
tangent
Excalidraw meets ComfyUI for LLMs
Stars: 234
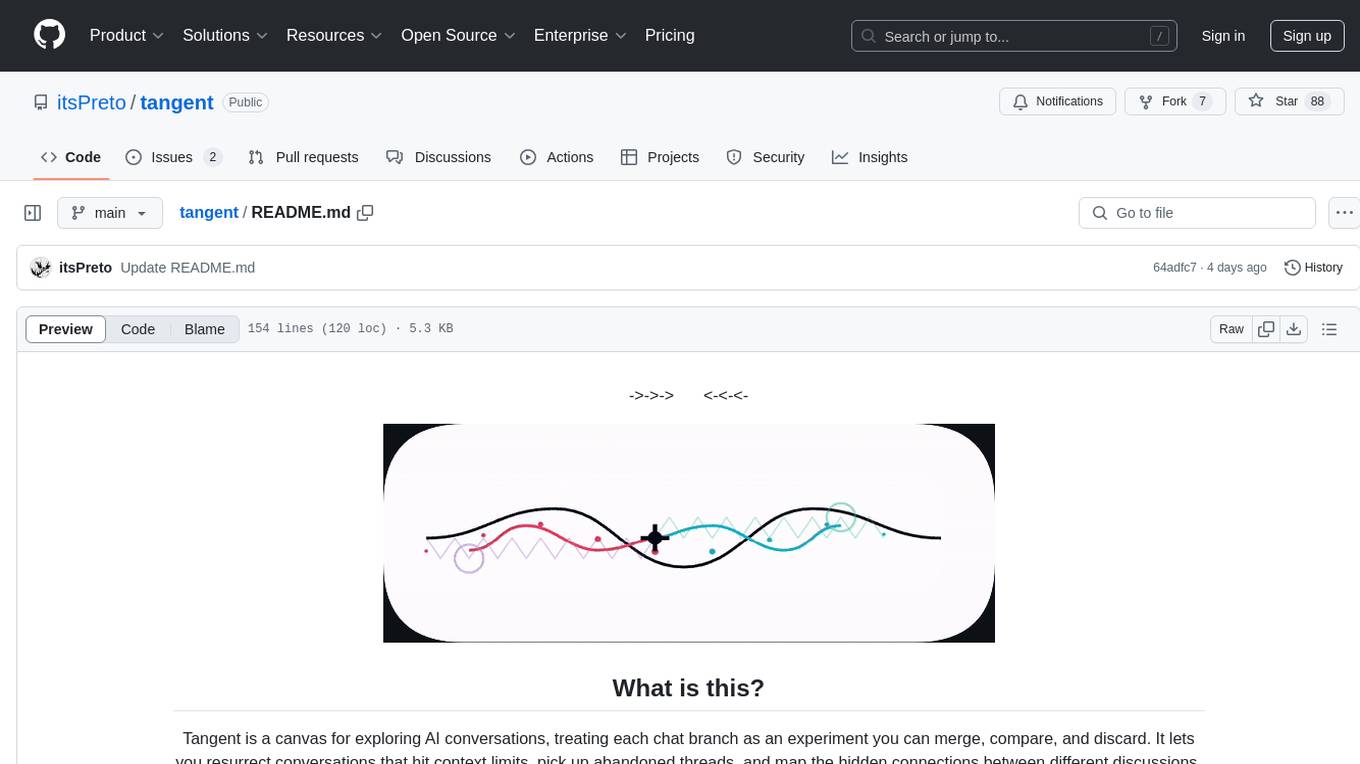
Tangent is a canvas for exploring AI conversations, allowing users to resurrect and continue conversations, branch and explore different ideas, organize conversations by topics, and support archive data exports. It aims to provide a visual/textual/audio exploration experience with AI assistants, offering a 'thoughts workbench' for experimenting freely, reviving old threads, and diving into tangents. The project structure includes a modular backend with components for API routes, background task management, data processing, and more. Prerequisites for setup include Whisper.cpp, Ollama, and exported archive data from Claude or ChatGPT. Users can initialize the environment, install Python packages, set up Ollama, configure local models, and start the backend and frontend to interact with the tool.
README:
Tangent is a canvas for exploring AI conversations, treating each chat branch as an experiment you can merge, compare, and discard. It lets you resurrect conversations that hit context limits, pick up abandoned threads, and map the hidden connections between different discussions.
- 🌟 Resurrect & Continue: Seamlessly resume conversations after reaching a prior context limit.
- 🌿 Branch & Explore: Effortlessly create conversation forks at any point to test multiple approaches or ideas.
- 💻 Offline-First: Fully powered by local models, leveraging Ollama with plans to expand support.
- 📂 Topic Clustering: Dynamically organize and filter conversations by their inferred topics, streamlining navigation.
- 📜 Archive Support: Comprehensive compatibility with Claude and ChatGPT data exports, with additional integrations in development.
https://github.com/user-attachments/assets/69fac816-ebec-4506-af33-2d31bbe9419e
The backend is organized into a clean, modular structure:
tangent-api
├── src
│ ├── app.py # Entry point of the application
│ ├── config.py # Configuration settings
│ ├── models.py # Data models and structures
│ ├── tasks.py # Background task management
│ ├── utils.py # Utility functions
│ ├── routes # API route definitions
│ │ ├── __init__.py
│ │ ├── api.py # Main API routes
│ │ ├── chats.py # Chat-related routes
│ │ ├── messages.py # Message retrieval routes
│ │ ├── states.py # State management routes
│ │ └── topics.py # Topic-related routes
│ └── services # Service layer for background processing and data handling
│ ├── __init__.py
│ ├── background_processor.py # Background processing tasks
│ ├── clustering.py # Clustering operations
│ ├── data_processing.py # Data processing functions
│ ├── embedding.py # Embedding functions
│ ├── reflection.py # Reflection generation functions
│ └── topic_generation.py # Topic generation functions
├── requirements.txt # Project dependencies
└── README.md # Project documentation
-
Whisper.cpp (
git clone https://github.com/ggerganov/whisper.cpp->cd whisper.cpp->sh ./models/download-ggml-model.sh base.en->make->./build/bin/whisper-server) - Ollama (project was kinda hardcoded for ollama but can be generalized to accept diff backends)
- Exported Archive Data (from Claude or ChatGPT)
# Clone the repository
git clone https://github.com/itsPreto/tangent.git
cd tangent
# Make the install script executable and run it
chmod +x install.sh
./install.shThe script will:
- Check for and start required services (Ollama)
- Optionally install Whisper.cpp for voice features
- Set up the Python environment and dependencies
- Install and start the frontend
- Set up default models (all-minilm for embeddings, qwen2.5 for generation)
For manual setup or troubleshooting, see the instructions below.
Initialize a new venv (mac):
cd tangent-api
source my_env/bin/activateInstall Python packages:
pip install -r requirements.txtInstall Ollama
find the appropriate image for your system here: https://ollama.com/
Verify installation
ollama --version
ollama version is 0.4.4Download models (embedding + llm)
if you choose to swap these pls see the
Configure local modelssection below
ollama pull all-minilm
ollama pull qwen2.5-coder:7bStart Ollama (download if u don't already have it)
ollama serveConfigure local models:
cd src
export EMBEDDING_MODEL="custom-embedding-model"
export GENERATION_MODEL="custom-generation-model"Then run with:
python3 app.pyOr all together:
python3 app.py --embedding-model "custom-embedding-model" --generation-model "custom-generation-model"The backend will start up at http://localhost:5001/api.
cd simplified-ui
npm i
npm startif you get any missing pckg error just manually install it and restart the UI
The backend exposes these main endpoints:
-
/api/process: Send your chat data for processing -
/api/process/status/<task_id>: Check how your processing is going -
/api/chats/save: Save chat data -
/api/chats/load/<chat_id>: Load up specific chats -
/api/topics: Get all the generated topics
Feel free to contribute! Just submit a PR or open an issue for any cool features or fixes you've got in mind.
Licensed under Apache 2.0 - see the LICENSE file for the full details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for tangent
Similar Open Source Tools
tangent
Tangent is a canvas for exploring AI conversations, allowing users to resurrect and continue conversations, branch and explore different ideas, organize conversations by topics, and support archive data exports. It aims to provide a visual/textual/audio exploration experience with AI assistants, offering a 'thoughts workbench' for experimenting freely, reviving old threads, and diving into tangents. The project structure includes a modular backend with components for API routes, background task management, data processing, and more. Prerequisites for setup include Whisper.cpp, Ollama, and exported archive data from Claude or ChatGPT. Users can initialize the environment, install Python packages, set up Ollama, configure local models, and start the backend and frontend to interact with the tool.
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
cookiecutter-data-science
Cookiecutter Data Science (CCDS) is a tool for setting up a data science project template that incorporates best practices. It provides a logical, reasonably standardized but flexible project structure for doing and sharing data science work. The tool helps users to easily start new data science projects with a well-organized directory structure, including folders for data, models, notebooks, reports, and more. By following the project template created by CCDS, users can streamline their data science workflow and ensure consistency across projects.
mmwave-gesture-recognition
This repository provides a setup for basic gesture recognition using the TI AWR1642 mmWave sensor. Users can collect data from the sensor and choose from various neural network architectures for gesture recognition. The supported gestures include Swipe Up, Swipe Down, Swipe Right, Swipe Left, Spin Clockwise, Spin Counterclockwise, Letter Z, Letter S, and Letter X. The repository includes data and models for training and inference, along with instructions for installation, serial permissions setup, flashing firmware, running the system, collecting data, training models, selecting different models, and accessing help documentation. The project is developed using Python and TensorFlow 2.15.
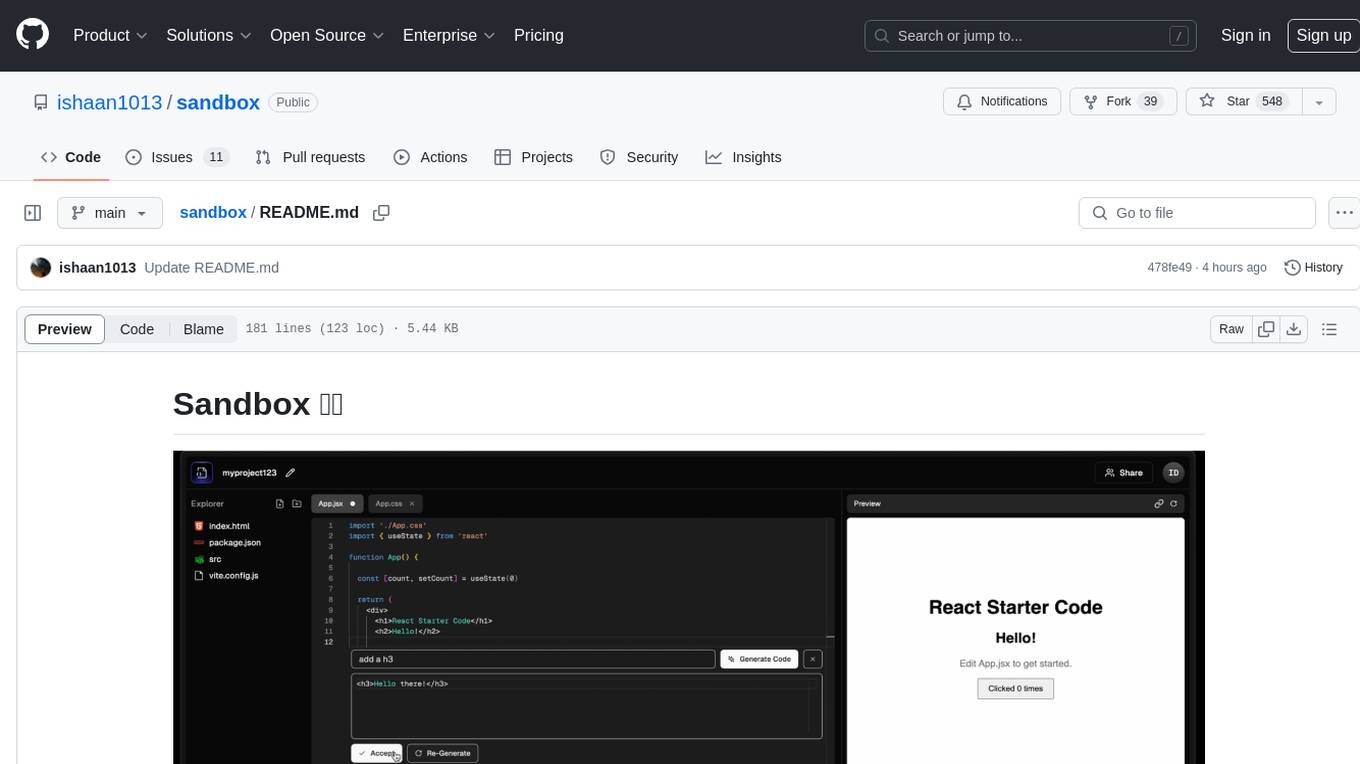
sandbox
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
nodejs-todo-api-boilerplate
An LLM-powered code generation tool that relies on the built-in Node.js API Typescript Template Project to easily generate clean, well-structured CRUD module code from text description. It orchestrates 3 LLM micro-agents (`Developer`, `Troubleshooter` and `TestsFixer`) to generate code, fix compilation errors, and ensure passing E2E tests. The process includes module code generation, DB migration creation, seeding data, and running tests to validate output. By cycling through these steps, it guarantees consistent and production-ready CRUD code aligned with vertical slicing architecture.
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.
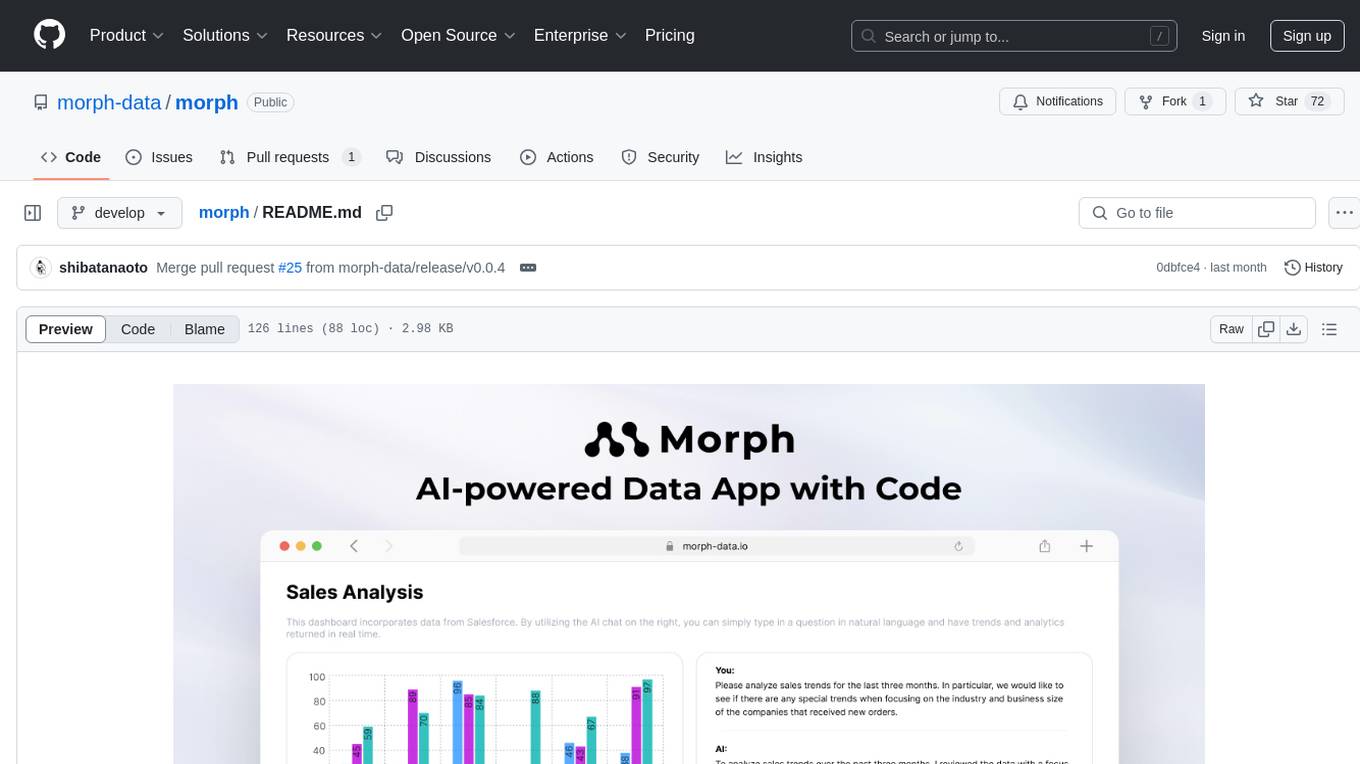
morph
Morph is a python-centric full-stack framework for building and deploying data apps. It is fast to start, deploy and operate, requires no HTML/CSS knowledge, and is customizable with Python and SQL for advanced data workflows. With Markdown-based syntax and pre-made components, users can create visually appealing designs without writing HTML or CSS.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.

trieve
Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.
middleware
Middleware is an open-source engineering management tool that helps engineering leaders measure and analyze team effectiveness using DORA metrics. It integrates with CI/CD tools, automates DORA metric collection and analysis, visualizes key performance indicators, provides customizable reports and dashboards, and integrates with project management platforms. Users can set up Middleware using Docker or manually, generate encryption keys, set up backend and web servers, and access the application to view DORA metrics. The tool calculates DORA metrics using GitHub data, including Deployment Frequency, Lead Time for Changes, Mean Time to Restore, and Change Failure Rate. Middleware aims to provide DORA metrics to users based on their Git data, simplifying the process of tracking software delivery performance and operational efficiency.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.
langstream
LangStream is a tool for natural language processing tasks, providing a CLI for easy installation and usage. Users can try sample applications like Chat Completions and create their own applications using the developer documentation. It supports running on Kubernetes for production-ready deployment, with support for various Kubernetes distributions and external components like Apache Kafka or Apache Pulsar cluster. Users can deploy LangStream locally using minikube and manage the cluster with mini-langstream. Development requirements include Docker, Java 17, Git, Python 3.11+, and PIP, with the option to test local code changes using mini-langstream.
snipkit
SnipKit is a CLI tool designed to manage snippets efficiently, allowing users to execute saved scripts or generate new ones with the help of AI directly from the terminal. It supports loading snippets from various sources, parameter substitution, different parameter types, themes, and customization options. The tool includes an interactive chat-style interface called SnipKit Assistant for generating parameterized scripts. Users can also work with different AI providers like OpenAI, Anthropic, Google Gemini, and more. SnipKit aims to streamline script execution and script generation workflows for developers and users who frequently work with code snippets.
AirCasting
AirCasting is a platform for gathering, visualizing, and sharing environmental data. It aims to provide a central hub for environmental data, making it easier for people to access and use this information to make informed decisions about their environment.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.
For similar tasks
tangent
Tangent is a canvas for exploring AI conversations, allowing users to resurrect and continue conversations, branch and explore different ideas, organize conversations by topics, and support archive data exports. It aims to provide a visual/textual/audio exploration experience with AI assistants, offering a 'thoughts workbench' for experimenting freely, reviving old threads, and diving into tangents. The project structure includes a modular backend with components for API routes, background task management, data processing, and more. Prerequisites for setup include Whisper.cpp, Ollama, and exported archive data from Claude or ChatGPT. Users can initialize the environment, install Python packages, set up Ollama, configure local models, and start the backend and frontend to interact with the tool.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.