
llm-strategy
Directly Connecting Python to LLMs via Strongly-Typed Functions, Dataclasses, Interfaces & Generic Types
Stars: 393
The 'llm-strategy' repository implements the Strategy Pattern using Large Language Models (LLMs) like OpenAI’s GPT-3. It provides a decorator 'llm_strategy' that connects to an LLM to implement abstract methods in interface classes. The package uses doc strings, type annotations, and method/function names as prompts for the LLM and can convert the responses back to Python data. It aims to automate the parsing of structured data by using LLMs, potentially reducing the need for manual Python code in the future.
README:




Implementing the Strategy Pattern using LLMs.
Also, please see https://blog.blackhc.net/2022/12/llm_software_engineering/ for a wider perspective on why this could be important in the future.
This package adds a decorator llm_strategy that connects to an LLM (such as OpenAI’s GPT-3) and uses the LLM to "implement" abstract methods in interface classes. It does this by forwarding requests to the LLM and converting the responses back to Python data using Python's @dataclasses.
It uses the doc strings, type annotations, and method/function names as prompts for the LLM, and can automatically convert the results back into Python types (currently only supporting @dataclasses). It can also extract a data schema to send to the LLM for interpretation. While the llm-strategy package still relies on some Python code, it has the potential to reduce the need for this code in the future by using additional, cheaper LLMs to automate the parsing of structured data.
- Github repository: https://github.com/blackhc/llm-strategy/
- Documentation https://blackhc.github.io/llm-strategy/
The latest version also includes a package for hyperparameter tracking and collecting traces from LLMs.
This for example allows for meta optimization. See examples/research for a simple implementation using Generics.
You can find an example WandB trace at: https://wandb.ai/blackhc/blackboard-pagi/reports/Meta-Optimization-Example-Trace--Vmlldzo3MDMxODEz?accessToken=p9hubfskmq1z5yj1uz7wx1idh304diiernp7pjlrjrybpaozlwv3dnitjt7vni1j
The prompts showing off the pattern using Generics are straightforward:
T_TaskParameters = TypeVar("T_TaskParameters")
T_TaskResults = TypeVar("T_TaskResults")
T_Hyperparameters = TypeVar("T_Hyperparameters")
class TaskRun(GenericModel, Generic[T_TaskParameters, T_TaskResults, T_Hyperparameters]):
"""
The task run. This is the 'data' we use to optimize the hyperparameters.
"""
task_parameters: T_TaskParameters = Field(..., description="The task parameters.")
hyperparameters: T_Hyperparameters = Field(
...,
description="The hyperparameters used for the task. We optimize these.",
)
all_chat_chains: dict = Field(..., description="The chat chains from the task execution.")
return_value: T_TaskResults | None = Field(
..., description="The results of the task. (None for exceptions/failure.)"
)
exception: list[str] | str | None = Field(..., description="Exception that occurred during the task execution.")
class TaskReflection(BaseModel):
"""
The reflections on the task.
This contains the lessons we learn from each task run to come up with better
hyperparameters to try.
"""
feedback: str = Field(
...,
description=(
"Only look at the final results field. Does its content satisfy the "
"task description and task parameters? Does it contain all the relevant "
"information from the all_chains and all_prompts fields? What could be improved "
"in the results?"
),
)
evaluation: str = Field(
...,
description=(
"The evaluation of the outputs given the task. Is the output satisfying? What is wrong? What is missing?"
),
)
hyperparameter_suggestion: str = Field(
...,
description="How we want to change the hyperparameters to improve the results. What could we try to change?",
)
hyperparameter_missing: str = Field(
...,
description=(
"What hyperparameters are missing to improve the results? What could "
"be changed that is not exposed via hyperparameters?"
),
)
class TaskInfo(GenericModel, Generic[T_TaskParameters, T_TaskResults, T_Hyperparameters]):
"""
The task run and the reflection on the experiment.
"""
task_parameters: T_TaskParameters = Field(..., description="The task parameters.")
hyperparameters: T_Hyperparameters = Field(
...,
description="The hyperparameters used for the task. We optimize these.",
)
reflection: TaskReflection = Field(..., description="The reflection on the task.")
class OptimizationInfo(GenericModel, Generic[T_TaskParameters, T_TaskResults, T_Hyperparameters]):
"""
The optimization information. This is the data we use to optimize the
hyperparameters.
"""
older_task_summary: str | None = Field(
None,
description=(
"A summary of previous experiments and the proposed changes with "
"the goal of avoiding trying the same changes repeatedly."
),
)
task_infos: list[TaskInfo[T_TaskParameters, T_TaskResults, T_Hyperparameters]] = Field(
..., description="The most recent tasks we have run and our reflections on them."
)
best_hyperparameters: T_Hyperparameters = Field(..., description="The best hyperparameters we have found so far.")
class OptimizationStep(GenericModel, Generic[T_TaskParameters, T_TaskResults, T_Hyperparameters]):
"""
The next optimization steps. New hyperparameters we want to try experiments and new
task parameters we want to evaluate on given the previous experiments.
"""
best_hyperparameters: T_Hyperparameters = Field(
...,
description="The best hyperparameters we have found so far given task_infos and history.",
)
suggestion: str = Field(
...,
description=(
"The suggestions for the next experiments. What could we try to "
"change? We will try several tasks next and several sets of hyperparameters. "
"Let's think step by step."
),
)
task_parameters_suggestions: list[T_TaskParameters] = Field(
...,
description="The task parameters we want to try next.",
hint_min_items=1,
hint_max_items=4,
)
hyperparameter_suggestions: list[T_Hyperparameters] = Field(
...,
description="The hyperparameters we want to try next.",
hint_min_items=1,
hint_max_items=2,
)
class ImprovementProbability(BaseModel):
considerations: list[str] = Field(..., description="The considerations for potential improvements.")
probability: float = Field(..., description="The probability of improvement.")
class LLMOptimizer:
@llm_explicit_function
@staticmethod
def reflect_on_task_run(
language_model,
task_run: TaskRun[T_TaskParameters, T_TaskResults, T_Hyperparameters],
) -> TaskReflection:
"""
Reflect on the results given the task parameters and hyperparameters.
This contains the lessons we learn from each task run to come up with better
hyperparameters to try.
"""
raise NotImplementedError()
@llm_explicit_function
@staticmethod
def summarize_optimization_info(
language_model,
optimization_info: OptimizationInfo[T_TaskParameters, T_TaskResults, T_Hyperparameters],
) -> str:
"""
Summarize the optimization info. We want to preserve all relevant knowledge for
improving the hyperparameters in the future. All information from previous
experiments will be forgotten except for what this summary.
"""
raise NotImplementedError()
@llm_explicit_function
@staticmethod
def suggest_next_optimization_step(
language_model,
optimization_info: OptimizationInfo[T_TaskParameters, T_TaskResults, T_Hyperparameters],
) -> OptimizationStep[T_TaskParameters, T_TaskResults, T_Hyperparameters]:
"""
Suggest the next optimization step.
"""
raise NotImplementedError()
@llm_explicit_function
@staticmethod
def probability_for_improvement(
language_model,
optimization_info: OptimizationInfo[T_TaskParameters, T_TaskResults, T_Hyperparameters],
) -> ImprovementProbability:
"""
Return the probability for improvement (between 0 and 1).
This is your confidence that your next optimization steps will improve the
hyperparameters given the information provided. If you think that the
information available is unlikely to lead to better hyperparameters, return 0.
If you think that the information available is very likely to lead to better
hyperparameters, return 1. Be concise.
"""
raise NotImplementedError()from dataclasses import dataclass
from llm_strategy import llm_strategy
from langchain.llms import OpenAI
@llm_strategy(OpenAI(max_tokens=256))
@dataclass
class Customer:
key: str
first_name: str
last_name: str
birthdate: str
address: str
@property
def age(self) -> int:
"""Return the current age of the customer.
This is a computed property based on `birthdate` and the current year (2022).
"""
raise NotImplementedError()
@dataclass
class CustomerDatabase:
customers: list[Customer]
def find_customer_key(self, query: str) -> list[str]:
"""Find the keys of the customers that match a natural language query best (sorted by closeness to the match).
We support semantic queries instead of SQL, so we can search for things like
"the customer that was born in 1990".
Args:
query: Natural language query
Returns:
The index of the best matching customer in the database.
"""
raise NotImplementedError()
def load(self):
"""Load the customer database from a file."""
raise NotImplementedError()
def store(self):
"""Store the customer database to a file."""
raise NotImplementedError()
@llm_strategy(OpenAI(max_tokens=1024))
@dataclass
class MockCustomerDatabase(CustomerDatabase):
def load(self):
self.customers = self.create_mock_customers(10)
def store(self):
pass
@staticmethod
def create_mock_customers(num_customers: int = 1) -> list[Customer]:
"""
Create mock customers with believable data (our customers are world citizens).
"""
raise NotImplementedError()See examples/mock_app/customer_database_search.py for a full example.



Clone the repository first. Then, install the environment and the pre-commit hooks with
make installThe CI/CD pipeline will be triggered when you open a pull request, merge to main, or when you create a new release.
To finalize the set-up for publishing to PyPi or Artifactory, see here. For activating the automatic documentation with MkDocs, see here. To enable the code coverage reports, see here.
- Create an API Token on Pypi.
- Add the API Token to your projects secrets with the name
PYPI_TOKENby visiting this page. - Create a new release on Github.
Create a new tag in the form
*.*.*.
For more details, see here.
Repository initiated with fpgmaas/cookiecutter-poetry.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-strategy
Similar Open Source Tools
llm-strategy
The 'llm-strategy' repository implements the Strategy Pattern using Large Language Models (LLMs) like OpenAI’s GPT-3. It provides a decorator 'llm_strategy' that connects to an LLM to implement abstract methods in interface classes. The package uses doc strings, type annotations, and method/function names as prompts for the LLM and can convert the responses back to Python data. It aims to automate the parsing of structured data by using LLMs, potentially reducing the need for manual Python code in the future.

xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.
chatmemory
ChatMemory is a simple yet powerful long-term memory manager that facilitates communication between AI and users. It organizes conversation data into history, summary, and knowledge entities, enabling quick retrieval of context and generation of clear, concise answers. The tool leverages vector search on summaries/knowledge and detailed history to provide accurate responses. It balances speed and accuracy by using lightweight retrieval and fallback detailed search mechanisms, ensuring efficient memory management and response generation beyond mere data retrieval.

airflow-ai-sdk
This repository contains an SDK for working with LLMs from Apache Airflow, based on Pydantic AI. It allows users to call LLMs and orchestrate agent calls directly within their Airflow pipelines using decorator-based tasks. The SDK leverages the familiar Airflow `@task` syntax with extensions like `@task.llm`, `@task.llm_branch`, and `@task.agent`. Users can define tasks that call language models, orchestrate multi-step AI reasoning, change the control flow of a DAG based on LLM output, and support various models in the Pydantic AI library. The SDK is designed to integrate LLM workflows into Airflow pipelines, from simple LLM calls to complex agentic workflows.

langevals
LangEvals is an all-in-one Python library for testing and evaluating LLM models. It can be used in notebooks for exploration, in pytest for writing unit tests, or as a server API for live evaluations and guardrails. The library is modular, with 20+ evaluators including Ragas for RAG quality, OpenAI Moderation, and Azure Jailbreak detection. LangEvals powers LangWatch evaluations and provides tools for batch evaluations on notebooks and unit test evaluations with PyTest. It also offers LangEvals evaluators for LLM-as-a-Judge scenarios and out-of-the-box evaluators for language detection and answer relevancy checks.
backtrack_sampler
Backtrack Sampler is a framework for experimenting with custom sampling algorithms that can backtrack the latest generated tokens. It provides a simple and easy-to-understand codebase for creating new sampling strategies. Users can implement their own strategies by creating new files in the `/strategy` directory. The repo includes examples for usage with llama.cpp and transformers, showcasing different strategies like Creative Writing, Anti-slop, Debug, Human Guidance, Adaptive Temperature, and Replace. The goal is to encourage experimentation and customization of backtracking algorithms for language models.
superpipe
Superpipe is a lightweight framework designed for building, evaluating, and optimizing data transformation and data extraction pipelines using LLMs. It allows users to easily combine their favorite LLM libraries with Superpipe's building blocks to create pipelines tailored to their unique data and use cases. The tool facilitates rapid prototyping, evaluation, and optimization of end-to-end pipelines for tasks such as classification and evaluation of job departments based on work history. Superpipe also provides functionalities for evaluating pipeline performance, optimizing parameters for cost, accuracy, and speed, and conducting grid searches to experiment with different models and prompts.
Tools4AI
Tools4AI is a Java-based Agentic Framework for building AI agents to integrate with enterprise Java applications. It enables the conversion of natural language prompts into actionable behaviors, streamlining user interactions with complex systems. By leveraging AI capabilities, it enhances productivity and innovation across diverse applications. The framework allows for seamless integration of AI with various systems, such as customer service applications, to interpret user requests, trigger actions, and streamline workflows. Prompt prediction anticipates user actions based on input prompts, enhancing user experience by proactively suggesting relevant actions or services based on context.

empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.

kor
Kor is a prototype tool designed to help users extract structured data from text using Language Models (LLMs). It generates prompts, sends them to specified LLMs, and parses the output. The tool works with the parsing approach and is integrated with the LangChain framework. Kor is compatible with pydantic v2 and v1, and schema is typed checked using pydantic. It is primarily used for extracting information from text based on provided reference examples and schema documentation. Kor is designed to work with all good-enough LLMs regardless of their support for function/tool calling or JSON modes.
ai-dev-2024-ml-workshop
The 'ai-dev-2024-ml-workshop' repository contains materials for the Deploy and Monitor ML Pipelines workshop at the AI_dev 2024 conference in Paris, focusing on deployment designs of machine learning pipelines using open-source applications and free-tier tools. It demonstrates automating data refresh and forecasting using GitHub Actions and Docker, monitoring with MLflow and YData Profiling, and setting up a monitoring dashboard with Quarto doc on GitHub Pages.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

ragtacts
Ragtacts is a Clojure library that allows users to easily interact with Large Language Models (LLMs) such as OpenAI's GPT-4. Users can ask questions to LLMs, create question templates, call Clojure functions in natural language, and utilize vector databases for more accurate answers. Ragtacts also supports RAG (Retrieval-Augmented Generation) method for enhancing LLM output by incorporating external data. Users can use Ragtacts as a CLI tool, API server, or through a RAG Playground for interactive querying.

instructor-js
Instructor is a Typescript library for structured extraction in Typescript, powered by llms, designed for simplicity, transparency, and control. It stands out for its simplicity, transparency, and user-centric design. Whether you're a seasoned developer or just starting out, you'll find Instructor's approach intuitive and steerable.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.

Toolio
Toolio is an OpenAI-like HTTP server API implementation that supports structured LLM response generation, making it conform to a JSON schema. It is useful for reliable tool calling and agentic workflows based on schema-driven output. Toolio is based on the MLX framework for Apple Silicon, specifically M1/M2/M3/M4 Macs. It allows users to host MLX-format LLMs for structured output queries and provides a command line client for easier usage of tools. The tool also supports multiple tool calls and the creation of custom tools for specific tasks.
For similar tasks

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
llm-strategy
The 'llm-strategy' repository implements the Strategy Pattern using Large Language Models (LLMs) like OpenAI’s GPT-3. It provides a decorator 'llm_strategy' that connects to an LLM to implement abstract methods in interface classes. The package uses doc strings, type annotations, and method/function names as prompts for the LLM and can convert the responses back to Python data. It aims to automate the parsing of structured data by using LLMs, potentially reducing the need for manual Python code in the future.
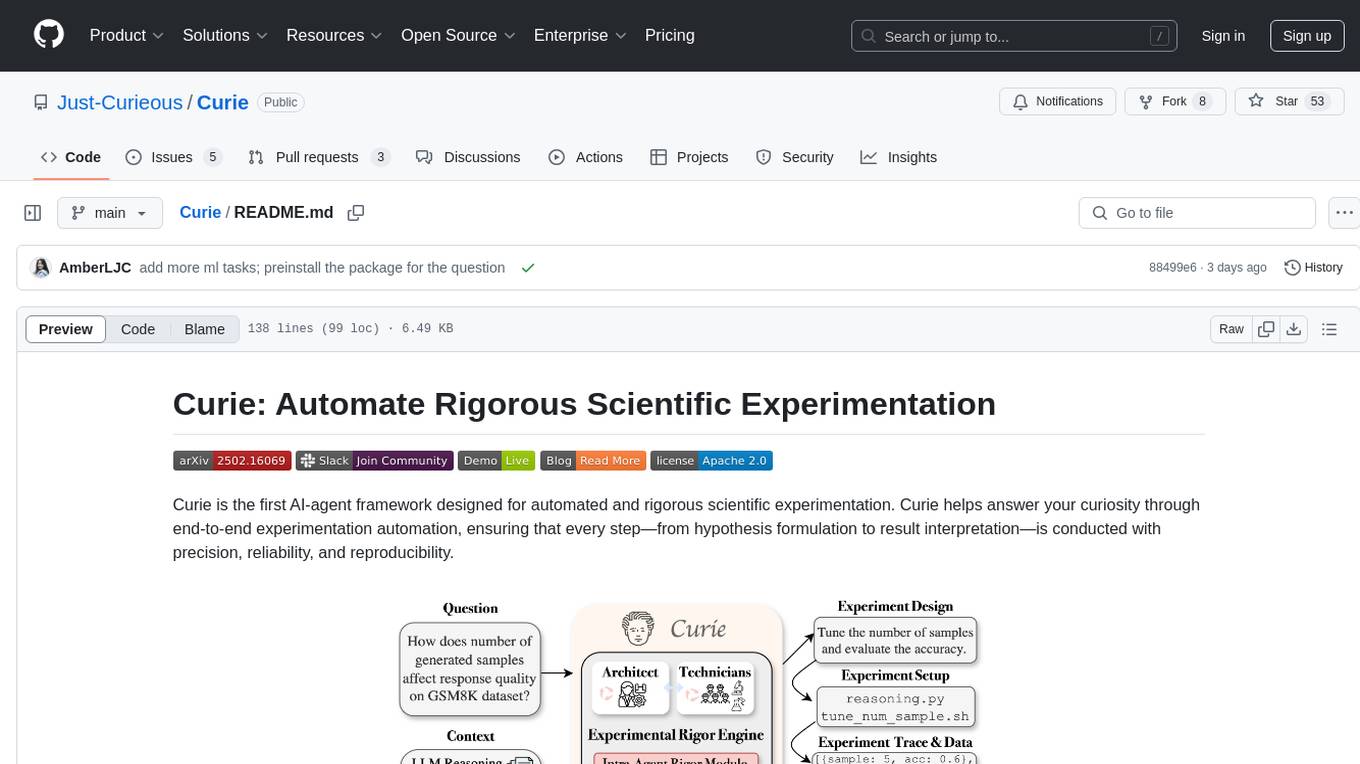
Curie
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.

ml-retreat
ML-Retreat is a comprehensive machine learning library designed to simplify and streamline the process of building and deploying machine learning models. It provides a wide range of tools and utilities for data preprocessing, model training, evaluation, and deployment. With ML-Retreat, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to optimize their models. The library is built with a focus on scalability, performance, and ease of use, making it suitable for both beginners and experienced machine learning practitioners.
sdk
The Kubeflow SDK is a set of unified Pythonic APIs that simplify running AI workloads at any scale without needing to learn Kubernetes. It offers consistent APIs across the Kubeflow ecosystem, enabling users to focus on building AI applications rather than managing complex infrastructure. The SDK provides a unified experience, simplifies AI workloads, is built for scale, allows rapid iteration, and supports local development without a Kubernetes cluster.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.