
aio-proxy
This script automates setting up proxy related tools in Linux.
Stars: 274
This script automates setting up TUIC, hysteria and other proxy-related tools in Linux. It features setting domains, getting SSL certification, setting up a simple web page, SmartSNI by Bepass, Chisel Tunnel, Hysteria V2, Tuic, Hiddify Reality Scanner, SSH, Telegram Proxy, Reverse TLS Tunnel, different panels, installing, disabling, and enabling Warp, Sing Box 4-in-1 script, showing ports in use and their corresponding processes, and an Android script to use Chisel tunnel.
README:

This script automates setting up TUIC, hysteria and other proxy-related tools in Linux.
- Setting domains( for both IPv4 and IPv6 proxy configs will be shown using domains if set)
- Getting SSL certification for the domains and setting up a simple web page( Probe Resistance )
- SmartSNI by Bepass
- Chisel Tunnel ( according to iSegaro's tutorial )
- Hysteria V2 ( according to iSegaro's hysteria v2 tutorial )
- Tuic ( according to iSegaro's tuic tutorial )
- Hiddify Reality Scanner
- SSH ( you can set a custom port for each user)
- Telegram Proxy ( All 4 methods thanks to @hirbodbehnam script )
- Reverse TLS Tunnel( Thanks to Radkesvat and Peyman )
- Different Panels( X-Ui by Alireza, X-Ui Sanaei, RealityEZPZ by Aleskxyz, Hiddify, and Marzban )
- Install, disable, and enable Warp(using yonggekkk's script )
- Sing Box 4-in-1 (reality+hyseria2+tuic+argo) script by Yongge
- Show Ports in use and their corresponding processes
- Android Script to use Chisel tunnel, just run the commands below:(run the first command with VPN)
pkg update -y && pkg install -y jq proot
bash <(curl -sL https://raw.githubusercontent.com/hrostami/aio-proxy/master/android-chisel.sh)
To use the script:
-
Run this command:
source ~/.bashrc && bash <(curl -sL https://bit.ly/aio-proxy)or
source ~/.bashrc && bash <(curl -sL https://raw.githubusercontent.com/hrostami/aio-proxy/master/aio.sh) -
Choose from the menu which protocol you want to install
-
Follow the prompts to enter a port number and password
-
The script will install dependencies, generate certs, create a config, and start the service
-
Your proxy credentials and server info will be printed at the end
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aio-proxy
Similar Open Source Tools
aio-proxy
This script automates setting up TUIC, hysteria and other proxy-related tools in Linux. It features setting domains, getting SSL certification, setting up a simple web page, SmartSNI by Bepass, Chisel Tunnel, Hysteria V2, Tuic, Hiddify Reality Scanner, SSH, Telegram Proxy, Reverse TLS Tunnel, different panels, installing, disabling, and enabling Warp, Sing Box 4-in-1 script, showing ports in use and their corresponding processes, and an Android script to use Chisel tunnel.
AIRAVAT
AIRAVAT is a multifunctional Android Remote Access Tool (RAT) with a GUI-based Web Panel that does not require port forwarding. It allows users to access various features on the victim's device, such as reading files, downloading media, retrieving system information, managing applications, SMS, call logs, contacts, notifications, keylogging, admin permissions, phishing, audio recording, music playback, device control (vibration, torch light, wallpaper), executing shell commands, clipboard text retrieval, URL launching, and background operation. The tool requires a Firebase account and tools like ApkEasy Tool or ApkTool M for building. Users can set up Firebase, host the web panel, modify Instagram.apk for RAT functionality, and connect the victim's device to the web panel. The tool is intended for educational purposes only, and users are solely responsible for its use.

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.

air-script
Air Script is a versatile tool designed for Wi-Fi penetration testing, offering automated and user-friendly features to streamline the hacking process. It allows users to easily capture handshakes from nearby networks, automate attacks, and even send email notifications upon completion. The tool is ideal for individuals looking to efficiently pwn Wi-Fi networks without extensive manual input. With additional tools and options available, Air Script caters to a wide range of users, including script kiddies, hackers, pentesters, and security researchers. Whether on the go or using a Raspberry Pi, Air Script provides a convenient solution for network penetration testing and password cracking.
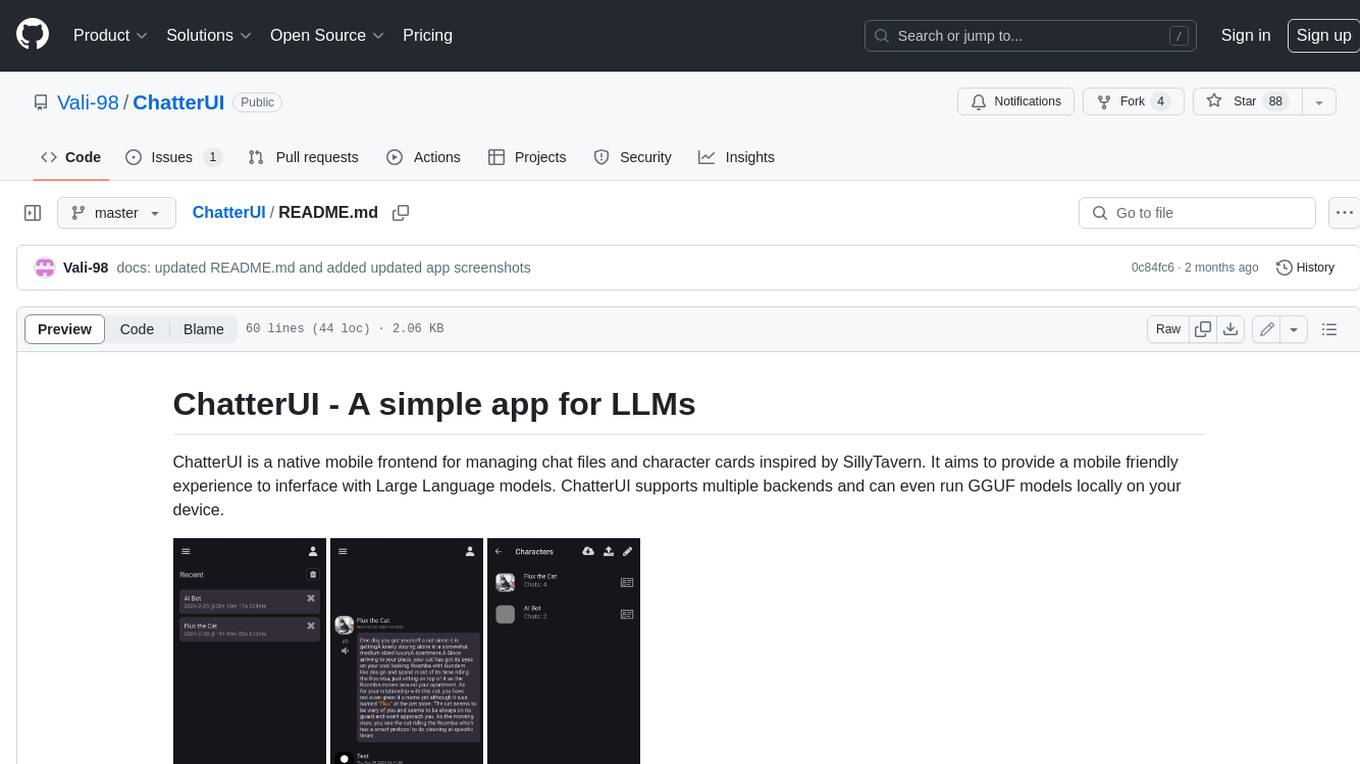
ChatterUI
ChatterUI is a mobile app that allows users to manage chat files and character cards, and to interact with Large Language Models (LLMs). It supports multiple backends, including local, koboldcpp, text-generation-webui, Generic Text Completions, AI Horde, Mancer, Open Router, and OpenAI. ChatterUI provides a mobile-friendly interface for interacting with LLMs, making it easy to use them for a variety of tasks, such as generating text, translating languages, writing code, and answering questions.
ai
The hack club AI proxy is a lightweight LLM proxy that provides various functionalities such as hack club auth, API keys, chat and embedding model support, moderation model support, global analytics, usage statistic logging, coding tool blocking, spending limits, and more. It requires a reverse proxy like traefik and openrouter for billing and provider ratelimits. The tech stack includes bun as the runtime, hono for the server, postgres for the database, drizzle for the ORM, alpine + htmx for the frontend, and various other tools for error tracking, analytics, and model support.
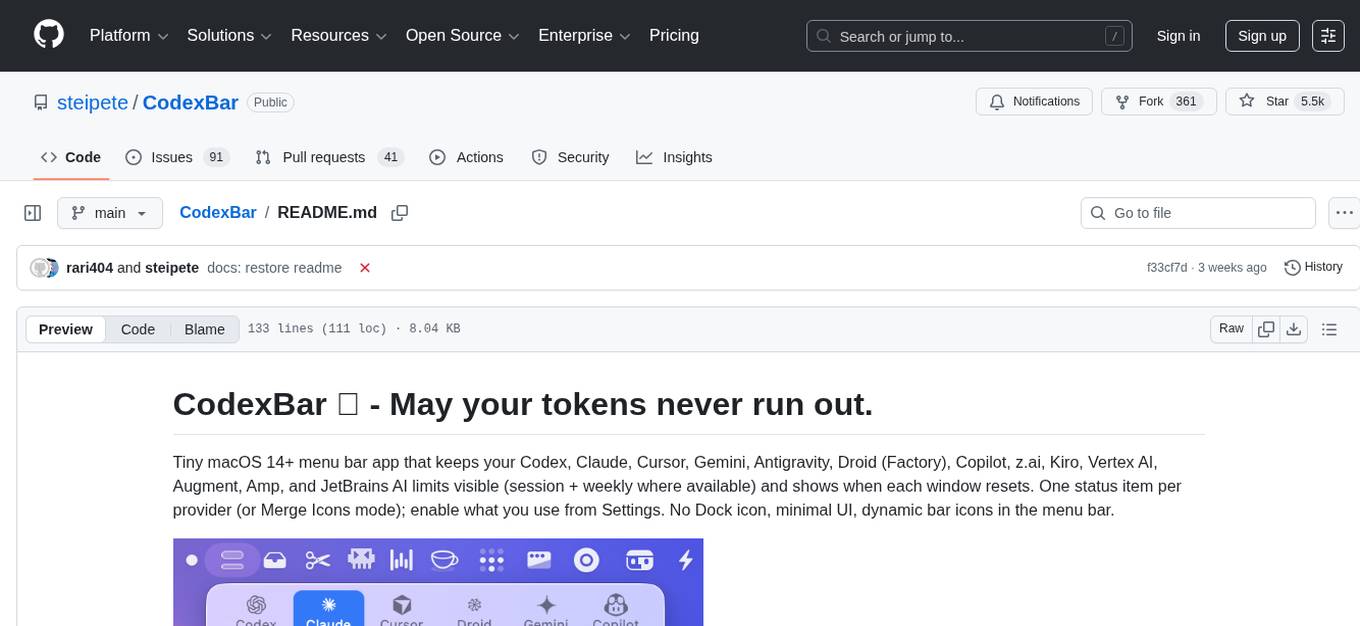
CodexBar
CodexBar is a tiny macOS menu bar app that displays and tracks usage limits for various AI providers such as Codex, Claude, Cursor, Gemini, Antigravity, Droid, Copilot, z.ai, Kiro, Vertex AI, Augment, Amp, and JetBrains AI. It provides a minimal UI with dynamic bar icons, session and weekly usage visibility, and reset countdowns. Users can enable specific providers, view status overlays, and merge icons for a consolidated view. The app offers privacy-first features, CLI support, and a WidgetKit widget for monitoring usage.
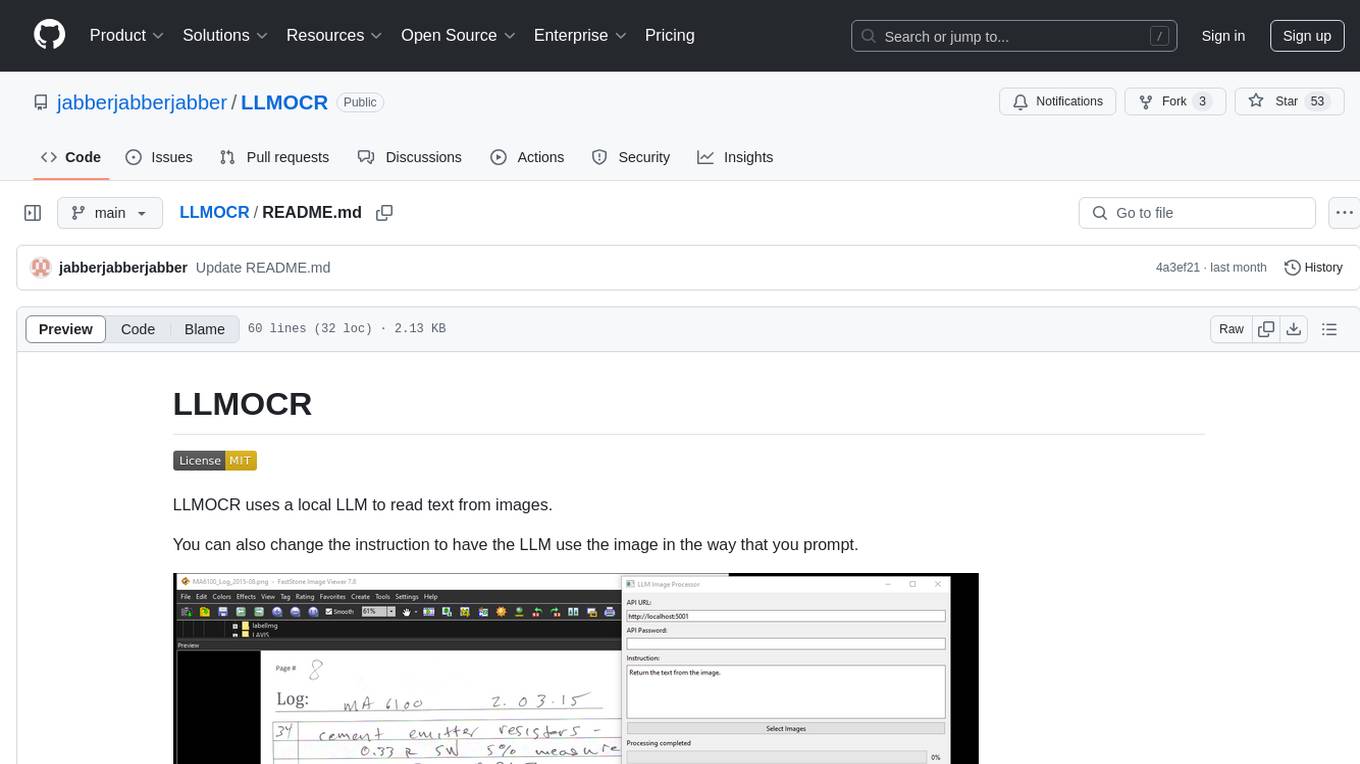
LLMOCR
LLMOCR is a tool that utilizes a local Large Language Model (LLM) to extract text from images. It offers a user-friendly GUI and supports GPU acceleration for faster inference. The tool is cross-platform, compatible with Windows, macOS ARM, and Linux. Users can prompt the LLM to process images in a customized way. The processing is done locally on the user's machine, ensuring data privacy and security. LLMOCR requires Python 3.8 or higher and KoboldCPP for installation and operation.
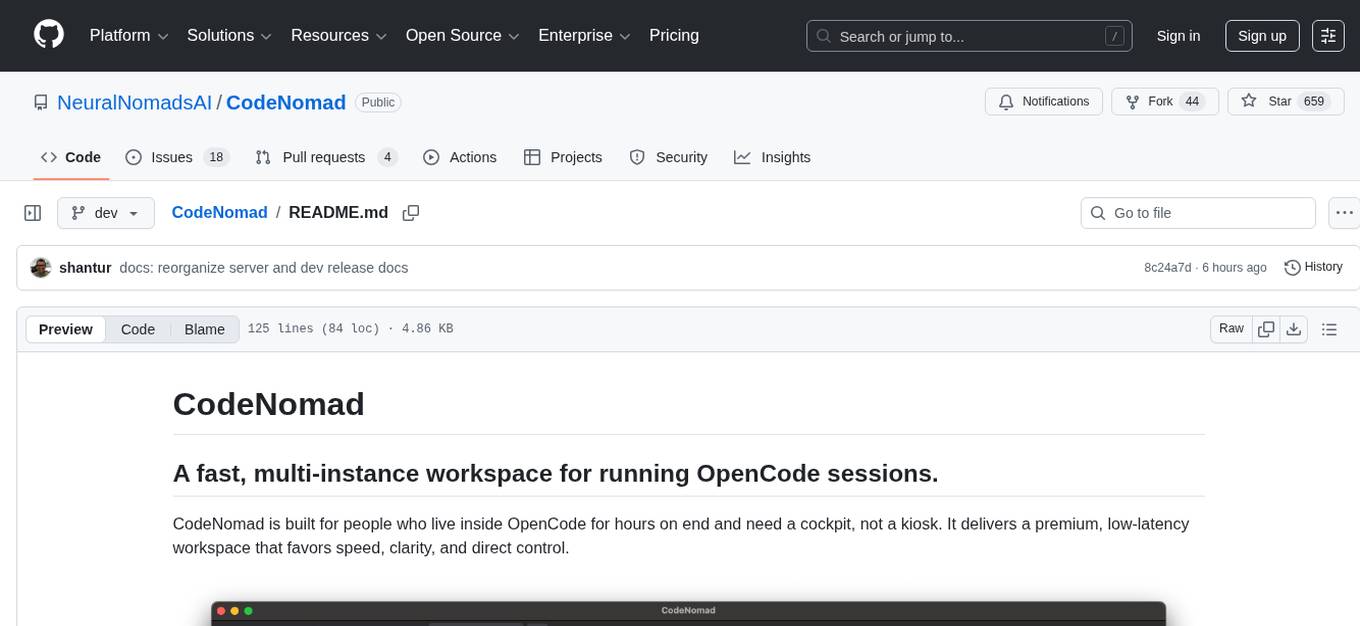
CodeNomad
CodeNomad is a fast, multi-instance workspace designed for users who spend extended hours in OpenCode. It provides a premium, low-latency environment with features like managing multiple OpenCode sessions side-by-side, global command palette for keyboard-first control, rich media previews, and browser support via CodeNomad Server. Users can choose between a Desktop App (Electron-based) with global shortcuts and deeper system integration, a Tauri App for lightweight high-performance experience, or run CodeNomad as a local server accessed via web browser. The tool supports multi-instance workspace, long-session native scrolling, command palette for easy navigation, and deep task awareness to monitor background tasks and child sessions without interruptions.
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.
ragapp
RAGapp is a tool designed for easy deployment of Agentic RAG in any enterprise. It allows users to configure and deploy RAG in their own cloud infrastructure using Docker. The tool is built using LlamaIndex and supports hosted AI models from OpenAI or Gemini, as well as local models using Ollama. RAGapp provides endpoints for Admin UI, Chat UI, and API, with the option to specify the model and Ollama host. The tool does not come with an authentication layer, requiring users to secure the '/admin' path in their cloud environment. Deployment can be done using Docker Compose with customizable model and Ollama host settings, or in Kubernetes for cloud infrastructure deployment. Development setup involves using Poetry for installation and building frontends.
sbnb
Sbnb Linux is a minimalist Linux distribution designed for bare-metal servers, offering fast tunnels for remote connections. It supports confidential computing and is ideal for environments from home labs to distributed data centers. The OS runs in memory, is immutable, and features a predictable update cadence. Users can deploy popular AI tools on bare metal using Sbnb Linux in an automated way. The system is resilient to power outages and supports flexible environments with Docker containers. Sbnb Linux is built with Buildroot, ensuring easy maintenance and updates.
langflow
Langflow is an open-source Python-powered visual framework designed for building multi-agent and RAG applications. It is fully customizable, language model agnostic, and vector store agnostic. Users can easily create flows by dragging components onto the canvas, connect them, and export the flow as a JSON file. Langflow also provides a command-line interface (CLI) for easy management and configuration, allowing users to customize the behavior of Langflow for development or specialized deployment scenarios. The tool can be deployed on various platforms such as Google Cloud Platform, Railway, and Render. Contributors are welcome to enhance the project on GitHub by following the contributing guidelines.

OmniSteward
OmniSteward is an AI-powered steward system based on large language models that can interact with users through voice or text to help control smart home devices and computer programs. It supports multi-turn dialogue, tool calling for complex tasks, multiple LLM models, voice recognition, smart home control, computer program management, online information retrieval, command line operations, and file management. The system is highly extensible, allowing users to customize and share their own tools.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
sre-agent
SRE Agent is an open-source AI agent designed to help Site Reliability Engineers (SREs) debug, maintain healthy Kubernetes systems, and simplify DevOps tasks. With a command-line interface (CLI), users can interact directly with the agent to diagnose issues, report diagnostics, and streamline operations. The agent supports root cause debugging, Kubernetes log querying, GitHub codebase search, and CLI-powered interactions. It is powered by the Model Context Protocol (MCP) for seamless connectivity. Users can configure AWS credentials, GitHub integration, and Anthropic API key to start monitoring deployments and diagnosing issues. The tool is structured with Python services and TypeScript MCP servers for development and maintenance.
For similar tasks
aio-proxy
This script automates setting up TUIC, hysteria and other proxy-related tools in Linux. It features setting domains, getting SSL certification, setting up a simple web page, SmartSNI by Bepass, Chisel Tunnel, Hysteria V2, Tuic, Hiddify Reality Scanner, SSH, Telegram Proxy, Reverse TLS Tunnel, different panels, installing, disabling, and enabling Warp, Sing Box 4-in-1 script, showing ports in use and their corresponding processes, and an Android script to use Chisel tunnel.
For similar jobs

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

openinference
OpenInference is a set of conventions and plugins that complement OpenTelemetry to enable tracing of AI applications. It provides a way to capture and analyze the performance and behavior of AI models, including their interactions with other components of the application. OpenInference is designed to be language-agnostic and can be used with any OpenTelemetry-compatible backend. It includes a set of instrumentations for popular machine learning SDKs and frameworks, making it easy to add tracing to your AI applications.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.