Best AI tools for< Benchmark Automatic Evaluation >
20 - AI tool Sites
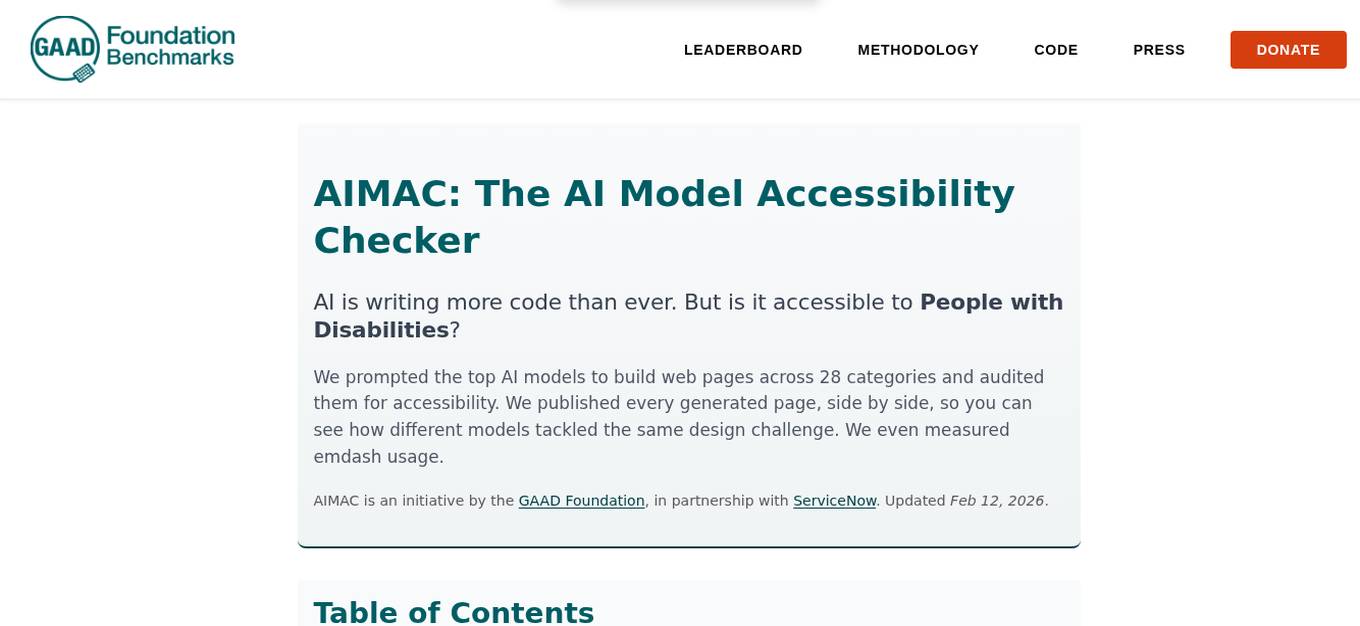
AIMAC Leaderboard
AIMAC Leaderboard is an AI Model Accessibility Checker that evaluates the accessibility of web pages generated by AI models across 28 categories. It compares top AI models side by side, auditing them for accessibility and measuring their performance. The initiative aims to ensure that AI models write accessible code by default. The project is a collaboration between the GAAD Foundation and ServiceNow, providing insights into how different models handle the same design challenges.
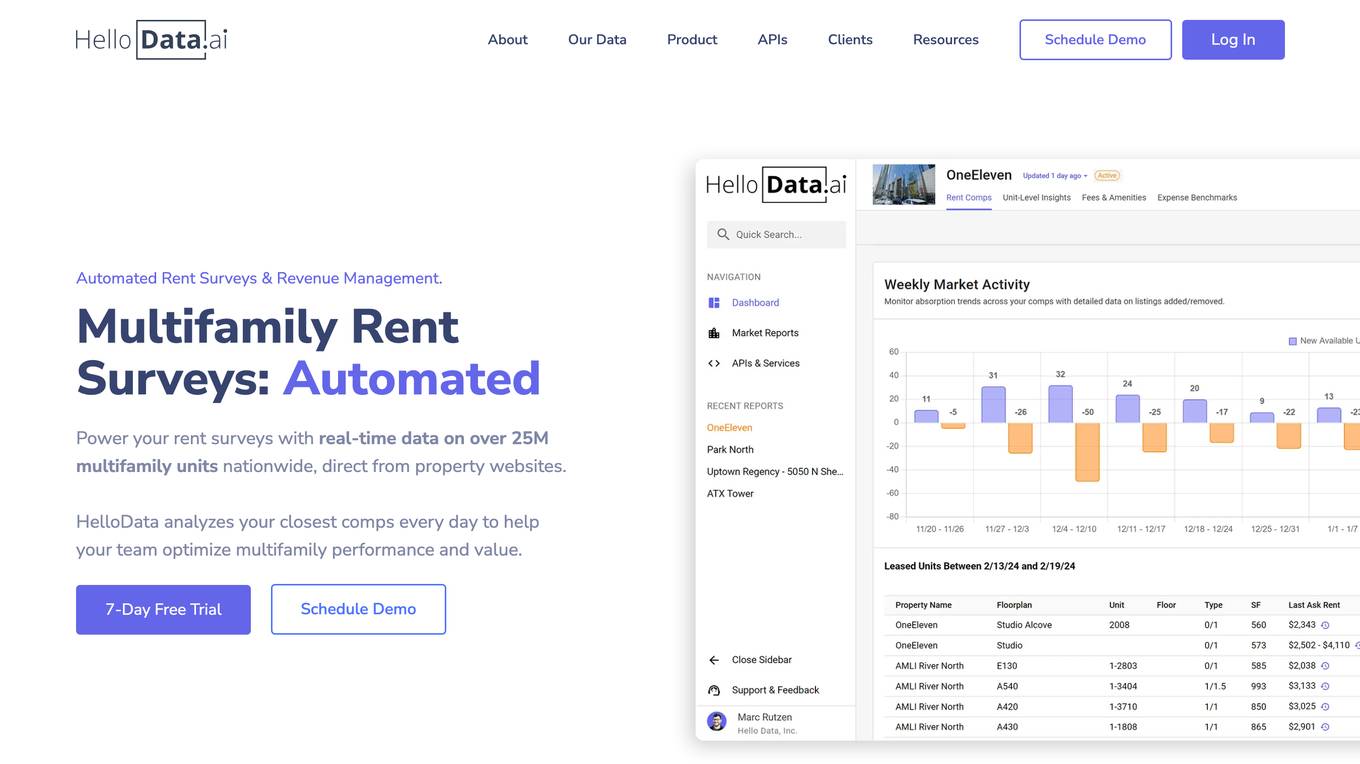
HelloData
HelloData is an AI-powered multifamily market analysis platform that automates market surveys, unit-level rent analysis, concessions monitoring, and development feasibility reports. It provides financial analysis tools to underwrite multifamily deals quickly and accurately. With custom query builders and Proptech APIs, users can analyze and download market data in bulk. HelloData is used by over 15,000 multifamily professionals to save time on market research and deal analysis, offering real-time property data and insights for operators, developers, investors, brokers, and Proptech companies.
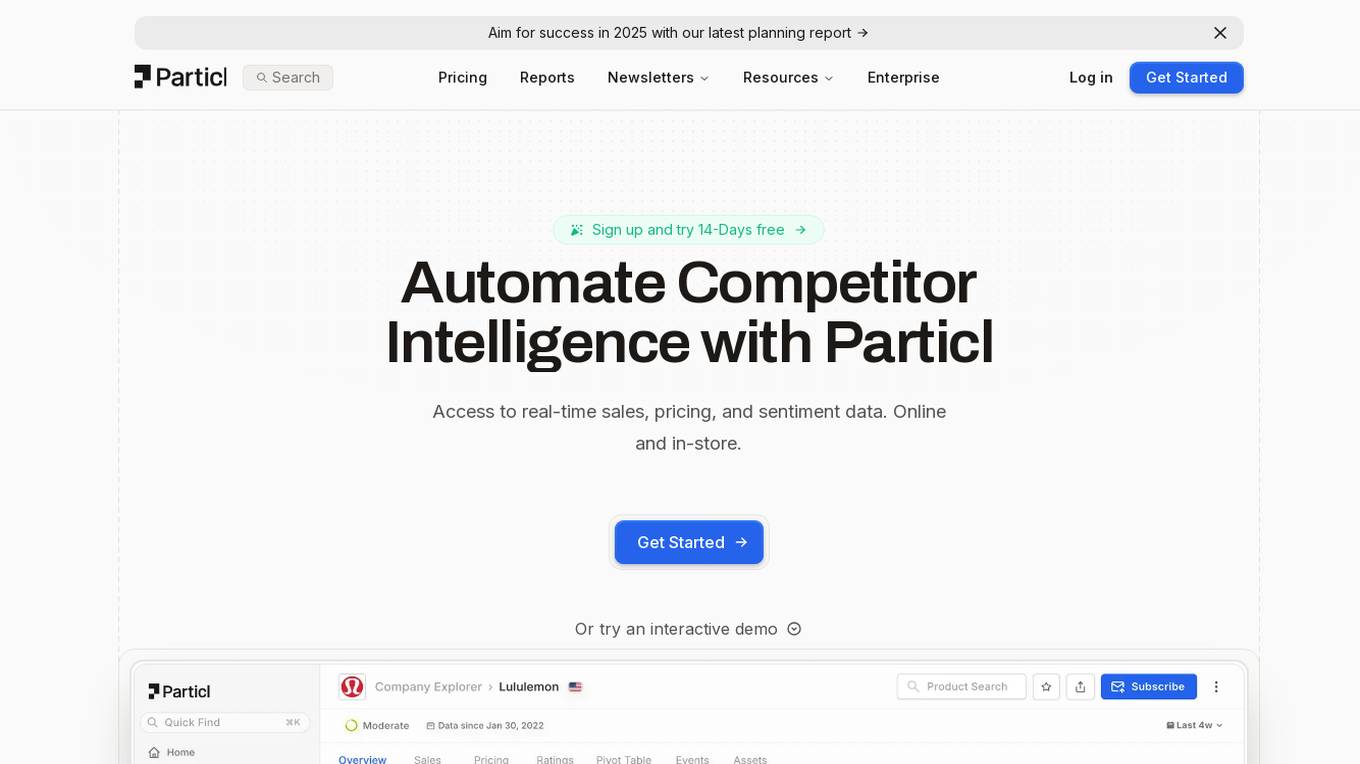
Particl
Particl is an AI-powered platform that automates competitor intelligence for modern retail businesses. It provides real-time sales, pricing, and sentiment data across various e-commerce channels. Particl's AI technology tracks sales, inventory, pricing, assortment, and sentiment to help users quickly identify profitable opportunities in the market. The platform offers features such as benchmarking performance, automated e-commerce intelligence, competitor research, product research, assortment analysis, and promotions monitoring. With easy-to-use tools and robust AI capabilities, Particl aims to elevate team workflows and capabilities in strategic planning, product launches, and market analysis.
ASK BOSCO®
ASK BOSCO® is an AI reporting and forecasting tool designed for agencies and retailers. It helps in collecting and analyzing data to improve browsing experience, customize marketing strategies, and provide analytics for better decision-making. The platform offers features like AI reporting, competitor benchmarking, AI budget planning, and data integrations to streamline marketing efforts and maximize ROI. Trusted by leading brands, ASK BOSCO® provides accurate forecasting and insights to optimize media spend and plan budgets effectively.
Censinet
Censinet is a purpose-built AI-powered solution designed to reduce risk in the healthcare industry. It offers a comprehensive platform to address various risk factors, including third-party vendors, patient data, medical devices, and supply chain cybersecurity. The flagship offering, Censinet RiskOps, facilitates secure data sharing and collaboration among healthcare delivery organizations and vendors. With deep expertise in healthcare and cybersecurity, Censinet aims to transform cybersecurity and risk management in the healthcare sector.
Seek AI
Seek AI is a generative AI-powered database query tool that helps businesses break through information barriers. It is the #1 most accurate model on the Yale Spider benchmark and offers a variety of features to help businesses modernize their analytics, including auto-verification with confidence estimation, natural language summary, and embedded AI data analyst.
Birdeye
Birdeye is an AI platform that offers efficient, hyper-personalized, and actionable AI solutions for businesses. It provides a range of AI agents tailored to industry needs, such as managing reviews, optimizing listings, and creating social posts. Birdeye's AI models are designed to deliver marketing outcomes at scale, empowering businesses with improved visibility, reputation, and competitive edge. The platform also offers insights, benchmarks, and automated content generation to enhance brand growth and customer retention.
WorkViz
WorkViz is an AI-powered performance tool designed for remote teams to visualize productivity, maximize performance, and foresee the team's potential. It offers features such as automated daily reports, employee voice expression through emojis, workload management alerts, productivity solutions, and intelligent summaries. WorkViz ensures data security through guaranteed audit, desensitization, and SSL security protocols. The application has received positive feedback from clients for driving improvements, providing KPIs and benchmarks, and simplifying daily reporting. It helps users track work hours, identify roadblocks, and improve team performance.
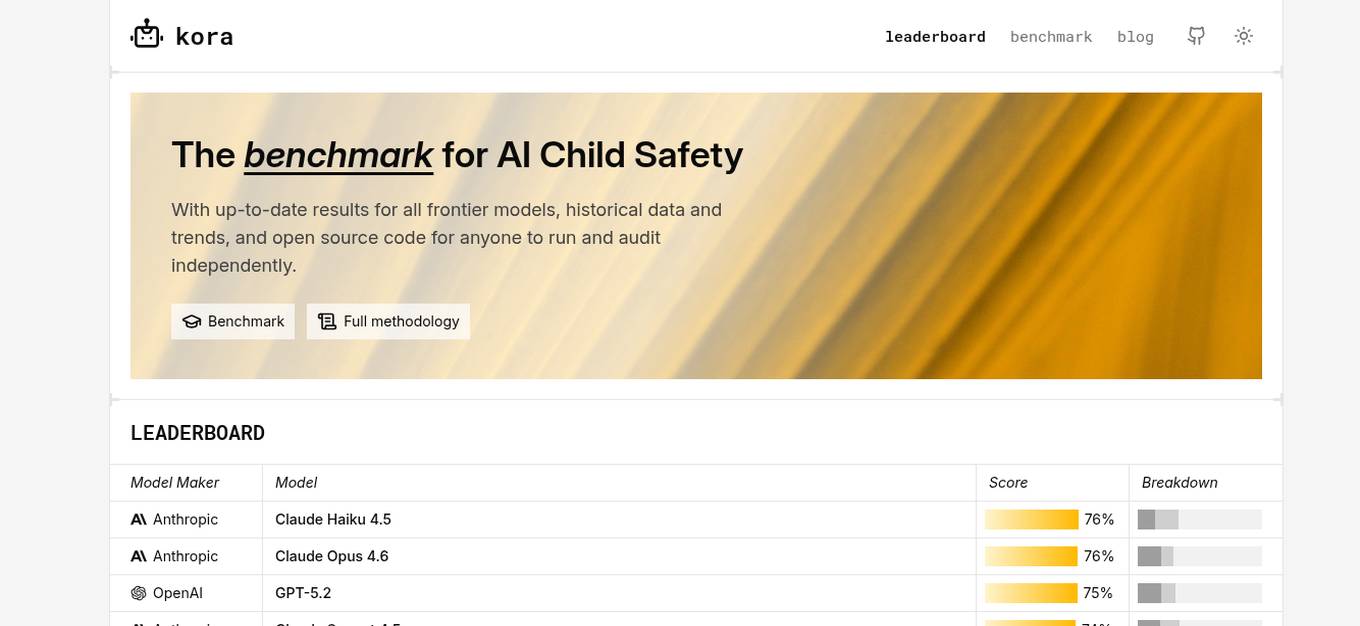
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.
Junbi.ai
Junbi.ai is an AI-powered insights platform designed for YouTube advertisers. It offers AI-powered creative insights for YouTube ads, allowing users to benchmark their ads, predict performance, and test quickly and easily with fully AI-powered technology. The platform also includes expoze.io API for attention prediction on images or videos, with scientifically valid results and developer-friendly features for easy integration into software applications.
SeeMe Index
SeeMe Index is an AI tool for inclusive marketing decisions. It helps brands and consumers by measuring brands' consumer-facing inclusivity efforts across public advertisements, product lineup, and DEI commitments. The tool utilizes responsible AI to score brands, develop industry benchmarks, and provide consulting to improve inclusivity. SeeMe Index awards the highest-scoring brands with an 'Inclusive Certification', offering consumers an unbiased way to identify inclusive brands.
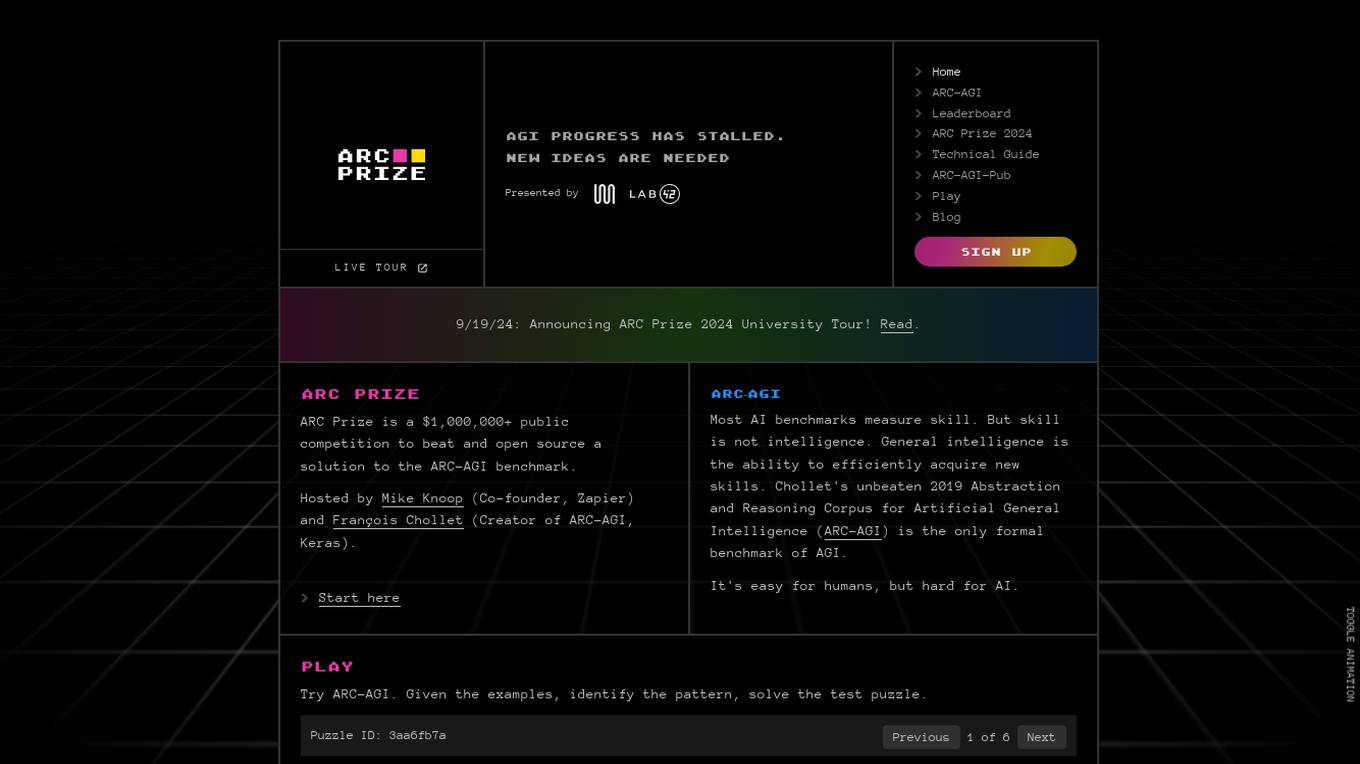
ARC Prize
ARC Prize is a platform hosting a $1,000,000+ public competition aimed at beating and open-sourcing a solution to the ARC-AGI benchmark. The platform is dedicated to advancing open artificial general intelligence (AGI) for the public benefit. It provides a formal benchmark, ARC-AGI, created by François Chollet, to measure progress towards AGI by testing the ability to efficiently acquire new skills and solve open-ended problems. ARC Prize encourages participants to try solving test puzzles to identify patterns and improve their AGI skills.

Report Card AI
Report Card AI is an AI Writing Assistant that helps users generate high-quality, unique, and personalized report card comments. It allows users to create a quality benchmark by writing their first draft of comments with the assistance of AI technology. The tool is designed to streamline the report card writing process for teachers, ensuring error-free and eloquently written comments that meet specific character count requirements. With features like 'rephrase', 'Max Character Count', and easy exporting options, Report Card AI aims to enhance efficiency and accuracy in creating report card comments.

Waikay
Waikay is an AI tool designed to help individuals, businesses, and agencies gain transparency into what AI knows about their brand. It allows users to manage reputation risks, optimize strategic positioning, and benchmark against competitors with actionable insights. By providing a comprehensive analysis of AI mentions, citations, implied facts, and competition, Waikay ensures a 360-degree view of model understanding. Users can easily track their brand's digital footprint, compare with competitors, and monitor their brand and content across leading AI search platforms.
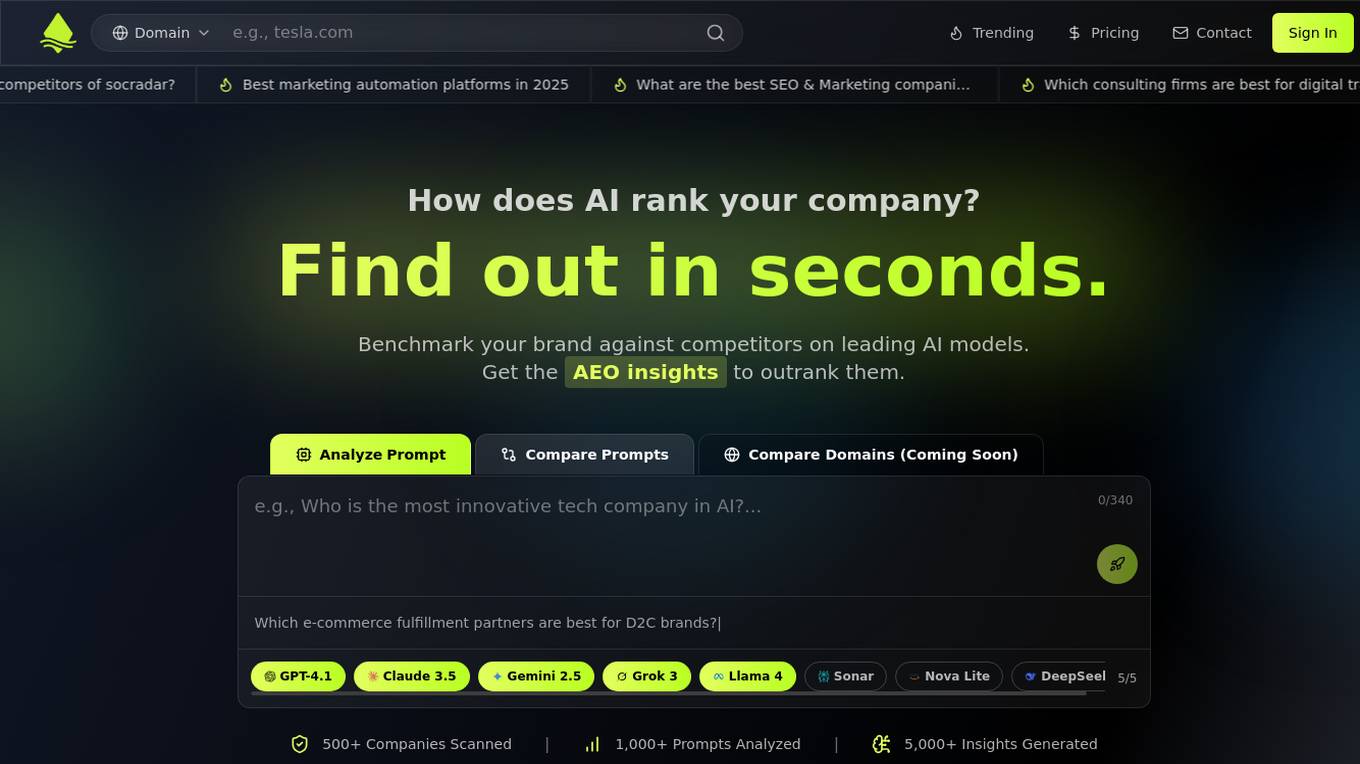
Spotrank.ai
Spotrank.ai is an AI-powered platform that provides advanced analytics and insights for businesses and individuals. It leverages artificial intelligence algorithms to analyze data and generate valuable reports to help users make informed decisions. The platform offers a user-friendly interface and customizable features to cater to diverse needs across various industries. Spotrank.ai is designed to streamline data analysis processes and enhance decision-making capabilities through cutting-edge AI technology.
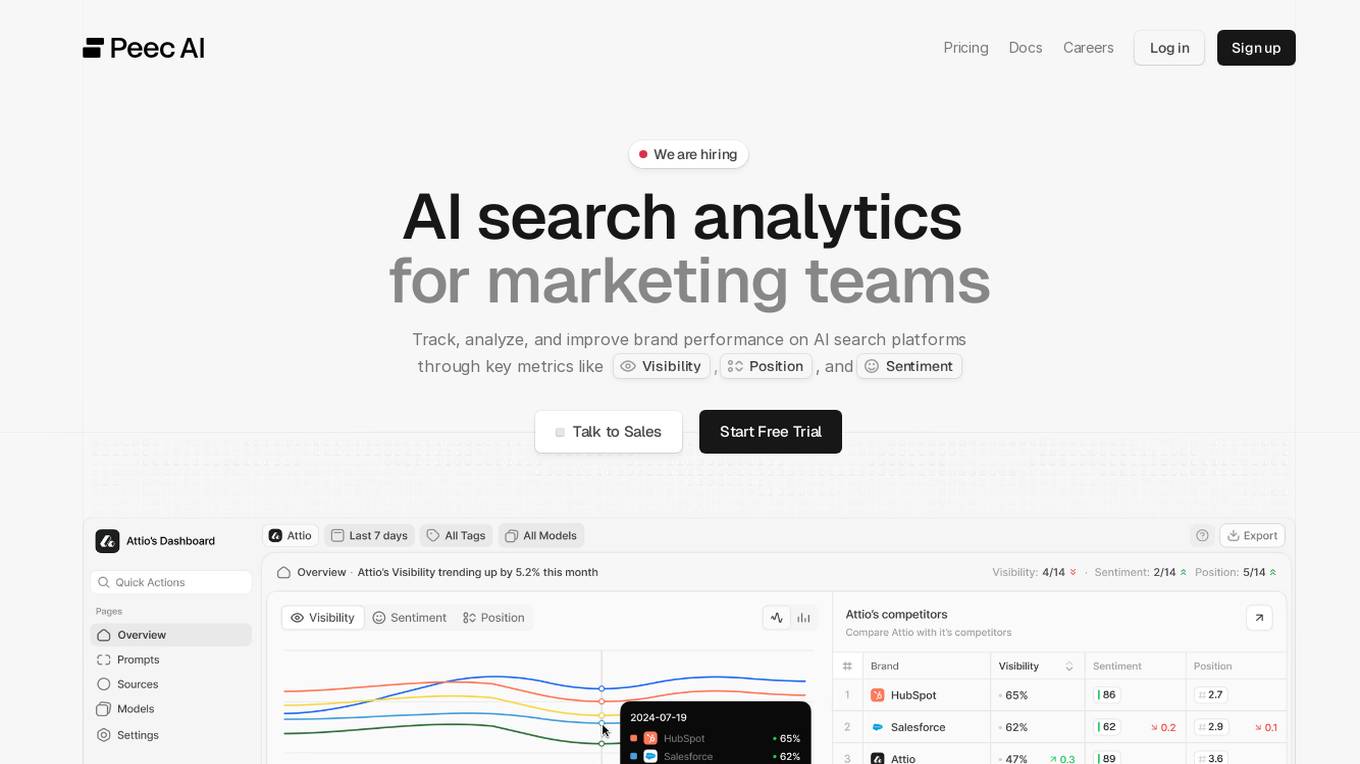
Peec AI
Peec AI is an AI search analytics tool designed for marketing teams to track, analyze, and improve brand performance on AI search platforms. It provides key metrics such as Visibility, Position, and Sentiment to help businesses understand how AI perceives their brand. The platform offers insights on AI visibility, prompts analysis, and competitor tracking to enhance marketing strategies in the era of AI and generative search.
Perspect
Perspect is an AI-powered platform designed for high-performance software teams. It offers real-time insights into team contributions and impact, optimizing developer experience, and rewarding high-performers. With 50+ integrations, Perspect enables visualization of impact, benchmarking performance, and uses machine learning models to identify and eliminate blockers. The platform is deeply integrated with web3 wallets and offers built-in reward mechanisms. Managers can align resources around crucial KPIs, identify top talent, and prevent burnout. Perspect aims to enhance team productivity and employee retention through AI and ML technologies.

Gorilla
Gorilla is an AI tool that integrates a large language model (LLM) with massive APIs to enable users to interact with a wide range of services. It offers features such as training the model to support parallel functions, benchmarking LLMs on function-calling capabilities, and providing a runtime for executing LLM-generated actions like code and API calls. Gorilla is open-source and focuses on enhancing interaction between apps and services with human-out-of-loop functionality.
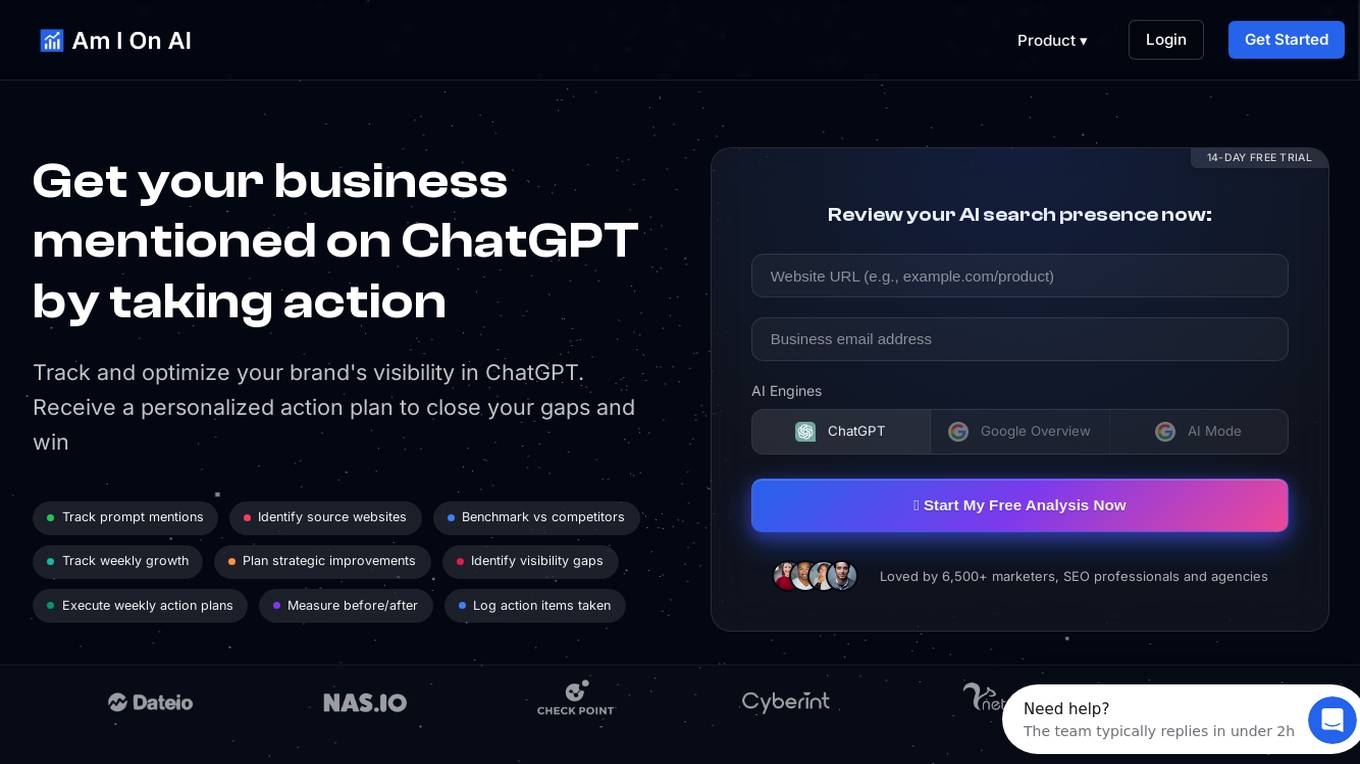
Am I On AI
Am I On AI is a platform designed to help businesses improve their visibility in AI responses, specifically focusing on ChatGPT. It provides personalized action plans to enhance brand visibility, track mentions, identify source websites, benchmark against competitors, and execute strategic improvements. The platform offers features such as AI brand monitoring, competitor rank analysis, sentiment analysis, citation tracking, and actionable insights. With a user-friendly interface and measurable results, Am I On AI is a valuable tool for marketers, SEO professionals, and agencies looking to optimize their AI visibility.
Comparables.ai
Comparables.ai is an AI-powered company and market intelligence platform designed for M&A professionals. It offers comprehensive data insights, valuation multiples, and market analysis to help users make informed decisions in investment banking, private equity, and corporate finance. The platform leverages AI technology to provide relevant company information, financial data, and M&A transaction history, enabling users to identify new investment targets, benchmark companies, and conduct market analysis efficiently.
1 - Open Source AI Tools
summary-of-a-haystack
This repository contains data and code for the experiments in the SummHay paper. It includes publicly released Haystacks in conversational and news domains, along with scripts for running the pipeline, visualizing results, and benchmarking automatic evaluation. The data structure includes topics, subtopics, insights, queries, retrievers, summaries, evaluation summaries, and documents. The pipeline involves scripts for retriever scores, summaries, and evaluation scores using GPT-4o. Visualization scripts are provided for compiling and visualizing results. The repository also includes annotated samples for benchmarking and citation information for the SummHay paper.
10 - OpenAI Gpts

HVAC Apex
Benchmark HVAC GPT model with unmatched expertise and forward-thinking solutions, powered by OpenAI
SaaS Navigator
A strategic SaaS analyst for CXOs, with a focus on market trends and benchmarks.


Transfer Pricing Advisor
Guides businesses in managing global tax liabilities efficiently.
Salary Guides
I provide monthly salary data in euros, using a structured format for global job roles.
Performance Testing Advisor
Ensures software performance meets organizational standards and expectations.