
VedAstro
A non-profit, open source project to make Vedic Astrology easily available to all.
Stars: 279
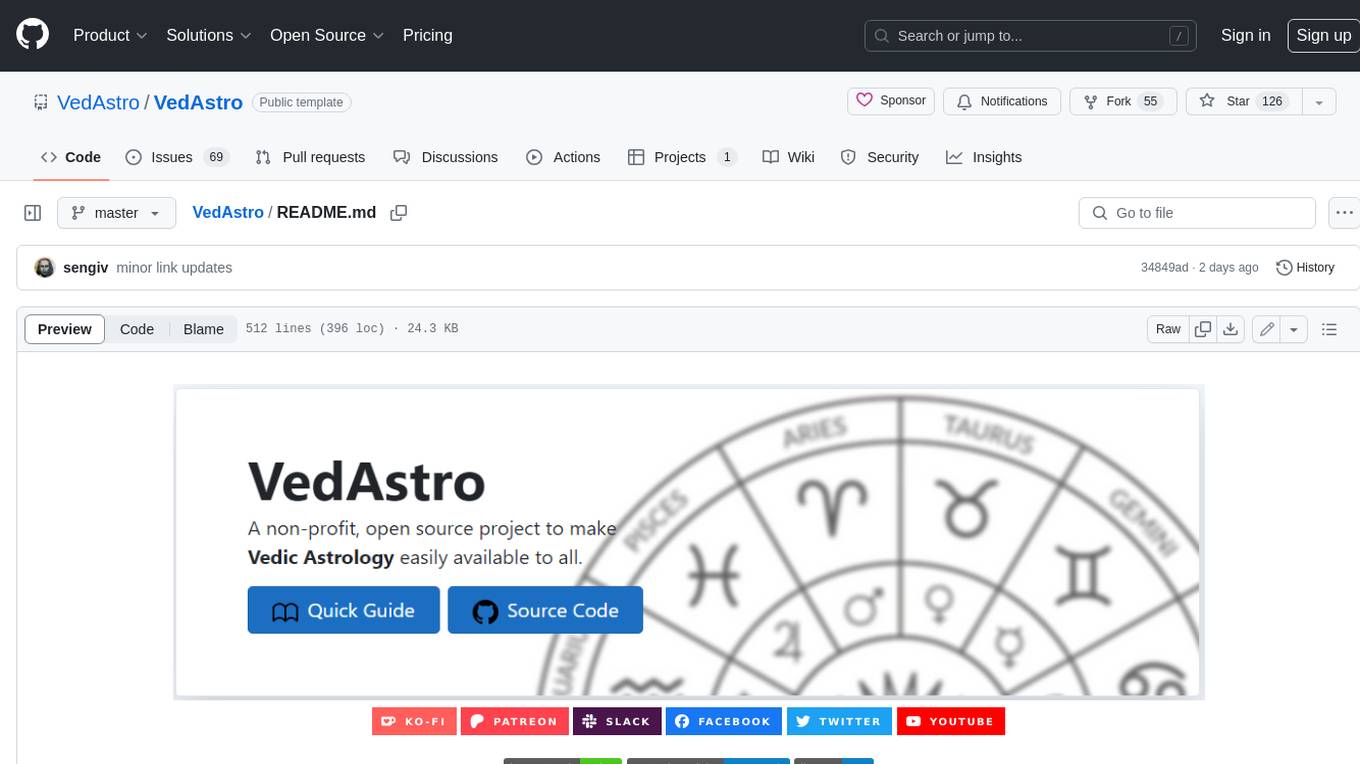
VedAstro is an open-source Vedic astrology tool that provides accurate astrological predictions and data. It offers a user-friendly website, a chat API, an open API, a JavaScript SDK, a Swiss Ephemeris API, and a machine learning table generator. VedAstro is free to use and is constantly being updated with new features and improvements.
README:







- Website --> easy & fast astrology data for normal users
- JavaScript SDK --> easy to use JS library to simplify API access and use
-
Learn Astro Computation --> learn exact math & logic used in astrology via
Free Open Sourcecode - Life Predictor --> accurate algorithmic prediction of a human life's past and future
- Build On Top --> import VedAstro code directly into your existing projects
- 15000 Famous People DOB --> Accurate birth dataset for Machine Learning & AI
- 15000 Famous People Marriage Info --> Accurate marriage/divorce dataset for Machine Learning & AI


The sage Parashara taught everybody the ways of astrology without asking money, as such VedAstro does the same.
Philosophy's the scaffold we use when we build,
Without it, a mud hut, not a structure fulfilled.
For creating grand codes, like VedAstro’s design,
Philosophy’s essential, its role is divine.
The purpose of VedAstro, we must understand,
Born of joy, in development it must stand.
This project thrives on happiness, pure and bright,
Don’t code till your heart feels the building's delight.
When your fingers can’t keep up, joy fills the air,
You’ll know that your code is placed right with care.
In the universe vast, it finds its own way,
Your work shines with brilliance, come what may.
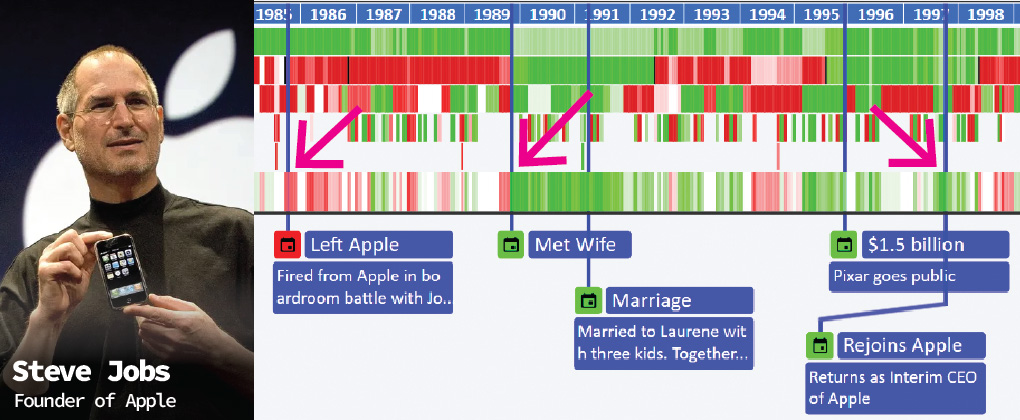
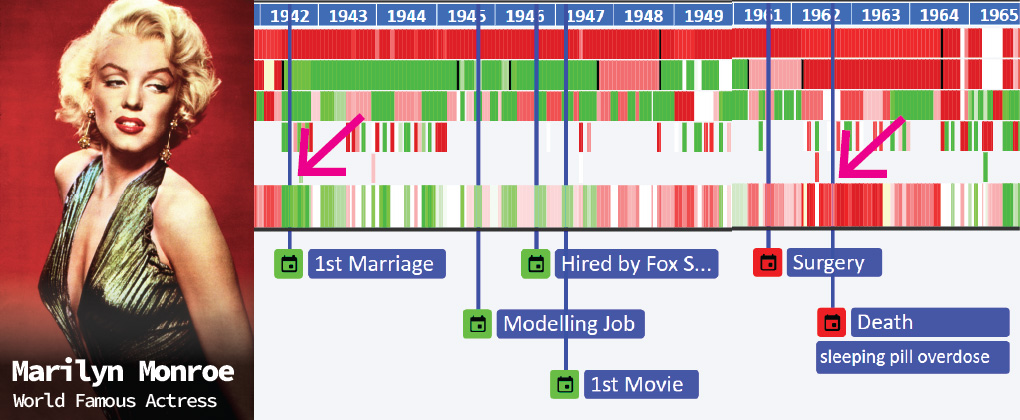
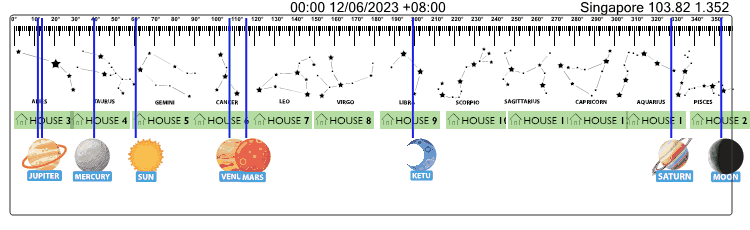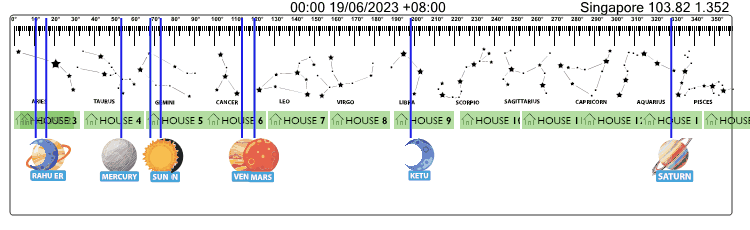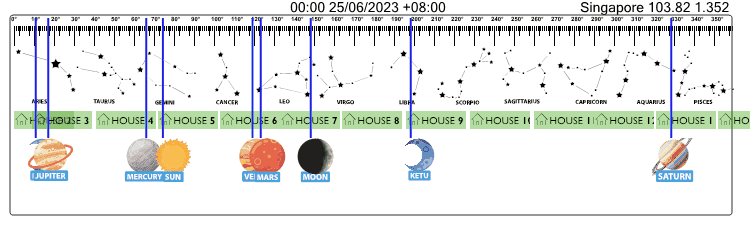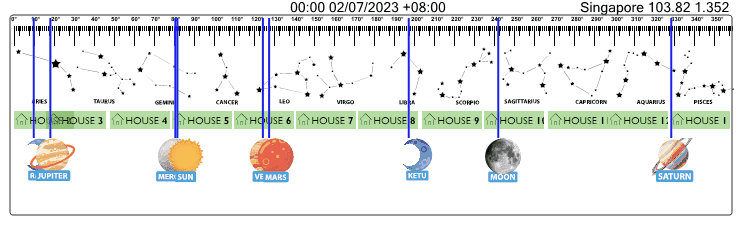
Below is sample API call result for data related to "Sun" on "30/06/2023" at "Singapore" --> Watch Video Guide --> JS Demo Files --> Demo API Call
"Payload": {
"SwissEphemeris": "{ Longitude = 97.672406549912, Latitude = 2.2248025536827577E-05, DistanceAU = 1.0165940297895264, SpeedLongitude = 0, SpeedLatitude = 0, SpeedDistance = 0 }",
"AbdaBala": "0",
"AspectedByMalefics": "False",
"AyanaBala": "118.071100045034",
"Benefic": "False",
"ChestaBala": "0",
"ConjunctWithMalefics": "True",
"Constellation": "Aridra - 3",
"Debilitated": "False",
"Declination": "23.2284400180136",
"DigBala": "5.222314814814815",
"Drekkana": "Libra",
"DrekkanaBala": "0",
"DrikBala": "4.883715277777782",
"Dwadasamsa": "Scorpio",
"Exalted": "False",
"HoraBala": "60",
"HousePlanetIsIn": "5",
"InKendra": "False",
"IsPlanetInOwnHouse": "False",
"IsPlanetStrongInShadvarga": "False",
"KalaBala": "200.68443337836732",
"KendraBala": "15",
"Malefic": "True",
"MasaBala": "0",
"Moolatrikona": "False",
"Motion": "Direct",
"NaisargikaBala": "60",
"NathonnathaBala": "5.709722222222221",
"Navamsa": "Aquarius",
"NirayanaLongitude": {
"DegreeMinuteSecond": "74° 56' 18",
"TotalDegrees": "74.93833333333333"
},
"OchchaBala": "38.35388888888889",
"OjayugmarasyamsaBala": "30",
"PakshaBala": "16.90361111111111",
"PlanetHoraSign": "Leo",
"PlanetsInConjuction": "Mercury",
"ReceivingAspectFrom": "",
"Saptamsa": "Virgo",
"SaptavargajaBala": "91.875",
"SayanaLatitude": {
"DegreeMinuteSecond": "0° 0' 0",
"TotalDegrees": "0"
},
"SayanaLongitude": {
"DegreeMinuteSecond": "97° 40' 20",
"TotalDegrees": "97.67222222222222"
},
"ShadbalaPinda": "446.02",
"ShadvargaBala": "88.125",
"Sign": {
"Name": "Gemini",
"DegreesIn": {
"DegreeMinuteSecond": "14° 56' 17",
"TotalDegrees": "14.938055555555556"
}
},
"SignsPlanetIsAspecting": "Sagittarius",
"Speed": "0.9533156649003025",
"SthanaBala": "175.2288888888889",
"TemporaryFriends": "Venus, Mars, Jupiter",
"Thrimsamsa": "Sagittarius",
"TotalStrength": "446.02",
"TransmittingAspectToHouse": "House11",
"TransmittingAspectToPlanet": "",
"TribhagaBala": "0",
"VaraBala": "0"
}Anybody who has studied Vedic Astrology knows well how accurate it can be. But also how complex it can get to make accurate predictions. It takes decades of experience to be able make accurate prediction. As such this knowledge only reaches a limited people. This project is an effort to change that. Read More
The first line of code for this project was written in late 2014 at Itä-Pasila. Started as a simple desktop software, with no UI and only text display. With continued support from users, this project has steadily grown to what it is today. Helping people from all over the world. 🌍

Thanks to B.V. Raman and his grandfather B. Suryanarain Rao for pioneering easy to read astrology books. Credit also goes to St. Jean-Baptiste de La Salle for proving the efficacy of free and open work for the benefit of all men...Read More.
This development style celebrates the methodology of chaotic development at the benefit of low cost and fast paced prototyping. Inspired by the concept of "Gonzo Journalism", pioneered by Hunter S. Thompson in the 1970s.
We favour this pattern for the development of VedAstro simply due to the volatile nature of this project. Other development styles like "Waterfall" and "Scrum" are equally good when the need is.
✅ We want to :
- 💓 try out novel ideas at a heartbeat
- 📬 we want the latest platform
- 💰 we want it cheap
Hence the "gonzo development" pattern is best suited for this needs.
We would like to introduce in this project a novel UX concept called "Drunk Proofing". The idea is simple. All UI is designed to be operated by an alcoholically intoxicated person aka drunk.
Why? Because this forces the team to make a simple and intuitive UI design. It is all too easy during development to make a complicated UI that only coders understand. But it is far more difficult and rewarding to make the UI intuitive & easy. A "no manuals" and "no brainer" approach to design.
The wisdom of ages, once passed down by word,
Now stored in circuits, rarely heard.
Once this knowledge was held in minds so keen,
Now it's coded in machines unseen.
The human touch, that once gave knowledge birth,
Replaced by algorithms, shaping future's girth.

Leslie Choi : Believed in the project even when work was only half done.

Swarn Siddhi : The makers of this awesome app keep this VedAstro project alive

JetBrains : Gave free "ReSharper License" that made coding life easier.
Just Like & Share our social pages and it'll be a big help already!
We discuss & share ideas on astrology and computation. And ways you can integrate VedAstro into your own project.

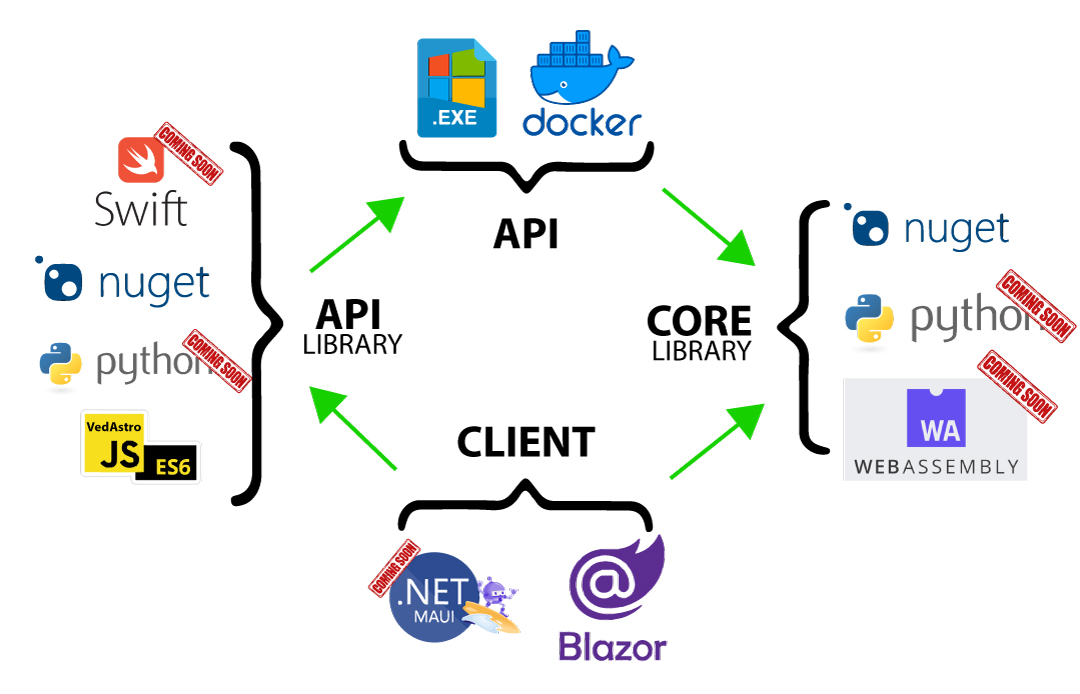
The main part of the program is the prediction/event generator. It works by combining logic on how to calculate a prediction with data about that prediction. This is done everytime a "Calculate" button is clicked. Below you will see a brief explanation of this process. This method was chosen to easily accommodate the thousands of astrological calculation possibilities.
CREATION OF AN EVENT/PREDICTION
STEP 1
Hard coded event data like name is stored in XML file.
A copy of the event name is stored as Enum to link
Calculator Methods with data from XML.
These static methods are the logic to check
if an event occurred. No astro calculation done at this stage.
This is the linking process of the logic and data.
-------+
|
+-----------------+ |
| Event Data (xml)| |
+-----------------+ |
+ |
+------------------+ |
|Event Names (Enum)| +-----> Event Data (Instance)
+------------------+ |
+ |
+------------------+ |
|Calculator Methods| |
+------------------+ |
|
------+
STEP 2
From the above step, list of Event Data is generated.
Is occuring logic of each Event Data is called with time slices,
generated from a start time & end time (inputed at runtime).
An Event is created if IsOccuring is true.
This's a merger of Time and EventData to create an
Event at a specific time. This Event is then used
throughout the program.
Event Data + Time Range
List List
|
|
|
v
Event List
+--------+ +------------------------+ +------------------+
| User | <------+ | Website | -------------> | API |
| | +------> | - Blazor WebAssembly | <------------- | -Azure Functions |
+--------+ GUI | - Azure Static WebApp | XML | |
| | | |
+------------------------+ +------------------+
all 3 independent, only linked in VS for easy access don't commit local referenced .csproj to Git as it'll be used by CI/CD
- Create a method in EventCalculatorMethods.cs
- Add the name in EventNames.cs
- Add the prediction/event details HoroscopeDataList.xml
- Edit in Genso.Astrology.Library EventTag enum. Change here reflects even in GUI
These are randomly ordered notes on why a feature was implemented in a certain way.
Will prove usefull when debugging & upgrading code.
Shows only clean & nice html index for bots from best known SEs
for direct access Blazor page via static storage without 404 error since no page actually exists at page url, blazor takes url and runs the page as app using rule engine this is possible rules also make sure not to redirect file & api access only page access
- not begins with "/api/"
- has a path
- Sec-Fetch-Mode = navigate
- Sec-Fetch-Dest = document
web : vedastro.org -> domain registra -> azure DNS -> azure cdn -> web blob storage api stable : api.vedastro.org -> domain registra -> azure DNS -> azure cdn -> stable api server (render) api beta : beta.api.vedastro.org -> domain registra -> azure DNS -> azure cdn -> beta api server (azure) domain cert managed by lets encyrpt acme bot azure func
via Azure CDN Rules Engine, this allows the use of api.vedastro.org/... & api.vedastro.org/nlp/...
Since not documented by BV. Raman, code here is created through experimentation by repeating relationship between Dasa planet & Bhukti planet.
Not all data regarding an event is hardwired. Generating gochara, antaram, sukshma and others is more effcient if description was created by Astronomical calculator At the moment EventDataList.xml is the source of truth, meaning if an event exists in xml file, then it must exist in code.
- Accessing events chart directly via API generated html
- CORS in Azure Website Storage needs to be disabled for this to work, outside of vedastro.org
The default timezone generated for all svg charts will be based on client timezone. Timezone does not matter when full life charts are made, but will matter alot when short term muhurtha charts are generated. Since most users are not living where they were born, it is only logical to default it client browser's timezone. This timezone must be visible/changeable to users who need to use otherwise.
- This feature is to store notes on the dasa report
- The notes are actualy Events converted to XML and stored inside each person's record
- When rendering these events are placed on top dasa report view
WEBSITE : Why astrological calculation done on API server and not in client (browser) via webassmebly?
- The calculations tested on Intel Xeon with parallel procesing takes about 1GB RAM & 30% CPU. With these loads browsers with mobile CPU's are going to be probelmatic for sure. So as not to waste time, the API route has been decided since it has been proven to work.
- There are places where all Astronomical computation is done in client, exp. Planet Info Box
-
Built on reference to, Hindu Predictive Astrology pg. 254
-
Asthavarga bindus are different from shadbala and it is to be implemented soon.
-
Asthavarga bindus are not yet account for, asthavarga good or bad nature of the planet. It is assumed that Shadbala system can compensate for it.
-
This passage on page 255 needs to be clarified "It must be noted that when passing through the first 10 degrees of a sign, Mars and the Sun produce results."
-
It's interpreted that Vendha is an obstruction and not a reversal of the Gochara results So as for now the design is that if a vedha is present than the result is simply nullified.
-
In Horoscope predictions methods have "time" & "person" arguments available, obvioulsy "time" is not needed, but for sake of semantic similarity with Muhurtha methods this is maintained.
-
Option 1 : generate a high res image (svg/html) and zoom horitontally into it - very fast - image gets blurry
-
Option 2 : Regenerate whole component in Blazor - very slow - hard to implement with touch screen
-
Option 3 : Generate multiple preset zooms, than place them on top of each other, and only make visible what is needed via selector - complicated, needs documentation - easy touch screen implimentation - very fast
Thus Option 3 was chosen.
- Structs are used to reduce overhead from large collections, exp. List<>
- When structs are part of a class, they are stored in the heap. An additional benefit is that structs need less memory than a class because they have no ObjectHeader or MethodTable. You should consider using a struct when the size of the struct will be minimal (say around 16 bytes), the struct will be short-lived, or the struct will be immutable.
- default hashing is inconsistent, MD5 is used
- many class's get hash overrides still use default hashing (in cache mechanism), could result in errors, needs to be updated
- NOTE : all default hashing is instance specific (FOR STRINGS ONLY so far), works as id in 1 enviroment, but with Client + Server config, hashes become different, needs changing to MD5
- In class/struct that only represent data and not computation, use direct property naming without modifiers like "Get" or "Set". Example: Person struct should be "Person.BirthTime" and not "Person.GetBirthTime()"
- 3 files exist now, azure storage, desktop, wwwroot (TODO delete all but wwwroot)
- 2 of these files exist, 1 local in MuhurthaCore for desktop version. The other online in VedAstro Azure storage for use by API. Both files need to be in sync, if forgot to sync. Use file with latest update.
- Future todo simplify into 1 file. Local MuhurthaCore can be deprecated.
- Generally 1 tag for 1 event, add only when needed.
- Multiple tags can be used by 1 event, separated by "," in in the Tag element
- Done so that event can be accessed for multiple uses. Example, Tarabala Events is taged for Personal & Tarabala.
- Needs to be added with care and where absolutely needed, else could get very confusing.
To all those who say we need money todo good. Jesus said not.
"It is easier for a camel to go through the eye of a needle, than for a rich man to enter the kingdom of God"

Oh so bright, On a Tuesday morning,
I'm pondering life, and what's in sight.
Is it fear, fate, justice, or a test of might?
From my father's voice rings a resounding insight.
Joy of my love, it's your guiding light!
All men that have joy, have God, just right,
Making love to their sweet wife, there, God's in sight!
When men love their wives, with all their heart,
They see a glimpse of God, a work of art.
In those precious moments, they see God's might.
Yet, swiftly it fades, like a star in the night
When fleeting moments pass, and cries are heard,
And we're left to wonder, if joy's been blurred.
Chasing worldly delights, may bring us cheer
But joy is what lasts, and banishes all fear.
To pursue worldly pleasures, is not quite right,
It's short-sighted, like a bat in the daylight.
They seek joy, in their ceaseless flight,
Forgetting it's joy that makes their wings ignite.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for VedAstro
Similar Open Source Tools
VedAstro
VedAstro is an open-source Vedic astrology tool that provides accurate astrological predictions and data. It offers a user-friendly website, a chat API, an open API, a JavaScript SDK, a Swiss Ephemeris API, and a machine learning table generator. VedAstro is free to use and is constantly being updated with new features and improvements.

memobase
Memobase is a user profile-based memory system designed to enhance Generative AI applications by enabling them to remember, understand, and evolve with users. It provides structured user profiles, scalable profiling, easy integration with existing LLM stacks, batch processing for speed, and is production-ready. Users can manage users, insert data, get memory profiles, and track user preferences and behaviors. Memobase is ideal for applications that require user analysis, tracking, and personalized interactions.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.
quivr
Quivr is a personal assistant powered by Generative AI, designed to be a second brain for users. It offers fast and efficient access to data, ensuring security and compatibility with various file formats. Quivr is open source and free to use, allowing users to share their brains publicly or keep them private. The marketplace feature enables users to share and utilize brains created by others, boosting productivity. Quivr's offline mode provides anytime, anywhere access to data. Key features include speed, security, OS compatibility, file compatibility, open source nature, public/private sharing options, a marketplace, and offline mode.

otto-m8
otto-m8 is a flowchart based automation platform designed to run deep learning workloads with minimal to no code. It provides a user-friendly interface to spin up a wide range of AI models, including traditional deep learning models and large language models. The tool deploys Docker containers of workflows as APIs for integration with existing workflows, building AI chatbots, or standalone applications. Otto-m8 operates on an Input, Process, Output paradigm, simplifying the process of running AI models into a flowchart-like UI.

kor
Kor is a prototype tool designed to help users extract structured data from text using Language Models (LLMs). It generates prompts, sends them to specified LLMs, and parses the output. The tool works with the parsing approach and is integrated with the LangChain framework. Kor is compatible with pydantic v2 and v1, and schema is typed checked using pydantic. It is primarily used for extracting information from text based on provided reference examples and schema documentation. Kor is designed to work with all good-enough LLMs regardless of their support for function/tool calling or JSON modes.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.

empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.
core
The Cheshire Cat is a framework for building custom AIs on top of any language model. It provides an API-first approach, making it easy to add a conversational layer to your application. The Cat remembers conversations and documents, and uses them in conversation. It is extensible via plugins, and supports event callbacks, function calling, and conversational forms. The Cat is easy to use, with an admin panel that allows you to chat with the AI, visualize memory and plugins, and adjust settings. It is also production-ready, 100% dockerized, and supports any language model.
llm-strategy
The 'llm-strategy' repository implements the Strategy Pattern using Large Language Models (LLMs) like OpenAI’s GPT-3. It provides a decorator 'llm_strategy' that connects to an LLM to implement abstract methods in interface classes. The package uses doc strings, type annotations, and method/function names as prompts for the LLM and can convert the responses back to Python data. It aims to automate the parsing of structured data by using LLMs, potentially reducing the need for manual Python code in the future.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.
openorch
OpenOrch is a daemon that transforms servers into a powerful development environment, running AI models, containers, and microservices. It serves as a blend of Kubernetes and a language-agnostic backend framework for building applications on fixed-resource setups. Users can deploy AI models and build microservices, managing applications while retaining control over infrastructure and data.
call-center-ai
Call Center AI is an AI-powered call center solution leveraging Azure and OpenAI GPT. It allows for AI agent-initiated phone calls or direct calls to the bot from a configured phone number. The bot is customizable for various industries like insurance, IT support, and customer service, with features such as accessing claim information, conversation history, language change, SMS sending, and more. The project is a proof of concept showcasing the integration of Azure Communication Services, Azure Cognitive Services, and Azure OpenAI for an automated call center solution.
For similar tasks
VedAstro
VedAstro is an open-source Vedic astrology tool that provides accurate astrological predictions and data. It offers a user-friendly website, a chat API, an open API, a JavaScript SDK, a Swiss Ephemeris API, and a machine learning table generator. VedAstro is free to use and is constantly being updated with new features and improvements.
For similar jobs
VedAstro
VedAstro is an open-source Vedic astrology tool that provides accurate astrological predictions and data. It offers a user-friendly website, a chat API, an open API, a JavaScript SDK, a Swiss Ephemeris API, and a machine learning table generator. VedAstro is free to use and is constantly being updated with new features and improvements.
psychic
Psychic is a tool that provides a platform for users to access psychic readings and services. It offers a range of features such as tarot card readings, astrology consultations, and spiritual guidance. Users can connect with experienced psychics and receive personalized insights and advice on various aspects of their lives. The platform is designed to be user-friendly and intuitive, making it easy for users to navigate and explore the different services available. Whether you're looking for guidance on love, career, or personal growth, Psychic has you covered.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.