
ling
The LLMs' framework optimized for ultra-fast response times.
Stars: 64
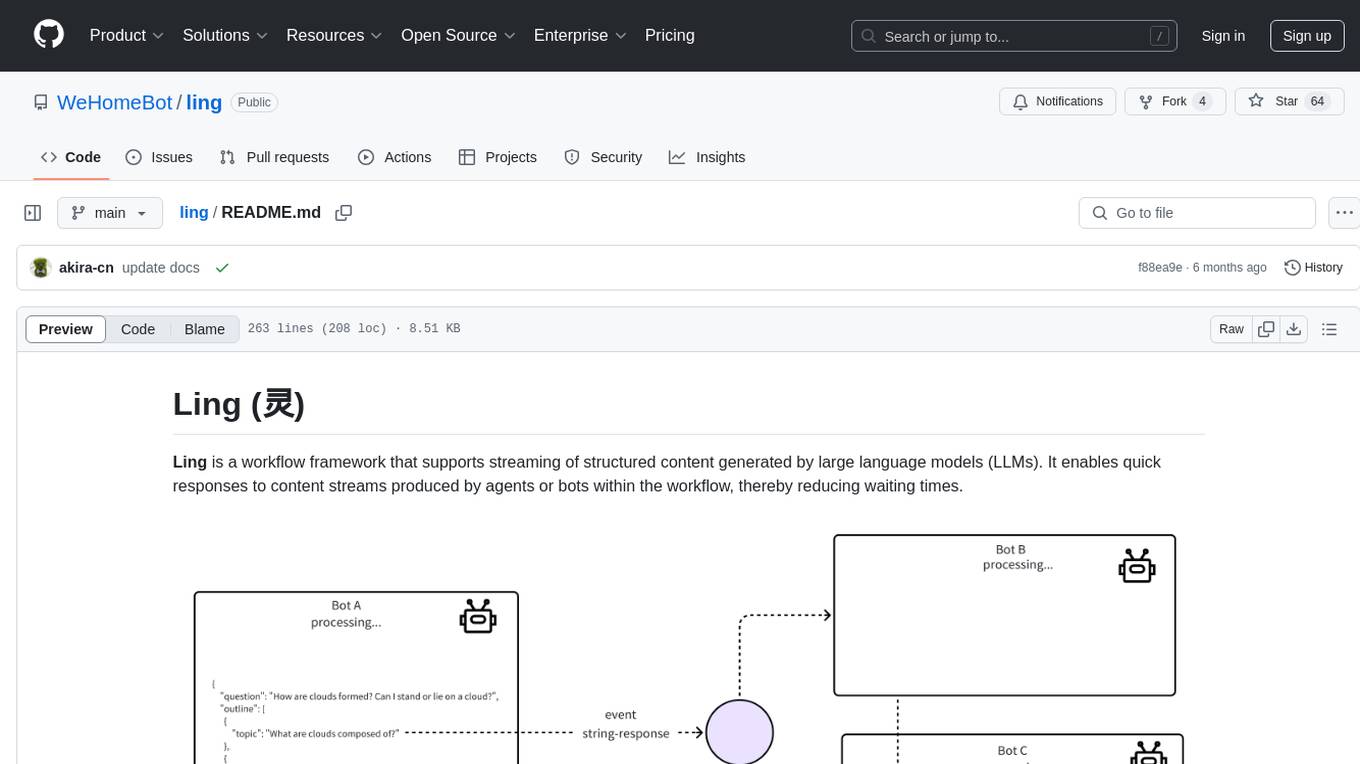
Ling is a workflow framework supporting streaming of structured content from large language models. It enables quick responses to content streams, reducing waiting times. Ling parses JSON data streams character by character in real-time, outputting content in jsonuri format. It facilitates immediate front-end processing by converting content during streaming input. The framework supports data stream output via JSONL protocol, correction of token errors in JSON output, complex asynchronous workflows, status messages during streaming output, and Server-Sent Events.
README:
Ling is a workflow framework that supports streaming of structured content generated by large language models (LLMs). It enables quick responses to content streams produced by agents or bots within the workflow, thereby reducing waiting times.
- [x] Supports data stream output via JSONL protocol.
- [x] Automatic correction of token errors in JSON output.
- [x] Supports complex asynchronous workflows.
- [x] Supports status messages during streaming output.
- [x] Supports Server-Sent Events.
- [ ] Provides Client SDK.
Complex AI workflows, such as those found in Bearbobo Learning Companion, require multiple agents/bots to process structured data collaboratively. However, considering real-time responses, utilizing structured data outputs is not conducive to enhancing timeliness through a streaming interface.
The commonly used JSON data format, although flexible, has structural integrity, meaning it is difficult to parse correctly until all the content is completely outputted. Of course, other structured data formats like YAML can be adopted, but they are not as powerful and convenient as JSON. Ling is a streaming framework created to address this issue. Its core is a real-time converter that can parse incoming JSON data streams character by character, outputting content in the form of jsonuri.
For example, consider the following JSON format:
{
"outline": [
{
"topic": "What are clouds made of?"
},
{
"topic": "Why do clouds look soft?"
}
]
// ...
}During streaming input, the content may be converted in real-time into the following data outputs (using Server-sent Events):
data: {"uri": "outline/0/topic", "delta": "clo"}
data: {"uri": "outline/0/topic", "delta": "uds"}
data: {"uri": "outline/0/topic", "delta": "are"}
data: {"uri": "outline/0/topic", "delta": "mad"}
data: {"uri": "outline/0/topic", "delta": "e"}
data: {"uri": "outline/0/topic", "delta": "of"}
data: {"uri": "outline/0/topic", "delta": "?"}
data: {"uri": "outline/1/topic", "delta": "Why"}
data: {"uri": "outline/1/topic", "delta": "do"}
data: {"uri": "outline/1/topic", "delta": "clo"}
data: {"uri": "outline/1/topic", "delta": "uds"}
data: {"uri": "outline/1/topic", "delta": "loo"}
data: {"uri": "outline/1/topic", "delta": "k"}
data: {"uri": "outline/1/topic", "delta": "sof"}
data: {"uri": "outline/1/topic", "delta": "t"}
data: {"uri": "outline/1/topic", "delta": "?"}
...
This method of real-time data transmission facilitates immediate front-end processing.
Server
import 'dotenv/config';
import express from 'express';
import bodyParser from 'body-parser';
import cors from 'cors';
import { Ling } from "@bearbobo/ling";
import type { ChatConfig } from "@bearbobo/ling/types";
import { pipeline } from 'node:stream/promises';
const apiKey = process.env.API_KEY as string;
const model_name = process.env.MODEL_NAME as string;
const endpoint = process.env.ENDPOINT as string;
const app = express();
app.use(cors());
app.use(bodyParser.json());
const port = 3000;
app.get('/', (req, res) => {
res.send('Hello World!');
});
app.post('/api', async (req, res) => {
const question = req.body.question;
const config: ChatConfig = {
model_name,
api_key: apiKey,
endpoint: endpoint,
};
// ------- The work flow start --------
const ling = new Ling(config);
const bot = ling.createBot(/*'bearbobo'*/);
bot.addPrompt('Respond to me in JSON format, starting with {.\n[Example]\n{"answer": "My response"}');
bot.chat(question);
bot.on('string-response', ({uri, delta}) => {
// Infer the content of the string in the JSON, and send the content of the 'answer' field to the second bot.
console.log('bot string-response', uri, delta);
const bot2 = ling.createBot(/*'bearbobo'*/);
bot2.addPrompt(`Expand the content I gave you into more detailed content, answer me in JSON format, place the detailed answer text in the 'details' field, and place 2-3 related knowledge points in the 'related_question' field.\n[Example]\n{"details": "My detailed answer", "related_question": [...]}`);
bot2.chat(delta);
bot2.on('response', (content) => {
// Stream data push completed.
console.log('bot2 response finished', content);
});
const bot3 = ling.createBot();
bot3.addPrompt('Expand the content I gave you into more detailed content, using Chinese. answer me in JSON format, place the detailed answer in Chinese in the 'details' field.\n[Example]\n{"details_cn": "my answer..."}');
bot3.chat(delta);
bot3.on('response', (content) => {
// Stream data push completed.
console.log('bot3 response finished', content);
});
});
ling.close(); // It can be directly closed, and when closing, it checks whether the status of all bots has been finished.
// ------- The work flow end --------
// setting below headers for Streaming the data
res.writeHead(200, {
'Content-Type': "text/event-stream",
'Cache-Control': "no-cache",
'Connection': "keep-alive"
});
console.log(ling.stream);
pipeline((ling.stream as any), res);
});
app.listen(port, () => {
console.log(`Example app listening at http://localhost:${port}`);
});Client
<script setup>
import { onMounted, ref } from 'vue';
import { set, get } from 'jsonuri';
const response = ref({
answer: 'Brief:',
details: 'Details:',
details_eng: 'Translation:',
related_question: [
'?',
'?',
'?'
],
});
onMounted(async () => {
const res = await fetch('http://localhost:3000/api', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
question: 'Can I laid on the cloud?'
}),
});
const reader = res.body.getReader();
const decoder = new TextDecoder();
let done = false;
const data = {
answer: 'Brief:',
details: 'Details:',
related_question: [],
};
while (!done) {
const { value, done: doneReading } = await reader.read();
done = doneReading;
if(!done) {
const content = decoder.decode(value);
const lines = content.trim().split('\n');
for(const line of lines) {
const input = JSON.parse(line);
if(input.uri) {
const content = get(data, input.uri);
set(data, input.uri, (content || '') + input.delta);
response.value = {...data};
}
}
}
}
});
</script>
<template>
<h1>Hello~</h1>
<p>{{ response.answer }}</p>
<p>{{ response.details }}</p>
<p>{{ response.details_eng }}</p>
<p v-for="item in response.related_question" :key="item.id"> >>> {{ item }}</p>
</template>This event is triggered when a string field in the JSON output by the AI is completed, returning a jsonuri object.
This event is triggered when the AI has completed its current inference, returning the complete output content. At this point, streaming output may not have ended, and data continues to be sent to the front end.
This event is triggered when all data generated by the AI during this session has been sent to the front end.
Note: Typically, the
string-responseevent occurs beforeinference-done, which in turn occurs beforeresponse.
Sometimes, we might want to send custom events to the front end to update its status. On the server, you can use ling.sendEvent({event, data}) to push messages to the front end. The front end can then receive and process JSON objects {event, data} from the stream.
bot.on('inference-done', () => {
bot.sendEvent({event: 'inference-done', state: 'Outline generated!'});
});Alternatively, you can also directly push jsonuri status updates, making it easier for the front end to set directly.
bot.on('inference-done', () => {
bot.sendEvent({uri: 'state/outline', delta: true});
});You can force ling to response the Server-Sent Events data format by using ling.setSSE(true). This allows the front end to handle the data using the EventSource API.
const es = new EventSource('http://localhost:3000/?question=Can I laid on the cloud?');
es.onmessage = (e) => {
console.log(e.data);
}
es.onopen = () => {
console.log('Connecting');
}
es.onerror = (e) => {
console.log(e);
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ling
Similar Open Source Tools
ling
Ling is a workflow framework supporting streaming of structured content from large language models. It enables quick responses to content streams, reducing waiting times. Ling parses JSON data streams character by character in real-time, outputting content in jsonuri format. It facilitates immediate front-end processing by converting content during streaming input. The framework supports data stream output via JSONL protocol, correction of token errors in JSON output, complex asynchronous workflows, status messages during streaming output, and Server-Sent Events.

ollama-ex
Ollama is a powerful tool for running large language models locally or on your own infrastructure. It provides a full implementation of the Ollama API, support for streaming requests, and tool use capability. Users can interact with Ollama in Elixir to generate completions, chat messages, and perform streaming requests. The tool also supports function calling on compatible models, allowing users to define tools with clear descriptions and arguments. Ollama is designed to facilitate natural language processing tasks and enhance user interactions with language models.
lmstudio.js
lmstudio.js is a pre-release alpha client SDK for LM Studio, allowing users to use local LLMs in JS/TS/Node. It is currently undergoing rapid development with breaking changes expected. Users can follow LM Studio's announcements on Twitter and Discord. The SDK provides API usage for loading models, predicting text, setting up the local LLM server, and more. It supports features like custom loading progress tracking, model unloading, structured output prediction, and cancellation of predictions. Users can interact with LM Studio through the CLI tool 'lms' and perform tasks like text completion, conversation, and getting prediction statistics.
structured-logprobs
This Python library enhances OpenAI chat completion responses by providing detailed information about token log probabilities. It works with OpenAI Structured Outputs to ensure model-generated responses adhere to a JSON Schema. Developers can analyze and incorporate token-level log probabilities to understand the reliability of structured data extracted from OpenAI models.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct
agent-kit
AgentKit is a framework for creating and orchestrating AI Agents, enabling developers to build, test, and deploy reliable AI applications at scale. It allows for creating networked agents with separate tasks and instructions to solve specific tasks, as well as simple agents for tasks like writing content. The framework requires the Inngest TypeScript SDK as a dependency and provides documentation on agents, tools, network, state, and routing. Example projects showcase AgentKit in action, such as the Test Writing Network demo using Workflow Kit, Supabase, and OpenAI.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.

firecrawl
Firecrawl is an API service that empowers AI applications with clean data from any website. It features advanced scraping, crawling, and data extraction capabilities. The repository is still in development, integrating custom modules into the mono repo. Users can run it locally but it's not fully ready for self-hosted deployment yet. Firecrawl offers powerful capabilities like scraping, crawling, mapping, searching, and extracting structured data from single pages, multiple pages, or entire websites with AI. It supports various formats, actions, and batch scraping. The tool is designed to handle proxies, anti-bot mechanisms, dynamic content, media parsing, change tracking, and more. Firecrawl is available as an open-source project under the AGPL-3.0 license, with additional features offered in the cloud version.
ogpt.nvim
OGPT.nvim is a Neovim plugin that enables users to interact with various language models (LLMs) such as Ollama, OpenAI, TextGenUI, and more. Users can engage in interactive question-and-answer sessions, have persona-based conversations, and execute customizable actions like grammar correction, translation, keyword generation, docstring creation, test addition, code optimization, summarization, bug fixing, code explanation, and code readability analysis. The plugin allows users to define custom actions using a JSON file or plugin configurations.
magma
Magma is a powerful and flexible framework for building scalable and efficient machine learning pipelines. It provides a simple interface for creating complex workflows, enabling users to easily experiment with different models and data processing techniques. With Magma, users can streamline the development and deployment of machine learning projects, saving time and resources.

sparkle
Sparkle is a tool that streamlines the process of building AI-driven features in applications using Large Language Models (LLMs). It guides users through creating and managing agents, defining tools, and interacting with LLM providers like OpenAI. Sparkle allows customization of LLM provider settings, model configurations, and provides a seamless integration with Sparkle Server for exposing agents via an OpenAI-compatible chat API endpoint.

parrot.nvim
Parrot.nvim is a Neovim plugin that prioritizes a seamless out-of-the-box experience for text generation. It simplifies functionality and focuses solely on text generation, excluding integration of DALLE and Whisper. It supports persistent conversations as markdown files, custom hooks for inline text editing, multiple providers like Anthropic API, perplexity.ai API, OpenAI API, Mistral API, and local/offline serving via ollama. It allows custom agent definitions, flexible API credential support, and repository-specific instructions with a `.parrot.md` file. It does not have autocompletion or hidden requests in the background to analyze files.
firecrawl-mcp-server
Firecrawl MCP Server is a Model Context Protocol (MCP) server implementation that integrates with Firecrawl for web scraping capabilities. It offers features such as web scraping, crawling, and discovery, search and content extraction, deep research and batch scraping, automatic retries and rate limiting, cloud and self-hosted support, and SSE support. The server can be configured to run with various tools like Cursor, Windsurf, SSE Local Mode, Smithery, and VS Code. It supports environment variables for cloud API and optional configurations for retry settings and credit usage monitoring. The server includes tools for scraping, batch scraping, mapping, searching, crawling, and extracting structured data from web pages. It provides detailed logging and error handling functionalities for robust performance.
bosquet
Bosquet is a tool designed for LLMOps in large language model-based applications. It simplifies building AI applications by managing LLM and tool services, integrating with Selmer templating library for prompt templating, enabling prompt chaining and composition with Pathom graph processing, defining agents and tools for external API interactions, handling LLM memory, and providing features like call response caching. The tool aims to streamline the development process for AI applications that require complex prompt templates, memory management, and interaction with external systems.
For similar tasks
ling
Ling is a workflow framework supporting streaming of structured content from large language models. It enables quick responses to content streams, reducing waiting times. Ling parses JSON data streams character by character in real-time, outputting content in jsonuri format. It facilitates immediate front-end processing by converting content during streaming input. The framework supports data stream output via JSONL protocol, correction of token errors in JSON output, complex asynchronous workflows, status messages during streaming output, and Server-Sent Events.
island-ai
island-ai is a TypeScript toolkit tailored for developers engaging with structured outputs from Large Language Models. It offers streamlined processes for handling, parsing, streaming, and leveraging AI-generated data across various applications. The toolkit includes packages like zod-stream for interfacing with LLM streams, stream-hooks for integrating streaming JSON data into React applications, and schema-stream for JSON streaming parsing based on Zod schemas. Additionally, related packages like @instructor-ai/instructor-js focus on data validation and retry mechanisms, enhancing the reliability of data processing workflows.
partial-json-parser-js
Partial JSON Parser is a lightweight and customizable library for parsing partial JSON strings. It allows users to parse incomplete JSON data and stream it to the user. The library provides options to specify what types of partialness are allowed during parsing, such as strings, objects, arrays, special values, and more. It helps handle malformed JSON and returns the parsed JavaScript value. Partial JSON Parser is implemented purely in JavaScript and offers both commonjs and esm builds.

draive
draive is an open-source Python library designed to simplify and accelerate the development of LLM-based applications. It offers abstract building blocks for connecting functionalities with large language models, flexible integration with various AI solutions, and a user-friendly framework for building scalable data processing pipelines. The library follows a function-oriented design, allowing users to represent complex programs as simple functions. It also provides tools for measuring and debugging functionalities, ensuring type safety and efficient asynchronous operations for modern Python apps.
partialjson
PartialJson is a Python library that allows users to parse partial and incomplete JSON data with ease. With just 3 lines of Python code, users can parse JSON data that may be missing key elements or contain errors. The library provides a simple solution for handling JSON data that may not be well-formed or complete, making it a valuable tool for data processing and manipulation tasks.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.
token.js
Token.js is a TypeScript SDK that integrates with over 200 LLMs from 10 providers using OpenAI's format. It allows users to call LLMs, supports tools, JSON outputs, image inputs, and streaming, all running on the client side without the need for a proxy server. The tool is free and open source under the MIT license.
web-ai-demos
Collection of client-side AI demos showcasing various AI applications using Chrome's built-in AI, Transformers.js, and Google's Gemma model through MediaPipe. Demos include weather description generation, summarization API, performance tips, utility functions, sentiment analysis, toxicity assessment, and streaming content using Server Sent Events.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.