
haiku.rag
Retrieval Augmented Generation based on LanceDB
Stars: 317
Haiku RAG is a Retrieval-Augmented Generation (RAG) library that utilizes LanceDB as a local vector database. It supports semantic and full-text search, hybrid search with Reciprocal Rank Fusion, multiple embedding and QA providers, default search result reranking, question answering, file monitoring, and various file formats. It can be used via CLI or Python API, and can serve as tools for AI assistants like Claude Desktop. The library offers features for document management and search, with detailed documentation available.
README:
Retrieval-Augmented Generation (RAG) library built on LanceDB.
haiku.rag is a Retrieval-Augmented Generation (RAG) library built to work with LanceDB as a local vector database. It uses LanceDB for storing embeddings and performs semantic (vector) search as well as full-text search combined through native hybrid search with Reciprocal Rank Fusion. Both open-source (Ollama) as well as commercial (OpenAI, VoyageAI) embedding providers are supported.
Note: Starting with version 0.7.0, haiku.rag uses LanceDB instead of SQLite. If you have an existing SQLite database, use
haiku-rag migrate old_database.sqliteto migrate your data safely.
- Local LanceDB: No external servers required, supports also LanceDB cloud storage, S3, Google Cloud & Azure
- Multiple embedding providers: Ollama, VoyageAI, OpenAI, vLLM
- Multiple QA providers: Any provider/model supported by Pydantic AI
- Native hybrid search: Vector + full-text search with native LanceDB RRF reranking
- Reranking: Default search result reranking with MixedBread AI, Cohere, or vLLM
- Question answering: Built-in QA agents on your documents
- File monitoring: Auto-index files when run as server
- 40+ file formats: PDF, DOCX, HTML, Markdown, code files, URLs
- MCP server: Expose as tools for AI assistants
- CLI & Python API: Use from command line or Python
# Install
uv pip install haiku.rag
# Add documents
haiku-rag add "Your content here"
haiku-rag add-src document.pdf
# Search
haiku-rag search "query"
# Ask questions
haiku-rag ask "Who is the author of haiku.rag?"
# Ask questions with citations
haiku-rag ask "Who is the author of haiku.rag?" --cite
# Rebuild database (re-chunk and re-embed all documents)
haiku-rag rebuild
# Migrate from SQLite to LanceDB
haiku-rag migrate old_database.sqlite
# Start server with file monitoring
export MONITOR_DIRECTORIES="/path/to/docs"
haiku-rag servefrom haiku.rag.client import HaikuRAG
async with HaikuRAG("database.lancedb") as client:
# Add document
doc = await client.create_document("Your content")
# Search (reranking enabled by default)
results = await client.search("query")
for chunk, score in results:
print(f"{score:.3f}: {chunk.content}")
# Ask questions
answer = await client.ask("Who is the author of haiku.rag?")
print(answer)
# Ask questions with citations
answer = await client.ask("Who is the author of haiku.rag?", cite=True)
print(answer)Use with AI assistants like Claude Desktop:
haiku-rag serve --stdioProvides tools for document management and search directly in your AI assistant.
Full documentation at: https://ggozad.github.io/haiku.rag/
- Installation - Provider setup
- Configuration - Environment variables
- CLI - Command reference
- Python API - Complete API docs
- Agents - QA agent and multi-agent research
- Benchmarks - Performance Benchmarks
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for haiku.rag
Similar Open Source Tools
haiku.rag
Haiku RAG is a Retrieval-Augmented Generation (RAG) library that utilizes LanceDB as a local vector database. It supports semantic and full-text search, hybrid search with Reciprocal Rank Fusion, multiple embedding and QA providers, default search result reranking, question answering, file monitoring, and various file formats. It can be used via CLI or Python API, and can serve as tools for AI assistants like Claude Desktop. The library offers features for document management and search, with detailed documentation available.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
agent-squad
Agent Squad is a flexible, lightweight open-source framework for orchestrating multiple AI agents to handle complex conversations. It intelligently routes queries, maintains context across interactions, and offers pre-built components for quick deployment. The system allows easy integration of custom agents and conversation messages storage solutions, making it suitable for various applications from simple chatbots to sophisticated AI systems, scaling efficiently.
llmgateway
The llmgateway repository is a tool that provides a gateway for interacting with various LLM (Large Language Model) models. It allows users to easily access and utilize pre-trained language models for tasks such as text generation, sentiment analysis, and language translation. The tool simplifies the process of integrating LLMs into applications and workflows, enabling developers to leverage the power of state-of-the-art language models for various natural language processing tasks.
multi-agent-orchestrator
Multi-Agent Orchestrator is a flexible and powerful framework for managing multiple AI agents and handling complex conversations. It intelligently routes queries to the most suitable agent based on context and content, supports dual language implementation in Python and TypeScript, offers flexible agent responses, context management across agents, extensible architecture for customization, universal deployment options, and pre-built agents and classifiers. It is suitable for various applications, from simple chatbots to sophisticated AI systems, accommodating diverse requirements and scaling efficiently.

aigne-framework
AIGNE Framework is a functional AI application development framework designed to simplify and accelerate the process of building modern applications. It combines functional programming features, powerful artificial intelligence capabilities, and modular design principles to help developers easily create scalable solutions. With key features like modular design, TypeScript support, multiple AI model support, flexible workflow patterns, MCP protocol integration, code execution capabilities, and Blocklet ecosystem integration, AIGNE Framework offers a comprehensive solution for developers. The framework provides various workflow patterns such as Workflow Router, Workflow Sequential, Workflow Concurrency, Workflow Handoff, Workflow Reflection, Workflow Orchestration, Workflow Code Execution, and Workflow Group Chat to address different application scenarios efficiently. It also includes built-in MCP support for running MCP servers and integrating with external MCP servers, along with packages for core functionality, agent library, CLI, and various models like OpenAI, Gemini, Claude, and Nova.
graphbit
GraphBit is an industry-grade agentic AI framework built for developers and AI teams that demand stability, scalability, and low resource usage. It is written in Rust for maximum performance and safety, delivering significantly lower CPU usage and memory footprint compared to leading alternatives. The framework is designed to run multi-agent workflows in parallel, persist memory across steps, recover from failures, and ensure 100% task success under load. With lightweight architecture, observability, and concurrency support, GraphBit is suitable for deployment in high-scale enterprise environments and low-resource edge scenarios.
ExtractThinker
ExtractThinker is a library designed for extracting data from files and documents using Language Model Models (LLMs). It offers ORM-style interaction between files and LLMs, supporting multiple document loaders such as Tesseract OCR, Azure Form Recognizer, AWS TextExtract, and Google Document AI. Users can customize extraction using contract definitions, process documents asynchronously, handle various document formats efficiently, and split and process documents. The project is inspired by the LangChain ecosystem and focuses on Intelligent Document Processing (IDP) using LLMs to achieve high accuracy in document extraction tasks.
gemini-coder
Gemini Coder is a free 2M context AI coding assistant that allows users to conveniently copy folders and files for chatbots. It provides FIM completions, file refactoring, and AI-suggested changes. The extension is versatile, private, and lightweight, offering unmatched accuracy, speed, and cost in AI assistance. Users have full control over the context and coding conventions included, ensuring high performance and signal to noise ratio. Gemini Coder supports various chatbots and provides quick start guides for chat and FIM completions. It also offers commands for FIM completions, refactoring, applying changes, chat, and context copying. Users can set up custom model providers for API features and contribute to the project through pull requests or discussions. The tool is licensed under the MIT License.
inferable
Inferable is an open source platform that helps users build reliable LLM-powered agentic automations at scale. It offers a managed agent runtime, durable tool calling, zero network configuration, multiple language support, and is fully open source under the MIT license. Users can define functions, register them with Inferable, and create runs that utilize these functions to automate tasks. The platform supports Node.js/TypeScript, Go, .NET, and React, and provides SDKs, core services, and bootstrap templates for various languages.
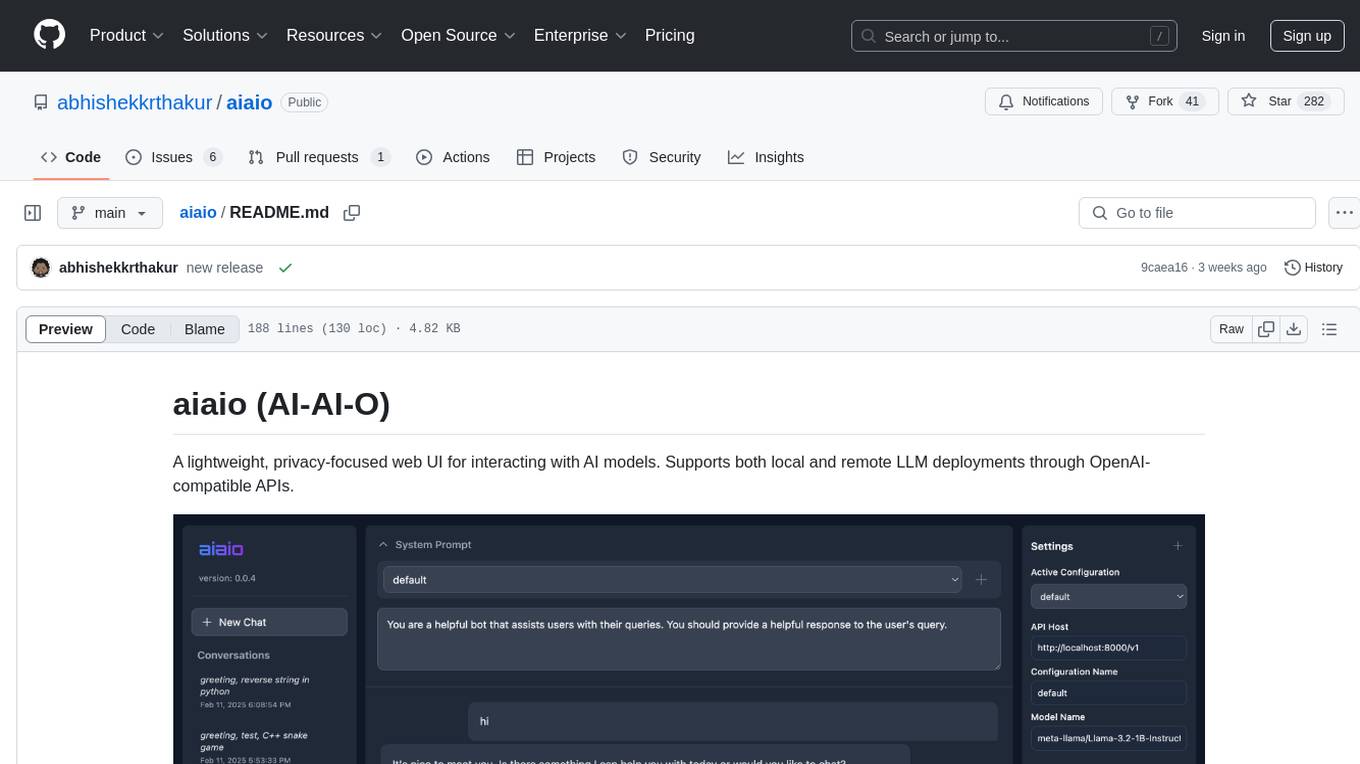
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
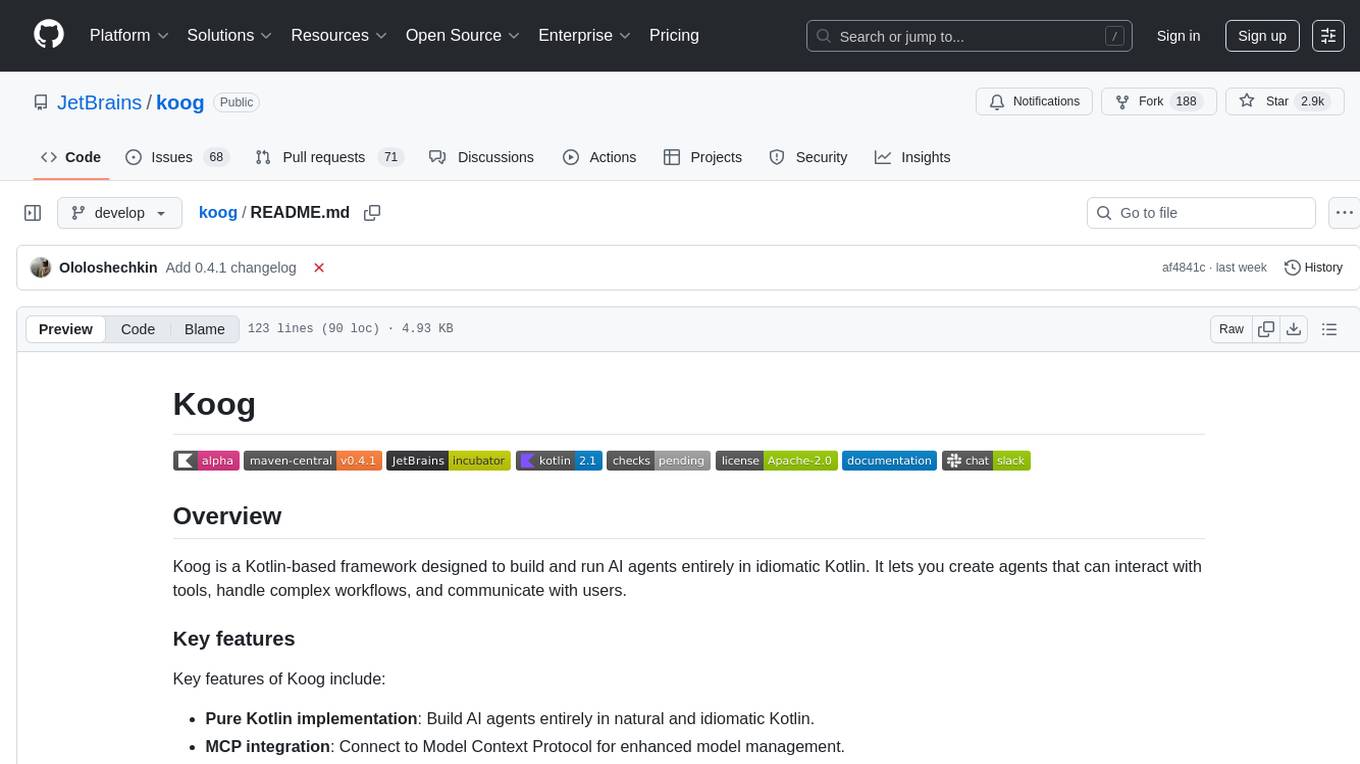
koog
Koog is a Kotlin-based framework for building and running AI agents entirely in idiomatic Kotlin. It allows users to create agents that interact with tools, handle complex workflows, and communicate with users. Key features include pure Kotlin implementation, MCP integration, embedding capabilities, custom tool creation, ready-to-use components, intelligent history compression, powerful streaming API, persistent agent memory, comprehensive tracing, flexible graph workflows, modular feature system, scalable architecture, and multiplatform support.
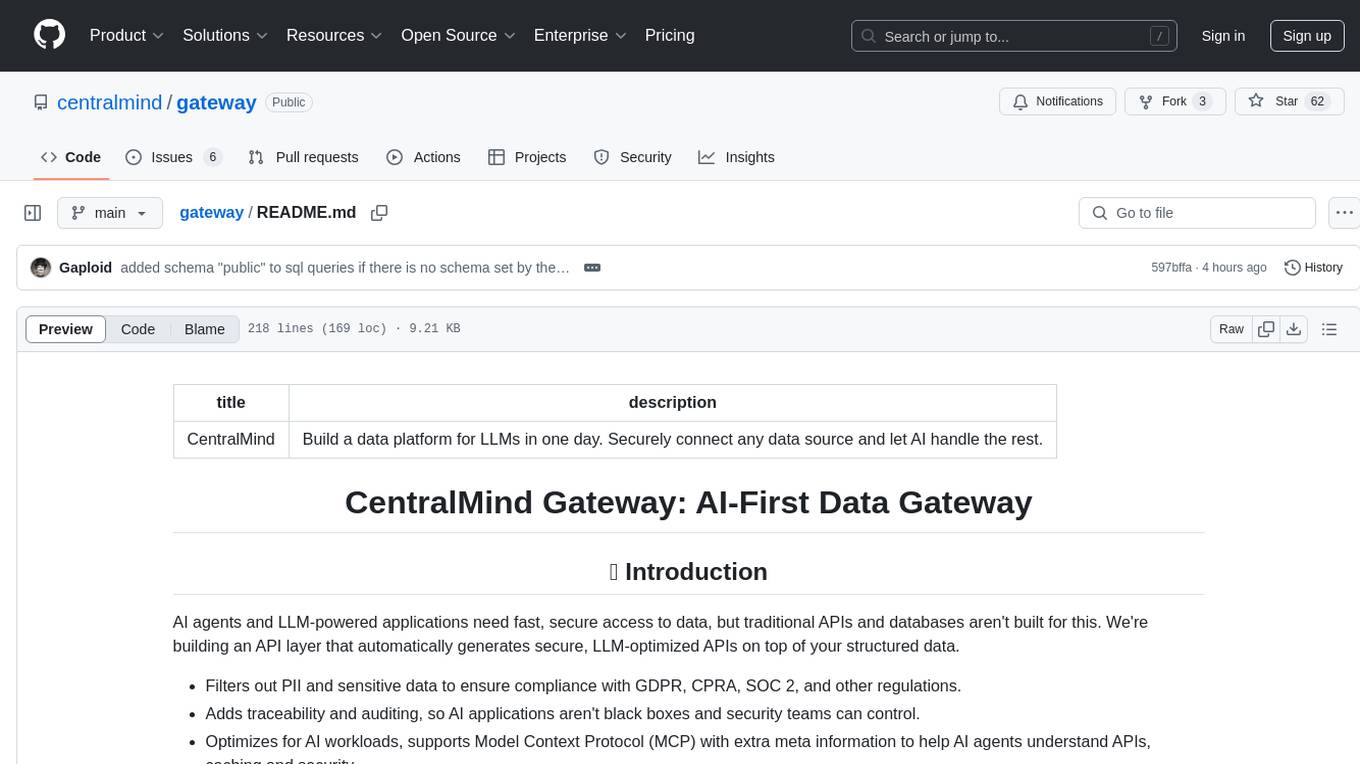
gateway
CentralMind Gateway is an AI-first data gateway that securely connects any data source and automatically generates secure, LLM-optimized APIs. It filters out sensitive data, adds traceability, and optimizes for AI workloads. Suitable for companies deploying AI agents for customer support and analytics.
resume-job-matcher
Resume Job Matcher is a Python script that automates the process of matching resumes to a job description using AI. It leverages the Anthropic Claude API or OpenAI's GPT API to analyze resumes and provide a match score along with personalized email responses for candidates. The tool offers comprehensive resume processing, advanced AI-powered analysis, in-depth evaluation & scoring, comprehensive analytics & reporting, enhanced candidate profiling, and robust system management. Users can customize font presets, generate PDF versions of unified resumes, adjust logging level, change scoring model, modify AI provider, and adjust AI model. The final score for each resume is calculated based on AI-generated match score and resume quality score, ensuring content relevance and presentation quality are considered. Troubleshooting tips, best practices, contribution guidelines, and required Python packages are provided.
VeritasGraph
VeritasGraph is an enterprise-grade graph RAG framework designed for secure, on-premise AI applications. It leverages a knowledge graph to perform complex, multi-hop reasoning, providing transparent, auditable reasoning paths with full source attribution. The framework excels at answering complex questions that traditional vector search engines struggle with, ensuring trust and reliability in enterprise AI. VeritasGraph offers full control over data and AI models, verifiable attribution for every claim, advanced graph reasoning capabilities, and open-source deployment with sovereignty and customization.
Agentarium
Agentarium is a powerful Python framework for managing and orchestrating AI agents with ease. It provides a flexible and intuitive way to create, manage, and coordinate interactions between multiple AI agents in various environments. The framework offers advanced agent management, robust interaction management, a checkpoint system for saving and restoring agent states, data generation through agent interactions, performance optimization, flexible environment configuration, and an extensible architecture for customization.
For similar tasks
haiku.rag
Haiku RAG is a Retrieval-Augmented Generation (RAG) library that utilizes LanceDB as a local vector database. It supports semantic and full-text search, hybrid search with Reciprocal Rank Fusion, multiple embedding and QA providers, default search result reranking, question answering, file monitoring, and various file formats. It can be used via CLI or Python API, and can serve as tools for AI assistants like Claude Desktop. The library offers features for document management and search, with detailed documentation available.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

supersonic
SuperSonic is a next-generation BI platform that integrates Chat BI (powered by LLM) and Headless BI (powered by semantic layer) paradigms. This integration ensures that Chat BI has access to the same curated and governed semantic data models as traditional BI. Furthermore, the implementation of both paradigms benefits from the integration: * Chat BI's Text2SQL gets augmented with context-retrieval from semantic models. * Headless BI's query interface gets extended with natural language API. SuperSonic provides a Chat BI interface that empowers users to query data using natural language and visualize the results with suitable charts. To enable such experience, the only thing necessary is to build logical semantic models (definition of metric/dimension/tag, along with their meaning and relationships) through a Headless BI interface. Meanwhile, SuperSonic is designed to be extensible and composable, allowing custom implementations to be added and configured with Java SPI. The integration of Chat BI and Headless BI has the potential to enhance the Text2SQL generation in two dimensions: 1. Incorporate data semantics (such as business terms, column values, etc.) into the prompt, enabling LLM to better understand the semantics and reduce hallucination. 2. Offload the generation of advanced SQL syntax (such as join, formula, etc.) from LLM to the semantic layer to reduce complexity. With these ideas in mind, we develop SuperSonic as a practical reference implementation and use it to power our real-world products. Additionally, to facilitate further development we decide to open source SuperSonic as an extensible framework.
chat-ollama
ChatOllama is an open-source chatbot based on LLMs (Large Language Models). It supports a wide range of language models, including Ollama served models, OpenAI, Azure OpenAI, and Anthropic. ChatOllama supports multiple types of chat, including free chat with LLMs and chat with LLMs based on a knowledge base. Key features of ChatOllama include Ollama models management, knowledge bases management, chat, and commercial LLMs API keys management.
ChatIDE
ChatIDE is an AI assistant that integrates with your IDE, allowing you to converse with OpenAI's ChatGPT or Anthropic's Claude within your development environment. It provides a seamless way to access AI-powered assistance while coding, enabling you to get real-time help, generate code snippets, debug errors, and brainstorm ideas without leaving your IDE.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.
xiaogpt
xiaogpt is a tool that allows you to play ChatGPT and other LLMs with Xiaomi AI Speaker. It supports ChatGPT, New Bing, ChatGLM, Gemini, Doubao, and Tongyi Qianwen. You can use it to ask questions, get answers, and have conversations with AI assistants. xiaogpt is easy to use and can be set up in a few minutes. It is a great way to experience the power of AI and have fun with your Xiaomi AI Speaker.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.