
prometheus-eval
Evaluate your LLM's response with Prometheus 💯
Stars: 581
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.
README:
![]()

⚡ A repository for evaluating LLMs in generation tasks 🚀 ⚡
Latest News 🔥
-
[2024/05] We release Prometheus 2 (7B & 8x7B) models!
-
Prometheus 2 (8x7B) is an open-source state-of-the-art evaluator language model!
- Compared to Prometheus 1 (13B), Prometheus 2 (8x7B) shows improved evaluation performances & supports assessing in pairwise ranking (relative grading) formats as well!
- It achieves a Pearson correlation of 0.6 to 0.7 with GPT-4-1106 on a 5-point Likert scale across multiple direct assessment benchmarks, including VicunaBench, MT-Bench, and FLASK.
- It also scores a 72% to 85% agreement with human judgments across multiple pairwise ranking benchmarks, including HHH Alignment, MT Bench Human Judgment, and Auto-J Eval.
-
Prometheus 2 (7B) is a lighter version of Prometheus 2 (8x7B) model with reasonable performances (outperforming Llama-2-70B & on par with Mixtral-8x7B).
- It achieves at least 80% of the evaluation statistics or performances of Prometheus 2 (8x7B)
- It requires only 16 GB of VRAM, making it suitable for running on consumer GPUs.
-
Note: prometheus-eval library is currently in the beta stage. If you encounter any issues, please let us know by creating an issue on the repository.
Installation with pip:
- (Optional) We encourage you to install flash attention for efficient inference.
pip install flash-attn --no-build-isolation
pip install prometheus-evalWith
prometheus-eval, evaluating any instruction and response pair is as simple as:
# Absolute Grading: Outputs score of 1 to 5
from prometheus_eval import PrometheusEval
from prometheus_eval.prompts import ABSOLUTE_PROMPT, SCORE_RUBRIC_TEMPLATE
judge = PrometheusEval(model_id="prometheus-eval/prometheus-7b-v2.0", absolute_grade_template=ABSOLUTE_PROMPT)
instruction = "Struggling with a recent break-up, a person opens up about the intense feelings of loneliness and sadness. They ask for advice on how to cope with the heartbreak and move forward in life.",
response = "I'm genuinely sorry to hear about your break-up. This can be an immensely challenging time filled with intense emotions of loneliness and sorrow. It's important to remember that it's normal to experience these feelings; they are a testament to the deep connection you once had. Firstly, don't hesitate to embrace your emotions, let them flow freely. Ignoring them often complicates the healing process. It's natural to be upset, to shed tears, or to feel angry. This is all part of the journey towards healing. Self-care can be a healing balm in these tough times. This could mean indulging in your favourite book, journaling your thoughts, or even just a quiet cup of tea. Small acts of kindness to oneself can significantly improve your emotional well-being. Also, don't isolate yourself. Surround yourself with supportive individuals who can offer comfort and understanding. This might include friends, family, or even a mental health professional. They can provide much-needed emotional support and strategies to help you cope. Lastly, remember there's no set timeline for healing. It's different for everyone and it's okay to take as long as you need. Keep your focus on the future and the potential it holds. Though it may not seem possible now, you will emerge stronger from this experience. It's okay to ask for help, it's okay to grieve, and it's okay to take it one day at a time. You're not alone in this journey, and there are people ready and willing to help. It's okay to heal at your own pace.",
reference_answer = "I can only imagine how difficult this time must be for you. Heartbreak can feel like an overwhelming wave that washes over you, making you feel lost and alone. It's important to remember that it's okay to feel this way; your feelings are valid and it's natural to grieve the loss of a relationship. Firstly, it's crucial to allow yourself to feel the emotions fully. Suppressing or denying them often only prolongs the healing process. It's okay to cry, to feel sad, or to be angry. These are all part of the healing journey. Engaging in self-care activities can also provide a much-needed boost. This could be anything from taking a warm bath, writing in a journal, or simply drinking a cup of your favorite tea. Small acts of self-love can make a big difference in how you feel. Next, try to surround yourself with supportive people who understand your situation and provide comfort. Friends and family can be a great source of strength in times of heartbreak. If you feel comfortable, you might want to consider seeking professional help. Therapists and counselors are trained to provide assistance and tools to navigate through difficult times like these. Lastly, it's important to remember that it's okay to take your time to heal. Everyone has their own pace and there's no rush. Try to focus on the future and the possibilities it holds. While it may not seem like it now, you will come out stronger and more resilient from this experience. Remember, it's okay to ask for help and it's okay to feel the way you feel. You are not alone in this journey and there are people who care about you and want to help. It's okay to take one day at a time. Healing is a process, and it's okay to move through it at your own pace.",
rubric_data = {
"criteria":"Is the model proficient in applying empathy and emotional intelligence to its responses when the user conveys emotions or faces challenging circumstances?",
"score1_description":"The model neglects to identify or react to the emotional tone of user inputs, giving responses that are unfitting or emotionally insensitive.",
"score2_description":"The model intermittently acknowledges emotional context but often responds without sufficient empathy or emotional understanding.",
"score3_description":"The model typically identifies emotional context and attempts to answer with empathy, yet the responses might sometimes miss the point or lack emotional profundity.",
"score4_description":"The model consistently identifies and reacts suitably to emotional context, providing empathetic responses. Nonetheless, there may still be sporadic oversights or deficiencies in emotional depth.",
"score5_description":"The model excels in identifying emotional context and persistently offers empathetic, emotionally aware responses that demonstrate a profound comprehension of the user's emotions or situation."
}
score_rubric = SCORE_RUBRIC_TEMPLATE.format(**rubric_data)
feedback, score = judge.single_absolute_grade(
instruction=instruction,
response=response,
rubric=score_rubric,
reference_answer=reference_answer
)
print("Feedback:", feedback)
print("Score:", score)
# Output
# Feedback: The response provided shows a high level of empathy and emotional intelligence. It effectively addresses the emotional distress expressed by the user. It acknowledges the user's pain and validates their feelings of loneliness and sadness, which is a crucial aspect of providing empathetic advice. The response also suggests practical steps for coping, such as embracing emotions, practicing self-care, and seeking support from friends, family, or professionals. Furthermore, the response reassures the user that healing is a personal process with no fixed timeline, offering comfort and understanding. It emphasizes the user's worth and potential to overcome the situation, which demonstrates a profound comprehension of the user's emotions and situation. By comparing the score rubric with the provided response, it is clear that the model exhibits an excellent ability to apply empathy and emotional intelligence. The response does not have any deficiencies in emotional depth and successfully meets the criteria for a score of 5.
# Score: 5# Relative Grading: Outputs A or B
from prometheus_eval import PrometheusEval
from prometheus_eval.prompts import RELATIVE_PROMPT
judge = PrometheusEval(model_id="prometheus-eval/prometheus-7b-v2.0", relative_grade_template=RELATIVE_PROMPT)
data = {
"instruction": "A group of historians are conducting a debate on the factors that led to the fall of the Roman Empire. One historian argues that the primary reason for the fall was the constant pressure from barbarian invasions. Another one believes it was because of economic troubles and overreliance on slave labor. A third one suggests it was due to moral decay and political instability. Each historian needs to provide evidence to support their claims. How would the historian arguing for economic troubles and overreliance on slave labor present their case?",
"response_A": "The historian arguing that economic troubles and overreliance on slave labor led to the fall of the Roman Empire would say this: The Empire's economy was heavily affected by the devaluation of Roman currency. This currency debasement resulted in rampant inflation, disrupting the stability of the economy. Additionally, the Roman Empire heavily depended on slave labor. This caused unemployment among free citizens because maintaining slaves was cheaper than hiring free citizens. The decline in employment opportunities resulted in economic instability. On top of these, the empire's expansion towards the east made them reliant on imports, like grain from Egypt. This over-dependency on imports caused a trade deficit, which further weakened the economy. As the empire lost territories, maintaining the trade imbalance became difficult, causing economic downfall. Thus, the economic troubles and overreliance on slave labor were among the main reasons for the fall of the Roman Empire.",
"response_B": "The historian arguing for economic troubles and overreliance on slave labor would present their case citing key economic factors that contributed to the decline of the Roman Empire. Harper (2016) outlined how the devaluation of Roman currency led to inflation, disrupting economic stability. Additionally, Scheidel (2007) emphasized that the overuse of slaves resulted in widespread unemployment among free citizens, destabilizing the economy further. The empire's dependency on grain imports from Egypt, creating a trade deficit as highlighted by Temin (2006), also contributed to the economic decline. Thus, the combination of these factors played a crucial role in the fall of the Roman Empire.",
"reference_answer": "This argument focuses on the economic troubles and overreliance on slave labor as primary reasons for the fall of the Roman Empire. To start with, one of the significant pieces of evidence is the devaluation of Roman currency. As highlighted by Harper (2016), the empire suffered from severe inflation due to the constant debasement of their currency, making it difficult for the economy to remain stable. Moreover, the overreliance on slave labor also played a detrimental role. As pointed out by Scheidel (2007), the dependence on slaves led to unemployment among free Roman citizens. This is because slaves were significantly cheaper to maintain compared to hiring free citizens, leading to a decline in job opportunities, which in turn resulted in economic instability. Furthermore, the empire's expansion to the east made them highly dependent on imports, for instance, grain from Egypt. As noted by Temin (2006), this created a trade deficit that further weakened the Roman economy. When the empire began to lose its territories, it became increasingly difficult to maintain this trade imbalance, leading to economic decline. In conclusion, it can be argued that the economic troubles, mainly due to the devaluation of currency and overreliance on slave labor, were significant contributing factors to the fall of the Roman Empire. The evidence provided, which includes scholarly references to Harper (2016), Scheidel (2007), and Temin (2006), supports this thesis.",
"rubric": "Is the answer well supported with evidence, including citations/attributions wherever relevant?"
}
feedback, score = judge.single_relative_grade(**data)
print("Feedback:", feedback)
print("Score:", score)
# Output
# Feedback: Both Response A and Response B correctly identify economic troubles and overreliance on slave labor as significant contributing factors to the fall of the Roman Empire. However, Response B is more effective in presenting the historian's argument due to its inclusion of scholarly sources to back up its claims. Specifically, it references works by Harper, Scheidel, and Temin, which adds credibility to the historian's argument and aligns well with the score rubric's emphasis on evidence and citations. While Response A provides a similar argument, it lacks any form of citations or attributions, which lessens the strength of the evidence presented. Therefore, based on the provided rubric, Response B is the superior response due to its use of scholarly evidence to support the historian's claims.
# Score: BNote: If you have multiple responses to grade, don't use single_absolute_grade / single_relative_grade - instead, use absolute_grade and relative_grade! It will give you more than 10x speedup. Refer to the documentation here!
instructions = [...] # List of instructions
responses = [...] # List of responses
reference_answers = [...] # List of reference answers
rubric = "..." # Rubric string
feedbacks, scores = judge.absolute_grade(
instructions=instructions,
responses=responses,
rubric=rubric,
reference_answers=reference_answers
)Prometheus-Eval🔥 is a repository that provides a collection of tools for training, evaluating, and using language models specialized in evaluating other language models. The repository includes the following components:
- The
prometheus-evalPython package, which provides a simple interface for evaluating instruction-response pairs using Prometheus. - Collection of evaluation datasets for training and evaluating Prometheus models.
- Scripts for training Prometheus models or fine-tuning on custom datasets.
Prometheus🔥 is a family of open-source language models specialized in evaluating other language models. By effectively simulating human judgments and proprietary LM-based evaluations, we aim to resolve the following issues:
-
Fairness: Not relying on closed-source models for evaluations!
-
Controllability: You don’t have to worry about GPT version updates or sending your private data to OpenAI by constructing internal evaluation pipelines
-
Affordability: If you already have GPUs, it is free to use!

Compared to the Prometheus 1 models, the Prometheus 2 models support both direct assessment (absolute grading) and pairwise ranking (relative grading).
You could switch modes by providing a different input prompt format and system prompt. Within the prompt, you should fill in the instruction, response(s), and score rubrics with your own data. Optionally, you could also add a reference answer which leads to better performance!

The prometheus-eval package provides a simple interface for evaluating instruction-response pairs using Prometheus. The package includes the following methods:
-
absolute_grade: Evaluates a single response based on a given instruction, reference answer, and score rubric. Outputs a score between 1 and 5. -
relative_grade: Evaluates two responses based on a given instruction and score rubric. Outputs 'A' or 'B' based on the better response.
If you prefer directly working with the weights uploaded in Huggingface Hub, you can directly download the model weights!
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("prometheus-eval/prometheus-7b-v2.0")
tokenizer = AutoTokenizer.from_pretrained("prometheus-eval/prometheus-7b-v2.0")
ABS_SYSTEM_PROMPT = "You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria, ensuring each assessment reflects the absolute standards set for performance."
ABSOLUTE_PROMPT = """###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: "Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
{instruction}
###Response to evaluate:
{response}
###Reference Answer (Score 5):
{reference_answer}
###Score Rubrics:
{rubric}
###Feedback: """
user_content = ABS_SYSTEM_PROMPT + "\n\n" + ABSOLUTE_PROMPT.format(...) # Fill the prompt with your data
messages = [
{"role": "user", "content": user_content},
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
| Section | Description |
|---|---|
| Documentation | WIP |
| Custom Benchmark Evaluation | WIP |
| Evaluation for Evaluator LMs | WIP |
| Training Prometheus | WIP |
| Collection of Prompts | WIP |
The underlying codebase for training originates from Huggingface's Alignment Handbook and Super Mario Merging repository. Also, for inference, it heavily utilizes the vllm and the transformer library. Huge thanks to all the contributors for these awesome repositories!! 🙌
If you find our work useful, please consider citing our paper!
@misc{kim2024prometheus,
title={Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models},
author={Seungone Kim and Juyoung Suk and Shayne Longpre and Bill Yuchen Lin and Jamin Shin and Sean Welleck and Graham Neubig and Moontae Lee and Kyungjae Lee and Minjoon Seo},
year={2024},
eprint={2405.01535},
archivePrefix={arXiv},
primaryClass={cs.CL}
}@article{kim2023prometheus,
title={Prometheus: Inducing Fine-grained Evaluation Capability in Language Models},
author={Kim, Seungone and Shin, Jamin and Cho, Yejin and Jang, Joel and Longpre, Shayne and Lee, Hwaran and Yun, Sangdoo and Shin, Seongjin and Kim, Sungdong and Thorne, James and others},
journal={arXiv preprint arXiv:2310.08491},
year={2023}
}@misc{lee2024prometheusvision,
title={Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation},
author={Seongyun Lee and Seungone Kim and Sue Hyun Park and Geewook Kim and Minjoon Seo},
year={2024},
eprint={2401.06591},
archivePrefix={arXiv},
primaryClass={cs.CL}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for prometheus-eval
Similar Open Source Tools
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.

TinyTroupe
TinyTroupe is an experimental Python library that leverages Large Language Models (LLMs) to simulate artificial agents called TinyPersons with specific personalities, interests, and goals in simulated environments. The focus is on understanding human behavior through convincing interactions and customizable personas for various applications like advertisement evaluation, software testing, data generation, project management, and brainstorming. The tool aims to enhance human imagination and provide insights for better decision-making in business and productivity scenarios.
chatgpt-universe
ChatGPT is a large language model that can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in a conversational way. It is trained on a massive amount of text data, and it is able to understand and respond to a wide range of natural language prompts. Here are 5 jobs suitable for this tool, in lowercase letters: 1. content writer 2. chatbot assistant 3. language translator 4. creative writer 5. researcher

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

raft
RAFT (Retrieval-Augmented Fine-Tuning) is a method for creating conversational agents that realistically emulate specific human targets. It involves a dual-phase process of fine-tuning and retrieval-based augmentation to generate nuanced and personalized dialogue. The tool is designed to combine interview transcripts with memories from past writings to enhance language model responses. RAFT has the potential to advance the field of personalized, context-sensitive conversational agents.
claudine
Claudine is an AI agent designed to reason and act autonomously, leveraging the Anthropic API, Unix command line tools, HTTP, local hard drive data, and internet data. It can administer computers, analyze files, implement features in source code, create new tools, and gather contextual information from the internet. Users can easily add specialized tools. Claudine serves as a blueprint for implementing complex autonomous systems, with potential for customization based on organization-specific needs. The tool is based on the anthropic-kotlin-sdk and aims to evolve into a versatile command line tool similar to 'git', enabling branching sessions for different tasks.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.

FigStep
FigStep is a black-box jailbreaking algorithm against large vision-language models (VLMs). It feeds harmful instructions through the image channel and uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. The tool highlights the vulnerability of VLMs to jailbreaking attacks, emphasizing the need for safety alignments between visual and textual modalities.
Auto-Data
Auto Data is a library designed for the automatic generation of realistic datasets, essential for the fine-tuning of Large Language Models (LLMs). This highly efficient and lightweight library enables the swift and effortless creation of comprehensive datasets across various topics, regardless of their size. It addresses challenges encountered during model fine-tuning due to data scarcity and imbalance, ensuring models are trained with sufficient examples.
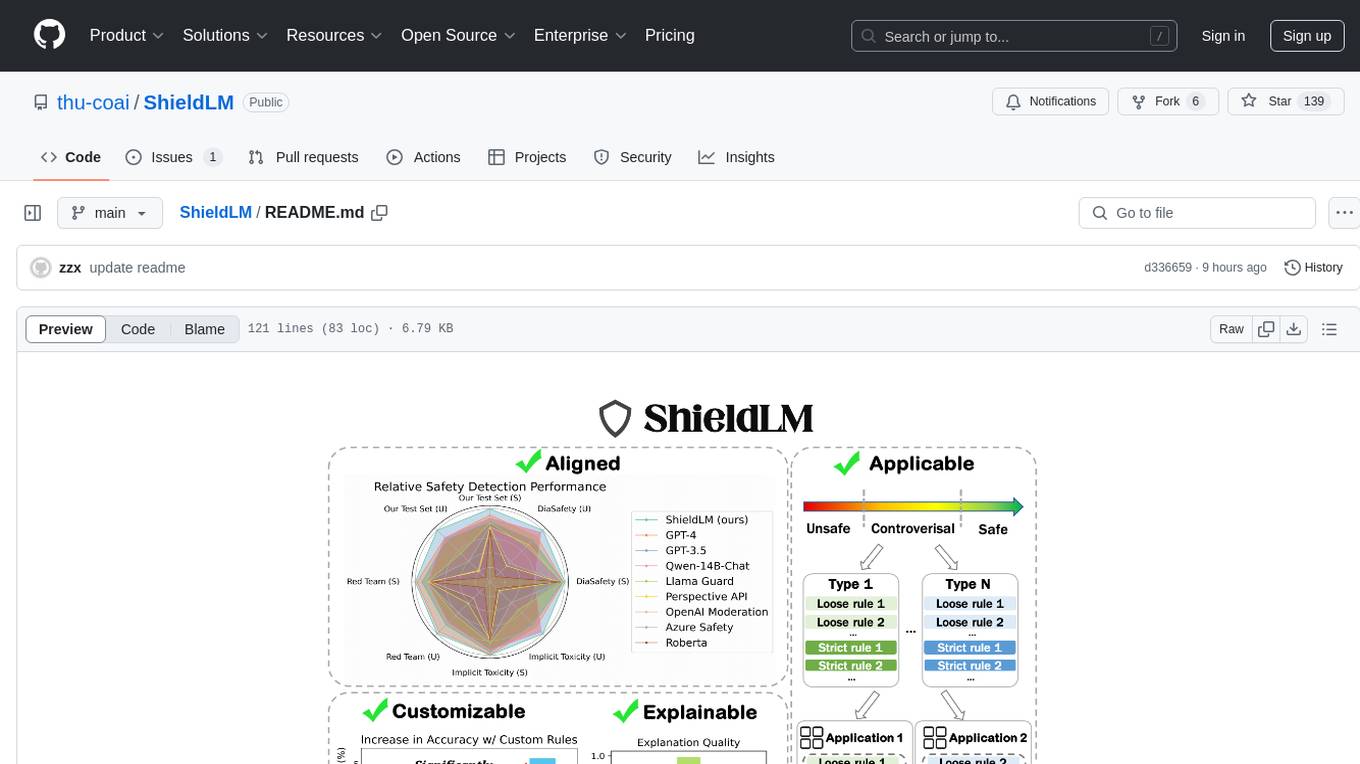
ShieldLM
ShieldLM is a bilingual safety detector designed to detect safety issues in LLMs' generations. It aligns with human safety standards, supports customizable detection rules, and provides explanations for decisions. Outperforming strong baselines, ShieldLM is impressive across 4 test sets.
llm-adaptive-attacks
This repository contains code and results for jailbreaking leading safety-aligned LLMs with simple adaptive attacks. We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. We demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token ``Sure''), potentially with multiple restarts. In this way, we achieve nearly 100% attack success rate---according to GPT-4 as a judge---on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models---that do not expose logprobs---via either a transfer or prefilling attack with 100% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models---a task that shares many similarities with jailbreaking---which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection).

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.
LLM-RGB
LLM-RGB is a repository containing a collection of detailed test cases designed to evaluate the reasoning and generation capabilities of Language Learning Models (LLMs) in complex scenarios. The benchmark assesses LLMs' performance in understanding context, complying with instructions, and handling challenges like long context lengths, multi-step reasoning, and specific response formats. Each test case evaluates an LLM's output based on context length difficulty, reasoning depth difficulty, and instruction compliance difficulty, with a final score calculated for each test case. The repository provides a score table, evaluation details, and quick start guide for running evaluations using promptfoo testing tools.
gptauthor
GPT Author is a command-line tool designed to help users write long form, multi-chapter stories by providing a story prompt and generating a synopsis and subsequent chapters using ChatGPT. Users can review and make changes to the generated content before finalizing the story output in Markdown and HTML formats. The tool aims to unleash storytelling genius by combining human input with AI-generated content, offering a seamless writing experience for creating engaging narratives.
For similar tasks
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.

Reflection_Tuning
Reflection-Tuning is a project focused on improving the quality of instruction-tuning data through a reflection-based method. It introduces Selective Reflection-Tuning, where the student model can decide whether to accept the improvements made by the teacher model. The project aims to generate high-quality instruction-response pairs by defining specific criteria for the oracle model to follow and respond to. It also evaluates the efficacy and relevance of instruction-response pairs using the r-IFD metric. The project provides code for reflection and selection processes, along with data and model weights for both V1 and V2 methods.

llm-verified-with-monte-carlo-tree-search
This prototype synthesizes verified code with an LLM using Monte Carlo Tree Search (MCTS). It explores the space of possible generation of a verified program and checks at every step that it's on the right track by calling the verifier. This prototype uses Dafny, Coq, Lean, Scala, or Rust. By using this technique, weaker models that might not even know the generated language all that well can compete with stronger models.

flashinfer
FlashInfer is a library for Language Languages Models that provides high-performance implementation of LLM GPU kernels such as FlashAttention, PageAttention and LoRA. FlashInfer focus on LLM serving and inference, and delivers state-the-art performance across diverse scenarios.

dolma
Dolma is a dataset and toolkit for curating large datasets for (pre)-training ML models. The dataset consists of 3 trillion tokens from a diverse mix of web content, academic publications, code, books, and encyclopedic materials. The toolkit provides high-performance, portable, and extensible tools for processing, tagging, and deduplicating documents. Key features of the toolkit include built-in taggers, fast deduplication, and cloud support.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.
For similar jobs
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.

cladder
CLadder is a repository containing the CLadder dataset for evaluating causal reasoning in language models. The dataset consists of yes/no questions in natural language that require statistical and causal inference to answer. It includes fields such as question_id, given_info, question, answer, reasoning, and metadata like query_type and rung. The dataset also provides prompts for evaluating language models and example questions with associated reasoning steps. Additionally, it offers dataset statistics, data variants, and code setup instructions for using the repository.
awesome-llm-unlearning
This repository tracks the latest research on machine unlearning in large language models (LLMs). It offers a comprehensive list of papers, datasets, and resources relevant to the topic.
COLD-Attack
COLD-Attack is a framework designed for controllable jailbreaks on large language models (LLMs). It formulates the controllable attack generation problem and utilizes the Energy-based Constrained Decoding with Langevin Dynamics (COLD) algorithm to automate the search of adversarial LLM attacks with control over fluency, stealthiness, sentiment, and left-right-coherence. The framework includes steps for energy function formulation, Langevin dynamics sampling, and decoding process to generate discrete text attacks. It offers diverse jailbreak scenarios such as fluent suffix attacks, paraphrase attacks, and attacks with left-right-coherence.
Awesome-LLM-in-Social-Science
Awesome-LLM-in-Social-Science is a repository that compiles papers evaluating Large Language Models (LLMs) from a social science perspective. It includes papers on evaluating, aligning, and simulating LLMs, as well as enhancing tools in social science research. The repository categorizes papers based on their focus on attitudes, opinions, values, personality, morality, and more. It aims to contribute to discussions on the potential and challenges of using LLMs in social science research.

awesome-llm-attributions
This repository focuses on unraveling the sources that large language models tap into for attribution or citation. It delves into the origins of facts, their utilization by the models, the efficacy of attribution methodologies, and challenges tied to ambiguous knowledge reservoirs, biases, and pitfalls of excessive attribution.
context-cite
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.
confabulations
LLM Confabulation Leaderboard evaluates large language models based on confabulations and non-response rates to challenging questions. It includes carefully curated questions with no answers in provided texts, aiming to differentiate between various models. The benchmark combines confabulation and non-response rates for comprehensive ranking, offering insights into model performance and tendencies. Additional notes highlight the meticulous human verification process, challenges faced by LLMs in generating valid responses, and the use of temperature settings. Updates and other benchmarks are also mentioned, providing a holistic view of the evaluation landscape.