
xFinder
[ICLR 2025] xFinder: Large Language Models as Automated Evaluators for Reliable Evaluation
Stars: 153

xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.
README:
Qingchen Yu1,*, Zifan Zheng1,*, Shichao Song2,*, Zhiyu Li1,†, Feiyu Xiong1, Bo Tang1, Ding Chen1
1Institute for Advanced Algorithms Research, Shanghai, 2Renmin University of China
For business inquiries, please contact us at [email protected].
🎯 Who Should Pay Attention to Our Work?
- If you are developing a Benchmark, you can use our xFinder to replace traditional RegEx methods for extracting key answers from LLM responses. This will help you improve the accuracy of your evaluation results, enabling more reliable and meaningful comparisons and validation of model performance.
- If you are a designer of evaluation frameworks, you can integrate our xFinder into your framework's answer extraction component to enhance the robustness and reliability of the evaluation process.
[!IMPORTANT]
🌟 Star Us! By starring our project on GitHub, you'll receive all release notifications instantly. We appreciate your support!
- [2025/01] Our work has been accepted to ICLR 2025! 🎉🎉🎉
- [2024/10] We have open-sourced the KAF-Dataset and released xFinder as a PyPI package.
- [2024/09] xFinder has been successfully integrated into OpenCompass! 🔥🔥🔥
- [2024/08] We updated xFinder: The model now supports processing both English and Chinese.
- [2024/05] We released xFinder: Robust and Pinpoint Answer Extraction for Large Language Models. Check out the paper.
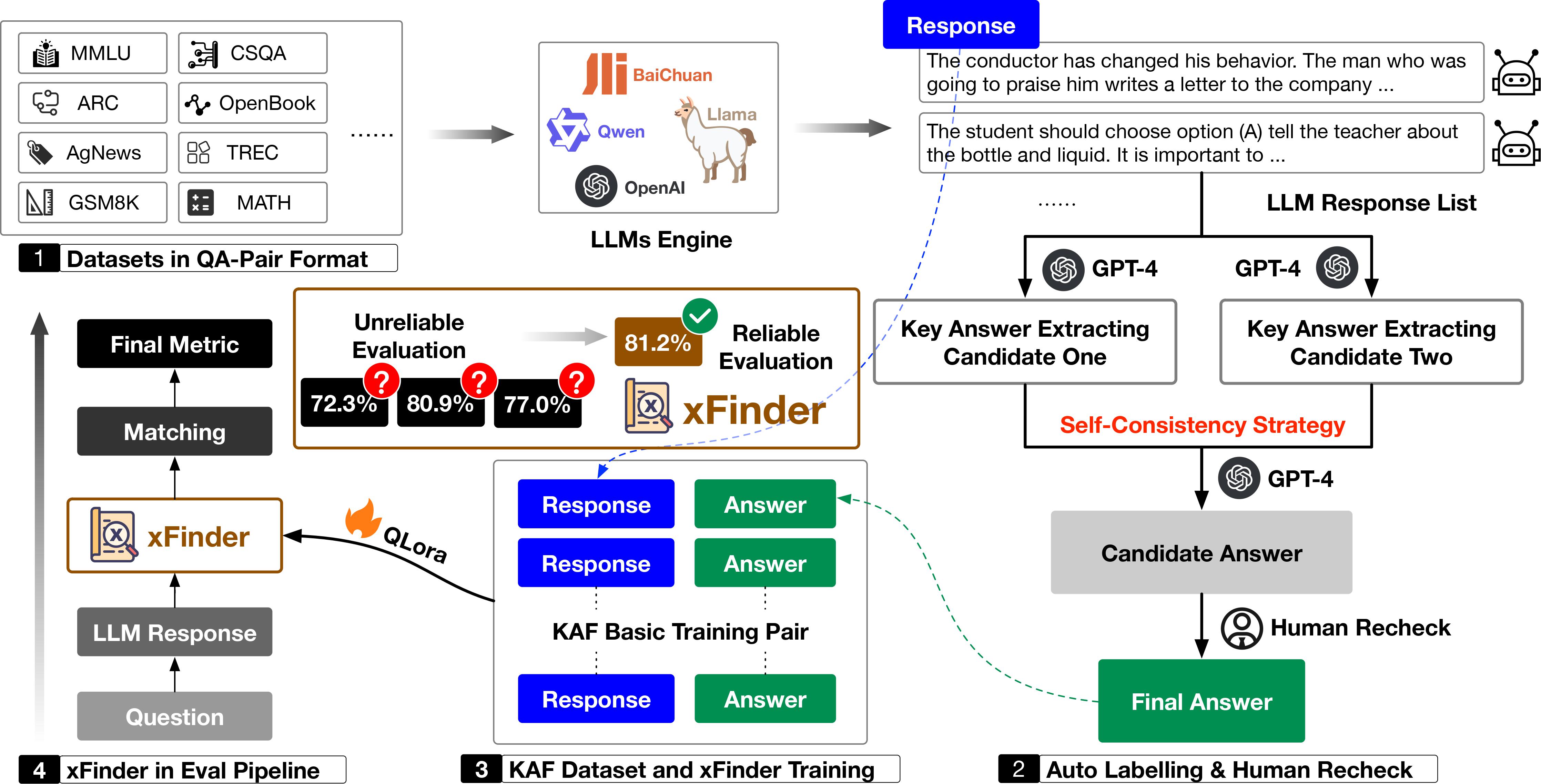
Abstract
The continuous advancement of large language models (LLMs) has brought increasing attention to the critical issue of developing fair and reliable methods for evaluating their performance. Particularly, the emergence of cheating phenomena, such as test set leakage and prompt format overfitting, poses significant challenges to the reliable evaluation of LLMs. As evaluation frameworks commonly use Regular Expression (RegEx) for answer extraction, models may adjust their responses to fit formats easily handled by RegEx. Nevertheless, the key answer extraction module based on RegEx frequently suffers from extraction errors. Furthermore, recent studies proposing fine-tuned LLMs as judge models for automated evaluation face challenges in terms of generalization ability and fairness. This paper comprehensively analyzes the entire LLM evaluation chain and demonstrates that optimizing the key answer extraction module improves extraction accuracy and enhances evaluation reliability. Our findings suggest that improving the key answer extraction module can lead to higher judgment accuracy and improved evaluation efficiency compared to the judge models. To address these issues, we propose xFinder, a novel evaluator for answer extraction and matching in LLM evaluation. As part of this process, we create a specialized dataset, the Key Answer Finder (KAF) dataset, to ensure effective model training and evaluation. Generalization tests and real-world evaluations show that the smallest xFinder model, with only 500 million parameters, achieves an average extraction accuracy of 93.42%. In contrast, RegEx accuracy in the best evaluation framework is 74.38%. The final judgment accuracy of xFinder reaches 97.61%, outperforming existing evaluation frameworks and judge models.We summarize our primary contributions as follows:
- We provide a comprehensive review of LLM evaluation processes in the industry, identifying critical factors that can lead to unreliable evaluation results.
- We introduce xFinder, a novel evaluator for answer extraction and matching in LLM evaluation, and construct the KAF dataset to support its training and testing.
- Our experiments show that both RegEx-based frameworks and automated judge models exhibit unreliability, leading to low judgment accuracy. In contrast, our method achieves higher accuracy and improved evaluation efficiency.

As shown in the figure, instances where evaluation frameworks such as LM Eval Harness and OpenCompass failed to extract key answers are illustrated. Specifically, A/T/C/M represent tasks with alphabet / short text / categorical label / math options, respectively.
-
Create Benchmark Dataset: To streamline the evaluation process using xFinder, we have standardized various mainstream benchmark datasets into a unified JSON format. For implementation details, refer to create_benchmark_dataset.py. If you wish to evaluate your own datasets using xFinder, please refer to our provided script template benchmark_dataset_template.py for format conversion guidance.
-
Prepare QA Pairs & LLM Outputs: Gather the LLM outputs you wish to evaluate. Ensure your data includes the following elements:
- Original question
- Key answer type (options: alphabet, short_text, categorical_label, math)
- LLM output
- Standard answer range
-
Deploy the xFinder Model: Select one of the following models for deployment:
After deploying the xFinder model, follow these steps to run an evaluation:
# Install xfinder
conda create -n xfinder_env python=3.10 -y
conda activate xfinder_env
pip install xfinder
# Perform an evaluation with xFinder (a built-in example)
CUDA_VISIBLE_DEVICES=0 python -m xfinder.eval --run-example --model-name xFinder-qwen1505 --inference-mode local --model-path-or-url /path/to/anonymized/model/xFinder-qwen1505📚 Batch Evaluation of Summarized Experimental Results
This method allows you to evaluate multiple examples stored in a JSON file.
# Initialize Evaluator object
evaluator = Evaluator(
model_name="xFinder-qwen1505", # Model name
inference_mode="api", # Inference mode, 'local' or 'api'
model_path_or_url="http://your-anonymized-url/generate", # Anonymized model path or URL
)
# Perform batch evaluation
data_path = "/path/to/your/data/example.json" # User needs to provide their own data path
accuracy = evaluator.evaluate(data_path)
print(f"Batch evaluation accuracy: {accuracy}")📄 Single-Instance Evaluation Mode
This method allows you to evaluate individual examples, which can be integrated into a LLM evaluation framework.
# Initialize Evaluator object
evaluator = Evaluator(
model_name="xFinder-qwen1505", # Model name
inference_mode="local", # Inference mode, 'local' or 'api'
model_path_or_url="IAAR-Shanghai/xFinder-qwen1505", # Anonymized model path or URL
)
# Define input for a single evaluation
question = "What is the capital of France?"
llm_output = "The capital of France is Paris."
standard_answer_range = "[\"Paris\", \"Lyon\", \"Marseille\"]"
key_answer_type = "short_text"
correct_answer = "Paris"
# Perform single example evaluation
result = evaluator.evaluate_single_example(
question,
llm_output,
standard_answer_range,
key_answer_type,
correct_answer
)[!Tip]
- Refer to
demo.ipynbfor more detailed examples.- Run
export HF_ENDPOINT=https://hf-mirror.comto use the Chinese mirror if you cannot connect to Hugging Face.- xFinder currently supports loading via the API method deployed by vllm.
- We provide scripts for fine-tuning xFinder in xfinder_training.
We demonstrate instances across four types of questions where RegEx fails to extract or frequently extracts incorrect answers, whereas xFinder accurately extracts the key answers.
{
"key_answer_type": "alphabet option",
"question": "A man is seen playing guitar on a stage with others playing instruments behind him. The man grabs a guitar from the audience and begins playing both one after the other ...",
"llm_output": "Option A is the correct choice as it describes ...",
"standard_answer_range": "[['A', 'strums the guitar in the end, continues playing the guitar with the crowd following him as well as lining up next to him.'], ['B', 'continues playing the instruments and ends by waving to the crowd and walking off stage.'], ['C', 'then turns to the audience and gives a stuffed toy to the audience and continues playing.'], ['D', 'finally stops playing and moves his hands for the crowd to see.']]",
"gold_label": "A",
"xFinder_output": "A",
},
{
"key_answer_type": "short text",
"question": "If you really wanted a grape, where would you go to get it? Answer Choices: winery / fruit stand / field / kitchen / food",
"llm_output": "The answer is winery / fruit stand / field / kitchen / food ...",
"standard_answer_range": "[\"winery\", \"fruit stand\", \"field\", \"kitchen\", \"food\"]",
"gold_label": "[No valid answer]",
"xFinder_output": "[No valid answer]",
},
{
"key_answer_type": "categorical label",
"question": "How tall is the Sears Building ?",
"llm_output": "The Sears Building is a specific structure, so the answer would be a Location ...",
"standard_answer_range": "['Abbreviation', 'Entity', 'Description', 'Person', 'Location', 'Number']",
"gold_label": "Location",
"xFinder_output": "Location",
},
{
"key_answer_type": "math",
"question": " Mike made 69 dollars mowing lawns over the summer. If he spent 24 dollars buying new mower blades, how many 5 dollar games could he buy with the money he had left? ",
"llm_output": "To find out how many 5 dollar ... Let's calculate that:\n\n$45 / $5 = 9\n\nSo, Mike could buy 9 5 dollar games with the money he had left.",
"standard_answer_range": "a(n) number / set / vector / matrix / interval / expression / function / equation / inequality",
"gold_label": "9",
"xFinder_output": "9",
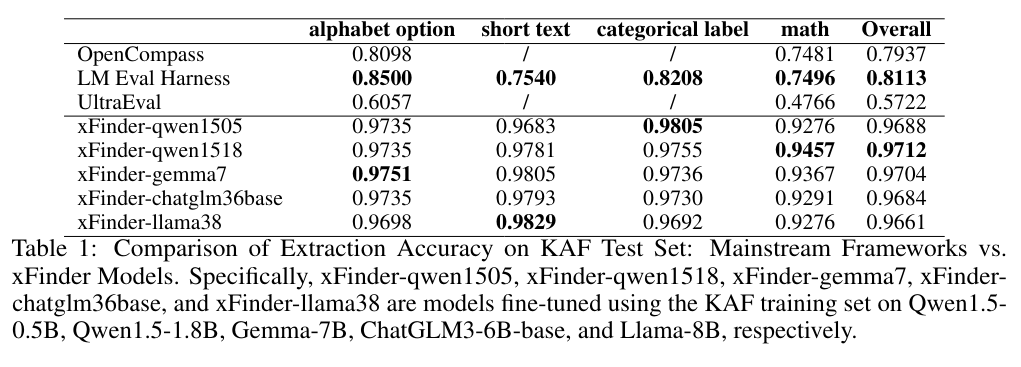
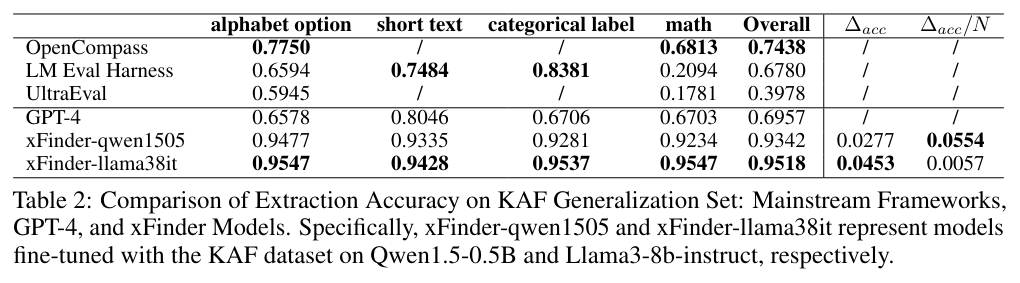
}Baseline: OpenCompass, LM Eval Harness, UltraEval, GPT-4. Our Method: xFinder-qwen1505, xFinder-qwen1518, xFinder-gemma7, xFinder-chatglm36base, xFinder-llama38, xFinder-llama38it.
We evaluated their accuracy in extracting key answers from both the KAF test set and generalization sets. The metric in the table is accuracy.
@inproceedings{
xFinder,
title={xFinder: Large Language Models as Automated Evaluators for Reliable Evaluation},
author={Qingchen Yu and Zifan Zheng and Shichao Song and Zhiyu li and Feiyu Xiong and Bo Tang and Ding Chen},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=7UqQJUKaLM}
}
Click me to show all TODOs
- [ ] feat: support quick replacement of RegEx in OpenCompass.
- [ ] feat: add additional example datasets to the xfinder PyPI package.
- [ ] feat: add model loading methods.
- [ ] docs: extend dataset construction documents.
- [ ] docs: add video tutorial.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for xFinder
Similar Open Source Tools
xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.
superpipe
Superpipe is a lightweight framework designed for building, evaluating, and optimizing data transformation and data extraction pipelines using LLMs. It allows users to easily combine their favorite LLM libraries with Superpipe's building blocks to create pipelines tailored to their unique data and use cases. The tool facilitates rapid prototyping, evaluation, and optimization of end-to-end pipelines for tasks such as classification and evaluation of job departments based on work history. Superpipe also provides functionalities for evaluating pipeline performance, optimizing parameters for cost, accuracy, and speed, and conducting grid searches to experiment with different models and prompts.
llm-strategy
The 'llm-strategy' repository implements the Strategy Pattern using Large Language Models (LLMs) like OpenAI’s GPT-3. It provides a decorator 'llm_strategy' that connects to an LLM to implement abstract methods in interface classes. The package uses doc strings, type annotations, and method/function names as prompts for the LLM and can convert the responses back to Python data. It aims to automate the parsing of structured data by using LLMs, potentially reducing the need for manual Python code in the future.
R-Judge
R-Judge is a benchmarking tool designed to evaluate the proficiency of Large Language Models (LLMs) in judging and identifying safety risks within diverse environments. It comprises 569 records of multi-turn agent interactions, covering 27 key risk scenarios across 5 application categories and 10 risk types. The tool provides high-quality curation with annotated safety labels and risk descriptions. Evaluation of 11 LLMs on R-Judge reveals the need for enhancing risk awareness in LLMs, especially in open agent scenarios. Fine-tuning on safety judgment is found to significantly improve model performance.
pipelex
Pipelex is an open-source devtool designed to transform how users build repeatable AI workflows. It acts as a Docker or SQL for AI operations, allowing users to create modular 'pipes' using different LLMs for structured outputs. These pipes can be connected sequentially, in parallel, or conditionally to build complex knowledge transformations from reusable components. With Pipelex, users can share and scale proven methods instantly, saving time and effort in AI workflow development.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.
chatmemory
ChatMemory is a simple yet powerful long-term memory manager that facilitates communication between AI and users. It organizes conversation data into history, summary, and knowledge entities, enabling quick retrieval of context and generation of clear, concise answers. The tool leverages vector search on summaries/knowledge and detailed history to provide accurate responses. It balances speed and accuracy by using lightweight retrieval and fallback detailed search mechanisms, ensuring efficient memory management and response generation beyond mere data retrieval.

Noema-Declarative-AI
Noema is a framework that enables developers to control a language model and choose the path it will follow. It integrates Python with llm's generations, allowing users to use LLM as a thought interpreter rather than a source of truth. Noema is built on llama.cpp and guidance's shoulders. It applies the declarative programming paradigm to a language model, providing a way to represent functions, descriptions, and transformations. Users can create subjects, think about tasks, and generate content through generators, selectors, and code generators. Noema supports ReAct prompting, visualization, and semantic Python functionalities, offering a versatile tool for automating tasks and guiding language models.
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.

axar
AXAR AI is a lightweight framework designed for building production-ready agentic applications using TypeScript. It aims to simplify the process of creating robust, production-grade LLM-powered apps by focusing on familiar coding practices without unnecessary abstractions or steep learning curves. The framework provides structured, typed inputs and outputs, familiar and intuitive patterns like dependency injection and decorators, explicit control over agent behavior, real-time logging and monitoring tools, minimalistic design with little overhead, model agnostic compatibility with various AI models, and streamed outputs for fast and accurate results. AXAR AI is ideal for developers working on real-world AI applications who want a tool that gets out of the way and allows them to focus on shipping reliable software.
flow-prompt
Flow Prompt is a dynamic library for managing and optimizing prompts for large language models. It facilitates budget-aware operations, dynamic data integration, and efficient load distribution. Features include CI/CD testing, dynamic prompt development, multi-model support, real-time insights, and prompt testing and evolution.
agentlang
AgentLang is an open-source programming language and framework designed for solving complex tasks with the help of AI agents. It allows users to build business applications rapidly from high-level specifications, making it more efficient than traditional programming languages. The language is data-oriented and declarative, with a syntax that is intuitive and closer to natural languages. AgentLang introduces innovative concepts such as first-class AI agents, graph-based hierarchical data model, zero-trust programming, declarative dataflow, resolvers, interceptors, and entity-graph-database mapping.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.
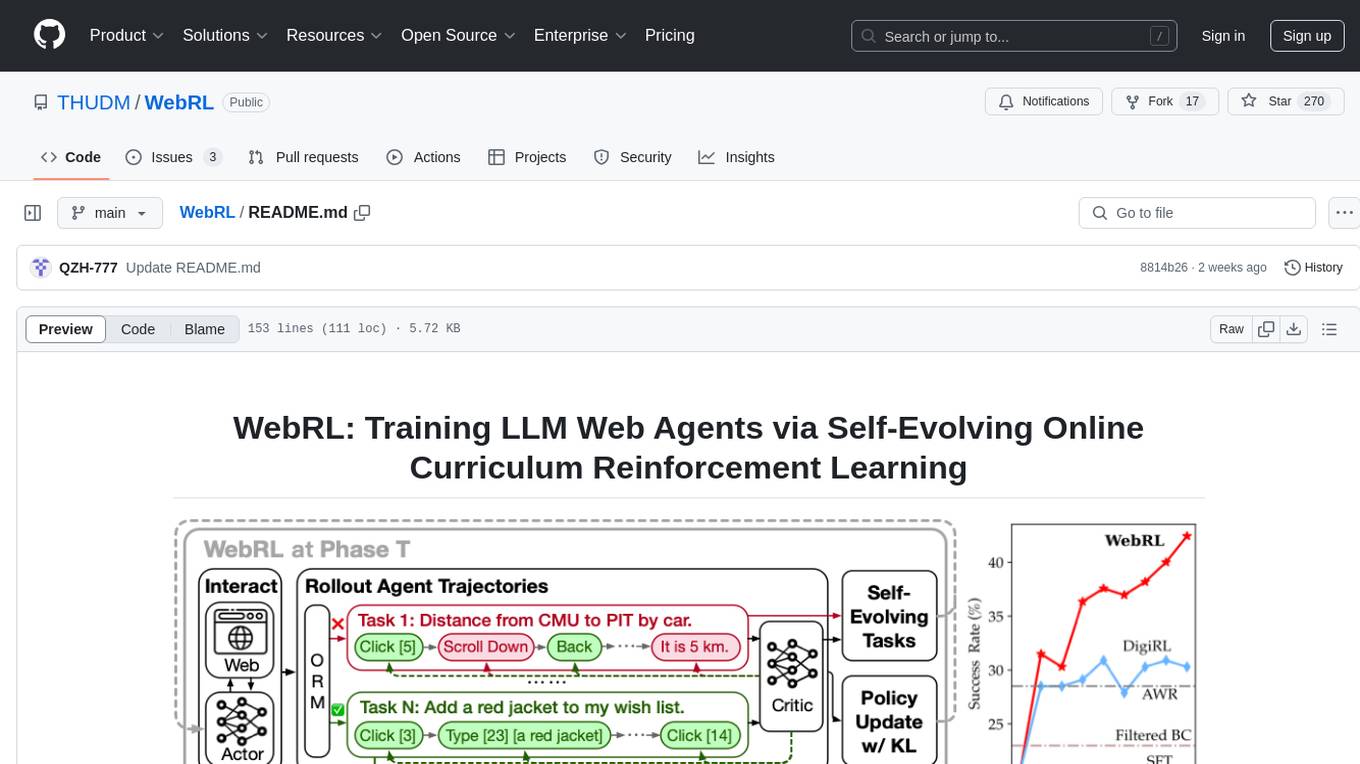
WebRL
WebRL is a self-evolving online curriculum learning framework designed for training web agents in the WebArena environment. It provides model checkpoints, training instructions, and evaluation processes for training the actor and critic models. The tool enables users to generate new instructions and interact with WebArena to configure tasks for training and evaluation.
For similar tasks
xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.

litgpt
LitGPT is a command-line tool designed to easily finetune, pretrain, evaluate, and deploy 20+ LLMs **on your own data**. It features highly-optimized training recipes for the world's most powerful open-source large-language-models (LLMs).

torchtune
Torchtune is a PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. It provides native-PyTorch implementations of popular LLMs using composable and modular building blocks, easy-to-use and hackable training recipes for popular fine-tuning techniques, YAML configs for easily configuring training, evaluation, quantization, or inference recipes, and built-in support for many popular dataset formats and prompt templates to help you quickly get started with training.
trulens
TruLens provides a set of tools for developing and monitoring neural nets, including large language models. This includes both tools for evaluation of LLMs and LLM-based applications with _TruLens-Eval_ and deep learning explainability with _TruLens-Explain_. _TruLens-Eval_ and _TruLens-Explain_ are housed in separate packages and can be used independently.

agenta
Agenta is an open-source LLM developer platform for prompt engineering, evaluation, human feedback, and deployment of complex LLM applications. It provides tools for prompt engineering and management, evaluation, human annotation, and deployment, all without imposing any restrictions on your choice of framework, library, or model. Agenta allows developers and product teams to collaborate in building production-grade LLM-powered applications in less time.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.
evals
Evals provide a framework for evaluating large language models (LLMs) or systems built using LLMs. We offer an existing registry of evals to test different dimensions of OpenAI models and the ability to write your own custom evals for use cases you care about. You can also use your data to build private evals which represent the common LLMs patterns in your workflow without exposing any of that data publicly.
Play-with-LLMs
This repository provides a comprehensive guide to training, evaluating, and building applications with Large Language Models (LLMs). It covers various aspects of LLMs, including pretraining, fine-tuning, reinforcement learning from human feedback (RLHF), and more. The repository also includes practical examples and code snippets to help users get started with LLMs quickly and easily.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.