
multipack_sampler
Multipack distributed sampler for fast padding-free training of LLMs
Stars: 162
The Multipack sampler is a tool designed for padding-free distributed training of large language models. It optimizes batch processing efficiency using an approximate solution to the identical machine scheduling problem. The V2 update further enhances the packing algorithm complexity, achieving better throughput for a large number of nodes. It includes two variants for models with different attention types, aiming to balance sequence lengths and optimize packing efficiency. Users can refer to the provided benchmark for evaluating efficiency, utilization, and L^2 lag. The tool is compatible with PyTorch DataLoader and is released under the MIT license.
README:
The Multipack sampler is designed for padding-free distributed training of large language models. It utilizes an approximate solution to the identical machine scheduling problem to maximize the efficiency of batch processing. On the OpenChat V1 training set, it achieves >99% theoretical efficiency, while the interleaved sampler only achieves ~75%.
Multipack V2 optimized the packing algorithm complexity from O(n k log n) down to O(n log k log n) without degrading the packing efficiency, achieving better throughput for a large number of nodes.
The V2 release also has two variants with different packing optimization objective:
-
MultipackDistributedBatchSampler: Designed for models with quadratic attention. It will try to optimize packing efficiency as well as balance long/short sequences between each nodes, to minimize the difference of quadratic load. -
MultipackDistributedBatchSampler_LinearAttention: For models with linear attention. Only consider packing efficiency and performs better on it than Quadratic variant, however this algorithm tends to put all long sequences into one node.
Please refer to test_multipack.ipynb
-
Efficiency: Percentage of actual batch size to max batch size
=
number of tokens per batch / max capacity of tokens per batch -
Utilization: all nodes waiting for the slowest node
=
number of tokens per batch / max number of tokens on a single node * node count
L^2 lag: sqrt(max over node(sum length^2) - min over node(sum length^2))
OpenChat V1 (testdata.json)
Sampler Multipack QuadraticAttention:
Batch count for ranks: [37, 37, 37, 37, 37, 37, 37, 37]
Packing Time: 20ms
L^2 lag avg: 438 max: 717
Efficiency: 98.16%
Utilization: 99.70%
==========
Sampler Multipack LinearAttention:
Batch count for ranks: [36, 36, 36, 36, 36, 36, 36, 36]
Packing Time: 18ms
L^2 lag avg: 6500 max: 6761
Efficiency: 99.64%
Utilization: 99.64%
==========
Sampler Interleaved:
Batch count for ranks: [48, 48, 48, 48, 48, 48, 48, 48]
Packing Time: 0ms
L^2 lag avg: 1914 max: 2000
Efficiency: 75.67%
Utilization: 96.79%
==========
Compatible with PyTorch DataLoader
batch_max_len = 16 * 2048 # batch size * max context length
lengths = np.array([len(tokens) for tokens in data])
sampler = MultipackDistributedBatchSampler(
batch_max_length=batch_max_len,
lengths=lengths,
seed=0
)
dataloader = DataLoader(data, batch_sampler=sampler)MIT
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for multipack_sampler
Similar Open Source Tools
multipack_sampler
The Multipack sampler is a tool designed for padding-free distributed training of large language models. It optimizes batch processing efficiency using an approximate solution to the identical machine scheduling problem. The V2 update further enhances the packing algorithm complexity, achieving better throughput for a large number of nodes. It includes two variants for models with different attention types, aiming to balance sequence lengths and optimize packing efficiency. Users can refer to the provided benchmark for evaluating efficiency, utilization, and L^2 lag. The tool is compatible with PyTorch DataLoader and is released under the MIT license.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.

zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.

WordLlama
WordLlama is a fast, lightweight NLP toolkit optimized for CPU hardware. It recycles components from large language models to create efficient word representations. It offers features like Matryoshka Representations, low resource requirements, binarization, and numpy-only inference. The tool is suitable for tasks like semantic matching, fuzzy deduplication, ranking, and clustering, making it a good option for NLP-lite tasks and exploratory analysis.

litdata
LitData is a tool designed for blazingly fast, distributed streaming of training data from any cloud storage. It allows users to transform and optimize data in cloud storage environments efficiently and intuitively, supporting various data types like images, text, video, audio, geo-spatial, and multimodal data. LitData integrates smoothly with frameworks such as LitGPT and PyTorch, enabling seamless streaming of data to multiple machines. Key features include multi-GPU/multi-node support, easy data mixing, pause & resume functionality, support for profiling, memory footprint reduction, cache size configuration, and on-prem optimizations. The tool also provides benchmarks for measuring streaming speed and conversion efficiency, along with runnable templates for different data types. LitData enables infinite cloud data processing by utilizing the Lightning.ai platform to scale data processing with optimized machines.
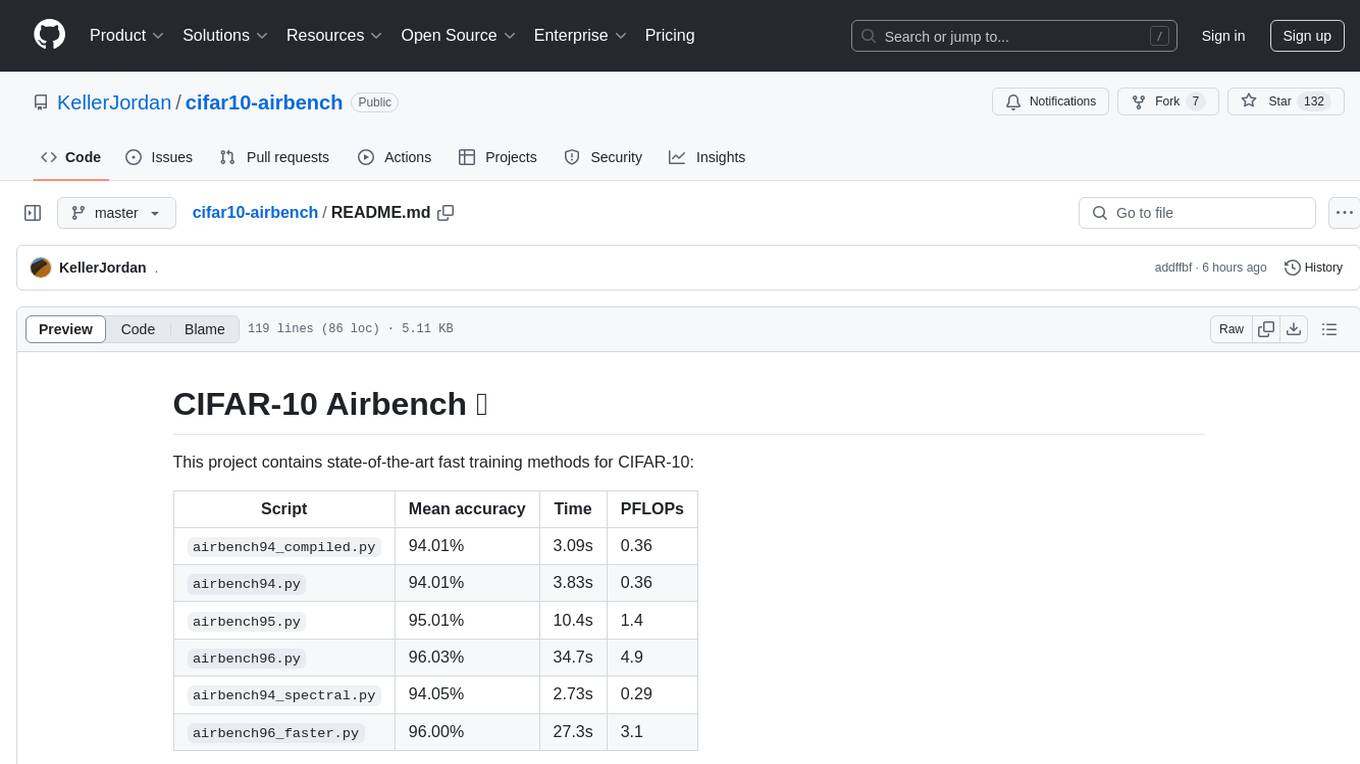
cifar10-airbench
CIFAR-10 Airbench is a project offering fast and stable training baselines for CIFAR-10 dataset, facilitating machine learning research. It provides easily runnable PyTorch scripts for training neural networks with high accuracy levels. The methods used in this project aim to accelerate research on fundamental properties of deep learning. The project includes GPU-accelerated dataloader for custom experiments and trainings, and can be used for data selection and active learning experiments. The training methods provided are faster than standard ResNet training, offering improved performance for research projects.
KIVI
KIVI is a plug-and-play 2bit KV cache quantization algorithm optimizing memory usage by quantizing key cache per-channel and value cache per-token to 2bit. It enables LLMs to maintain quality while reducing memory usage, allowing larger batch sizes and increasing throughput in real LLM inference workloads.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.

siftrank
siftrank is an implementation of the Sift Rank document ranking algorithm that uses Large Language Models (LLMs) to efficiently find the most relevant items in any dataset based on a given prompt. It addresses issues like non-determinism, limited context, output constraints, and scoring subjectivity encountered when using LLMs directly. siftrank allows users to rank anything without fine-tuning or domain-specific models, running in seconds and costing pennies. It supports JSON input, Go template syntax for customization, and various advanced options for configuration and optimization.

RTL-Coder
RTL-Coder is a tool designed to outperform GPT-3.5 in RTL code generation by providing a fully open-source dataset and a lightweight solution. It targets Verilog code generation and offers an automated flow to generate a large labeled dataset with over 27,000 diverse Verilog design problems and answers. The tool addresses the data availability challenge in IC design-related tasks and can be used for various applications beyond LLMs. The tool includes four RTL code generation models available on the HuggingFace platform, each with specific features and performance characteristics. Additionally, RTL-Coder introduces a new LLM training scheme based on code quality feedback to further enhance model performance and reduce GPU memory consumption.
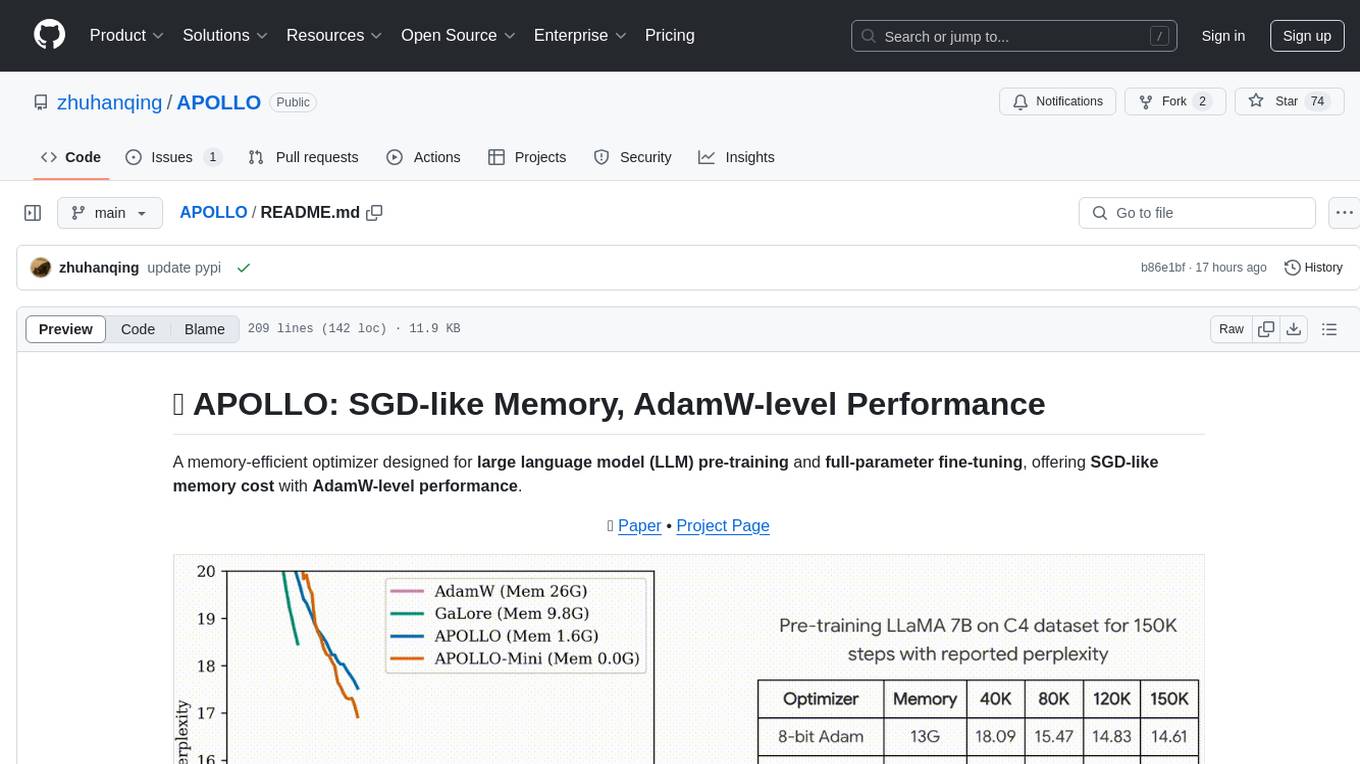
APOLLO
APOLLO is a memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning. It offers SGD-like memory cost with AdamW-level performance. The optimizer integrates low-rank approximation and optimizer state redundancy reduction to achieve significant memory savings while maintaining or surpassing the performance of Adam(W). Key contributions include structured learning rate updates for LLM training, approximated channel-wise gradient scaling in a low-rank auxiliary space, and minimal-rank tensor-wise gradient scaling. APOLLO aims to optimize memory efficiency during training large language models.

PDEBench
PDEBench provides a diverse and comprehensive set of benchmarks for scientific machine learning, including challenging and realistic physical problems. The repository consists of code for generating datasets, uploading and downloading datasets, training and evaluating machine learning models as baselines. It features a wide range of PDEs, realistic and difficult problems, ready-to-use datasets with various conditions and parameters. PDEBench aims for extensibility and invites participation from the SciML community to improve and extend the benchmark.
Eco2AI
Eco2AI is a python library for CO2 emission tracking that monitors energy consumption of CPU & GPU devices and estimates equivalent carbon emissions based on regional emission coefficients. Users can easily integrate Eco2AI into their Python scripts by adding a few lines of code. The library records emissions data and device information in a local file, providing detailed session logs with project names, experiment descriptions, start times, durations, power consumption, CO2 emissions, CPU and GPU names, operating systems, and countries.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.
For similar tasks
multipack_sampler
The Multipack sampler is a tool designed for padding-free distributed training of large language models. It optimizes batch processing efficiency using an approximate solution to the identical machine scheduling problem. The V2 update further enhances the packing algorithm complexity, achieving better throughput for a large number of nodes. It includes two variants for models with different attention types, aiming to balance sequence lengths and optimize packing efficiency. Users can refer to the provided benchmark for evaluating efficiency, utilization, and L^2 lag. The tool is compatible with PyTorch DataLoader and is released under the MIT license.

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.