
ethereum-etl-airflow
Airflow DAGs for exporting, loading, and parsing the Ethereum blockchain data. How to get any Ethereum smart contract into BigQuery https://towardsdatascience.com/how-to-get-any-ethereum-smart-contract-into-bigquery-in-8-mins-bab5db1fdeee
Stars: 394
This repository contains Airflow DAGs for extracting, transforming, and loading (ETL) data from the Ethereum blockchain into BigQuery. The DAGs use the Google Cloud Platform (GCP) services, including BigQuery, Cloud Storage, and Cloud Composer, to automate the ETL process. The repository also includes scripts for setting up the GCP environment and running the DAGs locally.
README:
Read this article: https://cloud.google.com/blog/products/data-analytics/ethereum-bigquery-how-we-built-dataset
- direnv
- pyenv
We are using direnv to automatically set up and load the correct python version. We also create a venv in the root folder, that is automatically activated when entering the project folder.
- Sign in to BigQuery https://bigquery.cloud.google.com/
- Create new datasets called
crypto_ethereum,crypto_ethereum_raw,crypto_ethereum_temp
- Create a new Google Storage bucket to store exported files https://console.cloud.google.com/storage/browser
Create a new Cloud Composer environment:
export ENVIRONMENT_NAME=ethereum-etl-0
AIRFLOW_CONFIGS_ARR=(
"celery-worker_concurrency=8"
"scheduler-dag_dir_list_interval=300"
"scheduler-min_file_process_interval=120"
)
export AIRFLOW_CONFIGS=$(IFS=, ; echo "${AIRFLOW_CONFIGS_ARR[*]}")
gcloud composer environments create \
$ENVIRONMENT_NAME \
--location=us-central1 \
--image-version=composer-2.1.14-airflow-2.5.1 \
--environment-size=medium \
--scheduler-cpu=2 \
--scheduler-memory=13 \
--scheduler-storage=1 \
--scheduler-count=1 \
--web-server-cpu=1 \
--web-server-memory=2 \
--web-server-storage=512MB \
--worker-cpu=2 \
--worker-memory=13 \
--worker-storage=10 \
--min-workers=1 \
--max-workers=8 \
--airflow-configs=$AIRFLOW_CONFIGS
gcloud composer environments update \
$ENVIRONMENT_NAME \
--location=us-central1 \
--update-pypi-packages-from-file=requirements_airflow.txtCreate variables in Airflow (Admin > Variables in the UI):
| Variable | Description |
|---|---|
| ethereum_output_bucket | GCS bucket to store exported files |
| ethereum_provider_uris | Comma separated URIs of Ethereum nodes |
| ethereum_destination_dataset_project_id | Project ID of BigQuery datasets |
| notification_emails | email for notifications |
Check other variables in dags/ethereumetl_airflow/variables.py.
Suggested package requirements for Composer are stored in requirements_airflow.txt.
You can update the Composer environment using the following script:
ENVIRONMENT_NAME="ethereum-etl-0"
LOCAL_REQUIREMENTS_PATH="$(mktemp)"
# grep pattern removes comments and whitespace:
cat "./requirements_airflow.txt" | grep -o '^[^#| ]*' > "$LOCAL_REQUIREMENTS_PATH"
gcloud composer environments update \
"$ENVIRONMENT_NAME" \
--location="us-central1" \
--update-pypi-packages-from-file="$LOCAL_REQUIREMENTS_PATH"Note: Composer can be very pedantic about conflicts in additional packages. You may have to fix dependency conflicts where you had no issues testing locally (when updating dependencies, Composer does something "cleverer" than just pip install -r requirements.txt). This is why eth-hash is currently pinned in requirements_airflow.txt. Typically we have found that pinning eth-hash and/or eth-rlp may make things work, though Your Mileage May Vary.
See this issue for further ideas on how to unblock problems you may encounter.
> ./upload_dags.sh <airflow_bucket>pip install \
-r requirements_test.txt \
-r requirements_local.txt \
-r requirements_airflow.txt
pytest -vv -sA docker compose definition has been provided to easily spin up a local Airflow instance.
To build the required image:
docker compose buildTo start Airflow:
docker compose up airflowThe instance requires the CLOUDSDK_CORE_PROJECT environment variable to be set in most cases. Airflow Variables can be defined in variables.json.
Read this article: https://medium.com/@medvedev1088/query-ens-and-0x-events-with-sql-in-google-bigquery-4d197206e644
A utility script for debugging and verifying contract parsing in Ethereum data processing pipelines is available. You can simply run
python3 generate_parse_sql.py <path_to_table_definition_file> <date>
This will output some example SQL that can be used to debug if the generated json files from the contract parser are correct.
NOTE: certain files may not have the contract_address field specified as a valid address ERC20Pool_event_TransferLP but use a select statement on another table instead. For these you can simply pass the contract address yourself like below:
python3 generate_parse_sql.py <path_to_table_definition_file> <date> --contract_address <contract_address>
You can follow the instructions here for Polygon DAGs https://github.com/blockchain-etl/polygon-etl. The architecture
there is very similar to Ethereum so in most case substituting polygon for ethereum will work. Contributions
to this README file for porting documentation from Polygon to Ethereum are welcome.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ethereum-etl-airflow
Similar Open Source Tools
ethereum-etl-airflow
This repository contains Airflow DAGs for extracting, transforming, and loading (ETL) data from the Ethereum blockchain into BigQuery. The DAGs use the Google Cloud Platform (GCP) services, including BigQuery, Cloud Storage, and Cloud Composer, to automate the ETL process. The repository also includes scripts for setting up the GCP environment and running the DAGs locally.
raycast_api_proxy
The Raycast AI Proxy is a tool that acts as a proxy for the Raycast AI application, allowing users to utilize the application without subscribing. It intercepts and forwards Raycast requests to various AI APIs, then reformats the responses for Raycast. The tool supports multiple AI providers and allows for custom model configurations. Users can generate self-signed certificates, add them to the system keychain, and modify DNS settings to redirect requests to the proxy. The tool is designed to work with providers like OpenAI, Azure OpenAI, Google, and more, enabling tasks such as AI chat completions, translations, and image generation.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.
openai_trtllm
OpenAI-compatible API for TensorRT-LLM and NVIDIA Triton Inference Server, which allows you to integrate with langchain
supabase-mcp
Supabase MCP Server standardizes how Large Language Models (LLMs) interact with Supabase, enabling AI assistants to manage tables, fetch config, and query data. It provides tools for project management, database operations, project configuration, branching (experimental), and development tools. The server is pre-1.0, so expect some breaking changes between versions.
mcp-server-qdrant
The mcp-server-qdrant repository is an official Model Context Protocol (MCP) server designed for keeping and retrieving memories in the Qdrant vector search engine. It acts as a semantic memory layer on top of the Qdrant database. The server provides tools like 'qdrant-store' for storing information in the database and 'qdrant-find' for retrieving relevant information. Configuration is done using environment variables, and the server supports different transport protocols. It can be installed using 'uvx' or Docker, and can also be installed via Smithery for Claude Desktop. The server can be used with Cursor/Windsurf as a code search tool by customizing tool descriptions. It can store code snippets and help developers find specific implementations or usage patterns. The repository is licensed under the Apache License 2.0.
cursor-tools
cursor-tools is a CLI tool designed to enhance AI agents with advanced skills, such as web search, repository context, documentation generation, GitHub integration, Xcode tools, and browser automation. It provides features like Perplexity for web search, Gemini 2.0 for codebase context, and Stagehand for browser operations. The tool requires API keys for Perplexity AI and Google Gemini, and supports global installation for system-wide access. It offers various commands for different tasks and integrates with Cursor Composer for AI agent usage.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.
desktop
ComfyUI Desktop is a packaged desktop application that allows users to easily use ComfyUI with bundled features like ComfyUI source code, ComfyUI-Manager, and uv. It automatically installs necessary Python dependencies and updates with stable releases. The app comes with Electron, Chromium binaries, and node modules. Users can store ComfyUI files in a specified location and manage model paths. The tool requires Python 3.12+ and Visual Studio with Desktop C++ workload for Windows. It uses nvm to manage node versions and yarn as the package manager. Users can install ComfyUI and dependencies using comfy-cli, download uv, and build/launch the code. Troubleshooting steps include rebuilding modules and installing missing libraries. The tool supports debugging in VSCode and provides utility scripts for cleanup. Crash reports can be sent to help debug issues, but no personal data is included.

hash
HASH is a self-building, open-source database which grows, structures and checks itself. With it, we're creating a platform for decision-making, which helps you integrate, understand and use data in a variety of different ways.
laravel-crod
Laravel Crod is a package designed to facilitate the implementation of CRUD operations in Laravel projects. It allows users to quickly generate controllers, models, migrations, services, repositories, views, and requests with various customization options. The package simplifies tasks such as creating resource controllers, making models fillable, querying repositories and services, and generating additional files like seeders and factories. Laravel Crod aims to streamline the process of building CRUD functionalities in Laravel applications by providing a set of commands and tools for developers.
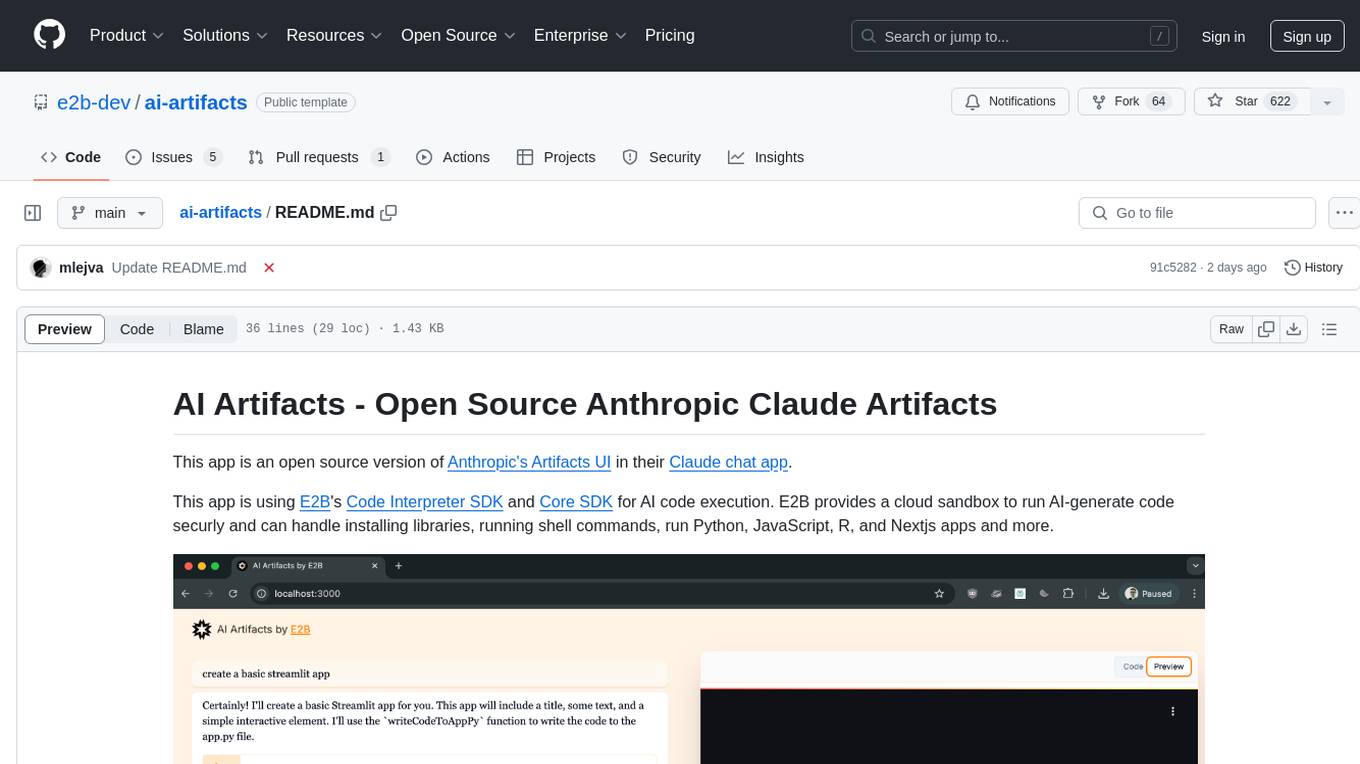
ai-artifacts
AI Artifacts is an open source tool that replicates Anthropic's Artifacts UI in the Claude chat app. It utilizes E2B's Code Interpreter SDK and Core SDK for secure AI code execution in a cloud sandbox environment. Users can run AI-generated code in various languages such as Python, JavaScript, R, and Nextjs apps. The tool also supports running AI-generated Python in Jupyter notebook, Next.js apps, and Streamlit apps. Additionally, it offers integration with Vercel AI SDK for tool calling and streaming responses from the model.

ML-Bench
ML-Bench is a tool designed to evaluate large language models and agents for machine learning tasks on repository-level code. It provides functionalities for data preparation, environment setup, usage, API calling, open source model fine-tuning, and inference. Users can clone the repository, load datasets, run ML-LLM-Bench, prepare data, fine-tune models, and perform inference tasks. The tool aims to facilitate the evaluation of language models and agents in the context of machine learning tasks on code repositories.
odoo-expert
RAG-Powered Odoo Documentation Assistant is a comprehensive documentation processing and chat system that converts Odoo's documentation to a searchable knowledge base with an AI-powered chat interface. It supports multiple Odoo versions (16.0, 17.0, 18.0) and provides semantic search capabilities powered by OpenAI embeddings. The tool automates the conversion of RST to Markdown, offers real-time semantic search, context-aware AI-powered chat responses, and multi-version support. It includes a Streamlit-based web UI, REST API for programmatic access, and a CLI for document processing and chat. The system operates through a pipeline of data processing steps and an interface layer for UI and API access to the knowledge base.
go-embeddings
This project provides API clients for fetching embeddings from various LLM providers. It includes implementations for OpenAI, Cohere, Google Vertex, VoyageAI, Ollama, and AWS Bedrock. Sample programs demonstrate how to use the client packages. The 'document' package offers text splitters inspired by Langchain framework. Environment variables are used to initialize API clients for each provider. Contributions are welcome.
loz
Loz is a command-line tool that integrates AI capabilities with Unix tools, enabling users to execute system commands and utilize Unix pipes. It supports multiple LLM services like OpenAI API, Microsoft Copilot, and Ollama. Users can run Linux commands based on natural language prompts, enhance Git commit formatting, and interact with the tool in safe mode. Loz can process input from other command-line tools through Unix pipes and automatically generate Git commit messages. It provides features like chat history access, configurable LLM settings, and contribution opportunities.
For similar tasks
ethereum-etl-airflow
This repository contains Airflow DAGs for extracting, transforming, and loading (ETL) data from the Ethereum blockchain into BigQuery. The DAGs use the Google Cloud Platform (GCP) services, including BigQuery, Cloud Storage, and Cloud Composer, to automate the ETL process. The repository also includes scripts for setting up the GCP environment and running the DAGs locally.
For similar jobs
ethereum-etl-airflow
This repository contains Airflow DAGs for extracting, transforming, and loading (ETL) data from the Ethereum blockchain into BigQuery. The DAGs use the Google Cloud Platform (GCP) services, including BigQuery, Cloud Storage, and Cloud Composer, to automate the ETL process. The repository also includes scripts for setting up the GCP environment and running the DAGs locally.

airnode
Airnode is a fully-serverless oracle node that is designed specifically for API providers to operate their own oracles.
CHATPGT-MEV-BOT
The 𝓜𝓔𝓥-𝓑𝓞𝓣 is a revolutionary tool that empowers users to maximize their ETH earnings through advanced slippage techniques within the Ethereum ecosystem. Its user-centric design, optimized earning mechanism, and comprehensive security measures make it an indispensable tool for traders seeking to enhance their crypto trading strategies. With its current free access, there's no better time to explore the 𝓜𝓔𝓥-𝓑𝓞𝓣's capabilities and witness the transformative impact it can have on your crypto trading journey.
CortexTheseus
CortexTheseus is a full node implementation of the Cortex blockchain, written in C++. It provides a complete set of features for interacting with the Cortex network, including the ability to create and manage accounts, send and receive transactions, and participate in consensus. CortexTheseus is designed to be scalable, secure, and easy to use, making it an ideal choice for developers building applications on the Cortex blockchain.
CHATPGT-MEV-BOT-ETH
This tool is a bot that monitors the performance of MEV transactions on the Ethereum blockchain. It provides real-time data on MEV profitability, transaction volume, and network congestion. The bot can be used to identify profitable MEV opportunities and to track the performance of MEV strategies.
airdrop-checker
Airdrop-checker is a tool that helps you to check if you are eligible for any airdrops. It supports multiple airdrops, including Altlayer, Rabby points, Zetachain, Frame, Anoma, Dymension, and MEME. To use the tool, you need to install it using npm and then fill the addresses files in the addresses folder with your wallet addresses. Once you have done this, you can run the tool using npm start.
go-cyber
Cyber is a superintelligence protocol that aims to create a decentralized and censorship-resistant internet. It uses a novel consensus mechanism called CometBFT and a knowledge graph to store and process information. Cyber is designed to be scalable, secure, and efficient, and it has the potential to revolutionize the way we interact with the internet.
bittensor
Bittensor is an internet-scale neural network that incentivizes computers to provide access to machine learning models in a decentralized and censorship-resistant manner. It operates through a token-based mechanism where miners host, train, and procure machine learning systems to fulfill verification problems defined by validators. The network rewards miners and validators for their contributions, ensuring continuous improvement in knowledge output. Bittensor allows anyone to participate, extract value, and govern the network without centralized control. It supports tasks such as generating text, audio, images, and extracting numerical representations.