
AIGC_text_detector
[ICLR'24 Spotlight] The official codes of our work on AIGC detection: "Multiscale Positive-Unlabeled Detection of AI-Generated Texts"
Stars: 203
AIGC_text_detector is a repository containing the official codes for the paper 'Multiscale Positive-Unlabeled Detection of AI-Generated Texts'. It includes detector models for both English and Chinese texts, along with stronger detectors developed with enhanced training strategies. The repository provides links to download the detector models, datasets, and necessary preprocessing tools. Users can train RoBERTa and BERT models on the HC3-English dataset using the provided scripts.
README:
Yuchuan Tian, Hanting Chen, Xutao Wang, Zheyuan Bai, Qinghua Zhang, Ruifeng Li, Chao Xu, Yunhe Wang
The official codes of our paper "Multiscale Positive-Unlabeled Detection of AI-Generated Texts".
Paper Link: https://arxiv.org/pdf/2305.18149.pdf
3/25/2025: We release a demo (with both English and Chinese) on HuggingFace: DEMO
3/6/2025: We will update a brand-new detector version to align with the latest LLMs. Please keep tuned!
BibTex formatted citation:
@misc{tian2023multiscale,
title={Multiscale Positive-Unlabeled Detection of AI-Generated Texts},
author={Yuchuan Tian and Hanting Chen and Xutao Wang and Zheyuan Bai and Qinghua Zhang and Ruifeng Li and Chao Xu and Yunhe Wang},
year={2023},
eprint={2305.18149},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
We have open-sourced detector models in the paper as follows.
Links for Detectors: Google Drive Baidu Disk (PIN:1234)
We have also uploaded detector models to HuggingFace, where easy-to-use DEMOs and online APIs are provided.
| Variants | HC3-Full-En | HC3-Sent-En |
|---|---|---|
| seed0 | 98.68 | 82.84 |
| seed1 HuggingFace: en v1 | 98.56 | 87.06 |
| seed2 | 97.97 | 86.02 |
| Avg. | 98.40$\pm$0.31 | 85.31$\pm$1.80 |
We have also open-sourced detector models with strengthened training strategies. Specifically, we develop a strong Chinese detector AIGC_detector_zhv2, which demonstrates similar performance to SOTA closed-source Chinese detectors on various texts, including news articles, poetry, essays, etc. The DEMOs and APIs are available on HuggingFace.
| Detector | Google Drive | Baidu Disk | HuggingFace Link |
|---|---|---|---|
| English, version 2 (env2) | Google Drive | Baidu Disk (PIN:1234) | en v2 |
| Chinese, version 2 (zhv2) | Google Drive | Baidu Disk (PIN:1234) | zh v2 |
Here we provide the official link for the HC3 dataset: Dataset Link. We also provide identical dataset copies on Google Drive and Baidu Disk (PIN:1234) for your ease of use. We acknowledge the marvelous work by HC3 authors.
In Appendix B of our paper, we proposed the removal of redundant spaces in human texts of the HC3-English dataset. We have provided a helper function en_cleaning in corpus_cleaning_kit.py that takes a sentence string as input and returns a preprocessed sentence without redundant spaces.
Here we provide a cleaned version of HC3-English. In this version, all answers are cleaned (i. e. redundant spaces are removed). However, please use the original version of HC3 for all experiments in our paper, as we have embedded the cleaning procedures in the training & validation scripts.
CLEANED HC3-English Link: Google Drive Baidu Disk (PIN:1234)
- Install requirement packages:
pip install -r requirements.txt-
Download datasets to directory:
./data -
Download nltk package punct (This step could be done by
nltkapi:nltk.download('punkt')) -
Download pretrained models (This step could be automatically done by
transformers)
Before running, the directory should contain the following files:
├── data
│ ├── unfilter_full
│ │ ├── en_test.csv
│ │ └── en_train.csv
│ └── unfilter_sent
│ ├── en_test.csv
│ └── en_train.csv
├── README.md
├── corpus_cleaning_kit.py
├── dataset.py
├── multiscale_kit.py
├── option.py
├── pu_loss_mod.py
├── prior_kit.py
├── requirements.txt
├── train.py
└── utils.py
The script for training is train.py.
Commands for seed=0,1,2:
CUDA_VISIBLE_DEVICES=0 python train.py --batch-size 32 --max-sequence-length 512 --train-data-file unfilter_full/en_train.csv --val-data-file unfilter_full/en_test.csv --model-name roberta-base --local-data data --lamb 0.4 --prior 0.2 --pu_type dual_softmax_dyn_dtrun --len_thres 55 --aug_min_length 1 --max-epochs 1 --weight-decay 0 --mode original_single --aug_mode sentence_deletion-0.25 --clean 1 --val_file1 unfilter_sent/en_test.csv --quick_val 1 --learning-rate 5e-05 --seed 0
CUDA_VISIBLE_DEVICES=0 python train.py --batch-size 32 --max-sequence-length 512 --train-data-file unfilter_full/en_train.csv --val-data-file unfilter_full/en_test.csv --model-name roberta-base --local-data data --lamb 0.4 --prior 0.2 --pu_type dual_softmax_dyn_dtrun --len_thres 55 --aug_min_length 1 --max-epochs 1 --weight-decay 0 --mode original_single --aug_mode sentence_deletion-0.25 --clean 1 --val_file1 unfilter_sent/en_test.csv --quick_val 1 --learning-rate 5e-05 --seed 1
CUDA_VISIBLE_DEVICES=0 python train.py --batch-size 32 --max-sequence-length 512 --train-data-file unfilter_full/en_train.csv --val-data-file unfilter_full/en_test.csv --model-name roberta-base --local-data data --lamb 0.4 --prior 0.2 --pu_type dual_softmax_dyn_dtrun --len_thres 55 --aug_min_length 1 --max-epochs 1 --weight-decay 0 --mode original_single --aug_mode sentence_deletion-0.25 --clean 1 --val_file1 unfilter_sent/en_test.csv --quick_val 1 --learning-rate 5e-05 --seed 2
Commands for seed=0,1,2:
CUDA_VISIBLE_DEVICES=0 python train.py --batch-size 32 --max-sequence-length 512 --train-data-file unfilter_full/en_train.csv --val-data-file unfilter_full/en_test.csv --model-name bert-base-cased --local-data data --lamb 0.5 --prior 0.3 --pu_type dual_softmax_dyn_dtrun --len_thres 60 --aug_min_length 1 --max-epochs 1 --weight-decay 0 --mode original_single --aug_mode sentence_deletion-0.25 --clean 1 --val_file1 unfilter_sent/en_test.csv --quick_val 1 --learning-rate 5e-05 --seed 0
CUDA_VISIBLE_DEVICES=0 python train.py --batch-size 32 --max-sequence-length 512 --train-data-file unfilter_full/en_train.csv --val-data-file unfilter_full/en_test.csv --model-name bert-base-cased --local-data data --lamb 0.5 --prior 0.3 --pu_type dual_softmax_dyn_dtrun --len_thres 60 --aug_min_length 1 --max-epochs 1 --weight-decay 0 --mode original_single --aug_mode sentence_deletion-0.25 --clean 1 --val_file1 unfilter_sent/en_test.csv --quick_val 1 --learning-rate 5e-05 --seed 1
CUDA_VISIBLE_DEVICES=0 python train.py --batch-size 32 --max-sequence-length 512 --train-data-file unfilter_full/en_train.csv --val-data-file unfilter_full/en_test.csv --model-name bert-base-cased --local-data data --lamb 0.5 --prior 0.3 --pu_type dual_softmax_dyn_dtrun --len_thres 60 --aug_min_length 1 --max-epochs 1 --weight-decay 0 --mode original_single --aug_mode sentence_deletion-0.25 --clean 1 --val_file1 unfilter_sent/en_test.csv --quick_val 1 --learning-rate 5e-05 --seed 2
Our code refers to the following GitHub repo:
https://github.com/openai/gpt-2-output-dataset
We sincerely thank their authors for open-sourcing.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AIGC_text_detector
Similar Open Source Tools
AIGC_text_detector
AIGC_text_detector is a repository containing the official codes for the paper 'Multiscale Positive-Unlabeled Detection of AI-Generated Texts'. It includes detector models for both English and Chinese texts, along with stronger detectors developed with enhanced training strategies. The repository provides links to download the detector models, datasets, and necessary preprocessing tools. Users can train RoBERTa and BERT models on the HC3-English dataset using the provided scripts.
Edit-Banana
Edit Banana is a universal content re-editor that allows users to transform fixed content into fully manipulatable assets. Powered by SAM 3 and multimodal large models, it enables high-fidelity reconstruction while preserving original diagram details and logical relationships. The platform offers advanced segmentation, fixed multi-round VLM scanning, high-quality OCR, user system with credits, multi-user concurrency, and a web interface. Users can upload images or PDFs to get editable DrawIO (XML) or PPTX files in seconds. The project structure includes components for segmentation, text extraction, frontend, models, and scripts, with detailed installation and setup instructions provided. The tool is open-source under the Apache License 2.0, allowing commercial use and secondary development.
ShapeLLM
ShapeLLM is the first 3D Multimodal Large Language Model designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. It supports single-view colored point cloud input and introduces a robust 3D QA benchmark, 3D MM-Vet, encompassing various variants. The model extends the powerful point encoder architecture, ReCon++, achieving state-of-the-art performance across a range of representation learning tasks. ShapeLLM can be used for tasks such as training, zero-shot understanding, visual grounding, few-shot learning, and zero-shot learning on 3D MM-Vet.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.
paperbanana
PaperBanana is an automated academic illustration tool designed for AI scientists. It implements an agentic framework for generating publication-quality academic diagrams and statistical plots from text descriptions. The tool utilizes a two-phase multi-agent pipeline with iterative refinement, Gemini-based VLM planning, and image generation. It offers a CLI, Python API, and MCP server for IDE integration, along with Claude Code skills for generating diagrams, plots, and evaluating diagrams. PaperBanana is not affiliated with or endorsed by the original authors or Google Research, and it may differ from the original system described in the paper.
smart-ralph
Smart Ralph is a Claude Code plugin designed for spec-driven development. It helps users turn vague feature ideas into structured specs and executes them task-by-task. The tool operates within a self-contained execution loop without external dependencies, providing a seamless workflow for feature development. Named after the Ralph agentic loop pattern, Smart Ralph simplifies the development process by focusing on the next task at hand, akin to the simplicity of the Springfield student, Ralph.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.
aiconfigurator
The `aiconfigurator` tool assists in finding a strong starting configuration for disaggregated serving in AI deployments. It helps optimize throughput at a given latency by evaluating thousands of configurations based on model, GPU count, and GPU type. The tool models LLM inference using collected data for a target machine and framework, running via CLI and web app. It generates configuration files for deployment with Dynamo, offering features like customized configuration, all-in-one automation, and tuning with advanced features. The tool estimates performance by breaking down LLM inference into operations, collecting operation execution times, and searching for strong configurations. Supported features include models like GPT and operations like attention, KV cache, GEMM, AllReduce, embedding, P2P, element-wise, MoE, MLA BMM, TRTLLM versions, and parallel modes like tensor-parallel and pipeline-parallel.
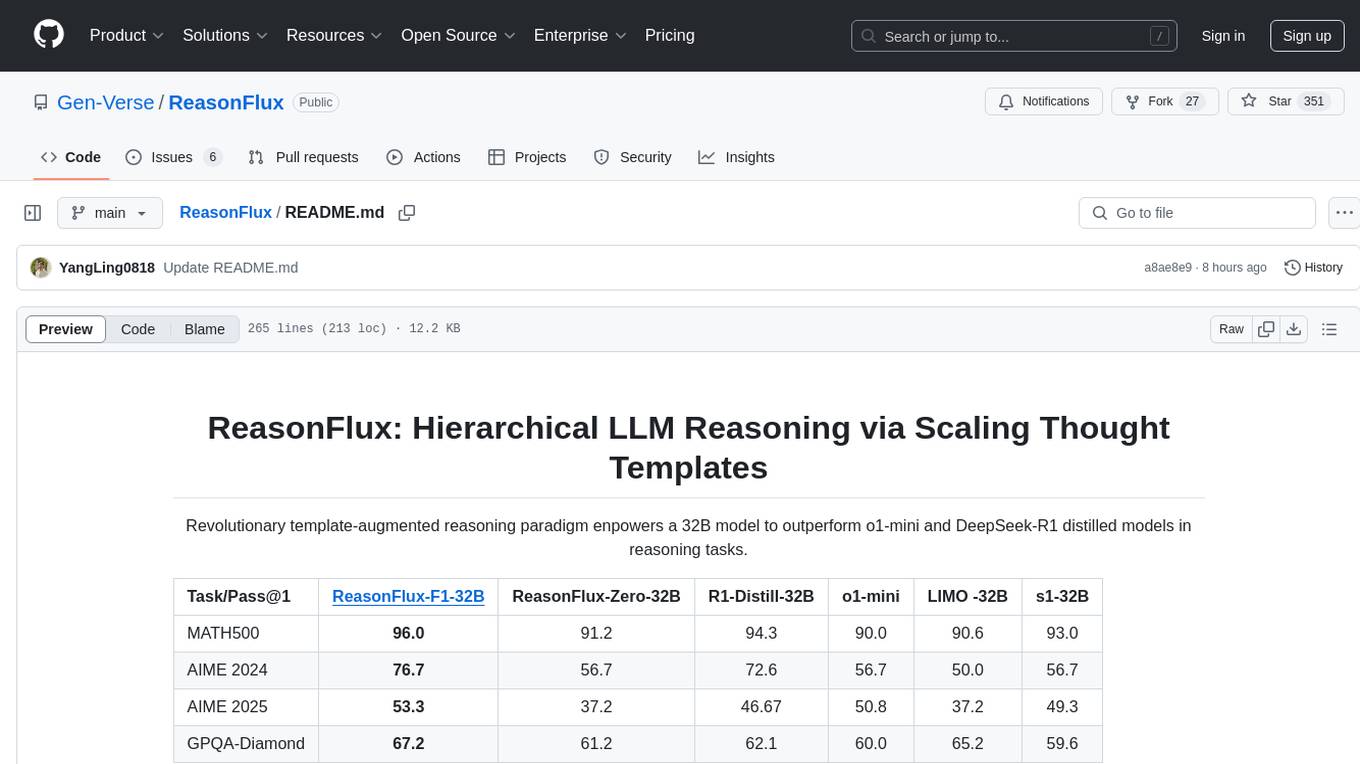
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
MetaScreener
MetaScreener is a local Python tool for AI-assisted systematic review workflows. It utilizes a Hierarchical Consensus Network (HCN) of 4 open-source LLMs with calibrated confidence aggregation, covering the full systematic review pipeline including literature screening, data extraction, and risk-of-bias assessment in a single tool. It offers a multi-LLM ensemble, 3 systematic review modules, reproducibility features, framework-agnostic criteria support, multiple input/output formats, interactive mode, CLI and Web UI, evaluation toolkit, and more.

OpenResearcher
OpenResearcher is a fully open agentic large language model designed for long-horizon deep research scenarios. It achieves an impressive 54.8% accuracy on BrowseComp-Plus, surpassing performance of GPT-4.1, Claude-Opus-4, Gemini-2.5-Pro, DeepSeek-R1, and Tongyi-DeepResearch. The tool is fully open-source, providing the training and evaluation recipe—including data, model, training methodology, and evaluation framework for everyone to progress deep research. It offers features like a fully open-source recipe, highly scalable and low-cost generation of deep research trajectories, and remarkable performance on deep research benchmarks.
TokenPacker
TokenPacker is a novel visual projector that compresses visual tokens by 75%∼89% with high efficiency. It adopts a 'coarse-to-fine' scheme to generate condensed visual tokens, achieving comparable or better performance across diverse benchmarks. The tool includes TokenPacker for general use and TokenPacker-HD for high-resolution image understanding. It provides training scripts, checkpoints, and supports various compression ratios and patch numbers.

deepfabric
DeepFabric is a CLI tool and SDK designed for researchers and developers to generate high-quality synthetic datasets at scale using large language models. It leverages a graph and tree-based architecture to create diverse and domain-specific datasets while minimizing redundancy. The tool supports generating Chain of Thought datasets for step-by-step reasoning tasks and offers multi-provider support for using different language models. DeepFabric also allows for automatic dataset upload to Hugging Face Hub and uses YAML configuration files for flexibility in dataset generation.
claude-code-ultimate-guide
The Claude Code Ultimate Guide is an exhaustive documentation resource that takes users from beginner to power user in using Claude Code. It includes production-ready templates, workflow guides, a quiz, and a cheatsheet for daily use. The guide covers educational depth, methodologies, and practical examples to help users understand concepts and workflows. It also provides interactive onboarding, a repository structure overview, and learning paths for different user levels. The guide is regularly updated and offers a unique 257-question quiz for comprehensive assessment. Users can also find information on agent teams coverage, methodologies, annotated templates, resource evaluations, and learning paths for different roles like junior developer, senior developer, power user, and product manager/devops/designer.
paiml-mcp-agent-toolkit
PAIML MCP Agent Toolkit (PMAT) is a zero-configuration AI context generation system with extreme quality enforcement and Toyota Way standards. It allows users to analyze any codebase instantly through CLI, MCP, or HTTP interfaces. The toolkit provides features such as technical debt analysis, advanced monitoring, metrics aggregation, performance profiling, bottleneck detection, alert system, multi-format export, storage flexibility, and more. It also offers AI-powered intelligence for smart recommendations, polyglot analysis, repository showcase, and integration points. PMAT enforces quality standards like complexity ≤20, zero SATD comments, test coverage >80%, no lint warnings, and synchronized documentation with commits. The toolkit follows Toyota Way development principles for iterative improvement, direct AST traversal, automated quality gates, and zero SATD policy.
For similar tasks
AIGC_text_detector
AIGC_text_detector is a repository containing the official codes for the paper 'Multiscale Positive-Unlabeled Detection of AI-Generated Texts'. It includes detector models for both English and Chinese texts, along with stronger detectors developed with enhanced training strategies. The repository provides links to download the detector models, datasets, and necessary preprocessing tools. Users can train RoBERTa and BERT models on the HC3-English dataset using the provided scripts.
RLHF-Reward-Modeling
This repository, RLHF-Reward-Modeling, is dedicated to training reward models for DRL-based RLHF (PPO), Iterative SFT, and iterative DPO. It provides state-of-the-art performance in reward models with a base model size of up to 13B. The installation instructions involve setting up the environment and aligning the handbook. Dataset preparation requires preprocessing conversations into a standard format. The code can be run with Gemma-2b-it, and evaluation results can be obtained using provided datasets. The to-do list includes various reward models like Bradley-Terry, preference model, regression-based reward model, and multi-objective reward model. The repository is part of iterative rejection sampling fine-tuning and iterative DPO.

MathEval
MathEval is a benchmark designed for evaluating the mathematical capabilities of large models. It includes over 20 evaluation datasets covering various mathematical domains with more than 30,000 math problems. The goal is to assess the performance of large models across different difficulty levels and mathematical subfields. MathEval serves as a reliable reference for comparing mathematical abilities among large models and offers guidance on enhancing their mathematical capabilities in the future.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.