:
- "As you may have noticed, many open source projects published in this GitHub organization are named in a beautiful language Gymraeg, which English speakers call 'Welsh', where this word
strwythuratranslates as the verb structure in English."
- Q:
- "Why aren't you using an LLM to build the graph instead?"
- A:
- "I promise to visit you in jail."
- Q:
- "Um, yeah, like, didn't Karpathy say to use vibe coding, or something? #justsayin"
- A:
- "Piss the eff off tech bro. Srsly, like yesterday -- you're embarrassing our entire industry with your overly exuberant ignorance."
Experimental: Relation Extraction evaluation
Current Python libraries for relation extraction (RE) are probably best characterized as "experimental research projects".
Their tokenization approaches tend to make the mistake of "throwing the baby out with the bath water" by not leveraging other available information, e.g., what we have in the textgraph representation of the parsed documents. Also, they tend to ignore the semantic constraints of the domain context, while computationally boiling the ocean.
RE libraries which have been evaluated:
-
GLiREL: https://github.com/jackboyla/GLiREL -
ReLIK: https://github.com/SapienzaNLP/relik -
OpenNRE: https://github.com/thunlp/OpenNRE -
mREBEL: https://github.com/Babelscape/rebel
This project had used GLiREL although its results were quite sparse.
The relation extraction will be replaced by DSPy workflows in the
near future.
There is some experimental code which illustrates OpenNRE evaluation.
Use the archive/nre.sh script to load OpenNRE pre-trained models
before running the archive/opennre.ipynb notebook.
This may not work in many environments, depending on how well the
OpenNRE library is being maintained.
Experimental: Tutorial notebooks
A collection of Jupyter notebooks were used to prototype code. These help illustrate important intermediate steps within these workflows:
.venv/bin/jupyter-lab- `archive/construct.ipynb` -- detailed KG construction using a lexical graph
- `archive/chunk.ipynb` -- simple example of how to scrape and chunk text
- `archive/vector.ipynb` -- query LanceDB table for text chunk embeddings (after running `build.py`)
- `archive/embed.ipynb` -- query the entity embedding model (after running `build.py`)
These are now archived, though kept available for study.
License and Copyright
Source code for Strwythura plus its logo, documentation, and examples have an MIT license which is succinct and simplifies use in commercial applications.
All materials herein are Copyright © 2024-2025 Senzing, Inc.
Kudos and Attribution
Please use the following BibTeX entry for citing Strwythura if you use it in your research or software. Citations are helpful for the continued development and maintenance of this library.
@software{strwythura,
author = {Paco Nathan},
title = {{Strwythura: construct a knowledge graph from unstructured data sources, organized by results from entity resolution, implementing an enhanced GraphRAG approach, and also implementing an ontology pipeline plus context engineering for optimizing AI application outcomes within a specific domain}},
year = 2024,
publisher = {Senzing},
doi = {10.5281/zenodo.16934079},
url = {https://github.com/DerwenAI/strwythura}
}Kudos to @louisguitton, @cj2001, @prrao87, @hellovai, @docktermj, @jbutcher21, @brianmacy, and the kind folks at GraphGeeks for their support.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for strwythura
Similar Open Source Tools
strwythura
Strwythura is a library and tutorial focused on constructing a knowledge graph from unstructured data sources using state-of-the-art models for named entity recognition. It implements an enhanced GraphRAG approach and curates semantics for optimizing AI application outcomes within a specific domain. The tutorial emphasizes the use of sophisticated NLP pipelines based on spaCy, GLiNER, TextRank, and related libraries to provide better/faster/cheaper results with more control over the intentional arrangement of the knowledge graph. It leverages neurosymbolic AI methods and combines practices from natural language processing, graph data science, entity resolution, ontology pipeline, context engineering, and human-in-the-loop processes.

LongRAG
This repository contains the code for LongRAG, a framework that enhances retrieval-augmented generation with long-context LLMs. LongRAG introduces a 'long retriever' and a 'long reader' to improve performance by using a 4K-token retrieval unit, offering insights into combining RAG with long-context LLMs. The repo provides instructions for installation, quick start, corpus preparation, long retriever, and long reader.

MultiPL-E
MultiPL-E is a system for translating unit test-driven neural code generation benchmarks to new languages. It is part of the BigCode Code Generation LM Harness and allows for evaluating Code LLMs using various benchmarks. The tool supports multiple versions with improvements and new language additions, providing a scalable and polyglot approach to benchmarking neural code generation. Users can access a tutorial for direct usage and explore the dataset of translated prompts on the Hugging Face Hub.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.

rtdl-num-embeddings
This repository provides the official implementation of the paper 'On Embeddings for Numerical Features in Tabular Deep Learning'. It focuses on transforming scalar continuous features into vectors before integrating them into the main backbone of tabular neural networks, showcasing improved performance. The embeddings for continuous features are shown to enhance the performance of tabular DL models and are applicable to various conventional backbones, offering efficiency comparable to Transformer-based models. The repository includes Python packages for practical usage, exploration of metrics and hyperparameters, and reproducing reported results for different algorithms and datasets.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

knowledge-graph-of-thoughts
Knowledge Graph of Thoughts (KGoT) is an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. The KGoT system consists of three main components: the Controller, the Graph Store, and the Integrated Tools, each playing a critical role in the task-solving process.
mimir
MIMIR is a Python package designed for measuring memorization in Large Language Models (LLMs). It provides functionalities for conducting experiments related to membership inference attacks on LLMs. The package includes implementations of various attacks such as Likelihood, Reference-based, Zlib Entropy, Neighborhood, Min-K% Prob, Min-K%++, Gradient Norm, and allows users to extend it by adding their own datasets and attacks.
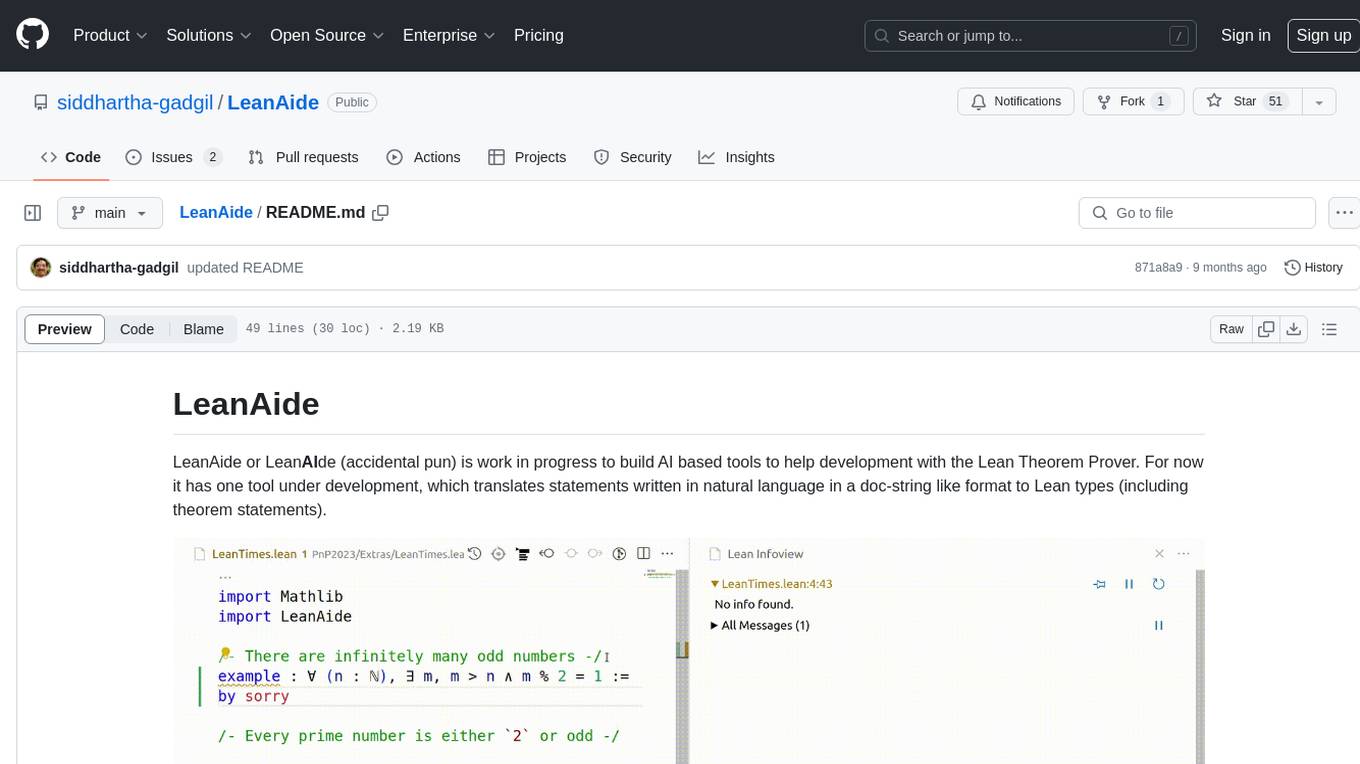
LeanAide
LeanAide is a work in progress AI tool designed to assist with development using the Lean Theorem Prover. It currently offers a tool that translates natural language statements to Lean types, including theorem statements. The tool is based on GPT 3.5-turbo/GPT 4 and requires an OpenAI key for usage. Users can include LeanAide as a dependency in their projects to access the translation functionality.

eval-dev-quality
DevQualityEval is an evaluation benchmark and framework designed to compare and improve the quality of code generation of Language Model Models (LLMs). It provides developers with a standardized benchmark to enhance real-world usage in software development and offers users metrics and comparisons to assess the usefulness of LLMs for their tasks. The tool evaluates LLMs' performance in solving software development tasks and measures the quality of their results through a point-based system. Users can run specific tasks, such as test generation, across different programming languages to evaluate LLMs' language understanding and code generation capabilities.

warc-gpt
WARC-GPT is an experimental retrieval augmented generation pipeline for web archive collections. It allows users to interact with WARC files, extract text, generate text embeddings, visualize embeddings, and interact with a web UI and API. The tool is highly customizable, supporting various LLMs, providers, and embedding models. Users can configure the application using environment variables, ingest WARC files, start the server, and interact with the web UI and API to search for content and generate text completions. WARC-GPT is designed for exploration and experimentation in exploring web archives using AI.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

garak
Garak is a vulnerability scanner designed for LLMs (Large Language Models) that checks for various weaknesses such as hallucination, data leakage, prompt injection, misinformation, toxicity generation, and jailbreaks. It combines static, dynamic, and adaptive probes to explore vulnerabilities in LLMs. Garak is a free tool developed for red-teaming and assessment purposes, focusing on making LLMs or dialog systems fail. It supports various LLM models and can be used to assess their security and robustness.
For similar tasks

NaLLM
The NaLLM project repository explores the synergies between Neo4j and Large Language Models (LLMs) through three primary use cases: Natural Language Interface to a Knowledge Graph, Creating a Knowledge Graph from Unstructured Data, and Generating a Report using static and LLM data. The repository contains backend and frontend code organized for easy navigation. It includes blog posts, a demo database, instructions for running demos, and guidelines for contributing. The project aims to showcase the potential of Neo4j and LLMs in various applications.
kweaver
KWeaver is an open-source cognitive intelligence development framework that provides data scientists, application developers, and domain experts with the ability for rapid development, comprehensive openness, and high-performance knowledge network generation and cognitive intelligence large model framework. It offers features such as automated and visual knowledge graph construction, visualization and analysis of knowledge graph data, knowledge graph integration, knowledge graph resource management, large model prompt engineering and debugging, and visual configuration for large model access.

graphrag-local-ollama
GraphRAG Local Ollama is a repository that offers an adaptation of Microsoft's GraphRAG, customized to support local models downloaded using Ollama. It enables users to leverage local models with Ollama for large language models (LLMs) and embeddings, eliminating the need for costly OpenAPI models. The repository provides a simple setup process and allows users to perform question answering over private text corpora by building a graph-based text index and generating community summaries for closely-related entities. GraphRAG Local Ollama aims to improve the comprehensiveness and diversity of generated answers for global sensemaking questions over datasets.

trustgraph
TrustGraph is a tool that deploys private GraphRAG pipelines to build a RDF style knowledge graph from data, enabling accurate and secure `RAG` requests compatible with cloud LLMs and open-source SLMs. It showcases the reliability and efficiencies of GraphRAG algorithms, capturing contextual language flags missed in conventional RAG approaches. The tool offers features like PDF decoding, text chunking, inference of various LMs, RDF-aligned Knowledge Graph extraction, and more. TrustGraph is designed to be modular, supporting multiple Language Models and environments, with a plug'n'play architecture for easy customization.
basic-memory
Basic Memory is a tool that enables users to build persistent knowledge through natural conversations with Large Language Models (LLMs) like Claude. It uses the Model Context Protocol (MCP) to allow compatible LLMs to read and write to a local knowledge base stored in simple Markdown files on the user's computer. The tool facilitates creating structured notes during conversations, maintaining a semantic knowledge graph, and keeping all data local and under user control. Basic Memory aims to address the limitations of ephemeral LLM interactions by providing a structured, bi-directional, and locally stored knowledge management solution.

helix-db
HelixDB is a database designed specifically for AI applications, providing a single platform to manage all components needed for AI applications. It supports graph + vector data model and also KV, documents, and relational data. Key features include built-in tools for MCP, embeddings, knowledge graphs, RAG, security, logical isolation, and ultra-low latency. Users can interact with HelixDB using the Helix CLI tool and SDKs in TypeScript and Python. The roadmap includes features like organizational auth, server code improvements, 3rd party integrations, educational content, and binary quantisation for better performance. Long term projects involve developing in-house tools for knowledge graph ingestion, graph-vector storage engine, and network protocol & serdes libraries.
strwythura
Strwythura is a library and tutorial focused on constructing a knowledge graph from unstructured data sources using state-of-the-art models for named entity recognition. It implements an enhanced GraphRAG approach and curates semantics for optimizing AI application outcomes within a specific domain. The tutorial emphasizes the use of sophisticated NLP pipelines based on spaCy, GLiNER, TextRank, and related libraries to provide better/faster/cheaper results with more control over the intentional arrangement of the knowledge graph. It leverages neurosymbolic AI methods and combines practices from natural language processing, graph data science, entity resolution, ontology pipeline, context engineering, and human-in-the-loop processes.

ApeRAG
ApeRAG is a production-ready platform for Retrieval-Augmented Generation (RAG) that combines Graph RAG, vector search, and full-text search with advanced AI agents. It is ideal for building Knowledge Graphs, Context Engineering, and deploying intelligent AI agents for autonomous search and reasoning across knowledge bases. The platform offers features like advanced index types, intelligent AI agents with MCP support, enhanced Graph RAG with entity normalization, multimodal processing, hybrid retrieval engine, MinerU integration for document parsing, production-grade deployment with Kubernetes, enterprise management features, MCP integration, and developer-friendly tools for customization and contribution.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.