
trex
Enforce structured output from LLMs 100% of the time
Stars: 239
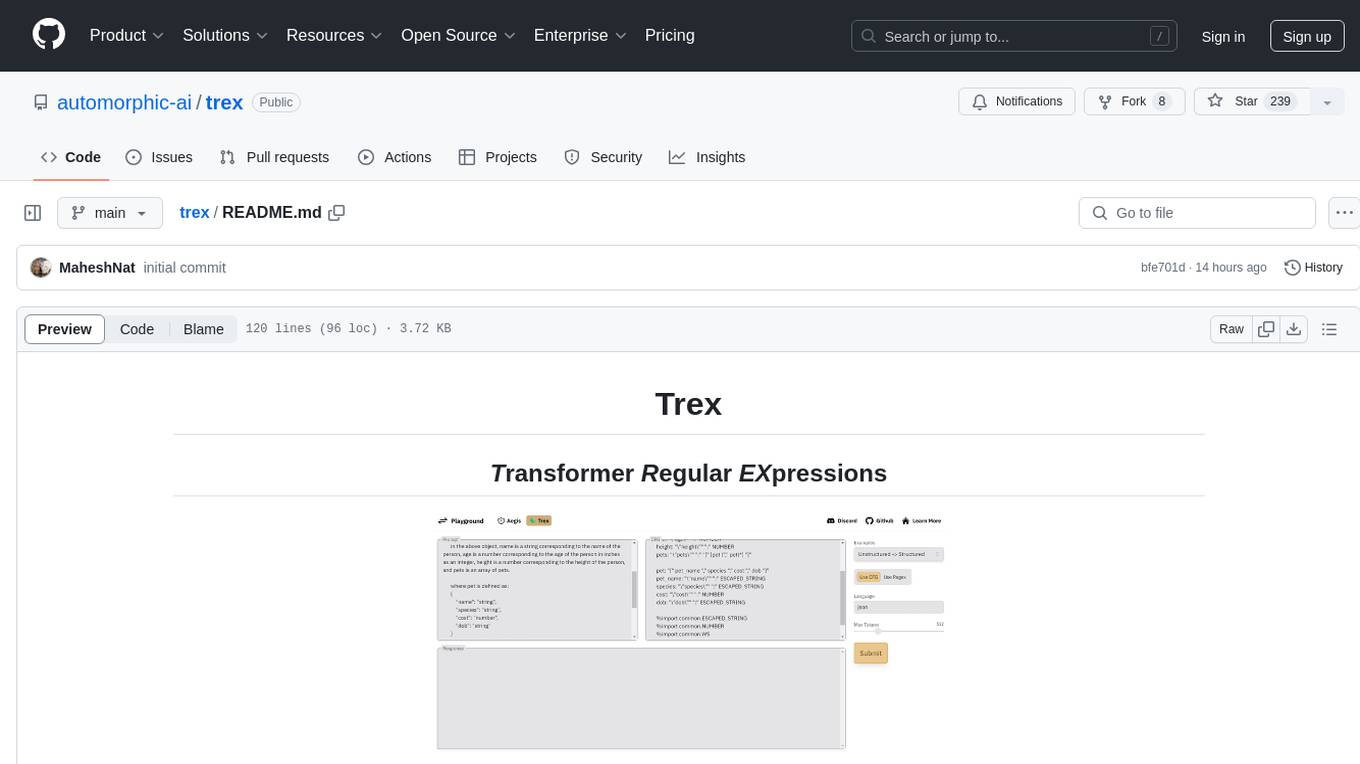
Trex is a tool that transforms unstructured data into structured data by specifying a regex or context-free grammar. It intelligently restructures data to conform to the defined schema. It offers a Python client for installation and requires an API key obtained by signing up at automorphic.ai. The tool supports generating structured JSON objects based on user-defined schemas and prompts. Trex aims to provide significant speed improvements, structured custom CFG and regex generation, and generation from JSON schema. Future plans include auto-prompt generation for unstructured ETL and more intelligent models.
README:

Trex transforms your unstructured to structured data—just specify a regex or context free grammar and we'll intelligently restructure your data so it conforms to that schema.
To experiment with Trex, check out the playground.
To install the Python client:
pip install git+https://github.com/automorphic-ai/trex.gitIf you'd like to self-host this in your own cloud / with your own model, email us.
To use Trex, you'll need an API key, which you can get by signing up for a free account at automorphic.ai.
import trex
tx = trex.Trex('<YOUR_AUTOMORPHIC_API_KEY>')
prompt = '''generate a valid json object of the following format:
{
"name": "string",
"age": "number",
"height": "number",
"pets": pet[]
}
in the above object, name is a string corresponding to the name of the person, age is a number corresponding to the age of the person in inches as an integer, height is a number corresponding to the height of the person, and pets is an array of pets.
where pet is defined as:
{
"name": "string",
"species": "string",
"cost": "number",
"dob": "string"
}
in the above object name is a string corresponding to the name of the pet, species is a string corresponding to the species of the pet, cost is a number corresponding to the cost of the pet, and dob is a string corresponding to the date of birth of the pet.
given the above, generate a valid json object containing the following data: one human named dave 30 years old 5 foot 8 with a single dog pet named 'trex'. the dog costed $100 and was born on 9/11/2001.
'''
json_schema = {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"age": {
"type": "number"
},
"height": {
"type": "number"
},
"pets": {
"type": "array",
"items": [{
"type": "object",
"properties": {
"name": {
"type": "string"
},
"species": {
"type": "string"
},
"cost": {
"type": "number"
},
"dob": {
"type": "string"
}
}
}]
}
}
}
print(tx.generate_json(prompt, json_schema=json_schema).response)
# the above produces:
# {
# "name": "dave",
# "age": 30,
# "height": 58,
# "pets": [
# {
# "name": "trex",
# "species": "dog",
# "cost": 100,
# "dob": "2008-10-27"
# }
# ]
# }- [x] Structured JSON generation
- [x] Structured custom CFG generation
- [x] Structured custom regex generation
- [x] SIGNIFICANT speed improvements
- [x] Generation from JSON schema
- [ ] Auto-prompt generation for unstructured ETL
- [ ] More intelligent models
Join our Discord or email us, if you're interested in or need help using Trex, have ideas, or want to contribute.
Follow us on Twitter for updates.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for trex
Similar Open Source Tools
trex
Trex is a tool that transforms unstructured data into structured data by specifying a regex or context-free grammar. It intelligently restructures data to conform to the defined schema. It offers a Python client for installation and requires an API key obtained by signing up at automorphic.ai. The tool supports generating structured JSON objects based on user-defined schemas and prompts. Trex aims to provide significant speed improvements, structured custom CFG and regex generation, and generation from JSON schema. Future plans include auto-prompt generation for unstructured ETL and more intelligent models.
fluid-db
FluidDB is a research repository focusing on the concept of a fluid database that dynamically updates its schema based on ingested data. It enables the creation of personalized AI agents with features like adaptive schema, flexible querying, and versatile data input. The tool allows for storing unstructured data in a structured form and supports natural language queries. It aims to revolutionize database management by providing a dynamic and intuitive approach to data storage and retrieval.

firecrawl
Firecrawl is an API service that empowers AI applications with clean data from any website. It features advanced scraping, crawling, and data extraction capabilities. The repository is still in development, integrating custom modules into the mono repo. Users can run it locally but it's not fully ready for self-hosted deployment yet. Firecrawl offers powerful capabilities like scraping, crawling, mapping, searching, and extracting structured data from single pages, multiple pages, or entire websites with AI. It supports various formats, actions, and batch scraping. The tool is designed to handle proxies, anti-bot mechanisms, dynamic content, media parsing, change tracking, and more. Firecrawl is available as an open-source project under the AGPL-3.0 license, with additional features offered in the cloud version.
VectorETL
VectorETL is a lightweight ETL framework designed to assist Data & AI engineers in processing data for AI applications quickly. It streamlines the conversion of diverse data sources into vector embeddings and storage in various vector databases. The framework supports multiple data sources, embedding models, and vector database targets, simplifying the creation and management of vector search systems for semantic search, recommendation systems, and other vector-based operations.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.
Agently
Agently is a development framework that helps developers build AI agent native application really fast. You can use and build AI agent in your code in an extremely simple way. You can create an AI agent instance then interact with it like calling a function in very few codes like this below. Click the run button below and witness the magic. It's just that simple: python # Import and Init Settings import Agently agent = Agently.create_agent() agent\ .set_settings("current_model", "OpenAI")\ .set_settings("model.OpenAI.auth", {"api_key": ""}) # Interact with the agent instance like calling a function result = agent\ .input("Give me 3 words")\ .output([("String", "one word")])\ .start() print(result) ['apple', 'banana', 'carrot'] And you may notice that when we print the value of `result`, the value is a `list` just like the format of parameter we put into the `.output()`. In Agently framework we've done a lot of work like this to make it easier for application developers to integrate Agent instances into their business code. This will allow application developers to focus on how to build their business logic instead of figure out how to cater to language models or how to keep models satisfied.
CoPilot
TigerGraph CoPilot is an AI assistant that combines graph databases and generative AI to enhance productivity across various business functions. It includes three core component services: InquiryAI for natural language assistance, SupportAI for knowledge Q&A, and QueryAI for GSQL code generation. Users can interact with CoPilot through a chat interface on TigerGraph Cloud and APIs. CoPilot requires LLM services for beta but will support TigerGraph's LLM in future releases. It aims to improve contextual relevance and accuracy of answers to natural-language questions by building knowledge graphs and using RAG. CoPilot is extensible and can be configured with different LLM providers, graph schemas, and LangChain tools.
summary-of-a-haystack
This repository contains data and code for the experiments in the SummHay paper. It includes publicly released Haystacks in conversational and news domains, along with scripts for running the pipeline, visualizing results, and benchmarking automatic evaluation. The data structure includes topics, subtopics, insights, queries, retrievers, summaries, evaluation summaries, and documents. The pipeline involves scripts for retriever scores, summaries, and evaluation scores using GPT-4o. Visualization scripts are provided for compiling and visualizing results. The repository also includes annotated samples for benchmarking and citation information for the SummHay paper.
structured-logprobs
This Python library enhances OpenAI chat completion responses by providing detailed information about token log probabilities. It works with OpenAI Structured Outputs to ensure model-generated responses adhere to a JSON Schema. Developers can analyze and incorporate token-level log probabilities to understand the reliability of structured data extracted from OpenAI models.
mistreevous
Mistreevous is a library written in TypeScript for Node and browsers, used to declaratively define, build, and execute behaviour trees for creating complex AI. It allows defining trees with JSON or a minimal DSL, providing in-browser editor and visualizer. The tool offers methods for tree state, stepping, resetting, and getting node details, along with various composite, decorator, leaf nodes, callbacks, guards, and global functions/subtrees. Version history includes updates for node types, callbacks, global functions, and TypeScript conversion.
ai-dev-2024-ml-workshop
The 'ai-dev-2024-ml-workshop' repository contains materials for the Deploy and Monitor ML Pipelines workshop at the AI_dev 2024 conference in Paris, focusing on deployment designs of machine learning pipelines using open-source applications and free-tier tools. It demonstrates automating data refresh and forecasting using GitHub Actions and Docker, monitoring with MLflow and YData Profiling, and setting up a monitoring dashboard with Quarto doc on GitHub Pages.

empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.

npi
NPi is an open-source platform providing Tool-use APIs to empower AI agents with the ability to take action in the virtual world. It is currently under active development, and the APIs are subject to change in future releases. NPi offers a command line tool for installation and setup, along with a GitHub app for easy access to repositories. The platform also includes a Python SDK and examples like Calendar Negotiator and Twitter Crawler. Join the NPi community on Discord to contribute to the development and explore the roadmap for future enhancements.

llm-structured-output
This repository contains a library for constraining LLM generation to structured output, enforcing a JSON schema for precise data types and property names. It includes an acceptor/state machine framework, JSON acceptor, and JSON schema acceptor for guiding decoding in LLMs. The library provides reference implementations using Apple's MLX library and examples for function calling tasks. The tool aims to improve LLM output quality by ensuring adherence to a schema, reducing unnecessary output, and enhancing performance through pre-emptive decoding. Evaluations show performance benchmarks and comparisons with and without schema constraints.
AICentral
AI Central is a powerful tool designed to take control of your AI services with minimal overhead. It is built on Asp.Net Core and dotnet 8, offering fast web-server performance. The tool enables advanced Azure APIm scenarios, PII stripping logging to Cosmos DB, token metrics through Open Telemetry, and intelligent routing features. AI Central supports various endpoint selection strategies, proxying asynchronous requests, custom OAuth2 authorization, circuit breakers, rate limiting, and extensibility through plugins. It provides an extensibility model for easy plugin development and offers enriched telemetry and logging capabilities for monitoring and insights.
notebook-intelligence
Notebook Intelligence (NBI) is an AI coding assistant and extensible AI framework for JupyterLab. It greatly boosts the productivity of JupyterLab users with AI assistance by providing features such as code generation with inline chat, auto-complete, and chat interface. NBI supports various LLM Providers and AI Models, including local models from Ollama. Users can configure model provider and model options, remember GitHub Copilot login, and save configuration files. NBI seamlessly integrates with Model Context Protocol (MCP) servers, supporting both Standard Input/Output (stdio) and Server-Sent Events (SSE) transports. Users can easily add MCP servers to NBI, auto-approve tools, set environment variables, and group servers based on functionality. Additionally, NBI allows access to built-in tools from an MCP participant, enhancing the user experience and productivity.
For similar tasks
trex
Trex is a tool that transforms unstructured data into structured data by specifying a regex or context-free grammar. It intelligently restructures data to conform to the defined schema. It offers a Python client for installation and requires an API key obtained by signing up at automorphic.ai. The tool supports generating structured JSON objects based on user-defined schemas and prompts. Trex aims to provide significant speed improvements, structured custom CFG and regex generation, and generation from JSON schema. Future plans include auto-prompt generation for unstructured ETL and more intelligent models.

instructor-js
Instructor is a Typescript library for structured extraction in Typescript, powered by llms, designed for simplicity, transparency, and control. It stands out for its simplicity, transparency, and user-centric design. Whether you're a seasoned developer or just starting out, you'll find Instructor's approach intuitive and steerable.
awesome-ai-repositories
A curated list of open source repositories for AI Engineers. The repository provides a comprehensive collection of tools and frameworks for various AI-related tasks such as AI Gateway, AI Workload Manager, Copilot Development, Dataset Engineering, Evaluation, Fine Tuning, Function Calling, Graph RAG, Guardrails, Local Model Inference, LLM Agent Framework, Model Serving, Observability, Pre Training, Prompt Engineering, RAG Framework, Security, Structured Extraction, Structured Generation, Vector DB, and Voice Agent.
orch
orch is a library for building language model powered applications and agents for the Rust programming language. It can be used for tasks such as text generation, streaming text generation, structured data generation, and embedding generation. The library provides functionalities for executing various language model tasks and can be integrated into different applications and contexts. It offers flexibility for developers to create language model-powered features and applications in Rust.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.