
expo-stable-diffusion
Run Stable Diffusion using Core ML on iOS within your Expo & React Native App
Stars: 187
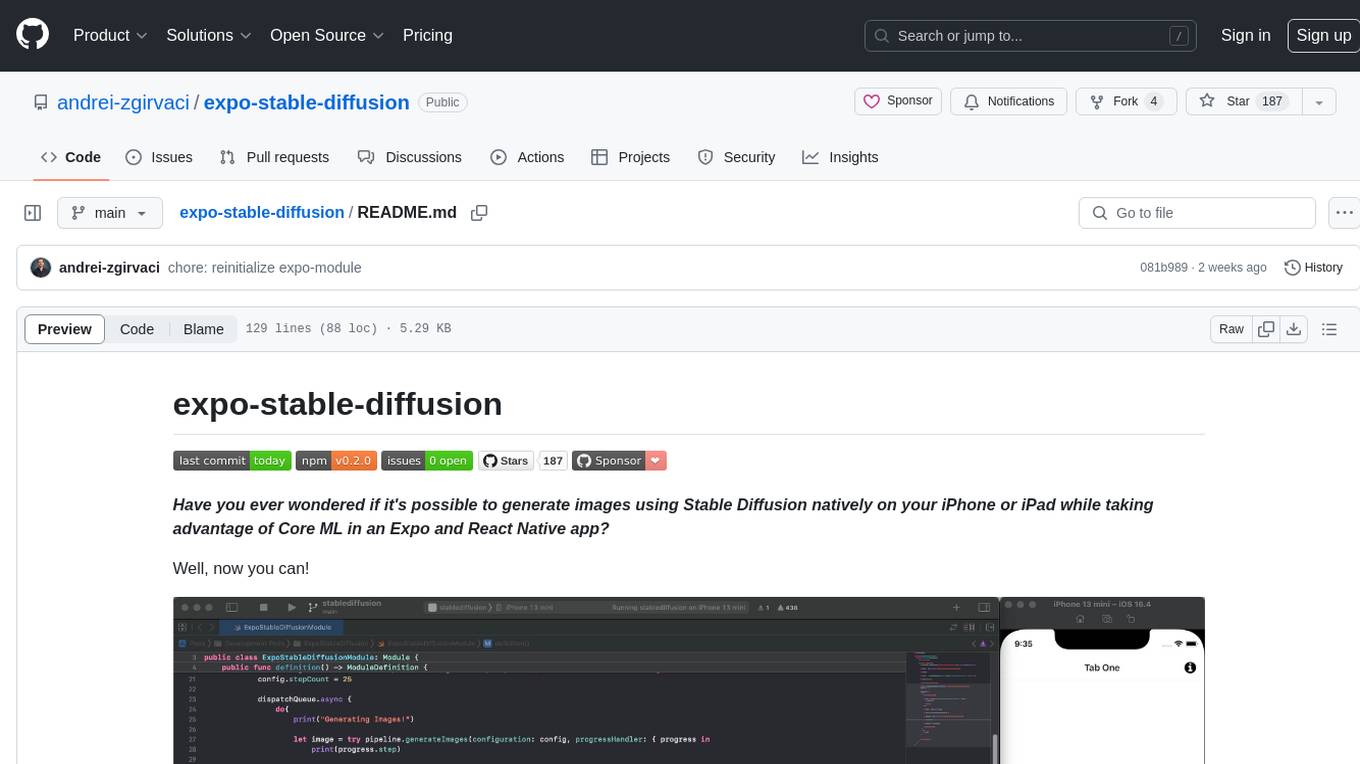
The `expo-stable-diffusion` repository provides a tool for generating images using Stable Diffusion natively on iOS devices within Expo and React Native apps. Users can install and configure the module to create images based on prompts. The repository includes information on updating iOS deployment targets, enabling increased memory limits, and building iOS apps. Additionally, users can obtain Stable Diffusion models from various sources. The repository also addresses troubleshooting tips related to model load times and image generation durations. The developer seeks sponsorship to further enhance the project, including adding Android support.
README:





Have you ever wondered if it's possible to generate images using Stable Diffusion natively on your iPhone or iPad while taking advantage of Core ML in an Expo and React Native app?
Well, now you can!

❗️
expo-stable-diffusioncurrently only works on iOS due to the platform's ability to run Stable Diffusion models on Apple Neural Engine!
❗️ This package is not included in the Expo Go. You will have to use a Development Build or build it locally using Xcode!
Start by installing the expo-stable-diffusion module into your Expo managed project:
npx expo install expo-stable-diffusionIn order for the project to build successfully, you have to set the iOS Deployment Target to 16.2. You can achieve this by installing the expo-build-properties plugin:
npx expo install expo-build-propertiesConfigure the plugin by adding the following to your app.json:
{
"expo": {
"plugins": [
[
"expo-build-properties",
{
"ios": {
"deploymentTarget": "16.2"
}
}
]
]
}
}To prevent memory issues, add the Increased Memory Limit capability to your iOS project. Add the following to your app.json:
{
"expo": {
"ios": {
"entitlements": {
"com.apple.developer.kernel.increased-memory-limit": true
}
}
}
}npx expo prebuild --clean --platform ios
npx expo run:iosAfter installation and configuration, you can start generating images using expo-stable-diffusion. Here's a basic example:
import * as FileSystem from 'expo-file-system';
import * as ExpoStableDiffusion from 'expo-stable-diffusion';
const MODEL_PATH = FileSystem.documentDirectory + 'Model/stable-diffusion-2-1';
const SAVE_PATH = FileSystem.documentDirectory + 'image.jpeg';
await ExpoStableDiffusion.loadModel(MODEL_PATH);
const subscription = ExpoStableDiffusion.addStepListener(({ step }) => {
console.log(`Current Step: ${step}`);
});
await ExpoStableDiffusion.generateImage({
prompt: 'a cat coding at night',
stepCount: 25,
savePath: SAVE_PATH,
});
subscription.remove();💡 If you are saving the image in a custom directory, make sure the directory exists. You can create a directory by calling the
FileSystem.makeDirectoryAsync(fileUri, options)function fromexpo-file-system.
To use the expo-stable-diffusion module, you need a converted Core ML Stable Diffusion model. You can convert your own model using Apple's official guide or download pre-converted models from Apple's Hugging Face repository or my Hugging Face repository.
❗️ The model load time and image generation duration take some time, especially on devices with lower RAM than 6GB! Find more information in Q6 in the FAQ section of the ml-stable-diffusion repo.
I am looking for at least $1,000 in sponsorship so that I can go full-time into building this project.
Currently, I dedicate my spare time to the development of this library. Please consider supporting this project if you find expo-stable-diffusion helpful or if you are using it in a production-ready app. This will motivate me to work on improving it and adding new features like Android support!
In case you need premium guidance on integrating expo-stable-diffusion into your own project, bugfixes or any other help, feel free to contact me. I will be happy to help!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for expo-stable-diffusion
Similar Open Source Tools
expo-stable-diffusion
The `expo-stable-diffusion` repository provides a tool for generating images using Stable Diffusion natively on iOS devices within Expo and React Native apps. Users can install and configure the module to create images based on prompts. The repository includes information on updating iOS deployment targets, enabling increased memory limits, and building iOS apps. Additionally, users can obtain Stable Diffusion models from various sources. The repository also addresses troubleshooting tips related to model load times and image generation durations. The developer seeks sponsorship to further enhance the project, including adding Android support.
react-native-executorch
React Native ExecuTorch is a framework that allows developers to run AI models on mobile devices using React Native. It bridges the gap between React Native and native platform capabilities, providing high-performance AI model execution without requiring deep knowledge of native code or machine learning internals. The tool supports ready-made models in `.pte` format and offers a Python API for custom models. It is designed to simplify the integration of AI features into React Native apps.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.

oasis
OASIS is a scalable, open-source social media simulator that integrates large language models with rule-based agents to realistically mimic the behavior of up to one million users on platforms like Twitter and Reddit. It facilitates the study of complex social phenomena such as information spread, group polarization, and herd behavior, offering a versatile tool for exploring diverse social dynamics and user interactions in digital environments. With features like scalability, dynamic environments, diverse action spaces, and integrated recommendation systems, OASIS provides a comprehensive platform for simulating social media interactions at a large scale.

kaito
KAITO is an operator that automates the AI/ML model inference or tuning workload in a Kubernetes cluster. It manages large model files using container images, provides preset configurations to avoid adjusting workload parameters based on GPU hardware, supports popular open-sourced inference runtimes, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry. Using KAITO simplifies the workflow of onboarding large AI inference models in Kubernetes.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.

supallm
Supallm is a Python library for super resolution of images using deep learning techniques. It provides pre-trained models for enhancing image quality by increasing resolution. The library is easy to use and allows users to upscale images with high fidelity and detail. Supallm is suitable for tasks such as enhancing image quality, improving visual appearance, and increasing the resolution of low-quality images. It is a valuable tool for researchers, photographers, graphic designers, and anyone looking to enhance image quality using AI technology.
doc-comments-ai
doc-comments-ai is a tool designed to automatically generate code documentation using language models. It allows users to easily create documentation comment blocks for methods in various programming languages such as Python, Typescript, Javascript, Java, Rust, and more. The tool supports both OpenAI and local LLMs, ensuring data privacy and security. Users can generate documentation comments for methods in files, inline comments in method bodies, and choose from different models like GPT-3.5-Turbo, GPT-4, and Azure OpenAI. Additionally, the tool provides support for Treesitter integration and offers guidance on selecting the appropriate model for comprehensive documentation needs.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.

llm-foundry
LLM Foundry is a codebase for training, finetuning, evaluating, and deploying LLMs for inference with Composer and the MosaicML platform. It is designed to be easy-to-use, efficient _and_ flexible, enabling rapid experimentation with the latest techniques. You'll find in this repo: * `llmfoundry/` - source code for models, datasets, callbacks, utilities, etc. * `scripts/` - scripts to run LLM workloads * `data_prep/` - convert text data from original sources to StreamingDataset format * `train/` - train or finetune HuggingFace and MPT models from 125M - 70B parameters * `train/benchmarking` - profile training throughput and MFU * `inference/` - convert models to HuggingFace or ONNX format, and generate responses * `inference/benchmarking` - profile inference latency and throughput * `eval/` - evaluate LLMs on academic (or custom) in-context-learning tasks * `mcli/` - launch any of these workloads using MCLI and the MosaicML platform * `TUTORIAL.md` - a deeper dive into the repo, example workflows, and FAQs
cover-agent
CodiumAI Cover Agent is a tool designed to help increase code coverage by automatically generating qualified tests to enhance existing test suites. It utilizes Generative AI to streamline development workflows and is part of a suite of utilities aimed at automating the creation of unit tests for software projects. The system includes components like Test Runner, Coverage Parser, Prompt Builder, and AI Caller to simplify and expedite the testing process, ensuring high-quality software development. Cover Agent can be run via a terminal and is planned to be integrated into popular CI platforms. The tool outputs debug files locally, such as generated_prompt.md, run.log, and test_results.html, providing detailed information on generated tests and their status. It supports multiple LLMs and allows users to specify the model to use for test generation.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
ollama-r
The Ollama R library provides an easy way to integrate R with Ollama for running language models locally on your machine. It supports working with standard data structures for different LLMs, offers various output formats, and enables integration with other libraries/tools. The library uses the Ollama REST API and requires the Ollama app to be installed, with GPU support for accelerating LLM inference. It is inspired by Ollama Python and JavaScript libraries, making it familiar for users of those languages. The installation process involves downloading the Ollama app, installing the 'ollamar' package, and starting the local server. Example usage includes testing connection, downloading models, generating responses, and listing available models.
For similar tasks
expo-stable-diffusion
The `expo-stable-diffusion` repository provides a tool for generating images using Stable Diffusion natively on iOS devices within Expo and React Native apps. Users can install and configure the module to create images based on prompts. The repository includes information on updating iOS deployment targets, enabling increased memory limits, and building iOS apps. Additionally, users can obtain Stable Diffusion models from various sources. The repository also addresses troubleshooting tips related to model load times and image generation durations. The developer seeks sponsorship to further enhance the project, including adding Android support.
DeepBattler
DeepBattler is a tool designed for Hearthstone Battlegrounds players, providing real-time strategic advice and insights to improve gameplay experience. It integrates with the Hearthstone Deck Tracker plugin and offers voice-assisted guidance. The tool is powered by a large language model (LLM) and can match the strength of top players on EU servers. Users can set up the tool by adding dependencies, configuring the plugin path, and launching the LLM agent. DeepBattler is licensed for personal, educational, and non-commercial use, with guidelines on non-commercial distribution and acknowledgment of external contributions.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
For similar jobs
stable-diffusion-prompt-reader
A simple standalone viewer for reading prompt from Stable Diffusion generated image outside the webui. The tool supports macOS, Windows, and Linux, providing both GUI and CLI functionalities. Users can interact with the tool through drag and drop, copy prompt to clipboard, remove prompt from image, export prompt to text file, edit or import prompt to images, and more. It supports multiple formats including PNG, JPEG, WEBP, TXT, and various tools like A1111's webUI, Easy Diffusion, StableSwarmUI, Fooocus-MRE, NovelAI, InvokeAI, ComfyUI, Draw Things, and Naifu(4chan). Users can download the tool for different platforms and install it via Homebrew Cask or pip. The tool can be used to read, export, remove, and edit prompts from images, providing various modes and options for different tasks.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.
expo-stable-diffusion
The `expo-stable-diffusion` repository provides a tool for generating images using Stable Diffusion natively on iOS devices within Expo and React Native apps. Users can install and configure the module to create images based on prompts. The repository includes information on updating iOS deployment targets, enabling increased memory limits, and building iOS apps. Additionally, users can obtain Stable Diffusion models from various sources. The repository also addresses troubleshooting tips related to model load times and image generation durations. The developer seeks sponsorship to further enhance the project, including adding Android support.
SUPIR
SUPIR is an AI-based image processing and upscaling tool that leverages cutting-edge technology to enhance image quality and resolution. The tool provides users with the ability to upscale images with high generalization and quality, as well as specific settings for light degradation scenarios. It offers a range of models and checkpoints for different use cases, along with detailed instructions for installation and usage. SUPIR also includes features for color fixing, linear CFG adjustments, and various prompts for image enhancement. The tool is designed for non-commercial use only and comes with a contact email for inquiries and permission requests for commercial use.
FluxAIGridComparisons
FluxAIGridComparisons is a repository containing a collection of different image grids generated using Flux. These grids showcase various attributes such as hairstyles, clothing, nationalities, and ages. The repository serves as a visual comparison tool for exploring different characteristics within images.

gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.
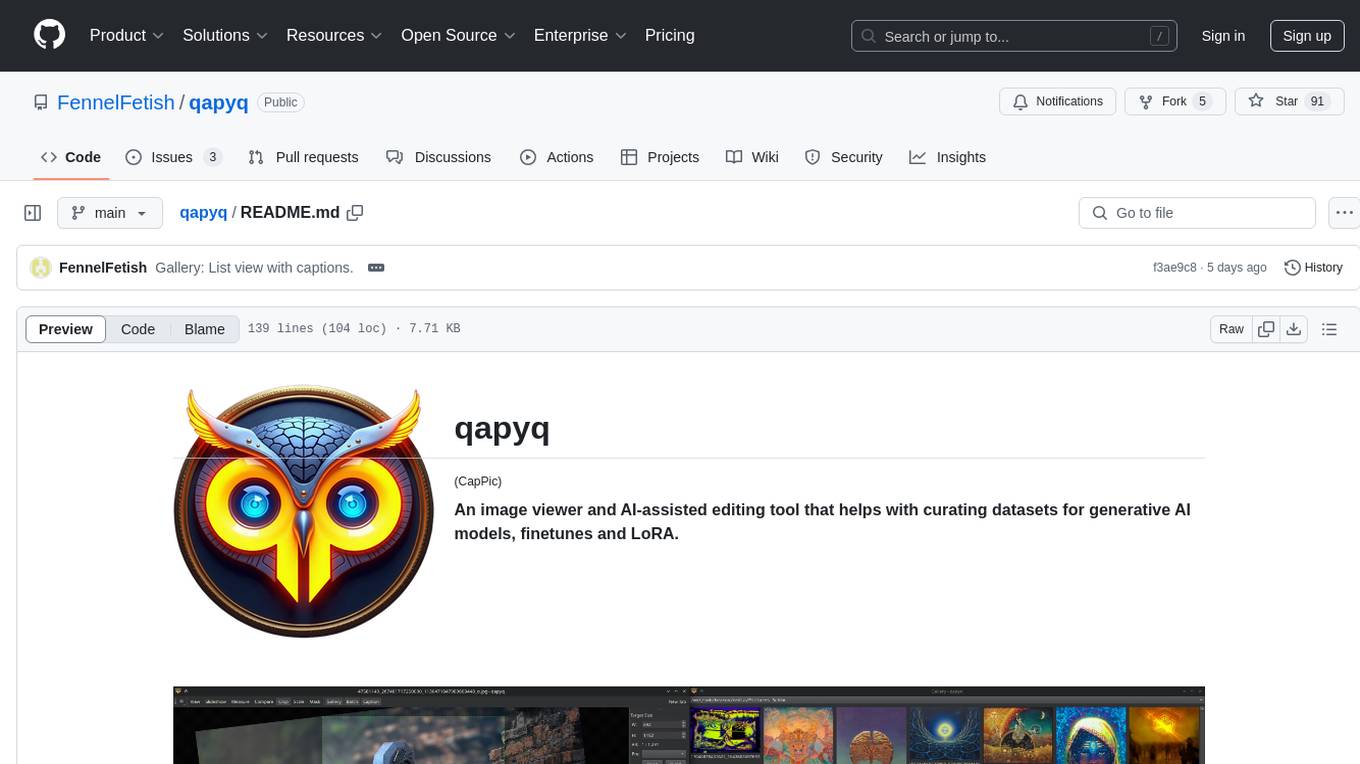
qapyq
qapyq is an image viewer and AI-assisted editing tool designed to help curate datasets for generative AI models. It offers features such as image viewing, editing, captioning, batch processing, and AI assistance. Users can perform tasks like cropping, scaling, editing masks, tagging, and applying sorting and filtering rules. The tool supports state-of-the-art captioning and masking models, with options for model settings, GPU acceleration, and quantization. qapyq aims to streamline the process of preparing images for training AI models by providing a user-friendly interface and advanced functionalities.