
context-cite
Attribute (or cite) statements generated by LLMs back to in-context information.
Stars: 110
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.
README:
![]()
[getting started]
[example notebooks]
[🤗 demo]
[blog post #1]
[blog post #2]
[paper]
[bib]
Maintainers: Ben Cohen-Wang, Harshay Shah, and Kristian Georgiev
context_cite is a tool for attributing statements generated by LLMs back to specific parts of the context.

Install context_cite via pip
pip install context_citeUsing context_cite is as simple as:
from context_cite import ContextCiter
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
context = """
Attention Is All You Need
Abstract
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
1 Introduction
Recurrent neural networks, long short-term memory [13] and gated recurrent [7] neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation [35, 2, 5]. Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures [38, 24, 15].
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states ht, as a function of the previous hidden state ht-1 and the input for position t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples. Recent work has achieved significant improvements in computational efficiency through factorization tricks [21] and conditional computation [32], while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences [2, 19]. In all but a few cases [27], however, such attention mechanisms are used in conjunction with a recurrent network.
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
"""
query = "What type of GPUs did the authors use in this paper?"
cc = ContextCiter.from_pretrained(model_name, context, query, device="cuda")We can check the model's response using
cc.response:
In [1]: cc.response
Out[1]: 'The authors used eight P100 GPUs in their Transformer architecture for training on the WMT 2014 English-to-German translation task.</s>'Where did the model get its information? Let's see what the attributions look like!
In [2]: cc.get_attributions(as_dataframe=True, top_k=5)
Out[2]:

Finally, let's try to attribute a specific part of the response. To do so, we specify a start_idx and end_idx corresponding to the range of the response that we would like to attribute.
In this case, we'll specify indices to attribute the phrase "the WMT 2014 English-to-German translation task" from the response.
In [3]: cc.get_attributions(start_idx=83, end_idx=129, as_dataframe=True, top_k=5)
Out[3]:

Try out context_cite using our example notebooks (you can open them in Google colab):
-
🤗 quickstart: a quick introduction to
context_cite -
🦜⛓️ RAG example: chaining
context_citewithin a simplelangchainRAG setup
@misc{cohenwang2024contextciteattributingmodelgeneration,
title={ContextCite: Attributing Model Generation to Context},
author={Benjamin Cohen-Wang and Harshay Shah and Kristian Georgiev and Aleksander Madry},
year={2024},
eprint={2409.00729},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2409.00729},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for context-cite
Similar Open Source Tools
context-cite
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.
Nucleoid
Nucleoid is a declarative (logic) runtime environment that manages both data and logic under the same runtime. It uses a declarative programming paradigm, which allows developers to focus on the business logic of the application, while the runtime manages the technical details. This allows for faster development and reduces the amount of code that needs to be written. Additionally, the sharding feature can help to distribute the load across multiple instances, which can further improve the performance of the system.

aligner
Aligner is a model-agnostic alignment tool designed to efficiently correct responses from large language models. It redistributes initial answers to align with human intentions, improving performance across various LLMs. The tool can be applied with minimal training, enhancing upstream models and reducing hallucination. Aligner's 'copy and correct' method preserves the base structure while enhancing responses. It achieves significant performance improvements in helpfulness, harmlessness, and honesty dimensions, with notable success in boosting Win Rates on evaluation leaderboards.
LLMSpeculativeSampling
This repository implements speculative sampling for large language model (LLM) decoding, utilizing two models - a target model and an approximation model. The approximation model generates token guesses, corrected by the target model, resulting in improved efficiency. It includes implementations of Google's and Deepmind's versions of speculative sampling, supporting models like llama-7B and llama-1B. The tool is designed for fast inference from transformers via speculative decoding.

llama3_interpretability_sae
This project focuses on implementing Sparse Autoencoders (SAEs) for mechanistic interpretability in Large Language Models (LLMs) like Llama 3.2-3B. The SAEs aim to untangle superimposed representations in LLMs into separate, interpretable features for each neuron activation. The project provides an end-to-end pipeline for capturing training data, training the SAEs, analyzing learned features, and verifying results experimentally. It includes comprehensive logging, visualization, and checkpointing of SAE training, interpretability analysis tools, and a pure PyTorch implementation of Llama 3.1/3.2 chat and text completion. The project is designed for scalability, efficiency, and maintainability.
agents
Agents 2.0 is a framework for training language agents using symbolic learning, inspired by connectionist learning for neural nets. It implements main components of connectionist learning like back-propagation and gradient-based weight update in the context of agent training using language-based loss, gradients, and weights. The framework supports optimizing multi-agent systems and allows multiple agents to take actions in one node.
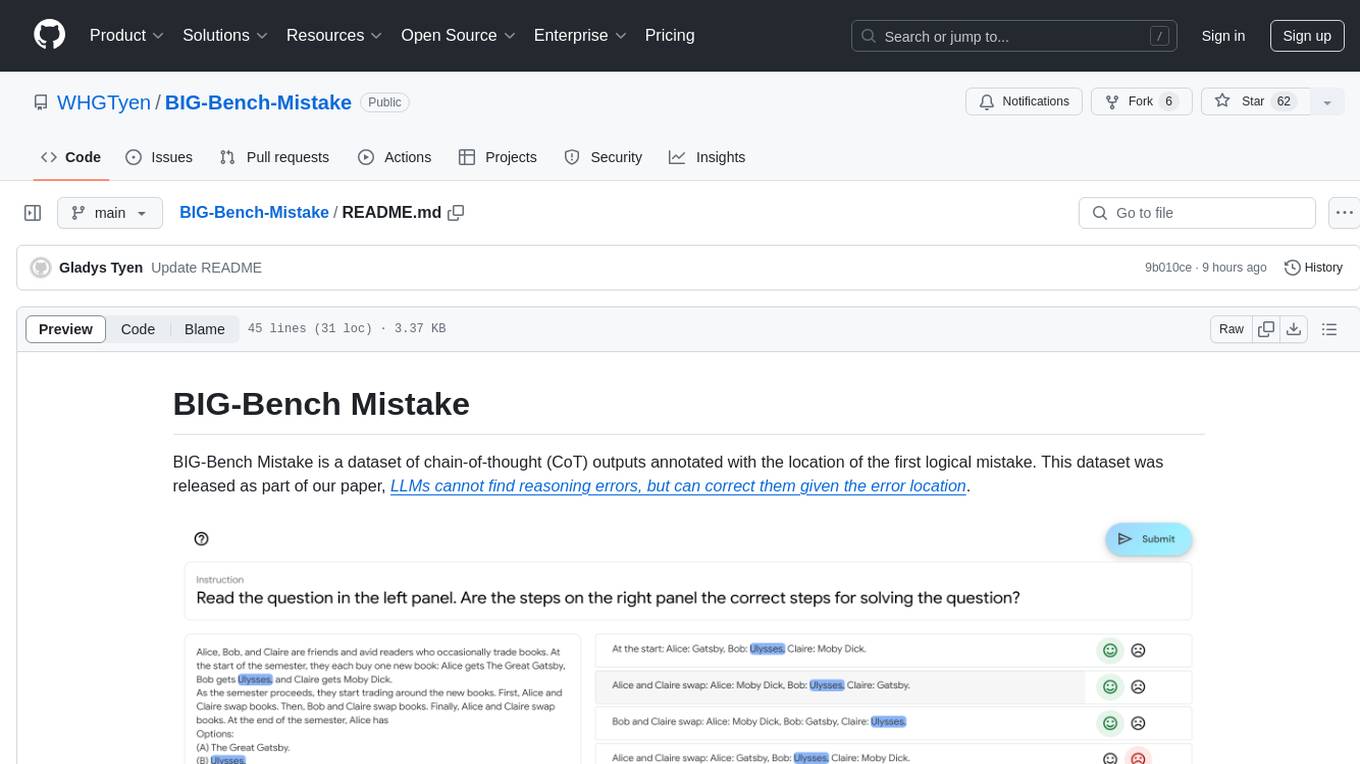
BIG-Bench-Mistake
BIG-Bench Mistake is a dataset of chain-of-thought (CoT) outputs annotated with the location of the first logical mistake. It was released as part of a research paper focusing on benchmarking LLMs in terms of their mistake-finding ability. The dataset includes CoT traces for tasks like Word Sorting, Tracking Shuffled Objects, Logical Deduction, Multistep Arithmetic, and Dyck Languages. Human annotators were recruited to identify mistake steps in these tasks, with automated annotation for Dyck Languages. Each JSONL file contains input questions, steps in the chain of thoughts, model's answer, correct answer, and the index of the first logical mistake.

long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.
PINNACLE
PINNACLE is a flexible geometric deep learning approach that trains on contextualized protein interaction networks to generate context-aware protein representations. It provides protein representations split across various cell-type contexts from different tissues and organs. The tool can be fine-tuned to study the genomic effects of drugs and nominate promising protein targets and cell-type contexts for further investigation. PINNACLE exemplifies the paradigm of incorporating context-specific effects for studying biological systems, especially the impact of disease and therapeutics.
LLM-Geo
LLM-Geo is an AI-powered geographic information system (GIS) that leverages Large Language Models (LLMs) for automatic spatial data collection, analysis, and visualization. By adopting LLM as the reasoning core, it addresses spatial problems with self-generating, self-organizing, self-verifying, self-executing, and self-growing capabilities. The tool aims to make spatial analysis easier, faster, and more accessible by reducing manual operation time and delivering accurate results through case studies. It uses GPT-4 API in a Python environment and advocates for further research and development in autonomous GIS.
AI4Animation
AI4Animation is a comprehensive framework for data-driven character animation, including data processing, neural network training, and runtime control, developed in Unity3D/PyTorch. It explores deep learning opportunities for character animation, covering biped and quadruped locomotion, character-scene interactions, sports and fighting games, and embodied avatar motions in AR/VR. The research focuses on generative frameworks, codebook matching, periodic autoencoders, animation layering, local motion phases, and neural state machines for character control and animation.
aihwkit
The IBM Analog Hardware Acceleration Kit is an open-source Python toolkit for exploring and using the capabilities of in-memory computing devices in the context of artificial intelligence. It consists of two main components: Pytorch integration and Analog devices simulator. The Pytorch integration provides a series of primitives and features that allow using the toolkit within PyTorch, including analog neural network modules, analog training using torch training workflow, and analog inference using torch inference workflow. The Analog devices simulator is a high-performant (CUDA-capable) C++ simulator that allows for simulating a wide range of analog devices and crossbar configurations by using abstract functional models of material characteristics with adjustable parameters. Along with the two main components, the toolkit includes other functionalities such as a library of device presets, a module for executing high-level use cases, a utility to automatically convert a downloaded model to its equivalent Analog model, and integration with the AIHW Composer platform. The toolkit is currently in beta and under active development, and users are advised to be mindful of potential issues and keep an eye for improvements, new features, and bug fixes in upcoming versions.

LongRoPE
LongRoPE is a method to extend the context window of large language models (LLMs) beyond 2 million tokens. It identifies and exploits non-uniformities in positional embeddings to enable 8x context extension without fine-tuning. The method utilizes a progressive extension strategy with 256k fine-tuning to reach a 2048k context. It adjusts embeddings for shorter contexts to maintain performance within the original window size. LongRoPE has been shown to be effective in maintaining performance across various tasks from 4k to 2048k context lengths.
matchem-llm
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry. It includes datasets related to chemistry, materials, multimodal data, and knowledge graphs in the field. The repository aims to provide resources for training and evaluating machine learning models in the materials science and chemistry domains.
For similar tasks

lmql
LMQL is a programming language designed for large language models (LLMs) that offers a unique way of integrating traditional programming with LLM interaction. It allows users to write programs that combine algorithmic logic with LLM calls, enabling model reasoning capabilities within the context of the program. LMQL provides features such as Python syntax integration, rich control-flow options, advanced decoding techniques, powerful constraints via logit masking, runtime optimization, sync and async API support, multi-model compatibility, and extensive applications like JSON decoding and interactive chat interfaces. The tool also offers library integration, flexible tooling, and output streaming options for easy model output handling.
context-cite
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.
promptmap
promptmap2 is a vulnerability scanning tool that automatically tests prompt injection attacks on custom LLM applications. It analyzes LLM system prompts, runs them, and sends attack prompts to determine if injection was successful. It has ready-to-use rules to steal system prompts or distract LLM applications. Supports multiple LLM providers like OpenAI, Anthropic, and open source models via Ollama. Customizable test rules in YAML format and automatic model download for Ollama.
GenAiGuidebook
GenAiGuidebook is a comprehensive resource for individuals looking to begin their journey in GenAI. It serves as a detailed guide providing insights, tips, and information on various aspects of GenAI technology. The guidebook covers a wide range of topics, including introductory concepts, practical applications, and best practices in the field of GenAI. Whether you are a beginner or an experienced professional, this resource aims to enhance your understanding and proficiency in GenAI.

ROGRAG
ROGRAG is a powerful open-source tool designed for data analysis and visualization. It provides a user-friendly interface for exploring and manipulating datasets, making it ideal for researchers, data scientists, and analysts. With ROGRAG, users can easily import, clean, analyze, and visualize data to gain valuable insights and make informed decisions. The tool supports a wide range of data formats and offers a variety of statistical and visualization tools to help users uncover patterns, trends, and relationships in their data. Whether you are working on exploratory data analysis, statistical modeling, or data visualization, ROGRAG is a versatile tool that can streamline your workflow and enhance your data analysis capabilities.
ExplainableAI.jl
ExplainableAI.jl is a Julia package that implements interpretability methods for black-box classifiers, focusing on local explanations and attribution maps in input space. The package requires models to be differentiable with Zygote.jl. It is similar to Captum and Zennit for PyTorch and iNNvestigate for Keras models. Users can analyze and visualize explanations for model predictions, with support for different XAI methods and customization. The package aims to provide transparency and insights into model decision-making processes, making it a valuable tool for understanding and validating machine learning models.
interpreto
Interpreto is an interpretability toolkit for large language models (LLMs) that provides a modular framework encompassing attribution methods, concept-based methods, and evaluation metrics. It includes various inference-based and gradient-based attribution methods for both classification and generation tasks. The toolkit also offers concept-based explanations to provide high-level interpretations of latent model representations through steps like concept discovery, interpretation, and concept-to-output attribution. Interpreto aims to enhance model interpretability and facilitate understanding of model decisions and outputs.
For similar jobs
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.

cladder
CLadder is a repository containing the CLadder dataset for evaluating causal reasoning in language models. The dataset consists of yes/no questions in natural language that require statistical and causal inference to answer. It includes fields such as question_id, given_info, question, answer, reasoning, and metadata like query_type and rung. The dataset also provides prompts for evaluating language models and example questions with associated reasoning steps. Additionally, it offers dataset statistics, data variants, and code setup instructions for using the repository.
awesome-llm-unlearning
This repository tracks the latest research on machine unlearning in large language models (LLMs). It offers a comprehensive list of papers, datasets, and resources relevant to the topic.
COLD-Attack
COLD-Attack is a framework designed for controllable jailbreaks on large language models (LLMs). It formulates the controllable attack generation problem and utilizes the Energy-based Constrained Decoding with Langevin Dynamics (COLD) algorithm to automate the search of adversarial LLM attacks with control over fluency, stealthiness, sentiment, and left-right-coherence. The framework includes steps for energy function formulation, Langevin dynamics sampling, and decoding process to generate discrete text attacks. It offers diverse jailbreak scenarios such as fluent suffix attacks, paraphrase attacks, and attacks with left-right-coherence.
Awesome-LLM-in-Social-Science
Awesome-LLM-in-Social-Science is a repository that compiles papers evaluating Large Language Models (LLMs) from a social science perspective. It includes papers on evaluating, aligning, and simulating LLMs, as well as enhancing tools in social science research. The repository categorizes papers based on their focus on attitudes, opinions, values, personality, morality, and more. It aims to contribute to discussions on the potential and challenges of using LLMs in social science research.

awesome-llm-attributions
This repository focuses on unraveling the sources that large language models tap into for attribution or citation. It delves into the origins of facts, their utilization by the models, the efficacy of attribution methodologies, and challenges tied to ambiguous knowledge reservoirs, biases, and pitfalls of excessive attribution.
context-cite
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.
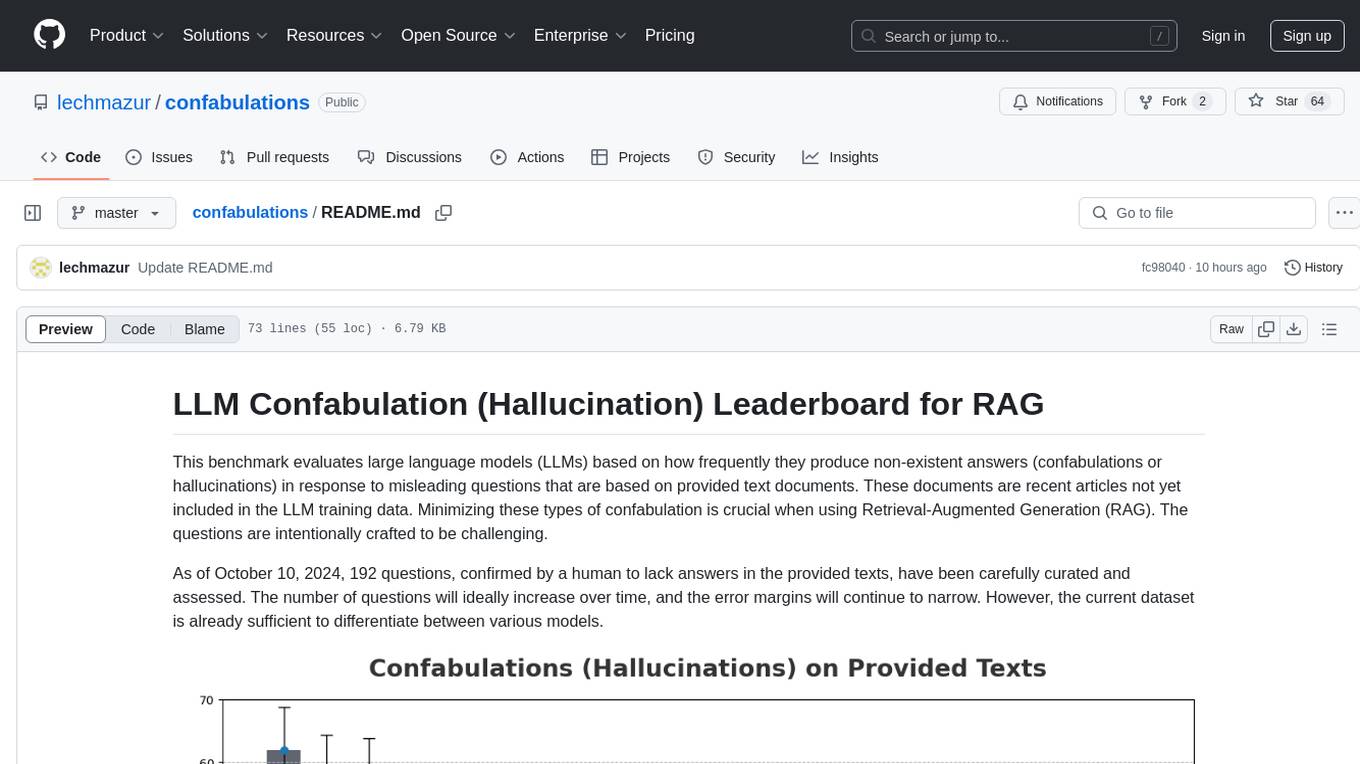
confabulations
LLM Confabulation Leaderboard evaluates large language models based on confabulations and non-response rates to challenging questions. It includes carefully curated questions with no answers in provided texts, aiming to differentiate between various models. The benchmark combines confabulation and non-response rates for comprehensive ranking, offering insights into model performance and tendencies. Additional notes highlight the meticulous human verification process, challenges faced by LLMs in generating valid responses, and the use of temperature settings. Updates and other benchmarks are also mentioned, providing a holistic view of the evaluation landscape.