
fluid-db
Fluid Database
Stars: 113
FluidDB is a research repository focusing on the concept of a fluid database that dynamically updates its schema based on ingested data. It enables the creation of personalized AI agents with features like adaptive schema, flexible querying, and versatile data input. The tool allows for storing unstructured data in a structured form and supports natural language queries. It aims to revolutionize database management by providing a dynamic and intuitive approach to data storage and retrieval.
README:
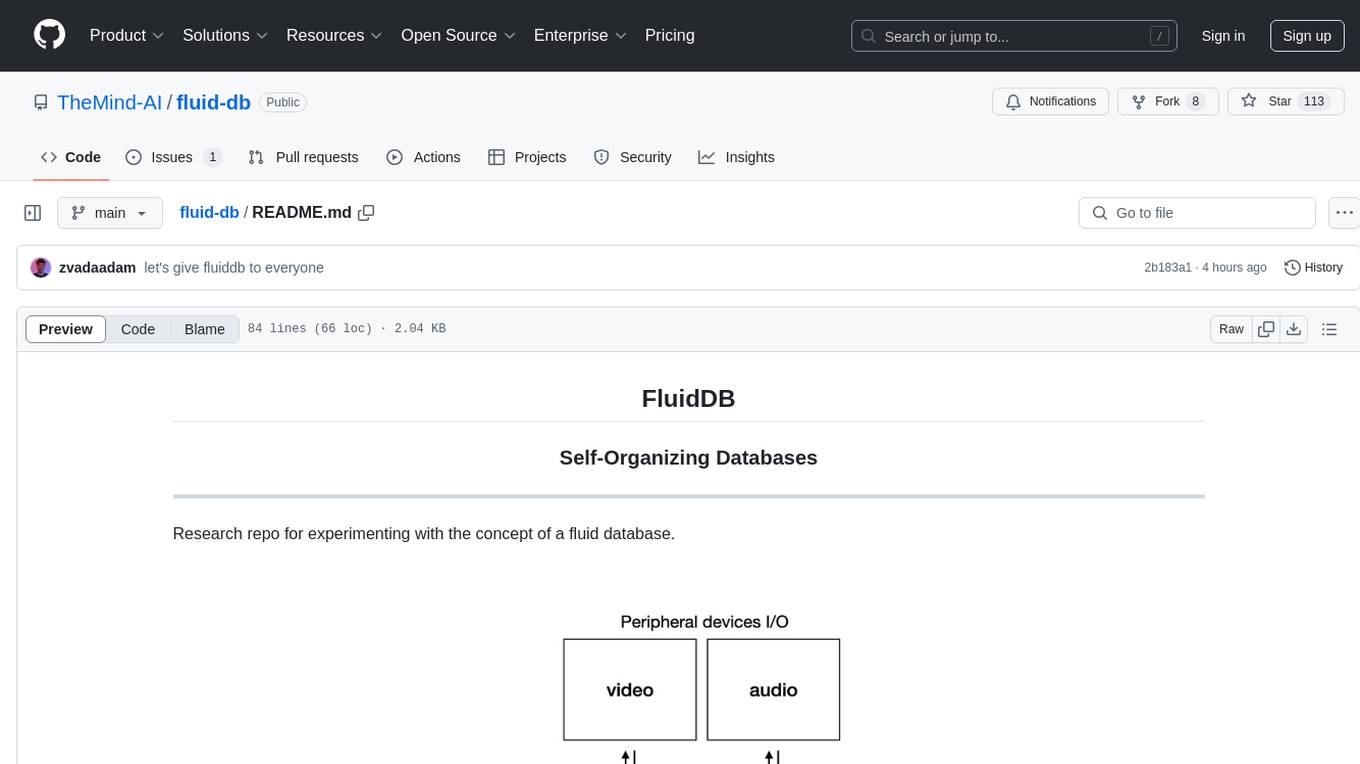
Research repo for experimenting with the concept of a fluid database.

FluidDB (Fluid Database) is a concept for databases that dynamically update its schema based on the ingested data. It's here for you to build truly personalized AI agents by giving them memory.
LLM + FluidDB = Personalized AI
Key features:
- Adaptive Schema: Automatically adjusts its structure based on the data being ingested.
- Flexible Querying: Supports both traditional query languages and intuitive natural language queries.
- Versatile Data Input: Enables data entry in natural language, as well as in semi-structured formats.
Want to see it in action? Check out the MIND Apps.
- [ ] FluidDB Client
- [ ] Databases Engine
- [ ] CLI
- [ ] Router
- [ ] Eval System
- [ ] Hosted Service
FluidDB saves unstructured data in a structured form.
# Saving a simple natural language statement into FluidDB
fluiddb.save(uid, "hey adam here and i like thinking about the roman empire")FluidDB automatically updates its schema to reflect this new data:
{
"name": "Adam",
"interests": ["thinking about the Roman Empire"]
}Further, FluidDB demonstrates its versatility with semi-structured data formats. For instance:
# Storing structured data like an email
email = {
"from": "[email protected]",
"to": "[email protected]",
"subject": "Check this out",
"content": "Hi Adam, Hope this email finds you well ..."
}
fluiddb.save(uid, email)FluidDB then incorporates this new information into its schema:
{
"name": "Adam",
"interests": ["thinking about the Roman Empire", "blue bottle"],
"email": [{
"from": "[email protected]",
"to": "[email protected]",
"subject": "Check this out",
"content": "Hi Adam, Hope this email finds you well ..."
}]
}building...For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for fluid-db
Similar Open Source Tools
fluid-db
FluidDB is a research repository focusing on the concept of a fluid database that dynamically updates its schema based on ingested data. It enables the creation of personalized AI agents with features like adaptive schema, flexible querying, and versatile data input. The tool allows for storing unstructured data in a structured form and supports natural language queries. It aims to revolutionize database management by providing a dynamic and intuitive approach to data storage and retrieval.
VectorETL
VectorETL is a lightweight ETL framework designed to assist Data & AI engineers in processing data for AI applications quickly. It streamlines the conversion of diverse data sources into vector embeddings and storage in various vector databases. The framework supports multiple data sources, embedding models, and vector database targets, simplifying the creation and management of vector search systems for semantic search, recommendation systems, and other vector-based operations.
chatmemory
ChatMemory is a simple yet powerful long-term memory manager that facilitates communication between AI and users. It organizes conversation data into history, summary, and knowledge entities, enabling quick retrieval of context and generation of clear, concise answers. The tool leverages vector search on summaries/knowledge and detailed history to provide accurate responses. It balances speed and accuracy by using lightweight retrieval and fallback detailed search mechanisms, ensuring efficient memory management and response generation beyond mere data retrieval.
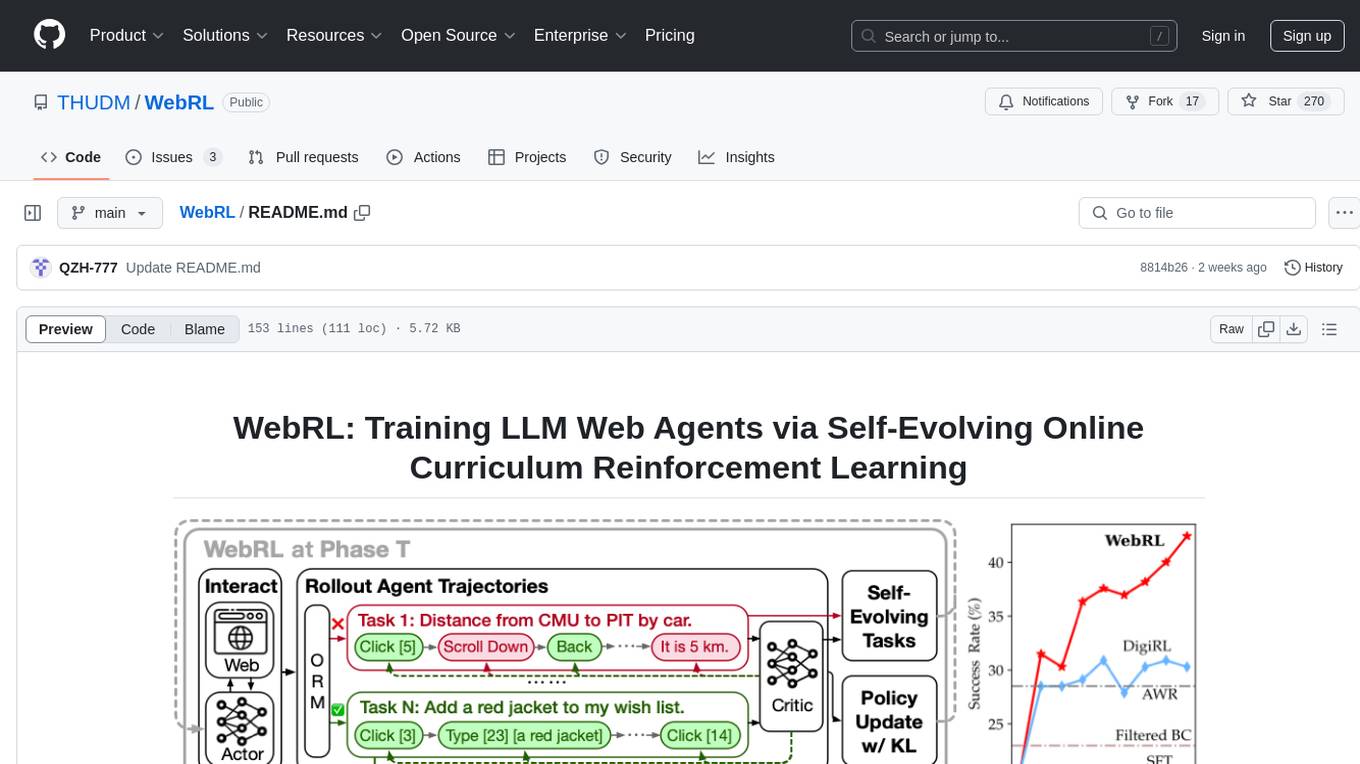
WebRL
WebRL is a self-evolving online curriculum learning framework designed for training web agents in the WebArena environment. It provides model checkpoints, training instructions, and evaluation processes for training the actor and critic models. The tool enables users to generate new instructions and interact with WebArena to configure tasks for training and evaluation.

awadb
AwaDB is an AI native database designed for embedding vectors. It simplifies database usage by eliminating the need for schema definition and manual indexing. The system ensures real-time search capabilities with millisecond-level latency. Built on 5 years of production experience with Vearch, AwaDB incorporates best practices from the community to offer stability and efficiency. Users can easily add and search for embedded sentences using the provided client libraries or RESTful API.
CoPilot
TigerGraph CoPilot is an AI assistant that combines graph databases and generative AI to enhance productivity across various business functions. It includes three core component services: InquiryAI for natural language assistance, SupportAI for knowledge Q&A, and QueryAI for GSQL code generation. Users can interact with CoPilot through a chat interface on TigerGraph Cloud and APIs. CoPilot requires LLM services for beta but will support TigerGraph's LLM in future releases. It aims to improve contextual relevance and accuracy of answers to natural-language questions by building knowledge graphs and using RAG. CoPilot is extensible and can be configured with different LLM providers, graph schemas, and LangChain tools.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.

empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.
redis-vl-python
The Python Redis Vector Library (RedisVL) is a tailor-made client for AI applications leveraging Redis. It enhances applications with Redis' speed, flexibility, and reliability, incorporating capabilities like vector-based semantic search, full-text search, and geo-spatial search. The library bridges the gap between the emerging AI-native developer ecosystem and the capabilities of Redis by providing a lightweight, elegant, and intuitive interface. It abstracts the features of Redis into a grammar that is more aligned to the needs of today's AI/ML Engineers or Data Scientists.
call-center-ai
Call Center AI is an AI-powered call center solution that leverages Azure and OpenAI GPT. It is a proof of concept demonstrating the integration of Azure Communication Services, Azure Cognitive Services, and Azure OpenAI to build an automated call center solution. The project showcases features like accessing claims on a public website, customer conversation history, language change during conversation, bot interaction via phone number, multiple voice tones, lexicon understanding, todo list creation, customizable prompts, content filtering, GPT-4 Turbo for customer requests, specific data schema for claims, documentation database access, SMS report sending, conversation resumption, and more. The system architecture includes components like RAG AI Search, SMS gateway, call gateway, moderation, Cosmos DB, event broker, GPT-4 Turbo, Redis cache, translation service, and more. The tool can be deployed remotely using GitHub Actions and locally with prerequisites like Azure environment setup, configuration file creation, and resource hosting. Advanced usage includes custom training data with AI Search, prompt customization, language customization, moderation level customization, claim data schema customization, OpenAI compatible model usage for the LLM, and Twilio integration for SMS.
SimplerLLM
SimplerLLM is an open-source Python library that simplifies interactions with Large Language Models (LLMs) for researchers and beginners. It provides a unified interface for different LLM providers, tools for enhancing language model capabilities, and easy development of AI-powered tools and apps. The library offers features like unified LLM interface, generic text loader, RapidAPI connector, SERP integration, prompt template builder, and more. Users can easily set up environment variables, create LLM instances, use tools like SERP, generic text loader, calling RapidAPI APIs, and prompt template builder. Additionally, the library includes chunking functions to split texts into manageable chunks based on different criteria. Future updates will bring more tools, interactions with local LLMs, prompt optimization, response evaluation, GPT Trainer, document chunker, advanced document loader, integration with more providers, Simple RAG with SimplerVectors, integration with vector databases, agent builder, and LLM server.

LLamaWorker
LLamaWorker is a HTTP API server developed to provide an OpenAI-compatible API for integrating Large Language Models (LLM) into applications. It supports multi-model configuration, streaming responses, text embedding, chat templates, automatic model release, function calls, API key authentication, and test UI. Users can switch models, complete chats and prompts, manage chat history, and generate tokens through the test UI. Additionally, LLamaWorker offers a Vulkan compiled version for download and provides function call templates for testing. The tool supports various backends and provides API endpoints for chat completion, prompt completion, embeddings, model information, model configuration, and model switching. A Gradio UI demo is also available for testing.
ai-dev-2024-ml-workshop
The 'ai-dev-2024-ml-workshop' repository contains materials for the Deploy and Monitor ML Pipelines workshop at the AI_dev 2024 conference in Paris, focusing on deployment designs of machine learning pipelines using open-source applications and free-tier tools. It demonstrates automating data refresh and forecasting using GitHub Actions and Docker, monitoring with MLflow and YData Profiling, and setting up a monitoring dashboard with Quarto doc on GitHub Pages.

instructor-js
Instructor is a Typescript library for structured extraction in Typescript, powered by llms, designed for simplicity, transparency, and control. It stands out for its simplicity, transparency, and user-centric design. Whether you're a seasoned developer or just starting out, you'll find Instructor's approach intuitive and steerable.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.
summary-of-a-haystack
This repository contains data and code for the experiments in the SummHay paper. It includes publicly released Haystacks in conversational and news domains, along with scripts for running the pipeline, visualizing results, and benchmarking automatic evaluation. The data structure includes topics, subtopics, insights, queries, retrievers, summaries, evaluation summaries, and documents. The pipeline involves scripts for retriever scores, summaries, and evaluation scores using GPT-4o. Visualization scripts are provided for compiling and visualizing results. The repository also includes annotated samples for benchmarking and citation information for the SummHay paper.
For similar tasks
AutoGPT
AutoGPT is a revolutionary tool that empowers everyone to harness the power of AI. With AutoGPT, you can effortlessly build, test, and delegate tasks to AI agents, unlocking a world of possibilities. Our mission is to provide the tools you need to focus on what truly matters: innovation and creativity.
agent-os
The Agent OS is an experimental framework and runtime to build sophisticated, long running, and self-coding AI agents. We believe that the most important super-power of AI agents is to write and execute their own code to interact with the world. But for that to work, they need to run in a suitable environment—a place designed to be inhabited by agents. The Agent OS is designed from the ground up to function as a long-term computing substrate for these kinds of self-evolving agents.
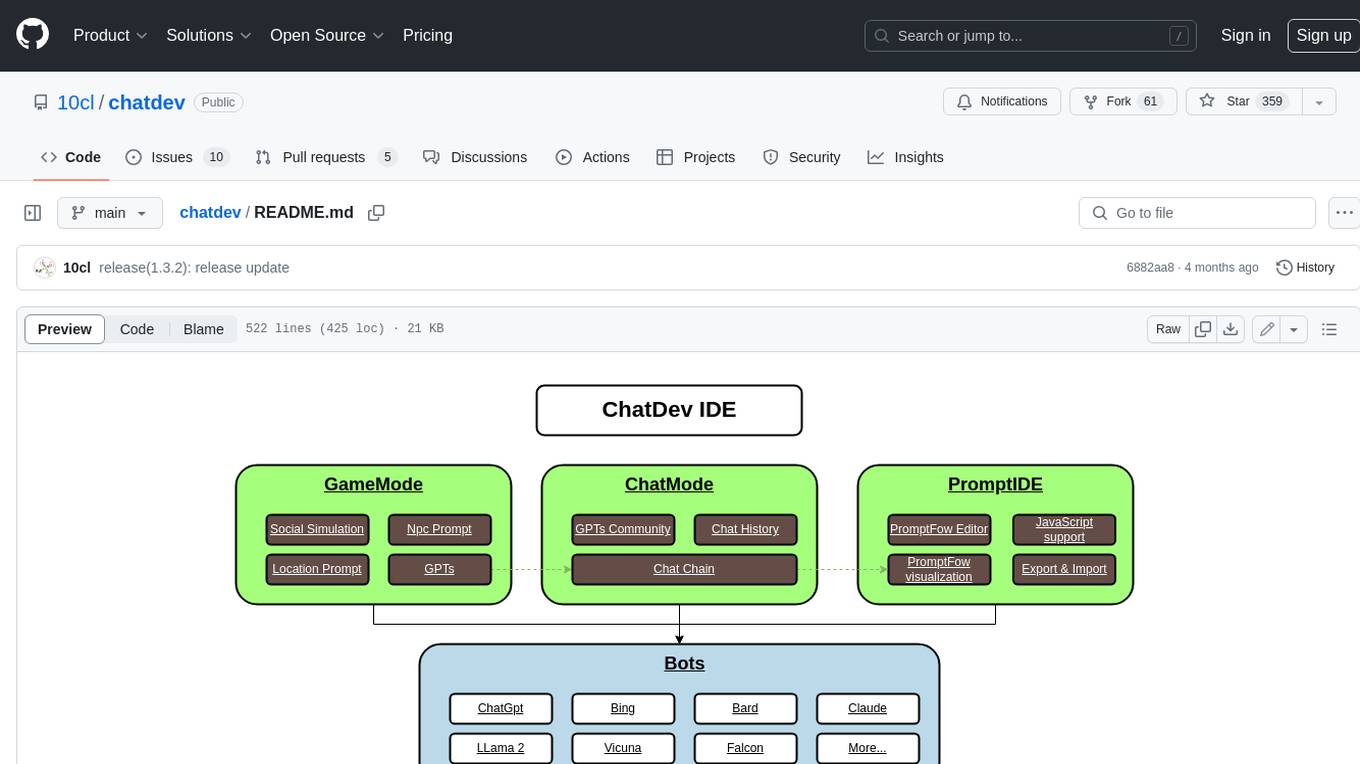
chatdev
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.
module-ballerinax-ai.agent
This library provides functionality required to build ReAct Agent using Large Language Models (LLMs).

npi
NPi is an open-source platform providing Tool-use APIs to empower AI agents with the ability to take action in the virtual world. It is currently under active development, and the APIs are subject to change in future releases. NPi offers a command line tool for installation and setup, along with a GitHub app for easy access to repositories. The platform also includes a Python SDK and examples like Calendar Negotiator and Twitter Crawler. Join the NPi community on Discord to contribute to the development and explore the roadmap for future enhancements.
ai-agents
The 'ai-agents' repository is a collection of books and resources focused on developing AI agents, including topics such as GPT models, building AI agents from scratch, machine learning theory and practice, and basic methods and tools for data analysis. The repository provides detailed explanations and guidance for individuals interested in learning about and working with AI agents.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
ai-app
The 'ai-app' repository is a comprehensive collection of tools and resources related to artificial intelligence, focusing on topics such as server environment setup, PyCharm and Anaconda installation, large model deployment and training, Transformer principles, RAG technology, vector databases, AI image, voice, and music generation, and AI Agent frameworks. It also includes practical guides and tutorials on implementing various AI applications. The repository serves as a valuable resource for individuals interested in exploring different aspects of AI technology.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.