
awesome-llm-unlearning
A resource repository for machine unlearning in large language models
Stars: 149
This repository tracks the latest research on machine unlearning in large language models (LLMs). It offers a comprehensive list of papers, datasets, and resources relevant to the topic.
README:




This repository tracks the latest research on machine unlearning in large language models (LLMs). The goal is to offer a comprehensive list of papers and resources relevant to the topic.
[!NOTE] If you believe your paper on LLM unlearning is not included, or if you find a mistake, typo, or information that is not up to date, please open an issue or submit a pull request, and I will be happy to update the list.
-
An Adversarial Perspective on Machine Unlearning for AI Safety
- Author(s): Jakub Łucki, Boyi Wei, Yangsibo Huang, Peter Henderson, Florian Tramèr, Javier Rando
- Date: 2024-09
- Venue: -
- Code:
-
Alternate Preference Optimization for Unlearning Factual Knowledge in Large Language Models
- Author(s): Anmol Mekala, Vineeth Dorna, Shreya Dubey, Abhishek Lalwani, David Koleczek, Mukund Rungta, Sadid Hasan, Elita Lobo
- Date: 2024-09
- Venue: -
- Code: -
-
LLM Surgery: Efficient Knowledge Unlearning and Editing in Large Language Models
- Author(s): Akshaj Kumar Veldanda, Shi-Xiong Zhang, Anirban Das, Supriyo Chakraborty, Stephen Rawls, Sambit Sahu, Milind Naphade
- Date: 2024-09
- Venue: -
- Code: -
-
MEOW: MEMOry Supervised LLM Unlearning Via Inverted Facts
- Author(s): Tianle Gu, Kexin Huang, Ruilin Luo, Yuanqi Yao, Yujiu Yang, Yan Teng, Yingchun Wang
- Date: 2024-09
- Venue: -
- Code: -
-
Unforgettable Generalization in Language Models
- Author(s): Eric Zhang, Leshem Chosen, Jacob Andreas
- Date: 2024-09
- Venue: COLM 2024
- Code: -
-
Forget to Flourish: Leveraging Machine-Unlearning on Pretrained Language Models for Privacy Leakage
- Author(s): Md Rafi Ur Rashid, Jing Liu, Toshiaki Koike-Akino, Shagufta Mehnaz, Ye Wang
- Date: 2024-08
- Venue: -
- Code: -
-
LLM Defenses Are Not Robust to Multi-Turn Human Jailbreaks Yet
- Author(s): Nathaniel Li, Ziwen Han, Ian Steneker, Willow Primack, Riley Goodside, Hugh Zhang, Zifan Wang, Cristina Menghini, Summer Yue
- Date: 2024-08
- Venue: -
- Code: -
-
Unlearning Trojans in Large Language Models: A Comparison Between Natural Language and Source Code
- Author(s): Mahdi Kazemi, Aftab Hussain, Md Rafiqul Islam Rabin, Mohammad Amin Alipour, Sen Lin
- Date: 2024-08
- Venue: -
- Code: -
-
Towards Robust Knowledge Unlearning: An Adversarial Framework for Assessing and Improving Unlearning Robustness in Large Language Models
- Author(s): Hongbang Yuan, Zhuoran Jin, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
- Date: 2024-08
- Venue: -
- Code: -
-
A Population-to-individual Tuning Framework for Adapting Pretrained LM to On-device User Intent Prediction
- Author(s): Jiahui Gong, Jingtao Ding, Fanjin Meng, Guilong Chen, Hong Chen, Shen Zhao, Haisheng Lu, Yong Li
- Date: 2024-08
- Venue: -
- Code: -
-
WPN: An Unlearning Method Based on N-pair Contrastive Learning in Language Models
- Author(s): Guitao Chen, Yunshen Wang, Hongye Sun, Guang Chen
- Date: 2024-08
- Venue: -
- Code: -
-
Towards Robust and Cost-Efficient Knowledge Unlearning for Large Language Models
- Author(s): Sungmin Cha, Sungjun Cho, Dasol Hwang, Moontae Lee
- Date: 2024-08
- Venue: -
- Code: -
-
On Effects of Steering Latent Representation for Large Language Model Unlearning
- Author(s): Dang Huu-Tien, Trung-Tin Pham, Hoang Thanh-Tung, Naoya Inoue
- Date: 2024-08
- Venue: -
- Code: -
-
Hotfixing Large Language Models for Code
- Author(s): Zhou Yang, David Lo
- Date: 2024-08
- Venue: -
- Code: -
-
UNLEARN Efficient Removal of Knowledge in Large Language Models
- Author(s): Tyler Lizzo, Larry Heck
- Date: 2024-08
- Venue: -
- Code: -
-
Tamper-Resistant Safeguards for Open-Weight LLMs
- Author(s): Rishub Tamirisa, Bhrugu Bharathi, Long Phan, Andy Zhou, Alice Gatti, Tarun Suresh, Maxwell Lin, Justin Wang, Rowan Wang, Ron Arel, Andy Zou, Dawn Song, Bo Li, Dan Hendrycks, Mantas Mazeika
- Date: 2024-08
- Venue: -
- Code:
-
On the Limitations and Prospects of Machine Unlearning for Generative AI
- Author(s): Shiji Zhou, Lianzhe Wang, Jiangnan Ye, Yongliang Wu, Heng Chang
- Date: 2024-08
- Venue: -
- Code: -
-
Learn while Unlearn: An Iterative Unlearning Framework for Generative Language Models
- Author(s): Haoyu Tang, Ye Liu, Xukai Liu, Kai Zhang, Yanghai Zhang, Qi Liu, Enhong Chen
- Date: 2024-07
- Venue: -
- Code:
-
Demystifying Verbatim Memorization in Large Language Models
- Author(s): Jing Huang, Diyi Yang, Christopher Potts
- Date: 2024-07
- Venue: -
- Code: -
-
Revisiting Who's Harry Potter: Towards Targeted Unlearning from a Causal Intervention Perspective
- Author(s): Yujian Liu, Yang Zhang, Tommi Jaakkola, Shiyu Chang
- Date: 2024-07
- Venue: -
- Code:
-
Towards Transfer Unlearning: Empirical Evidence of Cross-Domain Bias Mitigation
- Author(s): Huimin Lu, Masaru Isonuma, Junichiro Mori, Ichiro Sakata
- Date: 2024-07
- Venue: -
- Cdoe: -
-
Targeted Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs
- Author(s): Abhay Sheshadri, Aidan Ewart, Phillip Guo, Aengus Lynch, Cindy Wu, Vivek Hebbar, Henry Sleight, Asa Cooper Stickland, Ethan Perez, Dylan Hadfield-Menell, Stephen Casper
- Date: 2024-07
- Venue: -
- Code:
-
What Makes and Breaks Safety Fine-tuning? A Mechanistic Study
- Author(s): Samyak Jain, Ekdeep Singh Lubana, Kemal Oksuz, Tom Joy, Philip H.S. Torr, Amartya Sanyal, Puneet K. Dokania
- Date: 2024-07
- Venue: -
- Code: -
-
Practical Unlearning for Large Language Models
- Author(s): Chongyang Gao, Lixu Wang, Chenkai Weng, Xiao Wang, Qi Zhu
- Date: 2024-07
- Venue: -
- Code: -
-
Learning to Refuse: Towards Mitigating Privacy Risks in LLMs
- Author(s): Zhenhua Liu, Tong Zhu, Chuanyuan Tan, Wenliang Chen
- Date: 2024-07
- Venue: -
- Code:
-
Composable Interventions for Language Models
- Author(s): Arinbjorn Kolbeinsson, Kyle O'Brien, Tianjin Huang, Shanghua Gao, Shiwei Liu, Jonathan Richard Schwarz, Anurag Vaidya, Faisal Mahmood, Marinka Zitnik, Tianlong Chen, Thomas Hartvigsen
- Date: 2024-07
- Venue: -
- Code:
-
MUSE: Machine Unlearning Six-Way Evaluation for Language Models
- Author(s): Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A. Smith, Chiyuan Zhang
- Date: 2024-07
- Venue: -
- Code: -
-
If You Don't Understand It, Don't Use It: Eliminating Trojans with Filters Between Layers
- Author(s): Adriano Hernandez
- Date: 2024-07
- Venue: -
- Code:
-
Safe Unlearning: A Surprisingly Effective and Generalizable Solution to Defend Against Jailbreak Attacks
- Author(s): Zhexin Zhang, Junxiao Yang, Pei Ke, Shiyao Cui, Chujie Zheng, Hongning Wang, Minlie Huang
- Date: 2024-07
- Venue: -
- Code:
-
To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models
- Author(s): Bozhong Tian, Xiaozhuan Liang, Siyuan Cheng, Qingbin Liu, Mengru Wang, Dianbo Sui, Xi Chen, Huajun Chen, Ningyu Zhang
- Date: 2024-07
- Venue: -
- Code:
-
Can Small Language Models Learn, Unlearn, and Retain Noise Patterns?
- Author(s): Nicy Scaria, Silvester John Joseph Kennedy, Deepak Subramani
- Date: 2024-07
- Venue: -
- Code: -
-
UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
- Author(s): Ilia Shumailov, Jamie Hayes, Eleni Triantafillou, Guillermo Ortiz-Jimenez, Nicolas Papernot, Matthew Jagielski, Itay Yona, Heidi Howard, Eugene Bagdasaryan
- Date: 2024-07
- Venue: -
- Code: -
-
PISTOL: Dataset Compilation Pipeline for Structural Unlearning of LLMs
- Author(s): Xinchi Qiu, William F. Shen, Yihong Chen, Nicola Cancedda, Pontus Stenetorp, Nicholas D. Lane
- Date: 2024-06
- Venue: -
- Code:
-
Unveiling Entity-Level Unlearning for Large Language Models: A Comprehensive Analysis
- Author(s): Weitao Ma, Xiaocheng Feng, Weihong Zhong, Lei Huang, Yangfan Ye, Xiachong Feng, Bing Qin
- Date: 2024-06
- Venue: -
- Code: -
-
Protecting Privacy Through Approximating Optimal Parameters for Sequence Unlearning in Language Models
- Author(s): Dohyun Lee, Daniel Rim, Minseok Choi, Jaegul Choo
- Date: 2024-06
- Venue: ACL 2024 Findings
- Code: -
-
Every Language Counts: Learn and Unlearn in Multilingual LLMs
- Author(s): Taiming Lu, Philipp Koehn
- Date: 2024-06
- Venue: -
- Code:
-
Mitigating Social Biases in Language Models through Unlearning
- Author(s): Omkar Dige, Diljot Singh, Tsz Fung Yau, Qixuan Zhang, Borna Bolandraftar, Xiaodan Zhu, Faiza Khan Khattak
- Date: 2024-06
- Venue: -
- Code:
-
Textual Unlearning Gives a False Sense of Unlearning
- Author(s): Jiacheng Du, Zhibo Wang, Kui Ren
- Date: 2024-06
- Venue: -
- Code: -
-
Cross-Lingual Unlearning of Selective Knowledge in Multilingual Language Models
- Author(s): Minseok Choi, Kyunghyun Min, Jaegul Choo
- Date: 2024-06
- Venue: -
- Code:
-
SNAP: Unlearning Selective Knowledge in Large Language Models with Negative Instructions
- Author(s): Minseok Choi, Daniel Rim, Dohyun Lee, Jaegul Choo
- Date: 2024-06
- Venue: -
- Code:
-
Soft Prompting for Unlearning in Large Language Models
- Author(s): Karuna Bhaila, Minh-Hao Van, Xintao Wu
- Date: 2024-06
- Venue: -
- Code:
-
Split, Unlearn, Merge: Leveraging Data Attributes for More Effective Unlearning in LLMs
- Author(s): Swanand Ravindra Kadhe, Farhan Ahmed, Dennis Wei, Nathalie Baracaldo, Inkit Padhi
- Date: 2024-06
- Venue: -
- Code: -
-
Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces
- Author(s): Yihuai Hong, Lei Yu, Shauli Ravfogel, Haiqin Yang, Mor Geva
- Date: 2024-06
- Venue: -
- Code:
-
Avoiding Copyright Infringement via Machine Unlearning
- Author(s): Guangyao Dou, Zheyuan Liu, Qing Lyu, Kaize Ding, Eric Wong
- Date: 2024-06
- Venue: -
- Code:
-
RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models
- Author(s): Zhuoran Jin, Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, Jun Zhao
- Date: 2024-06
- Venue: -
- Code:
-
REVS: Unlearning Sensitive Information in Language Models via Rank Editing in the Vocabulary Space
- Author(s): Tomer Ashuach, Martin Tutek, Yonatan Belinkov
- Date: 2024-06
- Venue: -
- Code:
-
Unlearning with Control: Assessing Real-world Utility for Large Language Model Unlearning
- Author(s): Qizhou Wang, Bo Han, Puning Yang, Jianing Zhu, Tongliang Liu, Masashi Sugiyama
- Date: 2024-06
- Venue: -
- Code: -
-
Reversing the Forget-Retain Objectives: An Efficient LLM Unlearning Framework from Logit Difference
- Author(s): Jiabao Ji, Yujian Liu, Yang Zhang, Gaowen Liu, Ramana Rao Kompella, Sijia Liu, Shiyu Chang
- Date: 2024-06
- Venue: -
- Code:
-
Large Language Model Unlearning via Embedding-Corrupted Prompts
- Author(s): Chris Yuhao Liu, Yaxuan Wang, Jeffrey Flanigan, Yang Liu
- Date: 2024-06
- Venue: NeurIPS 2024
- Code:
-
Federated TrustChain: Blockchain-Enhanced LLM Training and Unlearning
- Author(s): Xuhan Zuo, Minghao Wang, Tianqing Zhu, Lefeng Zhang, Dayong Ye, Shui Yu, Wanlei Zhou
- Date: 2024-06
- Venue: -
- Code: -
-
Cross-Modal Safety Alignment: Is textual unlearning all you need?
- Author(s): Trishna Chakraborty, Erfan Shayegani, Zikui Cai, Nael Abu-Ghazaleh, M. Salman Asif, Yue Dong, Amit K. Roy-Chowdhury, Chengyu Song
- Date: 2024-06
- Venue: -
- Code: -
-
RKLD: Reverse KL-Divergence-based Knowledge Distillation for Unlearning Personal Information in Large Language Models
- Author(s): Bichen Wang, Yuzhe Zi, Yixin Sun, Yanyan Zhao, Bing Qin
- Date: 2024-06
- Venue: -
- Code: -
-
Toward Robust Unlearning for LLMs
- Author(s): Rishub Tamirisa, Bhrugu Bharathi, Andy Zhou, Bo Li, Mantas Mazeika
- Date: 2024-05
- Venue: ICLR 2024 SeT-LLM Workshop
- Code: -
-
Unlearning Climate Misinformation in Large Language Models
- Author(s): Michael Fore, Simranjit Singh, Chaehong Lee, Amritanshu Pandey, Antonios Anastasopoulos, Dimitrios Stamoulis
- Date: 2024-05
- Venue: -
- Code: -
-
Large Scale Knowledge Washing
- Author(s): Yu Wang, Ruihan Wu, Zexue He, Xiusi Chen, Julian McAuley
- Date: 2024-05
- Venue: -
- Code:
-
Single Image Unlearning: Efficient Machine Unlearning in Multimodal Large Language Models
- Author(s): Jiaqi Li, Qianshan Wei, Chuanyi Zhang, Guilin Qi, Miaozeng Du, Yongrui Chen, Sheng Bi
- Date: 2024-05
- Venue: -
- Code: -
-
To Each (Textual Sequence) Its Own: Improving Memorized-Data Unlearning in Large Language Models
- Author(s): George-Octavian Barbulescu, Peter Triantafillou
- Date: 2024-05
- Venue: ICML 2024
- Code: -
-
SOUL: Unlocking the Power of Second-Order Optimization for LLM Unlearning
- Author(s): Jinghan Jia, Yihua Zhang, Yimeng Zhang, Jiancheng Liu, Bharat Runwal, James Diffenderfer, Bhavya Kailkhura, Sijia Liu
- Date: 2024-04
- Venue: -
- Code:
-
Machine Unlearning in Large Language Models
- Author(s): Kongyang Chen, Zixin Wang, Bing Mi, Waixi Liu, Shaowei Wang, Xiaojun Ren, Jiaxing Shen
- Date: 2024-04
- Venue: -
- Code: -
-
Offset Unlearning for Large Language Models
- Author(s): James Y. Huang, Wenxuan Zhou, Fei Wang, Fred Morstatter, Sheng Zhang, Hoifung Poon, Muhao Chen
- Date: 2024-04
- Venue: -
- Code:
-
Eraser: Jailbreaking Defense in Large Language Models via Unlearning Harmful Knowledge
- Author(s): Weikai Lu, Ziqian Zeng, Jianwei Wang, Zhengdong Lu, Zelin Chen, Huiping Zhuang, Cen Chen
- Date: 2024-04
- Venue: -
- Code: -
-
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
- Author(s): Ruiqi Zhang, Licong Lin, Yu Bai, Song Mei
- Date: 2024-04
- Venue: -
- Code:
-
Localizing Paragraph Memorization in Language Models
- Author(s): Niklas Stoehr, Mitchell Gordon, Chiyuan Zhang, Owen Lewis
- Date: 2024-03
- Venue: -
- Code: -
-
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
- Author(s): Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Adam Khoja, Zhenqi Zhao, Ariel Herbert-Voss, Cort B. Breuer, Samuel Marks, Oam Patel, Andy Zou, Mantas Mazeika, Zifan Wang, Palash Oswal, Weiran Lin, Adam A. Hunt, Justin Tienken-Harder, Kevin Y. Shih, Kemper Talley, John Guan, Russell Kaplan, Ian Steneker, David Campbell, Brad Jokubaitis, Alex Levinson, Jean Wang, William Qian, Kallol Krishna Karmakar, Steven Basart, Stephen Fitz, Mindy Levine, Ponnurangam Kumaraguru, Uday Tupakula, Vijay Varadharajan, Ruoyu Wang, Yan Shoshitaishvili, Jimmy Ba, Kevin M. Esvelt, Alexandr Wang, Dan Hendrycks
- Date: 2024-03
- Venue: -
- Code:
-
Dissecting Language Models: Machine Unlearning via Selective Pruning
- Author(s): Nicholas Pochinkov, Nandi Schoots
- Date: 2024-03
- Venue: -
- Code: -
-
Second-Order Information Matters: Revisiting Machine Unlearning for Large Language Models
- Author(s): Kang Gu, Md Rafi Ur Rashid, Najrin Sultana, Shagufta Mehnaz
- Date: 2024-03
- Venue: -
- Code: -
-
Ethos: Rectifying Language Models in Orthogonal Parameter Space
- Author(s): Lei Gao, Yue Niu, Tingting Tang, Salman Avestimehr, Murali Annavaram
- Date: 2024-03
- Venue: -
- Code: -
-
Towards Efficient and Effective Unlearning of Large Language Models for Recommendation
- Author(s): Hangyu Wang, Jianghao Lin, Bo Chen, Yang Yang, Ruiming Tang, Weinan Zhang, Yong Yu
- Date: 2024-03
- Venue: -
- Code:
-
Guardrail Baselines for Unlearning in LLMs
- Author(s): Pratiksha Thaker, Yash Maurya, Virginia Smith
- Date: 2024-03
- Venue: ICLR 2024 SeT-LLM Workshop
- Code: -
-
Deciphering the Impact of Pretraining Data on Large Language Models through Machine Unlearning
- Author(s): Deciphering the Impact of Pretraining Data on Large Language Models through Machine Unlearning
- Date: 2024-02
- Venue: -
- Code: -
-
Unmemorization in Large Language Models via Self-Distillation and Deliberate Imagination
- Author(s): Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, Ivan Vulić
- Date: 2024-02
- Venue: -
- Code:
-
Towards Safer Large Language Models through Machine Unlearning
- Author(s): Zheyuan Liu, Guangyao Dou, Zhaoxuan Tan, Yijun Tian, Meng Jiang
- Date: 2024-02
- Venue: -
- Code:
-
Selective Forgetting: Advancing Machine Unlearning Techniques and Evaluation in Language Models
- Author(s): Lingzhi Wang, Xingshan Zeng, Jinsong Guo, Kam-Fai Wong, Georg Gottlob
- Date: 2024-02
- Venue: -
- Code: -
-
Unlearnable Algorithms for In-context Learning
- Author(s): Andrei Muresanu, Anvith Thudi, Michael R. Zhang, Nicolas Papernot
- Date: 2024-02
- Venue: -
- Code: -
-
Machine Unlearning of Pre-trained Large Language Models
- Author(s): Jin Yao, Eli Chien, Minxin Du, Xinyao Niu, Tianhao Wang, Zezhou Cheng, Xiang Yue
- Date: 2024-02
- Venue: ACL 2024
- Code:
-
Visual In-Context Learning for Large Vision-Language Models
- Author(s): Yucheng Zhou, Xiang Li, Qianning Wang, Jianbing Shen
- Date: 2024-02
- Venue: -
- Code: -
-
EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models
- Author(s): Shangyu Xing, Fei Zhao, Zhen Wu, Tuo An, Weihao Chen, Chunhui Li, Jianbing Zhang, Xinyu Dai
- Date: 2024-02
- Venue: -
- Code: -
-
Unlearning Reveals the Influential Training Data of Language Models
- Author(s): Masaru Isonuma, Ivan Titov
- Date: 2024-01
- Venue: -
- Code: -
-
TOFU: A Task of Fictitious Unlearning for LLMs
- Author(s): Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C. Lipton, J. Zico Kolter
- Date: 2024-01
- Venue: -
- Code:
-
FairSISA: Ensemble Post-Processing to Improve Fairness of Unlearning in LLMs
- Author(s): Swanand Ravindra Kadhe, Anisa Halimi, Ambrish Rawat, Nathalie Baracaldo
- Date: 2023-12
- Venue: NeurIPS 2023 SoLaR Workshop
- Code: -
-
Making Harmful Behaviors Unlearnable for Large Language Models
- Author(s): Xin Zhou, Yi Lu, Ruotian Ma, Tao Gui, Qi Zhang, Xuanjing Huang
- Date: 2023-11
- Venue: -
- Code: -
-
Forgetting before Learning: Utilizing Parametric Arithmetic for Knowledge Updating in Large Language Models
- Author(s): Shiwen Ni, Dingwei Chen, Chengming Li, Xiping Hu, Ruifeng Xu, Min Yang
- Date: 2023-11
- Venue: -
- Code: -
-
Who's Harry Potter? Approximate Unlearning in LLMs
- Author(s): Ronen Eldan, Mark Russinovich
- Date: 2023-10
- Venue: -
- Code: -
-
DEPN: Detecting and Editing Privacy Neurons in Pretrained Language Models
- Author(s): Xinwei Wu, Junzhuo Li, Minghui Xu, Weilong Dong, Shuangzhi Wu, Chao Bian, Deyi Xiong
- Date: 2023-10
- Venue: EMNLP 2023
- Code:
-
Unlearn What You Want to Forget: Efficient Unlearning for LLMs
- Author(s): Jiaao Chen, Diyi Yang
- Date: 2023-10
- Venue: EMNLP 2023
- Code:
-
In-Context Unlearning: Language Models as Few Shot Unlearners
- Author(s): Martin Pawelczyk, Seth Neel, Himabindu Lakkaraju
- Date: 2023-10
- Venue: -
- Code: -
-
Large Language Model Unlearning
- Author(s): Yuanshun Yao, Xiaojun Xu, Yang Liu
- Date: 2023-10
- Venue: NeurIPS 2023 SoLaR Workshop
- Code:
-
Forgetting Private Textual Sequences in Language Models via Leave-One-Out Ensemble
- Author(s): Zhe Liu, Ozlem Kalinli
- Date: 2023-09
- Venue: -
- Code: -
-
Can Sensitive Information Be Deleted From LLMs? Objectives for Defending Against Extraction Attacks
- Author(s): Vaidehi Patil, Peter Hase, Mohit Bansal
- Date: 2023-09
- Venue: -
- Code:
-
Separate the Wheat from the Chaff: Model Deficiency Unlearning via Parameter-Efficient Module Operation
- Author(s): Xinshuo Hu, Dongfang Li, Baotian Hu, Zihao Zheng, Zhenyu Liu, Min Zhang
- Date: 2023-08
- Venue: AAAI 2024
- Code:
-
Unlearning Bias in Language Models by Partitioning Gradients
- Author(s): Charles Yu, Sullam Jeoung, Anish Kasi, Pengfei Yu, Heng Ji
- Date: 2023-07
- Venue: ACL (Findings) 2023
- Code:
-
Make Text Unlearnable: Exploiting Effective Patterns to Protect Personal Data
- Author(s): Xinzhe Li, Ming Liu, Shang Gao
- Date: 2023-07
- Venue: -
- Code: -
-
What can we learn from Data Leakage and Unlearning for Law?
- Author(s): Jaydeep Borkar
- Date: 2023-07
- Venue: -
- Code: -
-
LEACE: Perfect linear concept erasure in closed form
- Author(s): Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, Stella Biderman
- Date: 2023-06
- Venue: NeurIPS 2023
- Code:
-
Composing Parameter-Efficient Modules with Arithmetic Operations
- Author(s): Jinghan Zhang, Shiqi Chen, Junteng Liu, Junxian He
- Date: 2023-06
- Venue: NeurIPS 2023
- Code:
-
KGA: A General Machine Unlearning Framework Based on Knowledge Gap Alignment
- Author(s): Lingzhi Wang, Tong Chen, Wei Yuan, Xingshan Zeng, Kam-Fai Wong, Hongzhi Yin
- Date: 2023-05
- Venue: -
- Code:
-
Editing Models with Task Arithmetic
- Author(s): Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, Ali Farhadi
- Date: 2022-12
- Venue: ICLR 2023
- Code:
-
Privacy Adhering Machine Un-learning in NLP
- Author(s): Vinayshekhar Bannihatti Kumar, Rashmi Gangadharaiah, Dan Roth
- Date: 2022-12
- Venue: -
- Code: -
-
The CRINGE Loss: Learning what language not to model
- Author(s): Leonard Adolphs, Tianyu Gao, Jing Xu, Kurt Shuster, Sainbayar Sukhbaatar, Jason Weston
- Date: 2022-11
- Venue: -
- Code: -
-
Knowledge Unlearning for Mitigating Privacy Risks in Language Models
- Author(s): Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, Minjoon Seo
- Date: 2022-10
- Venue: -
- Code:
-
Quark: Controllable Text Generation with Reinforced Unlearning
- Author(s): Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
- Date: 2022-05
- Venue: NeurIPS 2022
- Code:
-
DExperts: Decoding-Time Controlled Text Generation with Experts and Anti-Experts
- Author(s): Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A. Smith, Yejin Choi
- Date: 2021-05
- Venue: ACL 2021
- Code:
-
Preserving Privacy in Large Language Models: A Survey on Current Threats and Solutions
- Author(s): Michele Miranda, Elena Sofia Ruzzetti, Andrea Santilli, Fabio Massimo Zanzotto, Sébastien Bratières, Emanuele Rodolà
- Date: 2024-08
- Venue: -
-
Machine Unlearning in Generative AI: A Survey
- Author(s): Zheyuan Liu, Guangyao Dou, Zhaoxuan Tan, Yijun Tian, Meng Jiang
- Date: 2024-07
- Venue: -
-
Digital Forgetting in Large Language Models: A Survey of Unlearning Methods
- Author(s): Alberto Blanco-Justicia, Najeeb Jebreel, Benet Manzanares, David Sánchez, Josep Domingo-Ferrer, Guillem Collell, Kuan Eeik Tan
- Date: 2024-04
- Venue: -
-
Machine Unlearning for Traditional Models and Large Language Models: A Short Survey
- Author(s): Yi Xu
- Date: 2024-04
- Venue: -
-
The Frontier of Data Erasure: Machine Unlearning for Large Language Models
- Author(s): Youyang Qu, Ming Ding, Nan Sun, Kanchana Thilakarathna, Tianqing Zhu, Dusit Niyato
- Date: 2024-03
- Venue: -
-
Rethinking Machine Unlearning for Large Language Models
- Author(s): Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
- Date: 2024-02
- Venue: -
-
Eight Methods to Evaluate Robust Unlearning in LLMs
- Author(s): Aengus Lynch, Phillip Guo, Aidan Ewart, Stephen Casper, Dylan Hadfield-Menell
- Date: 2024-02
- Venue: -
-
Knowledge Unlearning for LLMs: Tasks, Methods, and Challenges
- Author(s): Nianwen Si, Hao Zhang, Heyu Chang, Wenlin Zhang, Dan Qu, Weiqiang Zhang
- Date: 2023-11
- Venue: -
-
Right to be Forgotten in the Era of Large Language Models: Implications, Challenges, and Solutions
- Author(s): Dawen Zhang, Pamela Finckenberg-Broman, Thong Hoang, Shidong Pan, Zhenchang Xing, Mark Staples, Xiwei Xu
- Date: 2023-07
- Venue: -
-
Machine Unlearning in 2024
- Author(s): Ken Liu
- Date: 2024-05
-
Deep Forgetting & Unlearning for Safely-Scoped LLMs
- Author(s): Stephen Casper
- Date: 2023-12
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-llm-unlearning
Similar Open Source Tools
awesome-llm-unlearning
This repository tracks the latest research on machine unlearning in large language models (LLMs). It offers a comprehensive list of papers, datasets, and resources relevant to the topic.
Awesome-Audio-LLM
Awesome-Audio-LLM is a repository dedicated to various models and methods related to audio and language processing. It includes a wide range of research papers and models developed by different institutions and authors. The repository covers topics such as bridging audio and language, speech emotion recognition, voice assistants, and more. It serves as a comprehensive resource for those interested in the intersection of audio and language processing.

Awesome-LLM-Reasoning-Openai-o1-Survey
The repository 'Awesome LLM Reasoning Openai-o1 Survey' provides a collection of survey papers and related works on OpenAI o1, focusing on topics such as LLM reasoning, self-play reinforcement learning, complex logic reasoning, and scaling law. It includes papers from various institutions and researchers, showcasing advancements in reasoning bootstrapping, reasoning scaling law, self-play learning, step-wise and process-based optimization, and applications beyond math. The repository serves as a valuable resource for researchers interested in exploring the intersection of language models and reasoning techniques.

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.
awesome-llm-role-playing-with-persona
Awesome-llm-role-playing-with-persona is a curated list of resources for large language models for role-playing with assigned personas. It includes papers and resources related to persona-based dialogue systems, personalized response generation, psychology of LLMs, biases in LLMs, and more. The repository aims to provide a comprehensive collection of research papers and tools for exploring role-playing abilities of large language models in various contexts.

Awesome-LLM-Reasoning
**Curated collection of papers and resources on how to unlock the reasoning ability of LLMs and MLLMs.** **Description in less than 400 words, no line breaks and quotation marks.** Large Language Models (LLMs) have revolutionized the NLP landscape, showing improved performance and sample efficiency over smaller models. However, increasing model size alone has not proved sufficient for high performance on challenging reasoning tasks, such as solving arithmetic or commonsense problems. This curated collection of papers and resources presents the latest advancements in unlocking the reasoning abilities of LLMs and Multimodal LLMs (MLLMs). It covers various techniques, benchmarks, and applications, providing a comprehensive overview of the field. **5 jobs suitable for this tool, in lowercase letters.** - content writer - researcher - data analyst - software engineer - product manager **Keywords of the tool, in lowercase letters.** - llm - reasoning - multimodal - chain-of-thought - prompt engineering **5 specific tasks user can use this tool to do, in less than 3 words, Verb + noun form, in daily spoken language.** - write a story - answer a question - translate a language - generate code - summarize a document
Prompt4ReasoningPapers
Prompt4ReasoningPapers is a repository dedicated to reasoning with language model prompting. It provides a comprehensive survey of cutting-edge research on reasoning abilities with language models. The repository includes papers, methods, analysis, resources, and tools related to reasoning tasks. It aims to support various real-world applications such as medical diagnosis, negotiation, etc.
awesome-open-ended
A curated list of open-ended learning AI resources focusing on algorithms that invent new and complex tasks endlessly, inspired by human advancements. The repository includes papers, safety considerations, surveys, perspectives, and blog posts related to open-ended AI research.
Awesome-Multimodal-LLM-for-Code
This repository contains papers, methods, benchmarks, and evaluations for code generation under multimodal scenarios. It covers UI code generation, scientific code generation, slide code generation, visually rich programming, logo generation, program repair, UML code generation, and general benchmarks.

awesome-generative-information-retrieval
This repository contains a curated list of resources on generative information retrieval, including research papers, datasets, tools, and applications. Generative information retrieval is a subfield of information retrieval that uses generative models to generate new documents or passages of text that are relevant to a given query. This can be useful for a variety of tasks, such as question answering, summarization, and document generation. The resources in this repository are intended to help researchers and practitioners stay up-to-date on the latest advances in generative information retrieval.

Awesome-LLM-Preference-Learning
The repository 'Awesome-LLM-Preference-Learning' is the official repository of a survey paper titled 'Towards a Unified View of Preference Learning for Large Language Models: A Survey'. It contains a curated list of papers related to preference learning for Large Language Models (LLMs). The repository covers various aspects of preference learning, including on-policy and off-policy methods, feedback mechanisms, reward models, algorithms, evaluation techniques, and more. The papers included in the repository explore different approaches to aligning LLMs with human preferences, improving mathematical reasoning in LLMs, enhancing code generation, and optimizing language model performance.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.
SLMs-Survey
SLMs-Survey is a comprehensive repository that includes papers and surveys on small language models. It covers topics such as technology, on-device applications, efficiency, enhancements for LLMs, and trustworthiness. The repository provides a detailed overview of existing SLMs, their architecture, enhancements, and specific applications in various domains. It also includes information on SLM deployment optimization techniques and the synergy between SLMs and LLMs.
LLM-as-a-Judge
LLM-as-a-Judge is a repository that includes papers discussed in a survey paper titled 'A Survey on LLM-as-a-Judge'. The repository covers various aspects of using Large Language Models (LLMs) as judges for tasks such as evaluation, reasoning, and decision-making. It provides insights into evaluation pipelines, improvement strategies, and specific tasks related to LLMs. The papers included in the repository explore different methodologies, applications, and future research directions for leveraging LLMs as evaluators in various domains.
For similar tasks
awesome-llm-unlearning
This repository tracks the latest research on machine unlearning in large language models (LLMs). It offers a comprehensive list of papers, datasets, and resources relevant to the topic.
For similar jobs
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.

cladder
CLadder is a repository containing the CLadder dataset for evaluating causal reasoning in language models. The dataset consists of yes/no questions in natural language that require statistical and causal inference to answer. It includes fields such as question_id, given_info, question, answer, reasoning, and metadata like query_type and rung. The dataset also provides prompts for evaluating language models and example questions with associated reasoning steps. Additionally, it offers dataset statistics, data variants, and code setup instructions for using the repository.
awesome-llm-unlearning
This repository tracks the latest research on machine unlearning in large language models (LLMs). It offers a comprehensive list of papers, datasets, and resources relevant to the topic.
COLD-Attack
COLD-Attack is a framework designed for controllable jailbreaks on large language models (LLMs). It formulates the controllable attack generation problem and utilizes the Energy-based Constrained Decoding with Langevin Dynamics (COLD) algorithm to automate the search of adversarial LLM attacks with control over fluency, stealthiness, sentiment, and left-right-coherence. The framework includes steps for energy function formulation, Langevin dynamics sampling, and decoding process to generate discrete text attacks. It offers diverse jailbreak scenarios such as fluent suffix attacks, paraphrase attacks, and attacks with left-right-coherence.
Awesome-LLM-in-Social-Science
Awesome-LLM-in-Social-Science is a repository that compiles papers evaluating Large Language Models (LLMs) from a social science perspective. It includes papers on evaluating, aligning, and simulating LLMs, as well as enhancing tools in social science research. The repository categorizes papers based on their focus on attitudes, opinions, values, personality, morality, and more. It aims to contribute to discussions on the potential and challenges of using LLMs in social science research.

awesome-llm-attributions
This repository focuses on unraveling the sources that large language models tap into for attribution or citation. It delves into the origins of facts, their utilization by the models, the efficacy of attribution methodologies, and challenges tied to ambiguous knowledge reservoirs, biases, and pitfalls of excessive attribution.
context-cite
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.
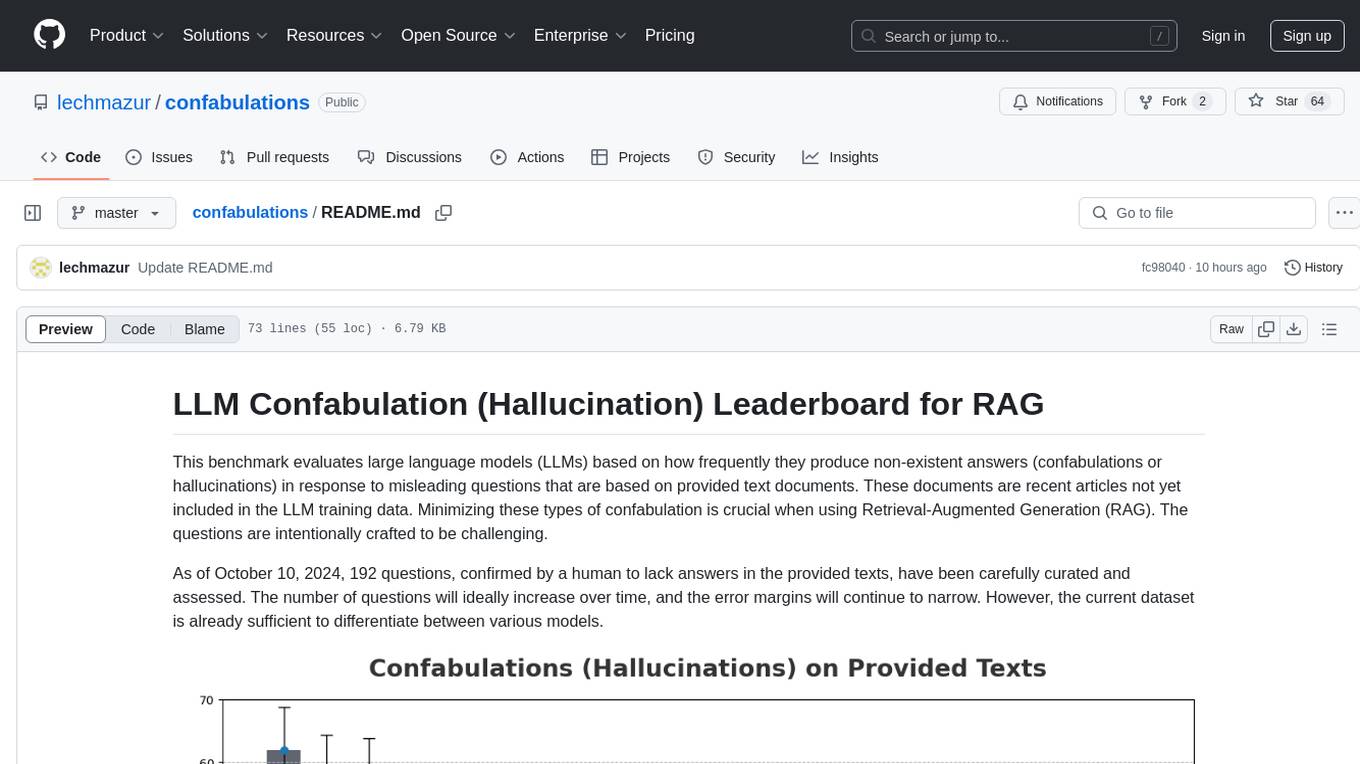
confabulations
LLM Confabulation Leaderboard evaluates large language models based on confabulations and non-response rates to challenging questions. It includes carefully curated questions with no answers in provided texts, aiming to differentiate between various models. The benchmark combines confabulation and non-response rates for comprehensive ranking, offering insights into model performance and tendencies. Additional notes highlight the meticulous human verification process, challenges faced by LLMs in generating valid responses, and the use of temperature settings. Updates and other benchmarks are also mentioned, providing a holistic view of the evaluation landscape.