
summary-of-a-haystack
Codebase accompanying the Summary of a Haystack paper.
Stars: 61
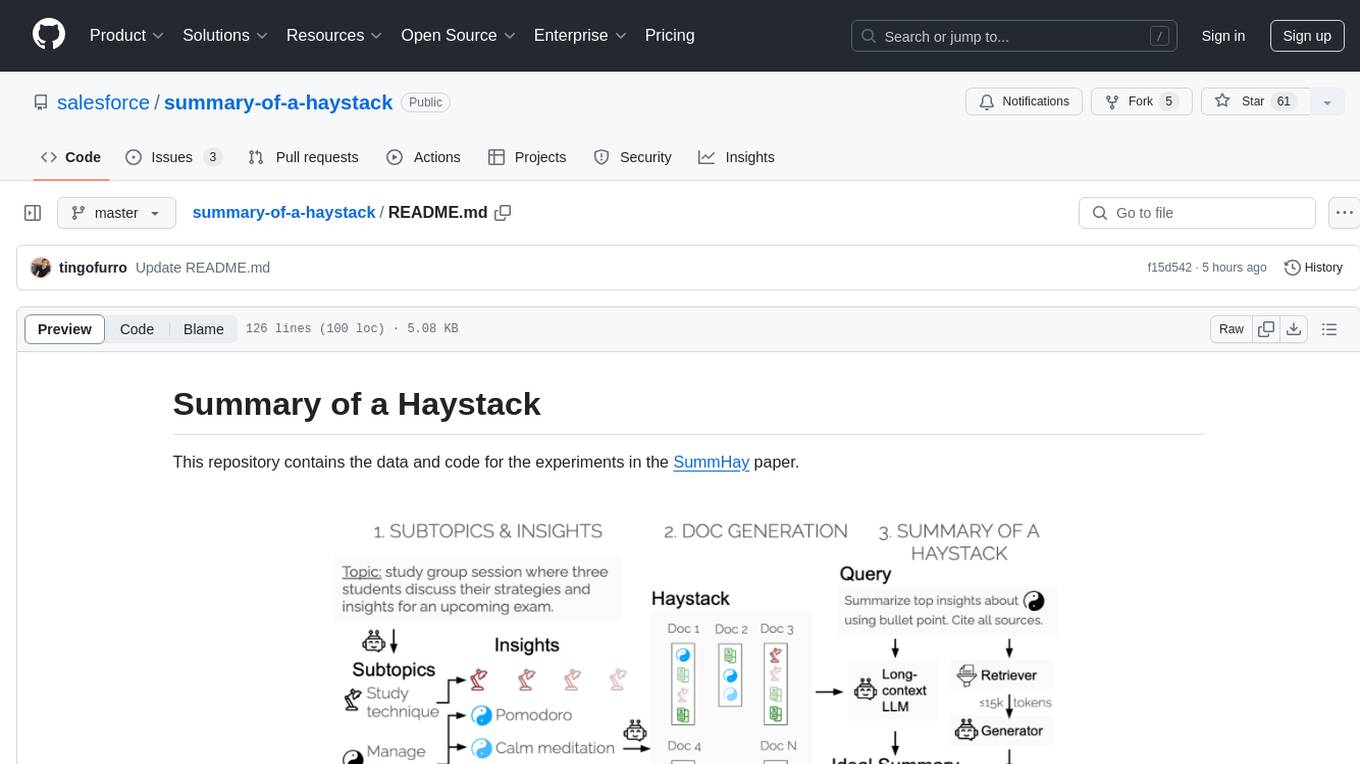
This repository contains data and code for the experiments in the SummHay paper. It includes publicly released Haystacks in conversational and news domains, along with scripts for running the pipeline, visualizing results, and benchmarking automatic evaluation. The data structure includes topics, subtopics, insights, queries, retrievers, summaries, evaluation summaries, and documents. The pipeline involves scripts for retriever scores, summaries, and evaluation scores using GPT-4o. Visualization scripts are provided for compiling and visualizing results. The repository also includes annotated samples for benchmarking and citation information for the SummHay paper.
README:
This repository contains the data and code for the experiments in the SummHay paper.

We publicly release the 10 Haystacks (5 in conversational domain, 5 in the news domain). You can access the Haystacks via huggingface datasets:
from datasets import load_dataset
dataset = load_dataset("Salesforce/summary-of-a-haystack")['train']They are also provided in the data/ folder. There is one Haystack per .json file.
Each Haystack follows the following schema:
{
"topic_id": "ObjectId()",
"topic": "",
"topic_metadata": {"participants": []}, // can be domain specific
"subtopics": [
{
"subtopic_id": "ObjectId()",
"subtopic_name": "",
"subtopic": "",
"insights": [
{
"insight_id": "ObjectId()",
"insight_name": "",
"insight": ""
}
],
"query": "question reformulation of the subtopic",
"retriever": {
"retriever_method": {
"document_id": "0|1"
}
},
"summaries": {
"summarization_method_xyz": ["line1", "line2", "line3"],
"{retriever}-{llm_summarizer}": ["line1", "line2", "line3"],
"summarization_method_abc": ["line1", "line2", "line3"]
},
"eval_summaries": {
"summarization_method_xyz": [
{
"insight_id": "",
"coverage": "NO_COVERAGE|PARTIAL_COVERAGE|FULL_COVERAGE",
"bullet_id": "line_number"
}
]
}
}
],
"documents": [
{
"document_id": "ObjectId()",
"document_text": "",
"document_metadata": [], // domain specific information
"insights_included": [] // list of insight_ids
}
]
}
The pipeline can be run with three consecutive scripts: (1) populate_retriever_scores.py (optional, if implementing a new retriever), (2) populate_summaries.py which populates the summary outputs, (3) populate_eval.py which generates the evaluation scores (using GPT-4o by default.
Some notes:
- In order to introduce a new retriever/summarizer, one should modify the
generatefunctions (which currently map to our internal LLM API) to link to the generative system that should be evaluated. - We recommend keeping the prompts unmodified (they are provided in
prompts/), but if you modify the prompt, we highly recommend stating so when reporting results. We did not perform extensive prompt engineering optimization in the results reported in the paper. - Each script has
argparsearguments that can help with specific use.
An example of running on the pipeline might look like:
python populate_summaries.py --fn data/topic_news1.json --domain news --model_cards claude4 --full_sum --retrieval_summ
python populate_eval.py --fn data/topic_news1.jsonThe above would run the SummHay experiment (i.e., generate summaries) for all retrievers, and for the full-context settings, for a model named Claude4 (whose access would have to be implemented within populate_summaries.py), followed by the automatic evaluation on those summaries.
The Results_Visualization.ipynb notebook contains the scripts that can be used to compile and visualize results, these are the exact scripts used to generate Table 2 in the paper.
Sections 4.2-4.3 of the paper mention an experimental setup to validate the automation of SummHay evaluation.
We release the 200 annotated samples used for this experiment (see data/eval_benchmark_data.json), which contains the manual annotations, as well as predictions obtained from the evaluator models included in our experiments.
The Eval_Benchmarking.ipynb notebook includes the code used to compile and visualize the results (corresponding to Table 1 in the paper), and the bias estimates for the automatic metrics (corresponding to Table 4 in the paper's Appendix).
The release of the data can serve as a basis to evaluate future (potentially more efficient) methods for evaluation of the SummHay task.
@article{laban2024SummHay,
title={Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems},
author={Laban, Philippe and Fabbri, Alexander R and Xiong, Caiming and Wu, Chien-Sheng},
journal={arXiv preprint arXiv:https://arxiv.org/pdf/2407.01370},
year={2024}
}
Please create a GitHub issue if you have any questions, suggestions, requests or bug-reports. We welcome PRs!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for summary-of-a-haystack
Similar Open Source Tools
summary-of-a-haystack
This repository contains data and code for the experiments in the SummHay paper. It includes publicly released Haystacks in conversational and news domains, along with scripts for running the pipeline, visualizing results, and benchmarking automatic evaluation. The data structure includes topics, subtopics, insights, queries, retrievers, summaries, evaluation summaries, and documents. The pipeline involves scripts for retriever scores, summaries, and evaluation scores using GPT-4o. Visualization scripts are provided for compiling and visualizing results. The repository also includes annotated samples for benchmarking and citation information for the SummHay paper.
CoPilot
TigerGraph CoPilot is an AI assistant that combines graph databases and generative AI to enhance productivity across various business functions. It includes three core component services: InquiryAI for natural language assistance, SupportAI for knowledge Q&A, and QueryAI for GSQL code generation. Users can interact with CoPilot through a chat interface on TigerGraph Cloud and APIs. CoPilot requires LLM services for beta but will support TigerGraph's LLM in future releases. It aims to improve contextual relevance and accuracy of answers to natural-language questions by building knowledge graphs and using RAG. CoPilot is extensible and can be configured with different LLM providers, graph schemas, and LangChain tools.
llm-strategy
The 'llm-strategy' repository implements the Strategy Pattern using Large Language Models (LLMs) like OpenAI’s GPT-3. It provides a decorator 'llm_strategy' that connects to an LLM to implement abstract methods in interface classes. The package uses doc strings, type annotations, and method/function names as prompts for the LLM and can convert the responses back to Python data. It aims to automate the parsing of structured data by using LLMs, potentially reducing the need for manual Python code in the future.

xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.
chatmemory
ChatMemory is a simple yet powerful long-term memory manager that facilitates communication between AI and users. It organizes conversation data into history, summary, and knowledge entities, enabling quick retrieval of context and generation of clear, concise answers. The tool leverages vector search on summaries/knowledge and detailed history to provide accurate responses. It balances speed and accuracy by using lightweight retrieval and fallback detailed search mechanisms, ensuring efficient memory management and response generation beyond mere data retrieval.

empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.

ragtacts
Ragtacts is a Clojure library that allows users to easily interact with Large Language Models (LLMs) such as OpenAI's GPT-4. Users can ask questions to LLMs, create question templates, call Clojure functions in natural language, and utilize vector databases for more accurate answers. Ragtacts also supports RAG (Retrieval-Augmented Generation) method for enhancing LLM output by incorporating external data. Users can use Ragtacts as a CLI tool, API server, or through a RAG Playground for interactive querying.
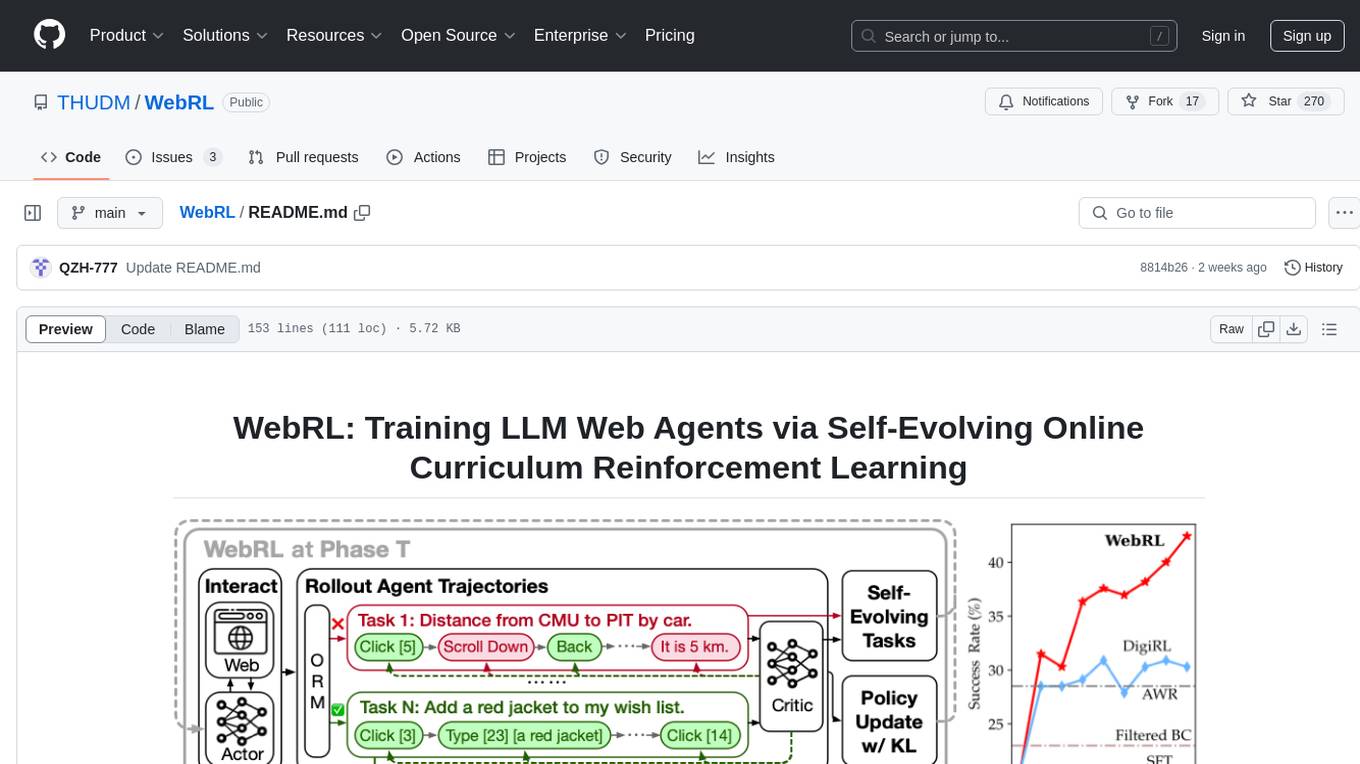
WebRL
WebRL is a self-evolving online curriculum learning framework designed for training web agents in the WebArena environment. It provides model checkpoints, training instructions, and evaluation processes for training the actor and critic models. The tool enables users to generate new instructions and interact with WebArena to configure tasks for training and evaluation.
structured-logprobs
This Python library enhances OpenAI chat completion responses by providing detailed information about token log probabilities. It works with OpenAI Structured Outputs to ensure model-generated responses adhere to a JSON Schema. Developers can analyze and incorporate token-level log probabilities to understand the reliability of structured data extracted from OpenAI models.

Toolio
Toolio is an OpenAI-like HTTP server API implementation that supports structured LLM response generation, making it conform to a JSON schema. It is useful for reliable tool calling and agentic workflows based on schema-driven output. Toolio is based on the MLX framework for Apple Silicon, specifically M1/M2/M3/M4 Macs. It allows users to host MLX-format LLMs for structured output queries and provides a command line client for easier usage of tools. The tool also supports multiple tool calls and the creation of custom tools for specific tasks.

awadb
AwaDB is an AI native database designed for embedding vectors. It simplifies database usage by eliminating the need for schema definition and manual indexing. The system ensures real-time search capabilities with millisecond-level latency. Built on 5 years of production experience with Vearch, AwaDB incorporates best practices from the community to offer stability and efficiency. Users can easily add and search for embedded sentences using the provided client libraries or RESTful API.

invariant
Invariant Analyzer is an open-source scanner designed for LLM-based AI agents to find bugs, vulnerabilities, and security threats. It scans agent execution traces to identify issues like looping behavior, data leaks, prompt injections, and unsafe code execution. The tool offers a library of built-in checkers, an expressive policy language, data flow analysis, real-time monitoring, and extensible architecture for custom checkers. It helps developers debug AI agents, scan for security violations, and prevent security issues and data breaches during runtime. The analyzer leverages deep contextual understanding and a purpose-built rule matching engine for security policy enforcement.
superpipe
Superpipe is a lightweight framework designed for building, evaluating, and optimizing data transformation and data extraction pipelines using LLMs. It allows users to easily combine their favorite LLM libraries with Superpipe's building blocks to create pipelines tailored to their unique data and use cases. The tool facilitates rapid prototyping, evaluation, and optimization of end-to-end pipelines for tasks such as classification and evaluation of job departments based on work history. Superpipe also provides functionalities for evaluating pipeline performance, optimizing parameters for cost, accuracy, and speed, and conducting grid searches to experiment with different models and prompts.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.

CEO-Agentic-AI-Framework
CEO-Agentic-AI-Framework is an ultra-lightweight Agentic AI framework based on the ReAct paradigm. It supports mainstream LLMs and is stronger than Swarm. The framework allows users to build their own agents, assign tasks, and interact with them through a set of predefined abilities. Users can customize agent personalities, grant and deprive abilities, and assign queries for specific tasks. CEO also supports multi-agent collaboration scenarios, where different agents with distinct capabilities can work together to achieve complex tasks. The framework provides a quick start guide, examples, and detailed documentation for seamless integration into research projects.
fluid-db
FluidDB is a research repository focusing on the concept of a fluid database that dynamically updates its schema based on ingested data. It enables the creation of personalized AI agents with features like adaptive schema, flexible querying, and versatile data input. The tool allows for storing unstructured data in a structured form and supports natural language queries. It aims to revolutionize database management by providing a dynamic and intuitive approach to data storage and retrieval.
For similar tasks

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.
oio-sds
OpenIO SDS is a software solution for object storage, targeting very large-scale unstructured data volumes.
summary-of-a-haystack
This repository contains data and code for the experiments in the SummHay paper. It includes publicly released Haystacks in conversational and news domains, along with scripts for running the pipeline, visualizing results, and benchmarking automatic evaluation. The data structure includes topics, subtopics, insights, queries, retrievers, summaries, evaluation summaries, and documents. The pipeline involves scripts for retriever scores, summaries, and evaluation scores using GPT-4o. Visualization scripts are provided for compiling and visualizing results. The repository also includes annotated samples for benchmarking and citation information for the SummHay paper.
IntelliChat
IntelliChat is an open-source AI chatbot tool designed to accelerate the integration of multiple language models into chatbot apps. Users can select their preferred AI provider and model from the UI, manage API keys, and access data using Intellinode. The tool is built with Intellinode and Next.js, and supports various AI providers such as OpenAI ChatGPT, Google Gemini, Azure Openai, Cohere Coral, Replicate, Mistral AI, Anthropic, and vLLM. It offers a user-friendly interface for developers to easily incorporate AI capabilities into their chatbot applications.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.
zep
Zep is a long-term memory service for AI Assistant apps. With Zep, you can provide AI assistants with the ability to recall past conversations, no matter how distant, while also reducing hallucinations, latency, and cost. Zep persists and recalls chat histories, and automatically generates summaries and other artifacts from these chat histories. It also embeds messages and summaries, enabling you to search Zep for relevant context from past conversations. Zep does all of this asyncronously, ensuring these operations don't impact your user's chat experience. Data is persisted to database, allowing you to scale out when growth demands. Zep also provides a simple, easy to use abstraction for document vector search called Document Collections. This is designed to complement Zep's core memory features, but is not designed to be a general purpose vector database. Zep allows you to be more intentional about constructing your prompt: 1. automatically adding a few recent messages, with the number customized for your app; 2. a summary of recent conversations prior to the messages above; 3. and/or contextually relevant summaries or messages surfaced from the entire chat session. 4. and/or relevant Business data from Zep Document Collections.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.
mslearn-ai-language
This repository contains lab files for Azure AI Language modules. It provides hands-on exercises and resources for learning about various AI language technologies on the Azure platform. The labs cover topics such as natural language processing, text analytics, language understanding, and more. By following the exercises in this repository, users can gain practical experience in implementing AI language solutions using Azure services.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.