Best AI tools for< Run Pipeline >
20 - AI tool Sites
Collate Labs
The website is an AI-powered Relationship Intelligence Platform designed for enterprise sales. It helps accelerate deals, boost win rates, and provides automatic account mapping and real-time contact insights. The platform centralizes user interactions, integrates with CRM systems, and offers AI-driven insights for better customer engagement and sales strategies.
Clari
Clari is a revenue operations platform that helps businesses track, forecast, and analyze their revenue performance. It provides a unified view of the revenue process, from lead generation to deal closing, and helps businesses identify and address revenue leaks. Clari is powered by AI and machine learning, which helps it to automate tasks, provide insights, and make recommendations. It is used by businesses of all sizes, from startups to large enterprises.
Clari
Clari is a revenue operations platform that helps businesses track, forecast, and close deals. It provides a unified view of the sales pipeline, allowing teams to identify and address potential problems early on. Clari also uses artificial intelligence to surface insights and recommendations, helping businesses improve their sales performance.
Cascadeur
Cascadeur is a standalone 3D software that lets you create keyframe animation, as well as clean up and edit any imported ones. Thanks to its AI-assisted and physics tools you can dramatically speed up the animation process and get high quality results. It works with .FBX, .DAE and .USD files making it easy to integrate into any animation workflow.
Octomind
Octomind is an AI-powered QA platform that provides automated end-to-end testing for web applications. It offers features such as self-healing tests, visual debugging, and stable test runs. Octomind is designed for early-stage and fast-growing SaaS or AI startups with small engineering teams, aiming to improve product quality and speed by catching regressions before they reach users. The platform is trusted by thousands of engineering teams worldwide and is SOC-2 certified, ensuring privacy and security.
Functionize
Functionize is an AI-powered test automation platform that helps enterprises improve their product quality and release faster. It uses machine learning to automate test creation, maintenance, and execution, and provides a range of features to help teams collaborate and manage their testing process. Functionize integrates with popular CI/CD tools and DevOps pipelines, and offers a range of pricing options to suit different needs.
Momentic
Momentic is an AI testing tool that offers automated AI testing for software applications. It streamlines regression testing, production monitoring, and UI automation, making test automation easy with its AI capabilities. Momentic is designed to be simple to set up, easy to maintain, and accelerates team productivity by creating and deploying tests faster with its intuitive low-code editor. The tool adapts to applications, saves time with automated test maintenance, and allows testing anywhere, anytime using cloud, local, or CI/CD pipelines.
RunPod
RunPod is a cloud platform specifically designed for AI development and deployment. It offers a range of features to streamline the process of developing, training, and scaling AI models, including a library of pre-built templates, efficient training pipelines, and scalable deployment options. RunPod also provides access to a wide selection of GPUs, allowing users to choose the optimal hardware for their specific AI workloads.
Momentic
Momentic is a purpose-built AI tool for modern software testing, offering automation for E2E, UI, API, and accessibility testing. It leverages AI to streamline testing processes, from element identification to test generation, helping users shorten development cycles and enhance productivity. With an intuitive editor and the ability to describe elements in plain English, Momentic simplifies test creation and execution. It supports local testing without the need for a public URL, smart waiting for in-flight requests, and integration with CI/CD pipelines. Momentic is trusted by numerous companies for its efficiency in writing and maintaining end-to-end tests.

BulkGPT
BulkGPT is the ultimate AI automation platform that allows users to build custom AI workflows and automate at scale without the need for coding. It enables users to chain together web scraping, Google search, and AI generation to create powerful pipelines. With BulkGPT, users can run workflows on thousands of rows simultaneously, process up to 5,000 tasks in a single bulk request, and generate SEO-optimized articles, among other features. The platform supports various AI models, including GPT-4o and GPT-4o-mini, and provides multiple export formats for easy integration.
Workflow DevKit
Workflow DevKit is an AI tool designed to make any TypeScript function durable by bringing durability, reliability, and observability to async JavaScript. It allows users to build apps and AI agents that can suspend, resume, and maintain state with ease. The tool provides a simple declarative API to define and use workflows, enabling users to move from hand-rolled queues and custom retries to durable, resumable code with simple directives. Workflow DevKit offers observability features to inspect every run end-to-end, pause, replay, and time-travel through steps with traces, logs, and metrics automatically captured. It is universally compatible with various frameworks and can power a wide array of applications, from streaming real-time agents to CI/CD pipelines or multi-day email subscriptions workflows. The tool ensures reliability without the need for plumbing, making it easy to build reliable, long-running processes with automatic retries, state persistence, and observability built-in.
NVIDIA Run:ai
NVIDIA Run:ai is an enterprise platform for AI workloads and GPU orchestration. It accelerates AI and machine learning operations by addressing key infrastructure challenges through dynamic resource allocation, comprehensive AI life-cycle support, and strategic resource management. The platform significantly enhances GPU efficiency and workload capacity by pooling resources across environments and utilizing advanced orchestration. NVIDIA Run:ai provides unparalleled flexibility and adaptability, supporting public clouds, private clouds, hybrid environments, or on-premises data centers.
Run Recommender
The Run Recommender is a web-based tool that helps runners find the perfect pair of running shoes. It uses a smart algorithm to suggest options based on your input, giving you a starting point in your search for the perfect pair. The Run Recommender is designed to be user-friendly and easy to use. Simply input your shoe width, age, weight, and other details, and the Run Recommender will generate a list of potential shoes that might suit your running style and body. You can also provide information about your running experience, distance, and frequency, and the Run Recommender will use this information to further refine its suggestions. Once you have a list of potential shoes, you can click on each shoe to learn more about it, including its features, benefits, and price. You can also search for the shoe on Amazon to find the best deals.
Practice Run AI
Practice Run AI is an online platform that offers AI-powered tools for various tasks. Users can utilize the application to practice and run AI algorithms without the need for complex setups or installations. The platform provides a user-friendly interface that allows individuals to experiment with AI models and enhance their understanding of artificial intelligence concepts. Practice Run AI aims to democratize AI education and make it accessible to a wider audience by simplifying the learning process and providing hands-on experience.
Dora
Dora is a no-code 3D animated website design platform that allows users to create stunning 3D and animated visuals without writing a single line of code. With Dora, designers, freelancers, and creative professionals can focus on what they do best: designing. The platform is tailored for professionals who prioritize design aesthetics without wanting to dive deep into the backend. Dora offers a variety of features, including a drag-and-connect constraint layout system, advanced animation capabilities, and pixel-perfect usability. With Dora, users can create responsive 3D and animated websites that translate seamlessly across devices.
Reflect
Reflect is an AI-powered test automation tool that revolutionizes the way end-to-end tests are created, executed, and maintained. By leveraging Generative AI, Reflect eliminates the need for manual coding and provides a seamless testing experience. The tool offers features such as no-code test automation, visual testing, API testing, cross-browser testing, and more. Reflect aims to help companies increase software quality by accelerating testing processes and ensuring test adaptability over time.

Learn Playwright
Learn Playwright is a comprehensive platform offering resources for learning end-to-end testing using the Playwright automation framework. It provides a blog with in-depth subjects about end-to-end testing, an 'Ask AI' feature for querying ChatGPT about Playwright questions, and a Dev Tools section that serves as an all-in-one toolbox for QA engineers. The platform also curates QA and Automation job opportunities, answers common questions about Playwright, hosts a Discord forum archive, offers various videos including tutorials and conference talks, provides a browser extension with a GUI for generating Playwright locators, and features a QA Wiki with definitions of common end-to-end testing terms. Users can quickly access all tools by using the shortcut Ctrl + k + 'Tools'.
Symphony
Symphony is a programming platform that allows users to write programs using natural language. It aims to simplify the process of coding by enabling users to interact with the system through conversational language, making it more accessible to individuals without a technical background. Symphony provides a user-friendly interface for creating scripts and automating tasks, bridging the gap between traditional programming languages and everyday communication.
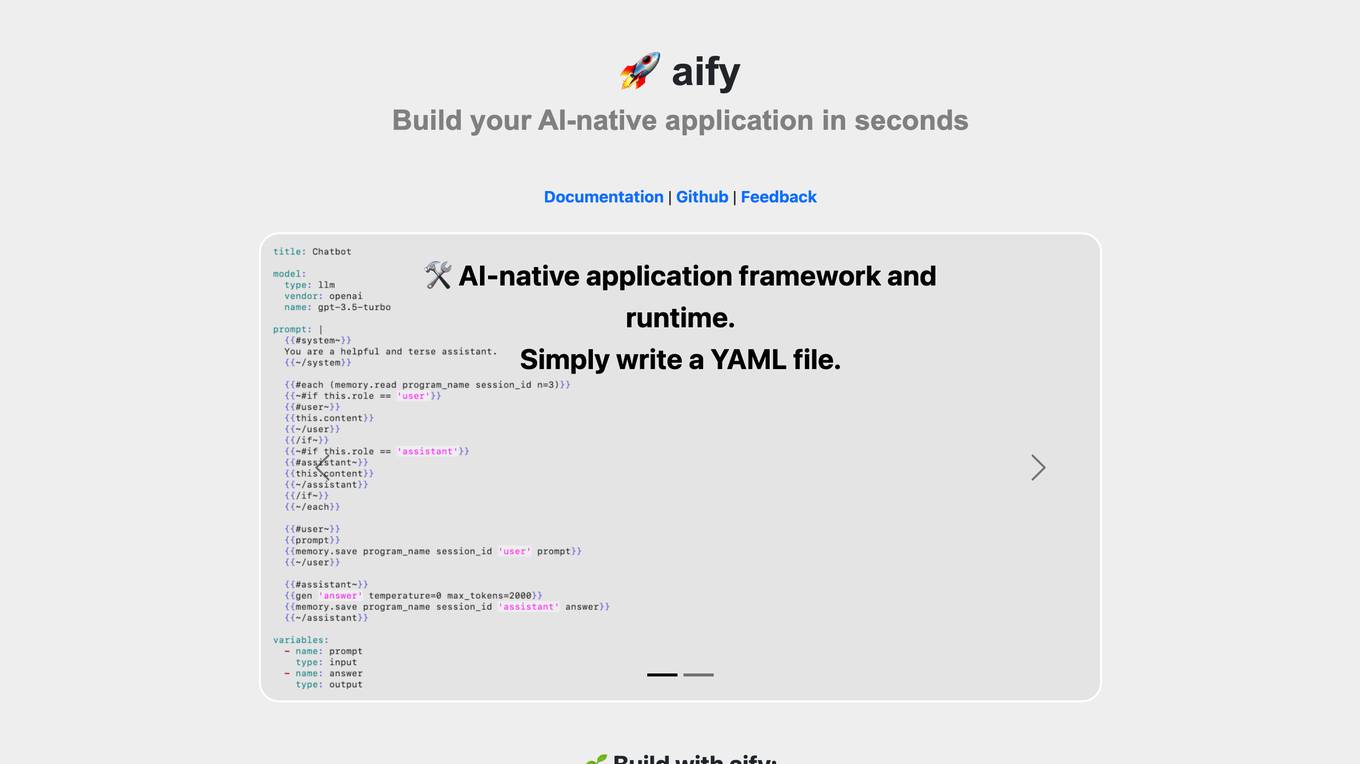
aify
aify is an AI-native application framework and runtime that allows users to build AI-native applications quickly and easily. With aify, users can create applications by simply writing a YAML file. The platform also offers a ready-to-use AI chatbot UI for seamless integration. Additionally, aify provides features such as Emoji express for searching emojis by semantics. The framework is open source under the MIT license, making it accessible to developers of all levels.
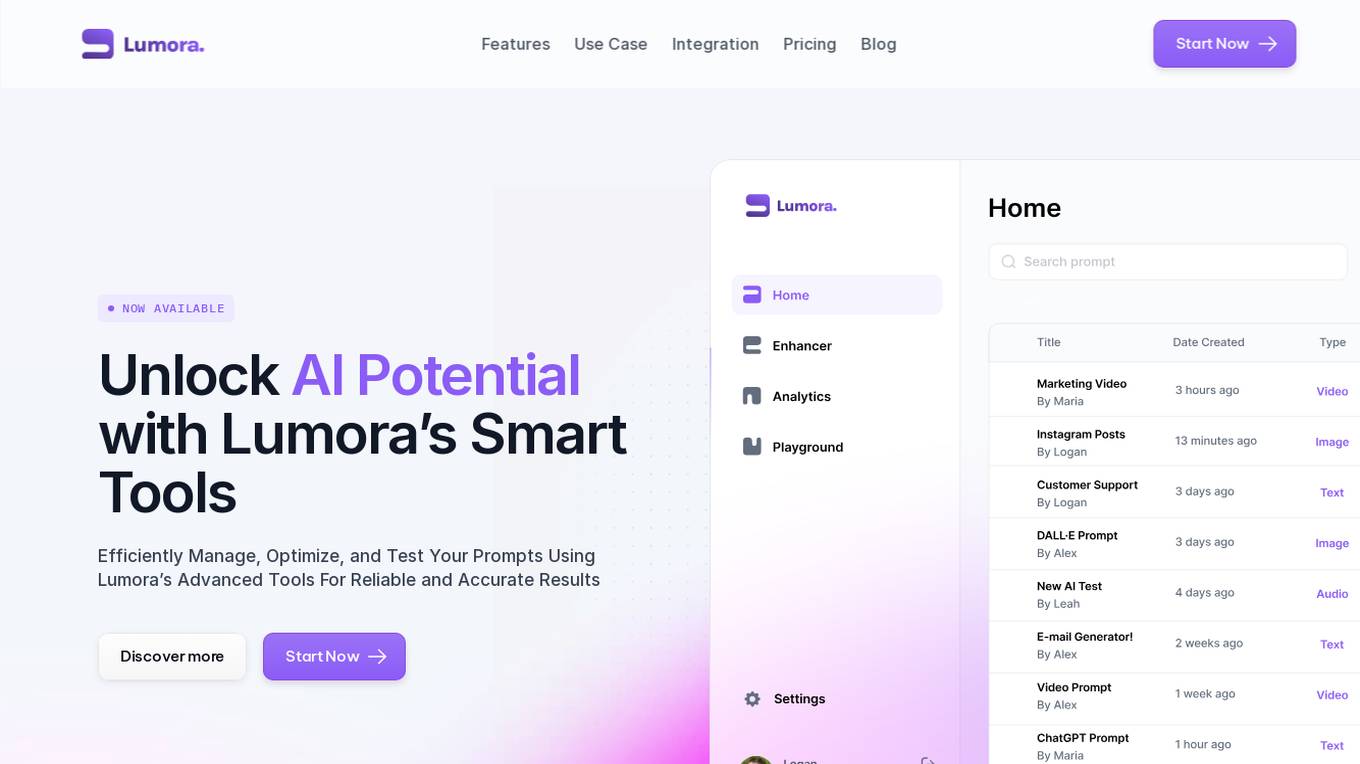
Lumora
Lumora is an AI tool designed to help users efficiently manage, optimize, and test prompts for various AI platforms. It offers features such as prompt organization, enhancement, testing, and development. Lumora aims to improve prompt outcomes and streamline prompt management for teams, providing a user-friendly interface and a playground for experimentation. The tool also integrates with various AI models for text, image, and video generation, allowing users to optimize prompts for better results.
1 - Open Source AI Tools
summary-of-a-haystack
This repository contains data and code for the experiments in the SummHay paper. It includes publicly released Haystacks in conversational and news domains, along with scripts for running the pipeline, visualizing results, and benchmarking automatic evaluation. The data structure includes topics, subtopics, insights, queries, retrievers, summaries, evaluation summaries, and documents. The pipeline involves scripts for retriever scores, summaries, and evaluation scores using GPT-4o. Visualization scripts are provided for compiling and visualizing results. The repository also includes annotated samples for benchmarking and citation information for the SummHay paper.
20 - OpenAI Gpts
Consulting & Investment Banking Interview Prep GPT
Run mock interviews, review content and get tips to ace strategy consulting and investment banking interviews

Dungeon Master's Assistant
Your new DM's screen: helping Dungeon Masters to craft & run amazing D&D adventures.
Database Builder
Hosts a real SQLite database and helps you create tables, make schema changes, and run SQL queries, ideal for all levels of database administration.
Restaurant Startup Guide
Meet the Restaurant Startup Guide GPT: your friendly guide in the restaurant biz. It offers casual, approachable advice to help you start and run your own restaurant with ease.

Community Design™
A community-building GPT based on the wildly popular Community Design™ framework from Mighty Networks. Start creating communities that run themselves.
Code Helper for Web Application Development
Friendly web assistant for efficient code. Ask the wizard to create an application and you will get the HTML, CSS and Javascript code ready to run your web application.

Creative Director GPT
I'm your brainstorm muse in marketing and advertising; the creativity machine you need to sharpen the skills, land the job, generate the ideas, win the pitches, build the brands, ace the awards, or even run your own agency. Psst... don't let your clients find out about me! 😉
Pace Assistant
Provides running splits for Strava Routes, accounting for distance and elevation changes



Design Sprint Coach (beta)
A helpful coach for guiding teams through Design Sprints with a touch of sass.