
UltraSinger
AI based tool to convert vocals lyrics and pitch from music to autogenerate Ultrastar Deluxe, Midi and notes. It automatic tapping, adding text, pitch vocals and creates karaoke files.
Stars: 305
UltraSinger is a tool under development that automatically creates UltraStar.txt, midi, and notes from music. It pitches UltraStar files, adds text and tapping, creates separate UltraStar karaoke files, re-pitches current UltraStar files, and calculates in-game score. It uses multiple AI models to extract text from voice and determine pitch. Users should mention UltraSinger in UltraStar.txt files and only use it on Creative Commons licensed songs.
README:



![]()
![]()
![]()
⚠️ This project is still under development!
UltraSinger is a tool to automatically create UltraStar.txt, midi and notes from music. It automatically pitches UltraStar files, adding text and tapping to UltraStar files and creates separate UltraStar karaoke files. It also can re-pitch current UltraStar files and calculates the possible in-game score.
Multiple AI models are used to extract text from the voice and to determine the pitch.
Please mention UltraSinger in your UltraStar.txt file if you use it. It helps others find this tool, and it helps this tool get improved and maintained. You should only use it on Creative Commons licensed songs.
There are many ways to support this project. Starring ⭐️ the repo is just one 🙏
You can also support this work on GitHub sponsors or Patreon or Buy Me a Coffee.
This will help me a lot to keep this project alive and improve it.



- Install Python 3.10 (older and newer versions has some breaking changes). Download
- Also install ffmpeg separately with PATH. Download
- Go to folder
installand run install script for your OS.- Choose
GPUif you have an nvidia CUDA GPU. - Choose
CPUif you don't have an nvidia CUDA GPU.
- Choose
- In root folder just run
run_on_windows.batorrun_on_linux.shto start the app. - Now you can use the UltraSinger source code with
py UltraSinger.py [opt] [mode] [transcription] [pitcher] [extra]. See How to use for more information.
Not all options working now!
UltraSinger.py [opt] [mode] [transcription] [pitcher] [extra]
[opt]
-h This help text.
-i Ultrastar.txt
audio like .mp3, .wav, youtube link
-o Output folder
[mode]
## if INPUT is audio ##
default Creates all
# Single file creation selection is in progress, you currently getting all!
(-u Create ultrastar txt file) # In Progress
(-m Create midi file) # In Progress
(-s Create sheet file) # In Progress
## if INPUT is ultrastar.txt ##
default Creates all
[separation]
# Default is htdemucs
--demucs Model name htdemucs|htdemucs_ft|htdemucs_6s|hdemucs_mmi|mdx|mdx_extra|mdx_q|mdx_extra_q >> ((default) is htdemucs)
[transcription]
# Default is whisper
--whisper Multilingual model > tiny|base|small|medium|large-v1|large-v2|large-v3 >> ((default) is large-v2)
English-only model > tiny.en|base.en|small.en|medium.en
--whisper_align_model Use other languages model for Whisper provided from huggingface.co
--language Override the language detected by whisper, does not affect transcription but steps after transcription
--whisper_batch_size Reduce if low on GPU mem >> ((default) is 16)
--whisper_compute_type Change to "int8" if low on GPU mem (may reduce accuracy) >> ((default) is "float16" for cuda devices, "int8" for cpu)
--keep_numbers Numbers will be transcribed as numerics instead of as words
[pitcher]
# Default is crepe
--crepe tiny|full >> ((default) is full)
--crepe_step_size unit is miliseconds >> ((default) is 10)
[extra]
--disable_hyphenation Disable word hyphenation. Hyphenation is enabled by default.
--disable_separation Disable track separation. Track separation is enabled by default.
--disable_karaoke Disable creation of karaoke style txt file. Karaoke is enabled by default.
--create_audio_chunks Enable creation of audio chunks. Audio chunks are disabled by default.
--keep_cache Keep cache folder after creation. Cache folder is removed by default.
--plot Enable creation of plots. Plots are disabled by default.
--format_version 0.3.0|1.0.0|1.1.0|1.2.0 >> ((default) is 1.2.0)
--musescore_path path to MuseScore executable
--keep_numbers Transcribe numbers as digits and not words
[yt-dlp]
--cookiefile File name where cookies should be read from
[device]
--force_cpu Force all steps to be processed on CPU.
--force_whisper_cpu Only whisper will be forced to cpu
--force_crepe_cpu Only crepe will be forced to cpu
For standard use, you only need to use [opt]. All other options are optional.
-i "input/music.mp3"
-i https://www.youtube.com/watch?v=YwNs1Z0qRY0
Note that if you run into a yt-dlp error such as Sign in to confirm you’re not a bot. This helps protect our community (yt-dlp issue) you can follow these steps:
- generate a cookies.txt file with yt-dlp
yt-dlp --cookies cookies.txt --cookies-from-browser firefox - then pass the cookies.txt to UltraSinger
--cookiefile cookies.txt
This re-pitch the audio and creates a new txt file.
-i "input/ultrastar.txt"
Keep in mind that while a larger model is more accurate, it also takes longer to transcribe.
For the first test run, use the tiny, to be accurate use the large-v2 model.
-i XYZ --whisper large-v2
Currently provided default language models are en, fr, de, es, it, ja, zh, nl, uk, pt.
If the language is not in this list, you need to find a phoneme-based ASR model from
🤗 huggingface model hub. It will download automatically.
Example for romanian:
-i XYZ --whisper_align_model "gigant/romanian-wav2vec2"
Is on by default. Can also be deactivated if hyphenation does not produce anything useful. Note that the word is simply split, without paying attention to whether the separated word really starts at the place or is heard. To disable:
-i XYZ --disable_hyphenation
Pitching is done with the crepe model.
Also consider that a bigger model is more accurate, but also takes longer to pitch.
For just testing you should use tiny.
If you want solid accurate, then use the full model.
-i XYZ --crepe full
The vocals are separated from the audio before they are passed to the models. If problems occur with this, you have the option to disable this function; in which case the original audio file is used instead.
-i XYZ --disable_separation
For Sheet Music generation you need to have MuseScore installed on your system.
Or provide the path to the MuseScore executable.
-i XYZ --musescore_path "C:/Program Files/MuseScore 4/bin/MuseScore4.exe"
This defines the format version of the UltraStar.txt file. For more info see Official UltraStar format specification.
You can choose between different format versions. The default is 1.2.0.
-
0.3.0is the first format version. Use this if you have an old UltraStar program and problems with the newer format. -
1.0.0should be supported by the most UltraStar programs. Use this if you have problems with the newest format version -
1.1.0is the current format version. -
1.2.0is the upcoming format version. It is not finished yet. -
2.0.0is the next format version. It is not finished yet.
-i XYZ --format_version 1.2.0
The score that the singer in the audio would receive will be measured. You get 2 scores, simple and accurate. You wonder where the difference is? Ultrastar is not interested in pitch hights. As long as it is in the pitch range A-G you get one point. This makes sense for the game, because otherwise men don't get points for high female voices and women don't get points for low male voices. Accurate is the real tone specified in the txt. I had txt files where the pitch was in a range not singable by humans, but you could still reach the 10k points in the game. The accuracy is important here, because from this MIDI and sheet are created. And you also want to have accurate files
With a GPU you can speed up the process. Also the quality of the transcription and pitching is better.
You need a cuda device for this to work. Sorry, there is no cuda device for macOS.
It is optional (but recommended) to install the cuda driver for your gpu: see driver.
Install torch with cuda separately in your venv. See tourch+cuda.
Also check you GPU cuda support. See cuda support
Command for pip:
pip3 install torch==2.0.1+cu117 torchvision==0.15.2+cu117 torchaudio==2.0.2+cu117 --index-url https://download.pytorch.org/whl/cu117
When you want to use conda instead you need a different installation command.
The pitch tracker used by UltraSinger (crepe) uses TensorFlow as its backend. TensorFlow dropped GPU support for Windows for versions >2.10 as you can see in this release note and their installation instructions.
For now UltraSinger runs the latest version available that still supports GPUs on windows.
For running later versions of TensorFlow on windows while still taking advantage of GPU support the suggested solution is to run UltraSinger in a container.
If something crashes because of low VRAM then use a smaller model.
Whisper needs more than 8GB VRAM in the large model!
You can also force cpu usage with the extra option --force_cpu.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for UltraSinger
Similar Open Source Tools
UltraSinger
UltraSinger is a tool under development that automatically creates UltraStar.txt, midi, and notes from music. It pitches UltraStar files, adds text and tapping, creates separate UltraStar karaoke files, re-pitches current UltraStar files, and calculates in-game score. It uses multiple AI models to extract text from voice and determine pitch. Users should mention UltraSinger in UltraStar.txt files and only use it on Creative Commons licensed songs.
Upscaler
Holloway's Upscaler is a consolidation of various compiled open-source AI image/video upscaling products for a CLI-friendly image and video upscaling program. It provides low-cost AI upscaling software that can run locally on a laptop, programmable for albums and videos, reliable for large video files, and works without GUI overheads. The repository supports hardware testing on various systems and provides important notes on GPU compatibility, video types, and image decoding bugs. Dependencies include ffmpeg and ffprobe for video processing. The user manual covers installation, setup pathing, calling for help, upscaling images and videos, and contributing back to the project. Benchmarks are provided for performance evaluation on different hardware setups.
obs-cleanstream
CleanStream is an OBS plugin that utilizes AI to clean live audio streams by removing unwanted words and utterances, such as 'uh's and 'um's, and configurable words like profanity. It uses a neural network (OpenAI Whisper) in real-time to predict speech and eliminate unwanted words. The plugin is still experimental and not recommended for live production use, but it is functional for testing purposes. Users can adjust settings and configure the plugin to enhance audio quality during live streams.

obs-cleanstream
CleanStream is an OBS plugin that utilizes real-time local AI to clean live audio streams by removing unwanted words and utterances, such as 'uh' and 'um', and configurable words like profanity. It employs a neural network (OpenAI Whisper) to predict speech in real-time and eliminate undesired words. The plugin runs efficiently using the Whisper.cpp project from ggerganov. CleanStream offers users the ability to adjust settings and add the plugin to any audio-generating source in OBS, providing a seamless experience for content creators looking to enhance the quality of their live audio streams.

fabric
Fabric is an open-source framework for augmenting humans using AI. It provides a structured approach to breaking down problems into individual components and applying AI to them one at a time. Fabric includes a collection of pre-defined Patterns (prompts) that can be used for a variety of tasks, such as extracting the most interesting parts of YouTube videos and podcasts, writing essays, summarizing academic papers, creating AI art prompts, and more. Users can also create their own custom Patterns. Fabric is designed to be easy to use, with a command-line interface and a variety of helper apps. It is also extensible, allowing users to integrate it with their own AI applications and infrastructure.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
docker-h5ai
docker-h5ai is a Docker image that provides a modern file indexer for HTTP web servers, enhancing file browsing with different views, a breadcrumb, and a tree overview. It is built on Alpine Linux with Nginx and PHP, supporting h5ai 0.30.0 and enabling PHP 8 JIT compiler. The image supports multiple architectures and can be used to host shared files with customizable configurations. Users can set up authentication using htpasswd and run the image as a real-time service. It is recommended to use HTTPS for data encryption when deploying the service.
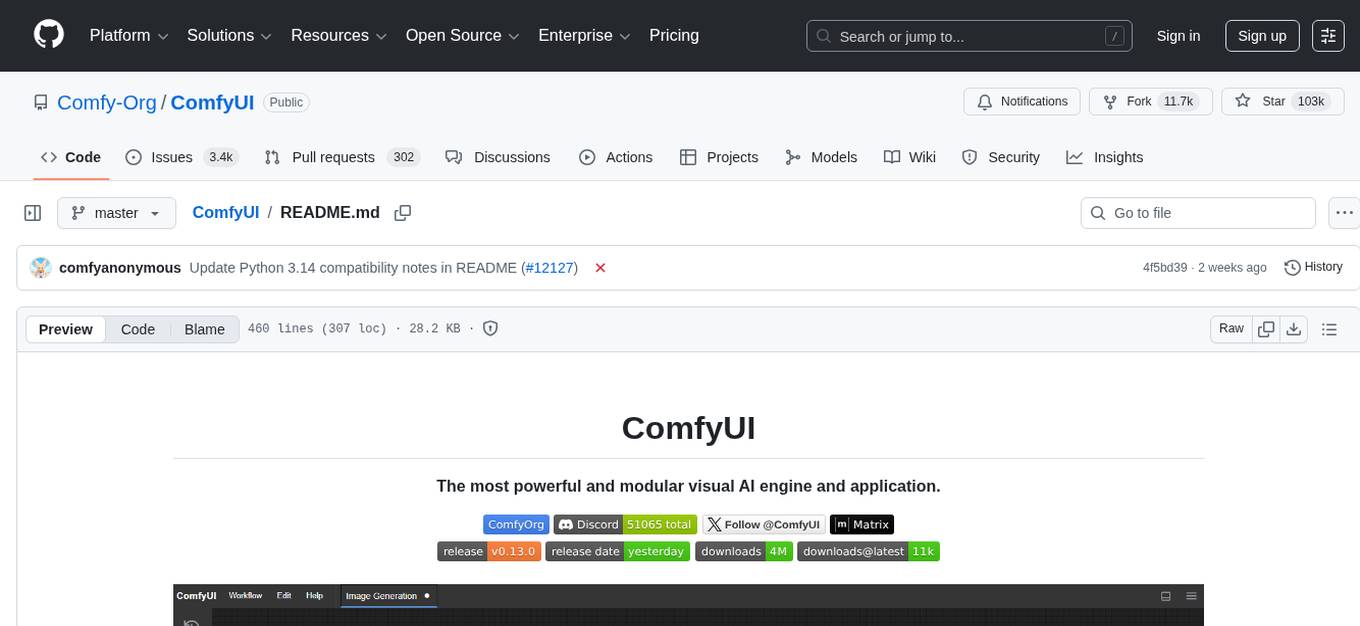
ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image, video, audio, and 3D processing, along with features like smart memory management, model loading, embeddings/textual inversion, and offline usage. Users can experiment with different models, create complex workflows, and optimize their processes efficiently.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.
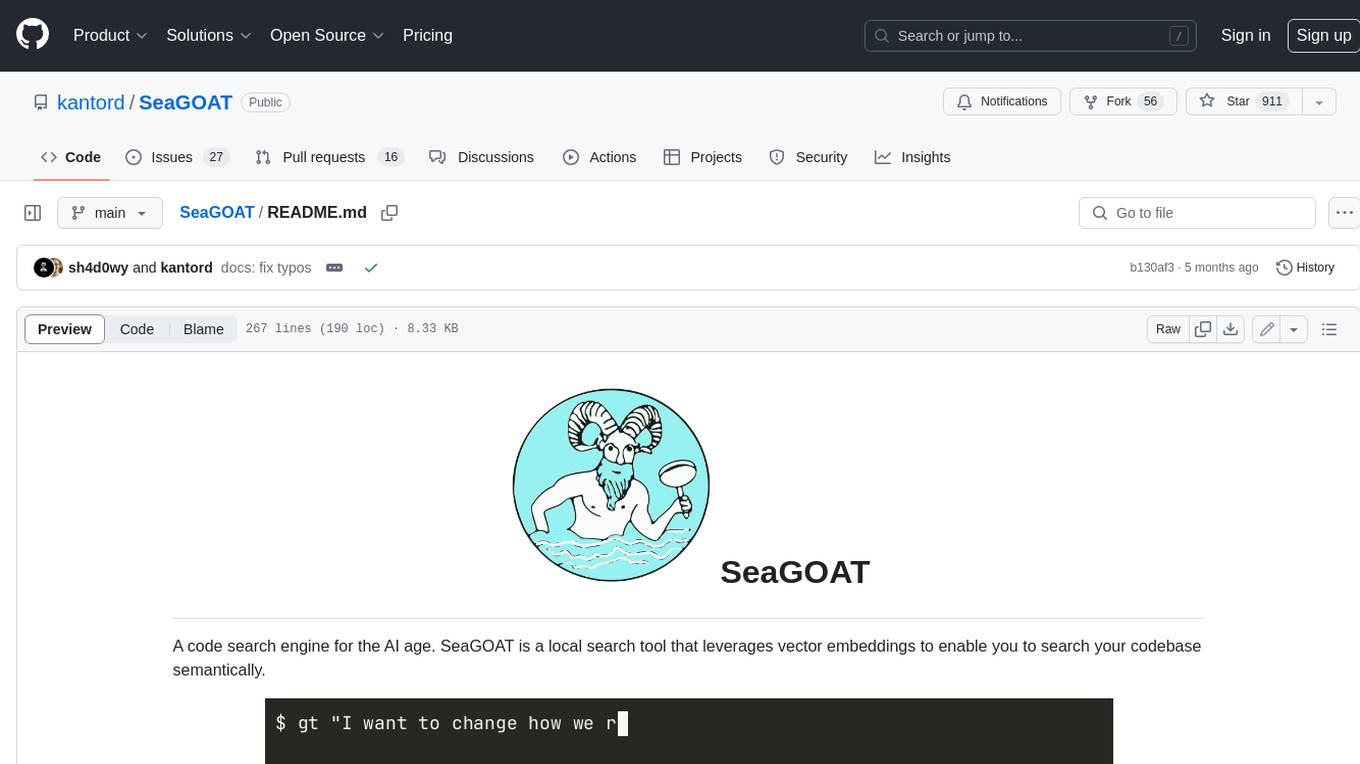
SeaGOAT
SeaGOAT is a local search tool that leverages vector embeddings to enable you to search your codebase semantically. It is designed to work on Linux, macOS, and Windows and can process files in various formats, including text, Markdown, Python, C, C++, TypeScript, JavaScript, HTML, Go, Java, PHP, and Ruby. SeaGOAT uses a vector database called ChromaDB and a local vector embedding engine to provide fast and accurate search results. It also supports regular expression/keyword-based matches. SeaGOAT is open-source and licensed under an open-source license, and users are welcome to examine the source code, raise concerns, or create pull requests to fix problems.
parllama
PAR LLAMA is a Text UI application for managing and using LLMs, designed with Textual and Rich and PAR AI Core. It runs on major OS's including Windows, Windows WSL, Mac, and Linux. Supports Dark and Light mode, custom themes, and various workflows like Ollama chat, image chat, and OpenAI provider chat. Offers features like custom prompts, themes, environment variables configuration, and remote instance connection. Suitable for managing and using LLMs efficiently.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.

MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.
SunoApi
SunoAPI is an unofficial client for Suno AI, built on Python and Streamlit. It supports functions like generating music and obtaining music information. Users can set up multiple account information to be saved for use. The tool also features built-in maintenance and activation functions for tokens, eliminating concerns about token expiration. It supports multiple languages and allows users to upload pictures for generating songs based on image content analysis.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.
browser
Lightpanda Browser is an open-source headless browser designed for fast web automation, AI agents, LLM training, scraping, and testing. It features ultra-low memory footprint, exceptionally fast execution, and compatibility with Playwright and Puppeteer through CDP. Built for performance, Lightpanda offers Javascript execution, support for Web APIs, and is optimized for minimal memory usage. It is a modern solution for web scraping and automation tasks, providing a lightweight alternative to traditional browsers like Chrome.
For similar tasks
UltraSinger
UltraSinger is a tool under development that automatically creates UltraStar.txt, midi, and notes from music. It pitches UltraStar files, adds text and tapping, creates separate UltraStar karaoke files, re-pitches current UltraStar files, and calculates in-game score. It uses multiple AI models to extract text from voice and determine pitch. Users should mention UltraSinger in UltraStar.txt files and only use it on Creative Commons licensed songs.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.