
ezlocalai
ezlocalai is an easy to set up local artificial intelligence server with OpenAI Style Endpoints.
Stars: 67
ezlocalai is an artificial intelligence server that simplifies running multimodal AI models locally. It handles model downloading and server configuration based on hardware specs. It offers OpenAI Style endpoints for integration, voice cloning, text-to-speech, voice-to-text, and offline image generation. Users can modify environment variables for customization. Supports NVIDIA GPU and CPU setups. Provides demo UI and workflow visualization for easy usage.
README:
ezlocalai is an easy set up artificial intelligence server that allows you to easily run multimodal artificial intelligence from your computer. It is designed to be as easy as possible to get started with running local models. It automatically handles downloading the model of your choice and configuring the server based on your CPU, RAM, and GPU specifications. It also includes OpenAI Style endpoints for easy integration with other applications using ezlocalai as an OpenAI API proxy with any model. Additional functionality is built in for voice cloning text to speech and a voice to text for easy voice communication as well as image generation entirely offline after the initial setup.
- Git
- Docker Desktop (Windows or Mac)
- CUDA Toolkit (NVIDIA GPU only)
Additional Linux Prerequisites
- Docker
- Docker Compose
- NVIDIA Container Toolkit (NVIDIA GPU only)
git clone https://github.com/DevXT-LLC/ezlocalai
cd ezlocalaiExpand Environment Setup if you would like to modify the default environment variables, otherwise skip to Usage. All environment variables are optional and have useful defaults. Change the default model that starts with ezlocalai in your .env file.
Environment Setup (Optional)
None of the values need modified in order to run the server. If you are using an NVIDIA GPU, I would recommend setting the GPU_LAYERS and MAIN_GPU environment variables. If you plan to expose the server to the internet, I would recommend setting the EZLOCALAI_API_KEY environment variable for security. THREADS is set to your CPU thread count minus 2 by default, if this causes significant performance issues, consider setting the THREADS environment variable manually to a lower number.
Modify the .env file to your desired settings. Assumptions will be made on all of these values if you choose to accept the defaults.
Replace the environment variables with your desired settings. Assumptions will be made on all of these values if you choose to accept the defaults.
-
EZLOCALAI_URL- The URL to use for the server. Default ishttp://localhost:8091. -
EZLOCALAI_API_KEY- The API key to use for the server. If not set, the server will not require an API key when accepting requests. -
NGROK_TOKEN- The ngrok token to use for the server. If not set, ngrok will not be used. Using ngrok will allow you to expose your ezlocalai server to the public with as simple as an API key. Get your free NGROK_TOKEN here. -
DEFAULT_MODEL- The default model to use when no model is specified. Use the Hugging Face path. Default isTheBloke/phi-2-dpo-GGUF. -
LLM_MAX_TOKENS- The maximum number of tokens to use for the language model. If set to0, it will automatically use the max tokens for the model. Default is0. -
WHISPER_MODEL- The model to use for speech-to-text. Default isbase.en. -
AUTO_UPDATE- Whether or not to automatically update ezlocalai. Default istrue. -
THREADS- The number of CPU threads ezlocalai is allowed to use. Default is 4. -
GPU_LAYERS(Only applicable to NVIDIA GPU) - The number of layers to use on the GPU. Default is0. YourGPU_LAYERSwill automatically determine a number of layers to use based on your GPU's memory if it is set to-1and you have an NVIDIA GPU. If it is set to-2, it will use the maximum number of layers requested by the model. -
MAIN_GPU(Only applicable to NVIDIA GPU) - The GPU to use for the language model. Default is0. -
IMG_ENABLED- If set to true, models will choose to generate images when they want to based on the user input. This is only available on GPU. Default isfalse. -
SD_MODEL- The stable diffusion model to use. Default isstabilityai/sdxl-turbo. -
VISION_MODEL- The vision model to use. Default is None. Current options aredeepseek-ai/deepseek-vl-1.3b-chatanddeepseek-ai/deepseek-vl-7b-chat.
docker-compose -f docker-compose-cuda.yml down
docker-compose -f docker-compose-cuda.yml build
docker-compose -f docker-compose-cuda.yml updocker-compose down
docker-compose build
docker-compose upOpenAI Style endpoints available at http://<YOUR LOCAL IP ADDRESS>:8091/v1/ by default. Documentation can be accessed at that http://localhost:8091 when the server is running.
For examples on how to use the server to communicate with the models, see the Examples Jupyter Notebook once the server is running. We also have an example to use in Google Colab.
You can access the basic demo UI at http://localhost:8502, or your local IP address with port 8502.
graph TD
A[app.py] --> B[FASTAPI]
B --> C[Pipes]
C --> D[LLM]
C --> E[STT]
C --> F[CTTS]
C --> G[IMG]
D --> H[llama_cpp]
D --> I[tiktoken]
D --> J[torch]
E --> K[faster_whisper]
E --> L[pyaudio]
E --> M[webrtcvad]
E --> N[pydub]
F --> O[TTS]
F --> P[torchaudio]
G --> Q[diffusers]
Q --> J
A --> R[Uvicorn]
R --> S[ASGI Server]
A --> T[API Endpoint: /v1/completions]
T --> U[Pipes.get_response]
U --> V{completion_type}
V -->|completion| W[LLM.completion]
V -->|chat| X[LLM.chat]
X --> Y[LLM.generate]
W --> Y
Y --> Z[LLM.create_completion]
Z --> AA[Return response]
AA --> AB{stream}
AB -->|True| AC[StreamingResponse]
AB -->|False| AD[JSON response]
U --> AE[Audio transcription]
AE --> AF{audio_format}
AF -->|Exists| AG[Transcribe audio]
AG --> E
AF -->|None| AH[Skip transcription]
U --> AI[Audio generation]
AI --> AJ{voice}
AJ -->|Exists| AK[Generate audio]
AK --> F
AK --> AL{stream}
AL -->|True| AM[StreamingResponse]
AL -->|False| AN[JSON response with audio URL]
AJ -->|None| AO[Skip audio generation]
U --> AP[Image generation]
AP --> AQ{IMG enabled}
AQ -->|True| AR[Generate image]
AR --> G
AR --> AS[Append image URL to response]
AQ -->|False| AT[Skip image generation]
A --> AU[API Endpoint: /v1/chat/completions]
AU --> U
A --> AV[API Endpoint: /v1/embeddings]
AV --> AW[LLM.embedding]
AW --> AX[LLM.create_embedding]
AX --> AY[Return embedding]
A --> AZ[API Endpoint: /v1/audio/transcriptions]
AZ --> BA[STT.transcribe_audio]
BA --> BB[Return transcription]
A --> BC[API Endpoint: /v1/audio/generation]
BC --> BD[CTTS.generate]
BD --> BE[Return audio URL or base64 audio]
A --> BF[API Endpoint: /v1/models]
BF --> BG[LLM.models]
BG --> BH[Return available models]
A --> BI[CORS Middleware]
BJ[.env] --> BK[Environment Variables]
BK --> A
BL[setup.py] --> BM[ezlocalai package]
BM --> BN[LLM]
BM --> BO[STT]
BM --> BP[CTTS]
BM --> BQ[IMG]
A --> BR[API Key Verification]
BR --> BS[verify_api_key]
A --> BT[Static Files]
BT --> BU[API Endpoint: /outputs]
A --> BV[Ngrok]
BV --> BW[Public URL]For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ezlocalai
Similar Open Source Tools
ezlocalai
ezlocalai is an artificial intelligence server that simplifies running multimodal AI models locally. It handles model downloading and server configuration based on hardware specs. It offers OpenAI Style endpoints for integration, voice cloning, text-to-speech, voice-to-text, and offline image generation. Users can modify environment variables for customization. Supports NVIDIA GPU and CPU setups. Provides demo UI and workflow visualization for easy usage.
screen-pipe
Screen-pipe is a Rust + WASM tool that allows users to turn their screen into actions using Large Language Models (LLMs). It enables users to record their screen 24/7, extract text from frames, and process text and images for tasks like analyzing sales conversations. The tool is still experimental and aims to simplify the process of recording screens, extracting text, and integrating with various APIs for tasks such as filling CRM data based on screen activities. The project is open-source and welcomes contributions to enhance its functionalities and usability.

agenticSeek
AgenticSeek is a voice-enabled AI assistant powered by DeepSeek R1 agents, offering a fully local alternative to cloud-based AI services. It allows users to interact with their filesystem, code in multiple languages, and perform various tasks autonomously. The tool is equipped with memory to remember user preferences and past conversations, and it can divide tasks among multiple agents for efficient execution. AgenticSeek prioritizes privacy by running entirely on the user's hardware without sending data to the cloud.
gpt-cli
gpt-cli is a command-line interface tool for interacting with various chat language models like ChatGPT, Claude, and others. It supports model customization, usage tracking, keyboard shortcuts, multi-line input, markdown support, predefined messages, and multiple assistants. Users can easily switch between different assistants, define custom assistants, and configure model parameters and API keys in a YAML file for easy customization and management.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.

Gemini-API
Gemini-API is a reverse-engineered asynchronous Python wrapper for Google Gemini web app (formerly Bard). It provides features like persistent cookies, ImageFx support, extension support, classified outputs, official flavor, and asynchronous operation. The tool allows users to generate contents from text or images, have conversations across multiple turns, retrieve images in response, generate images with ImageFx, save images to local files, use Gemini extensions, check and switch reply candidates, and control log level.

chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
lollms_legacy
Lord of Large Language Models (LoLLMs) Server is a text generation server based on large language models. It provides a Flask-based API for generating text using various pre-trained language models. This server is designed to be easy to install and use, allowing developers to integrate powerful text generation capabilities into their applications. The tool supports multiple personalities for generating text with different styles and tones, real-time text generation with WebSocket-based communication, RESTful API for listing personalities and adding new personalities, easy integration with various applications and frameworks, sending files to personalities, running on multiple nodes to provide a generation service to many outputs at once, and keeping data local even in the remote version.

termax
Termax is an LLM agent in your terminal that converts natural language to commands. It is featured by: - Personalized Experience: Optimize the command generation with RAG. - Various LLMs Support: OpenAI GPT, Anthropic Claude, Google Gemini, Mistral AI, and more. - Shell Extensions: Plugin with popular shells like `zsh`, `bash` and `fish`. - Cross Platform: Able to run on Windows, macOS, and Linux.
AirspeedVelocity.jl
AirspeedVelocity.jl is a tool designed to simplify benchmarking of Julia packages over their lifetime. It provides a CLI to generate benchmarks, compare commits/tags/branches, plot benchmarks, and run benchmark comparisons for every submitted PR as a GitHub action. The tool freezes the benchmark script at a specific revision to prevent old history from affecting benchmarks. Users can configure options using CLI flags and visualize benchmark results. AirspeedVelocity.jl can be used to benchmark any Julia package and offers features like generating tables and plots of benchmark results. It also supports custom benchmarks and can be integrated into GitHub actions for automated benchmarking of PRs.
Upscaler
Holloway's Upscaler is a consolidation of various compiled open-source AI image/video upscaling products for a CLI-friendly image and video upscaling program. It provides low-cost AI upscaling software that can run locally on a laptop, programmable for albums and videos, reliable for large video files, and works without GUI overheads. The repository supports hardware testing on various systems and provides important notes on GPU compatibility, video types, and image decoding bugs. Dependencies include ffmpeg and ffprobe for video processing. The user manual covers installation, setup pathing, calling for help, upscaling images and videos, and contributing back to the project. Benchmarks are provided for performance evaluation on different hardware setups.

magic-cli
Magic CLI is a command line utility that leverages Large Language Models (LLMs) to enhance command line efficiency. It is inspired by projects like Amazon Q and GitHub Copilot for CLI. The tool allows users to suggest commands, search across command history, and generate commands for specific tasks using local or remote LLM providers. Magic CLI also provides configuration options for LLM selection and response generation. The project is still in early development, so users should expect breaking changes and bugs.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.
APIMyLlama
APIMyLlama is a server application that provides an interface to interact with the Ollama API, a powerful AI tool to run LLMs. It allows users to easily distribute API keys to create amazing things. The tool offers commands to generate, list, remove, add, change, activate, deactivate, and manage API keys, as well as functionalities to work with webhooks, set rate limits, and get detailed information about API keys. Users can install APIMyLlama packages with NPM, PIP, Jitpack Repo+Gradle or Maven, or from the Crates Repository. The tool supports Node.JS, Python, Java, and Rust for generating responses from the API. Additionally, it provides built-in health checking commands for monitoring API health status.
fish-ai
fish-ai is a tool that adds AI functionality to Fish shell. It can be integrated with various AI providers like OpenAI, Azure OpenAI, Google, Hugging Face, Mistral, or a self-hosted LLM. Users can transform comments into commands, autocomplete commands, and suggest fixes. The tool allows customization through configuration files and supports switching between contexts. Data privacy is maintained by redacting sensitive information before submission to the AI models. Development features include debug logging, testing, and creating releases.
For similar tasks
ezlocalai
ezlocalai is an artificial intelligence server that simplifies running multimodal AI models locally. It handles model downloading and server configuration based on hardware specs. It offers OpenAI Style endpoints for integration, voice cloning, text-to-speech, voice-to-text, and offline image generation. Users can modify environment variables for customization. Supports NVIDIA GPU and CPU setups. Provides demo UI and workflow visualization for easy usage.
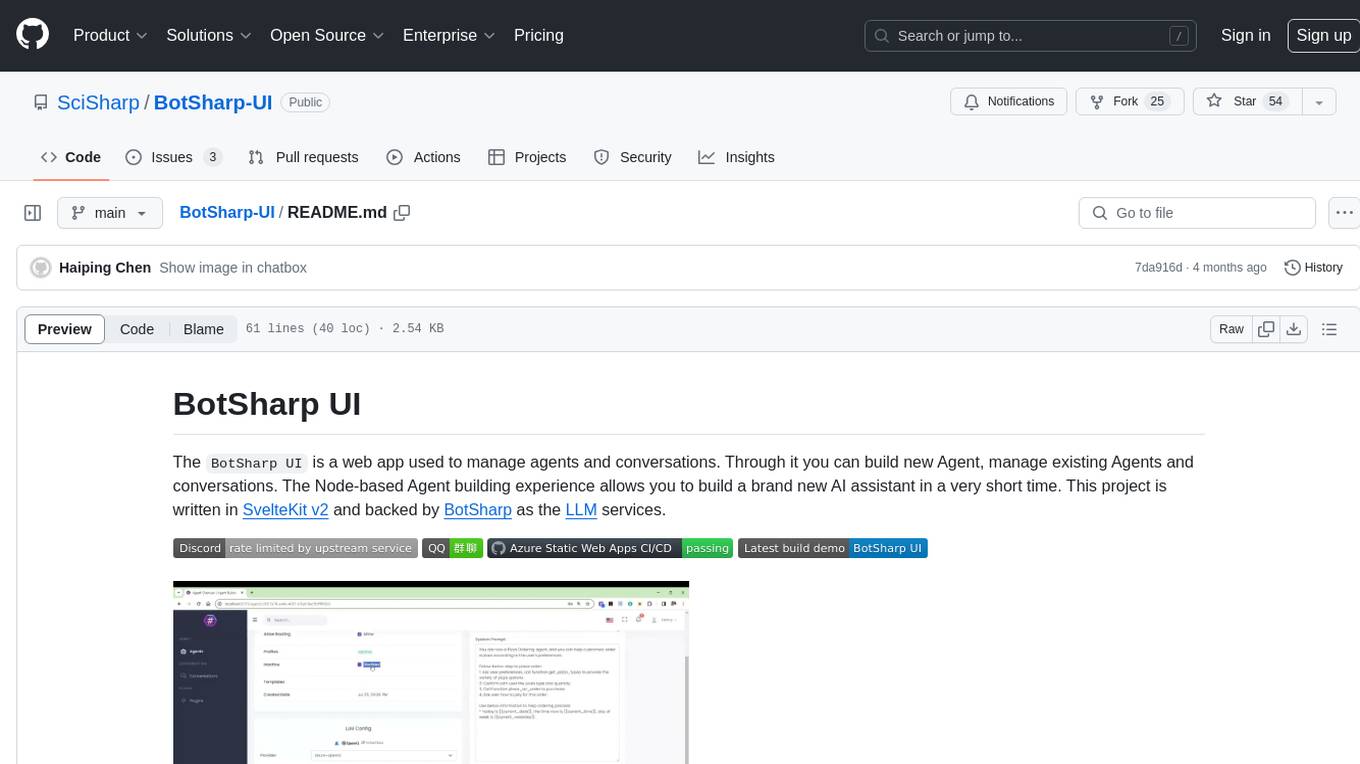
BotSharp-UI
BotSharp UI is a web app for managing agents and conversations. It allows users to build new AI assistants quickly using a Node-based Agent building experience. The project is written in SvelteKit v2 and utilizes BotSharp as the LLM services.
stable-diffusion-webui
Stable Diffusion WebUI Docker Image allows users to run Automatic1111 WebUI in a docker container locally or in the cloud. The images do not bundle models or third-party configurations, requiring users to use a provisioning script for container configuration. It supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with additional environment variables for customization and pre-configured templates for Vast.ai and Runpod.io. The service is password protected by default, with options for version pinning, startup flags, and service management using supervisorctl.
ai-accelerator
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.
CVPR2024-Papers-with-Code-Demo
This repository contains a collection of papers and code for the CVPR 2024 conference. The papers cover a wide range of topics in computer vision, including object detection, image segmentation, image generation, and video analysis. The code provides implementations of the algorithms described in the papers, making it easy for researchers and practitioners to reproduce the results and build upon the work of others. The repository is maintained by a team of researchers at the University of California, Berkeley.
ms-copilot-play
Microsoft Copilot Play is a Cloudflare Worker service that accelerates Microsoft Copilot functionalities in China. It allows high-speed access to Microsoft Copilot features like chatting, notebook, plugins, image generation, and sharing. The service filters out meaningless requests used for statistics, saving up to 80% of Cloudflare Worker requests. Users can deploy the service easily with Cloudflare Worker, ensuring fast and unlimited access with no additional operations. The service leverages the power of Microsoft Copilot, based on OpenAI GPT-4, and utilizes Bing search to answer questions.

oh-my-pi
oh-my-pi is an AI coding agent for the terminal, providing tools for interactive coding, AI-powered git commits, Python code execution, LSP integration, time-traveling streamed rules, interactive code review, task management, interactive questioning, custom TypeScript slash commands, universal config discovery, MCP & plugin system, web search & fetch, SSH tool, Cursor provider integration, multi-credential support, image generation, TUI overhaul, edit fuzzy matching, and more. It offers a modern terminal interface with smart session management, supports multiple AI providers, and includes various tools for coding, task management, code review, and interactive questioning.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.