
EMA-VFI-WebUI
Advanced AI-Based Video Renovation UI Using EMA-VFI & Real-ESRGAN
Stars: 62
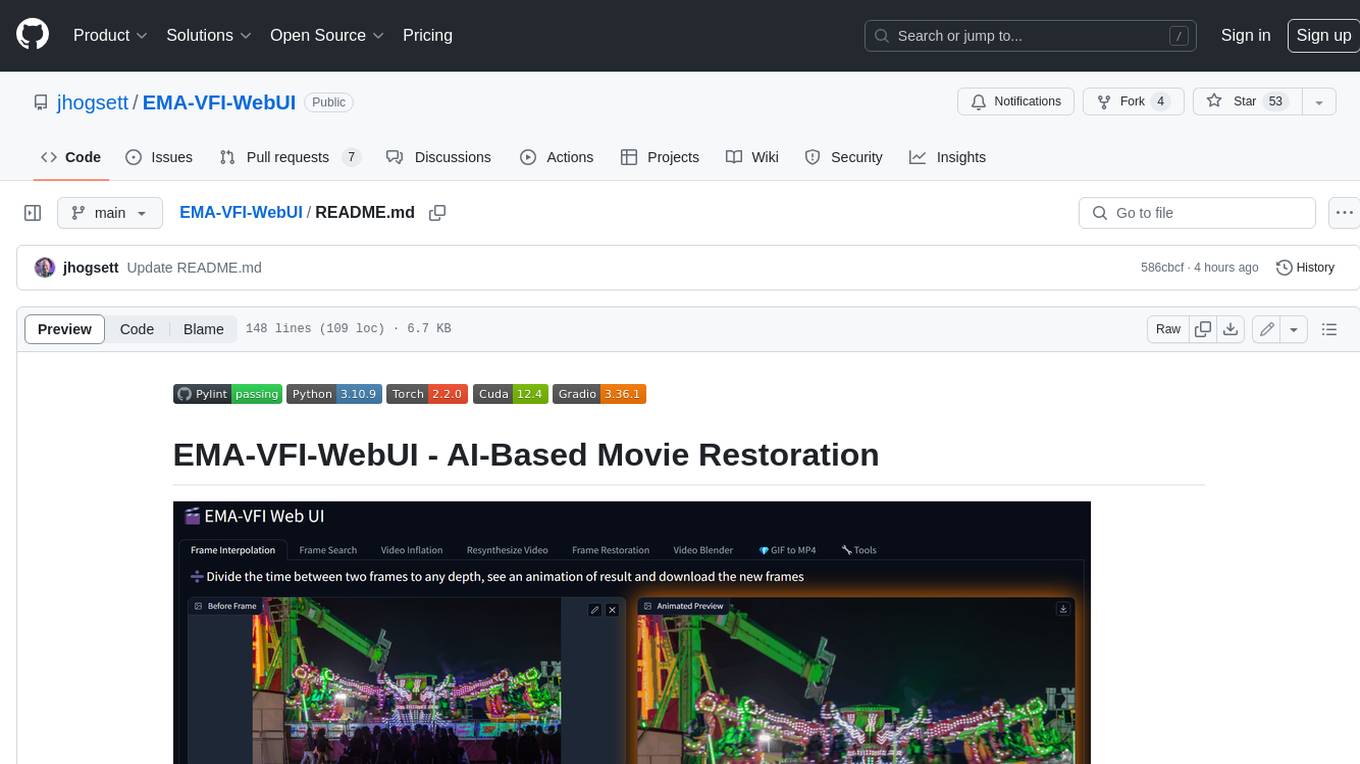
EMA-VFI-WebUI is a web-based graphical user interface (GUI) for the EMA-VFI AI-based movie restoration tool. It provides a user-friendly interface for accessing the various features of EMA-VFI, including frame interpolation, frame search, video inflation, video resynthesis, frame restoration, video blending, file conversion, file resequencing, FPS conversion, GIF to MP4 conversion, and frame upscaling. The web UI makes it easy to use EMA-VFI's powerful features without having to deal with the command line interface.
README:
![]()
🎬 Windows 11 example install steps 4/20/2024
💥 See more samples in the Samples Showcase
| Example - Interpolated Frames |
|---|
 |
| Example - GIF to MP4 (frame size X4, frame rate X8) | Example - Original GIF |
|---|---|
| https://user-images.githubusercontent.com/825994/224548062-4cad649c-5cdb-4f66-936d-e2296eb0fbc8.mp4 |  |
| Example - Resyntheszed Video (YouTube) |
|---|
| https://youtube.com/shorts/lKtY2CHqA98?feature=share |
| Upper: 8MM footage with heavy dirt and noise |
| Lower: Same footage after using Resynthesize Video |
| 🎬 EMA-VFI-WebUI Features | |
|---|---|
| ➗ Frame Interpolation | Restore Missing Frames, Reveal Hidden Motion |
| 🔎 Frame Search | Synthesize Between Frames At Precise Times |
| 🎈 Video Inflation | Create Super Slow-Motion |
| 💕 Resynthesize Video | Create a Complete Set of Replacement Frames |
| 🪄 Frame Restoration | Restore Adjacent Missing / Damaged Frames |
| 🔬 Video Blender | Project-Based Movie Restoration |
| 📁 File Conversion | Convert between PNG Sequences and Videos |
| 🔢 Resequence Files | Renumber for Import into Video Editing Software |
| 🎞️ Change FPS | Convert any FPS to any other FPS |
| 💎 GIF to MP4 | Convert Animated GIF to MP4 in one click |
| 📈 Upscale Frames | Use Real-ESRGAN to Enlarge and Clean Frames |
- Get EMA-VFI working on your local system
- See their repo at https://github.com/MCG-NJU/EMA-VFI
- I run locally with:
- Anaconda 23.1.0
- Python 3.10.9
- Torch 1.13.1
- Cuda 11.7
- NVIDIA RTX 3090
- Windows 11
- Clone this repo in a separate directory and copy all directories/files on top of your working EMA-VFI installation
- This code makes no changes to their original code (but borrows some) and causes no conflicts with it
- It shouldn't introduce any additional requirements over what EMA-VFI, Gradio-App and Real-ESRGAN need
- If it's set up properly, the following command should write a new file
images/image1.pngusing default settings
python interpolate.py
- Get EMA-VFI working on your local system
- See their repo at https://github.com/MCG-NJU/EMA-VFI
- I run locally with:
- Anaconda 23.1.0
- Python 3.10.9
- Torch 1.13.1
- Cuda 11.7
- NVIDIA RTX 3090
- Windows 11
- Clone this repo to a directory in which you intend to use the app and/or develop on it
- Copy the following directories and files from your working EMA-VFI installation to this directory:
benchmarkckptmodelconfig.pydataset.pyTrainer.py
- If it's set up properly, the following command should write a new file
images/image1.png
python interpolate.py
The GIF to MP4 feature uses Real-ESRGAN to clean and upscale frames
- Get Real-ESRGAN working on your local system
- See their repo at https://github.com/xinntao/Real-ESRGAN
- Clone their repo to its own directory and follow their instructions for local setup
- Copy the
realesrgandirectory to yourEMA-VFI-WebUIdirectory
- The Real-ESRGAN 4x+ model (65MB) will automatically download on first use
A few features rely on FFmpeg being available on the system path
The application can be started in any of these ways:
webui.bat-
python webui.py-
Command line arguments
-
--config_path pathpath to alternate configuration file, defaultconfig.yaml -
--verboseenables verbose output to the console, default False
-
-
Command line arguments
The core feature have command-line equivalents
Thanks! to the EMA-VFI folks for their amazing AI frame interpolation tool
Thans! to the Real-ESRGAN folks for their wonderful frame restoration/upscaling tool
Thanks! to the stable-diffusion-webui folks for their great UI, amazing tool, and for inspiring me to learn Gradio
Thanks to Gradio for their easy-to-use Web UI building tool and great docs
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for EMA-VFI-WebUI
Similar Open Source Tools
EMA-VFI-WebUI
EMA-VFI-WebUI is a web-based graphical user interface (GUI) for the EMA-VFI AI-based movie restoration tool. It provides a user-friendly interface for accessing the various features of EMA-VFI, including frame interpolation, frame search, video inflation, video resynthesis, frame restoration, video blending, file conversion, file resequencing, FPS conversion, GIF to MP4 conversion, and frame upscaling. The web UI makes it easy to use EMA-VFI's powerful features without having to deal with the command line interface.
Pallaidium
Pallaidium is a generative AI movie studio integrated into the Blender video editor. It allows users to AI-generate video, image, and audio from text prompts or existing media files. The tool provides various features such as text to video, text to audio, text to speech, text to image, image to image, image to video, video to video, image to text, and more. It requires a Windows system with a CUDA-supported Nvidia card and at least 6 GB VRAM. Pallaidium offers batch processing capabilities, text to audio conversion using Bark, and various performance optimization tips. Users can install the tool by downloading the add-on and following the installation instructions provided. The tool comes with a set of restrictions on usage, prohibiting the generation of harmful, pornographic, violent, or false content.

airunner
AI Runner is a multi-modal AI interface that allows users to run open-source large language models and AI image generators on their own hardware. The tool provides features such as voice-based chatbot conversations, text-to-speech, speech-to-text, vision-to-text, text generation with large language models, image generation capabilities, image manipulation tools, utility functions, and more. It aims to provide a stable and user-friendly experience with security updates, a new UI, and a streamlined installation process. The application is designed to run offline on users' hardware without relying on a web server, offering a smooth and responsive user experience.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.
RWKV-Runner
RWKV Runner is a project designed to simplify the usage of large language models by automating various processes. It provides a lightweight executable program and is compatible with the OpenAI API. Users can deploy the backend on a server and use the program as a client. The project offers features like model management, VRAM configurations, user-friendly chat interface, WebUI option, parameter configuration, model conversion tool, download management, LoRA Finetune, and multilingual localization. It can be used for various tasks such as chat, completion, composition, and model inspection.
NExT-GPT
NExT-GPT is an end-to-end multimodal large language model that can process input and generate output in various combinations of text, image, video, and audio. It leverages existing pre-trained models and diffusion models with end-to-end instruction tuning. The repository contains code, data, and model weights for NExT-GPT, allowing users to work with different modalities and perform tasks like encoding, understanding, reasoning, and generating multimodal content.
stable-diffusion-prompt-reader
A simple standalone viewer for reading prompt from Stable Diffusion generated image outside the webui. The tool supports macOS, Windows, and Linux, providing both GUI and CLI functionalities. Users can interact with the tool through drag and drop, copy prompt to clipboard, remove prompt from image, export prompt to text file, edit or import prompt to images, and more. It supports multiple formats including PNG, JPEG, WEBP, TXT, and various tools like A1111's webUI, Easy Diffusion, StableSwarmUI, Fooocus-MRE, NovelAI, InvokeAI, ComfyUI, Draw Things, and Naifu(4chan). Users can download the tool for different platforms and install it via Homebrew Cask or pip. The tool can be used to read, export, remove, and edit prompts from images, providing various modes and options for different tasks.
quickvid
QuickVid is an open-source video summarization tool that uses AI to generate summaries of YouTube videos. It is built with Whisper, GPT, LangChain, and Supabase. QuickVid can be used to save time and get the essence of any YouTube video with intelligent summarization.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.
OutofFocus
Out of Focus v1.0 is a flexible tool in Gradio for image manipulation through prompt manipulation by reconstruction via diffusion inversion process. Users can modify images using this tool, which is the first version of the Image modification tool by Out of AI.
SoM-LLaVA
SoM-LLaVA is a new data source and learning paradigm for Multimodal LLMs, empowering open-source Multimodal LLMs with Set-of-Mark prompting and improved visual reasoning ability. The repository provides a new dataset that is complementary to existing training sources, enhancing multimodal LLMs with Set-of-Mark prompting and improved general capacity. By adding 30k SoM data to the visual instruction tuning stage of LLaVA, the tool achieves 1% to 6% relative improvements on all benchmarks. Users can train SoM-LLaVA via command line and utilize the implementation to annotate COCO images with SoM. Additionally, the tool can be loaded in Huggingface for further usage.
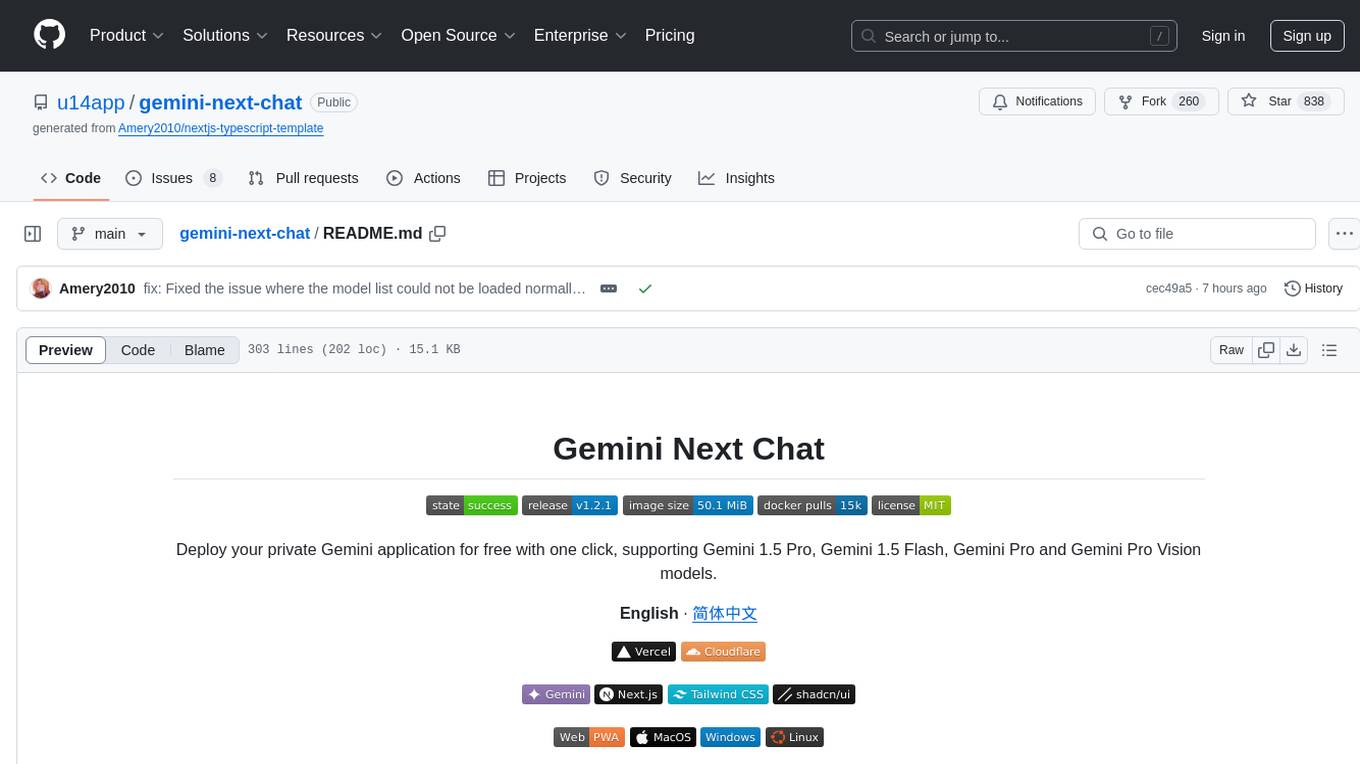
gemini-next-chat
Gemini Next Chat is an open-source, extensible high-performance Gemini chatbot framework that supports one-click free deployment of private Gemini web applications. It provides a simple interface with image recognition and voice conversation, supports multi-modal models, talk mode, visual recognition, assistant market, support plugins, conversation list, full Markdown support, privacy and security, PWA support, well-designed UI, fast loading speed, static deployment, and multi-language support.

ichigo
Ichigo is a local real-time voice AI tool that uses an early fusion technique to extend a text-based LLM to have native 'listening' ability. It is an open research experiment with improved multiturn capabilities and the ability to refuse processing inaudible queries. The tool is designed for open data, open weight, on-device Siri-like functionality, inspired by Meta's Chameleon paper. Ichigo offers a web UI demo and Gradio web UI for users to interact with the tool. It has achieved enhanced MMLU scores, stronger context handling, advanced noise management, and improved multi-turn capabilities for a robust user experience.
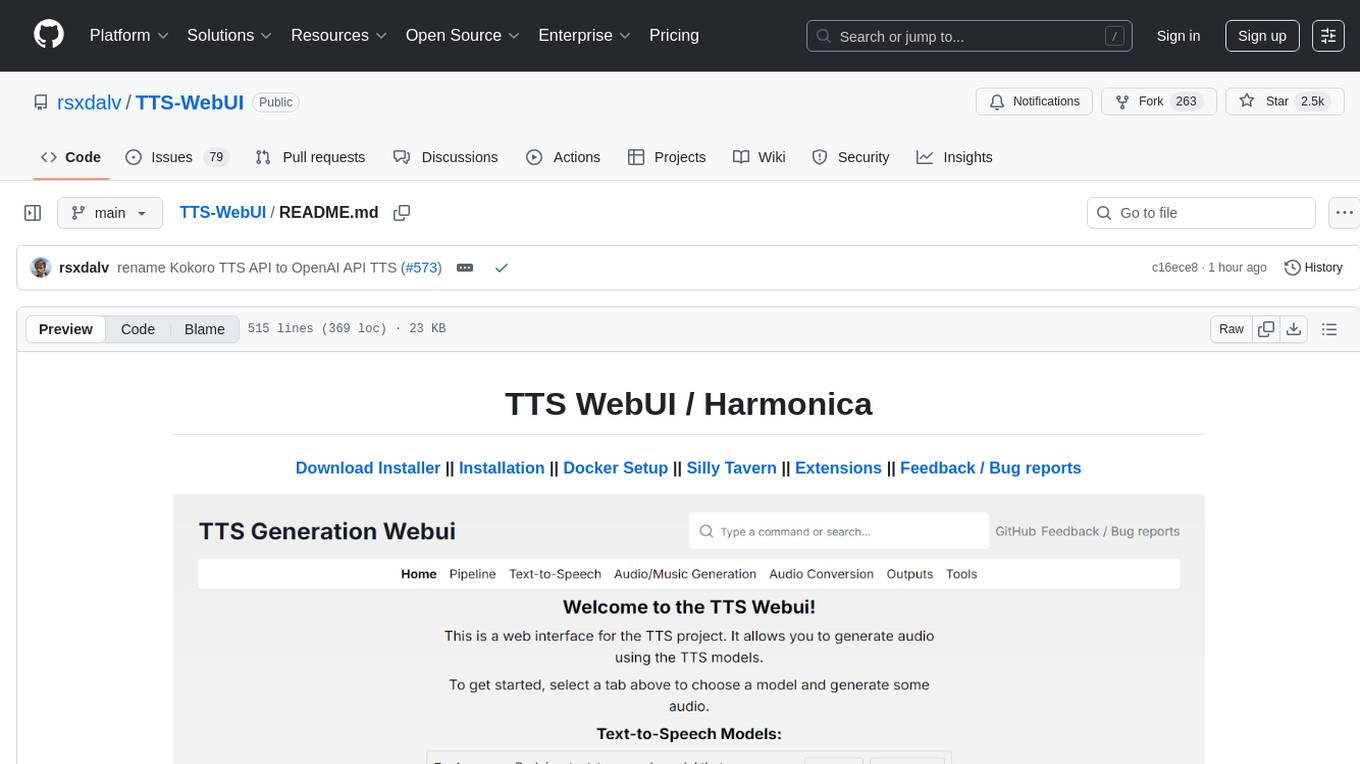
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.

vision-parse
Vision Parse is a tool that leverages Vision Language Models to parse PDF documents into beautifully formatted markdown content. It offers smart content extraction, content formatting, multi-LLM support, PDF document support, and local model hosting using Ollama. Users can easily convert PDFs to markdown with high precision and preserve document hierarchy and styling. The tool supports multiple Vision LLM providers like OpenAI, LLama, and Gemini for accuracy and speed, making document processing efficient and effortless.
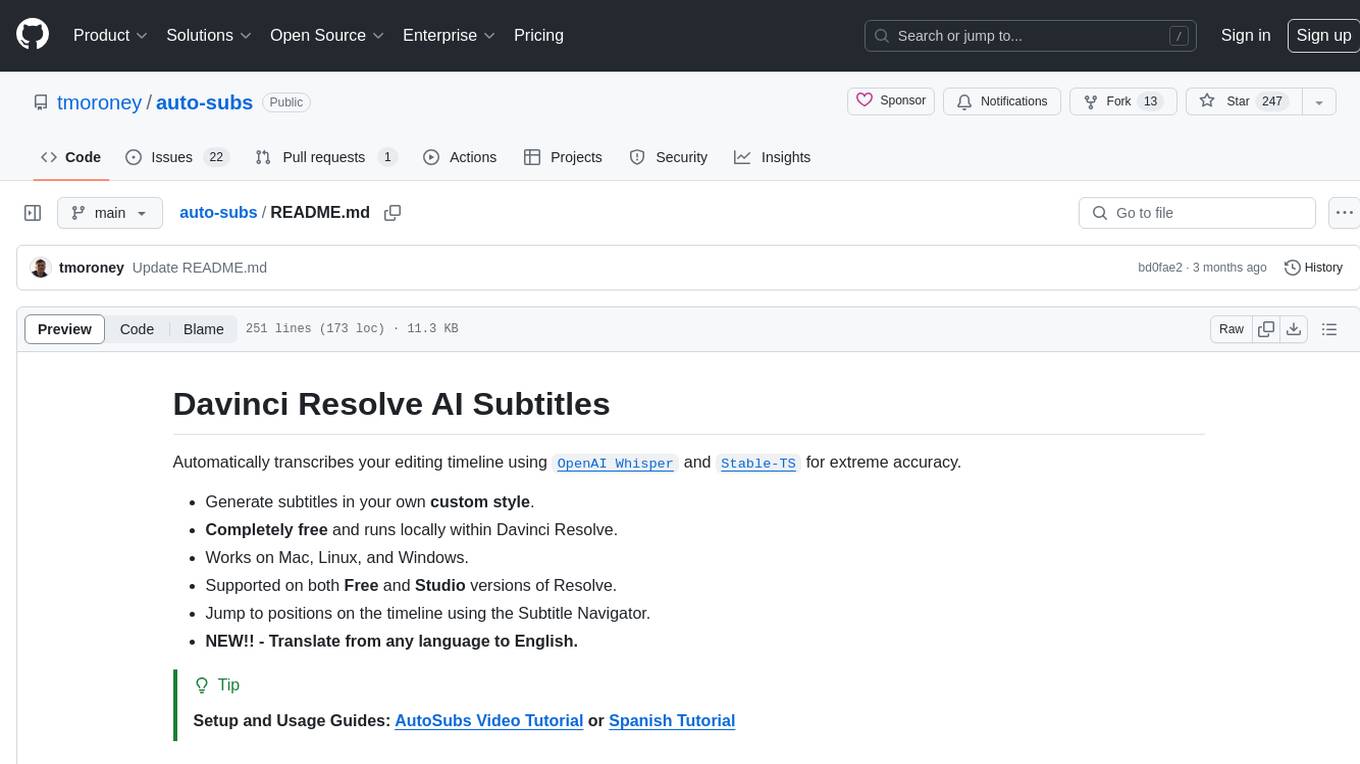
auto-subs
Auto-subs is a tool designed to automatically transcribe editing timelines using OpenAI Whisper and Stable-TS for extreme accuracy. It generates subtitles in a custom style, is completely free, and runs locally within Davinci Resolve. It works on Mac, Linux, and Windows, supporting both Free and Studio versions of Resolve. Users can jump to positions on the timeline using the Subtitle Navigator and translate from any language to English. The tool provides a user-friendly interface for creating and customizing subtitles for video content.
For similar tasks
EMA-VFI-WebUI
EMA-VFI-WebUI is a web-based graphical user interface (GUI) for the EMA-VFI AI-based movie restoration tool. It provides a user-friendly interface for accessing the various features of EMA-VFI, including frame interpolation, frame search, video inflation, video resynthesis, frame restoration, video blending, file conversion, file resequencing, FPS conversion, GIF to MP4 conversion, and frame upscaling. The web UI makes it easy to use EMA-VFI's powerful features without having to deal with the command line interface.
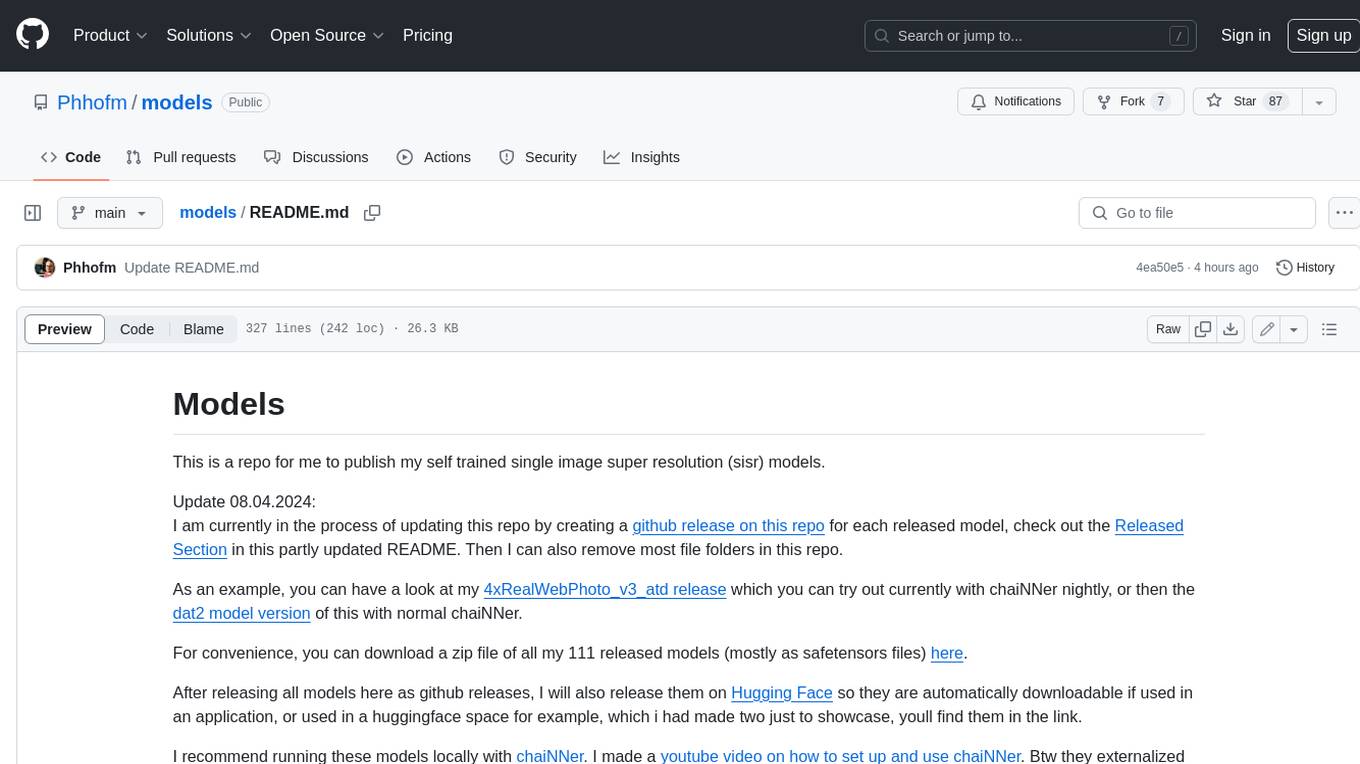
models
This repository contains self-trained single image super resolution (SISR) models. The models are trained on various datasets and use different network architectures. They can be used to upscale images by 2x, 4x, or 8x, and can handle various types of degradation, such as JPEG compression, noise, and blur. The models are provided as safetensors files, which can be loaded into a variety of deep learning frameworks, such as PyTorch and TensorFlow. The repository also includes a number of resources, such as examples, results, and a website where you can compare the outputs of different models.

QualityScaler
QualityScaler is a Windows app powered by AI to enhance, upscale, and de-noise photographs and videos. It provides an easy-to-use GUI for upscaling images and videos using multiple AI models. The tool supports automatic image tiling and merging to avoid GPU VRAM limitations, resizing images/videos before upscaling, and interpolation between the original and upscaled content. QualityScaler is written in Python and utilizes external packages such as torch, onnxruntime-directml, customtkinter, OpenCV, moviepy, and nuitka. It requires Windows 11 or Windows 10, at least 8GB of RAM, and a Directx12 compatible GPU with 4GB VRAM or more. The tool aims to continue improving with upcoming versions by adding new features, enhancing performance, and supporting additional AI architectures.

RealScaler
RealScaler is a Windows app powered by RealESRGAN AI to enhance, upscale, and de-noise photos and videos. It provides an easy-to-use GUI for upscaling images and videos using multiple AI models. The tool supports automatic image tiling and merging to avoid GPU VRAM limitations, resizing images/videos before upscaling, interpolation between original and upscaled content, and compatibility with various image and video formats. RealScaler is written in Python and requires Windows 11/10, at least 8GB RAM, and a Directx12 compatible GPU with 4GB VRAM. Future versions aim to enhance performance, support more GPUs, offer a new GUI with Windows 11 style, include audio for upscaled videos, and provide features like metadata extraction and application from original to upscaled files.
For similar jobs
EMA-VFI-WebUI
EMA-VFI-WebUI is a web-based graphical user interface (GUI) for the EMA-VFI AI-based movie restoration tool. It provides a user-friendly interface for accessing the various features of EMA-VFI, including frame interpolation, frame search, video inflation, video resynthesis, frame restoration, video blending, file conversion, file resequencing, FPS conversion, GIF to MP4 conversion, and frame upscaling. The web UI makes it easy to use EMA-VFI's powerful features without having to deal with the command line interface.
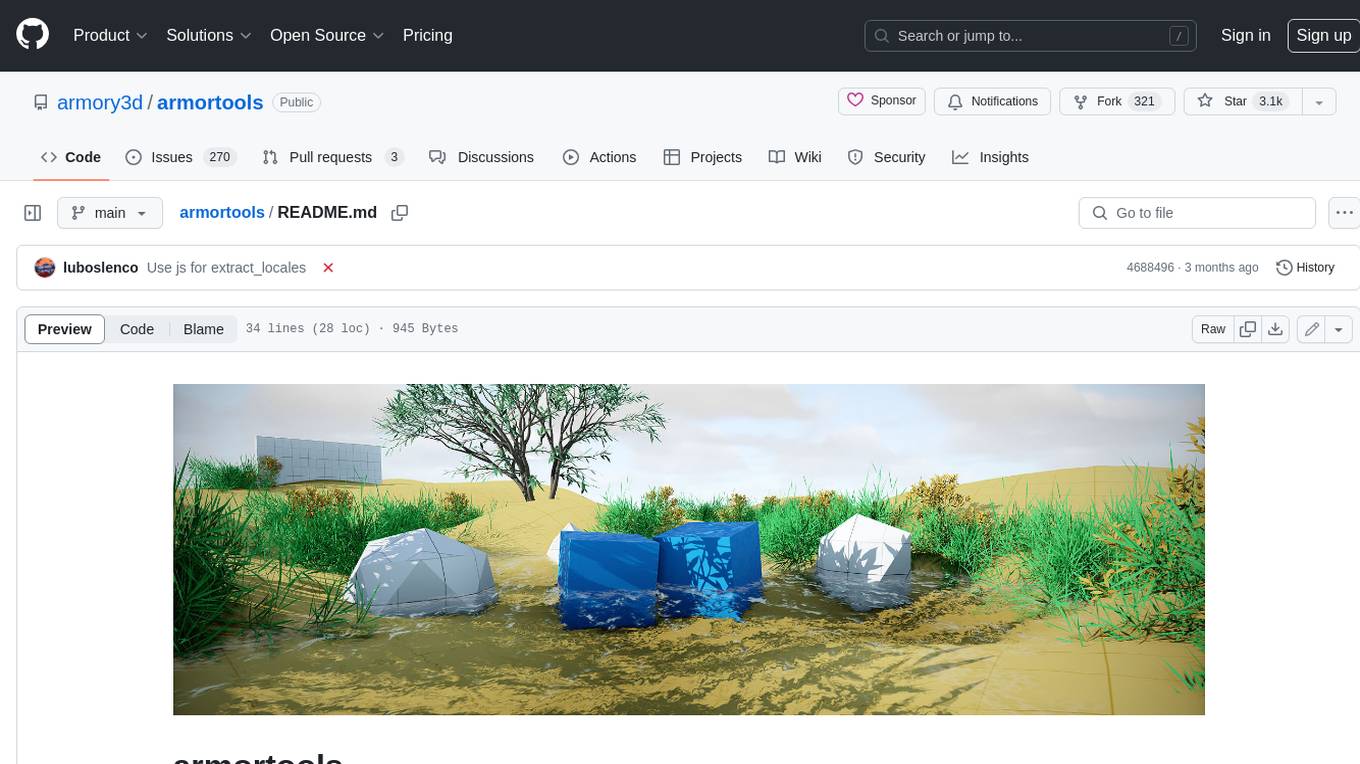
EasyAIVtuber
EasyAIVtuber is a tool designed to animate 2D waifus by providing features like automatic idle actions, speaking animations, head nodding, singing animations, and sleeping mode. It also offers API endpoints and a web UI for interaction. The tool requires dependencies like torch and pre-trained models for optimal performance. Users can easily test the tool using OBS and UnityCapture, with options to customize character input, output size, simplification level, webcam output, model selection, port configuration, sleep interval, and movement extension. The tool also provides an API using Flask for actions like speaking based on audio, rhythmic movements, singing based on music and voice, stopping current actions, and changing images.
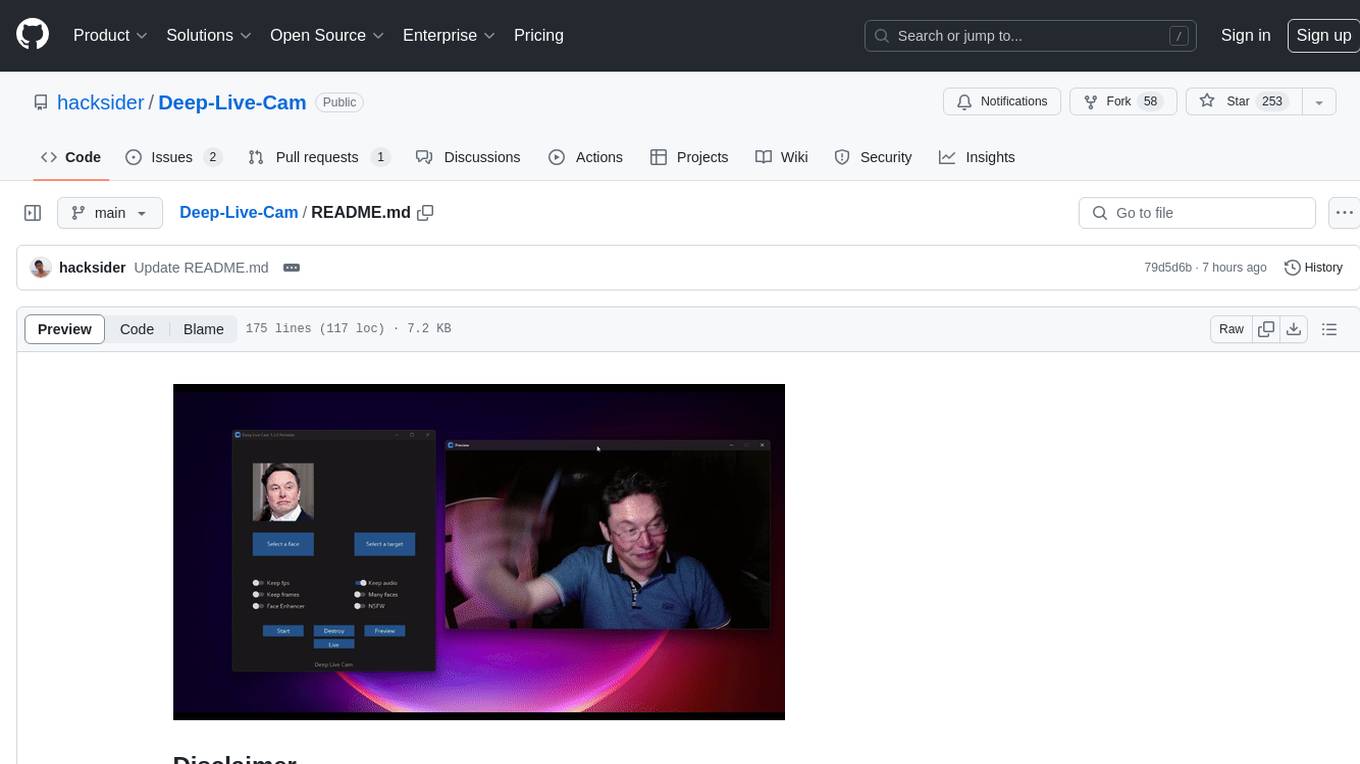
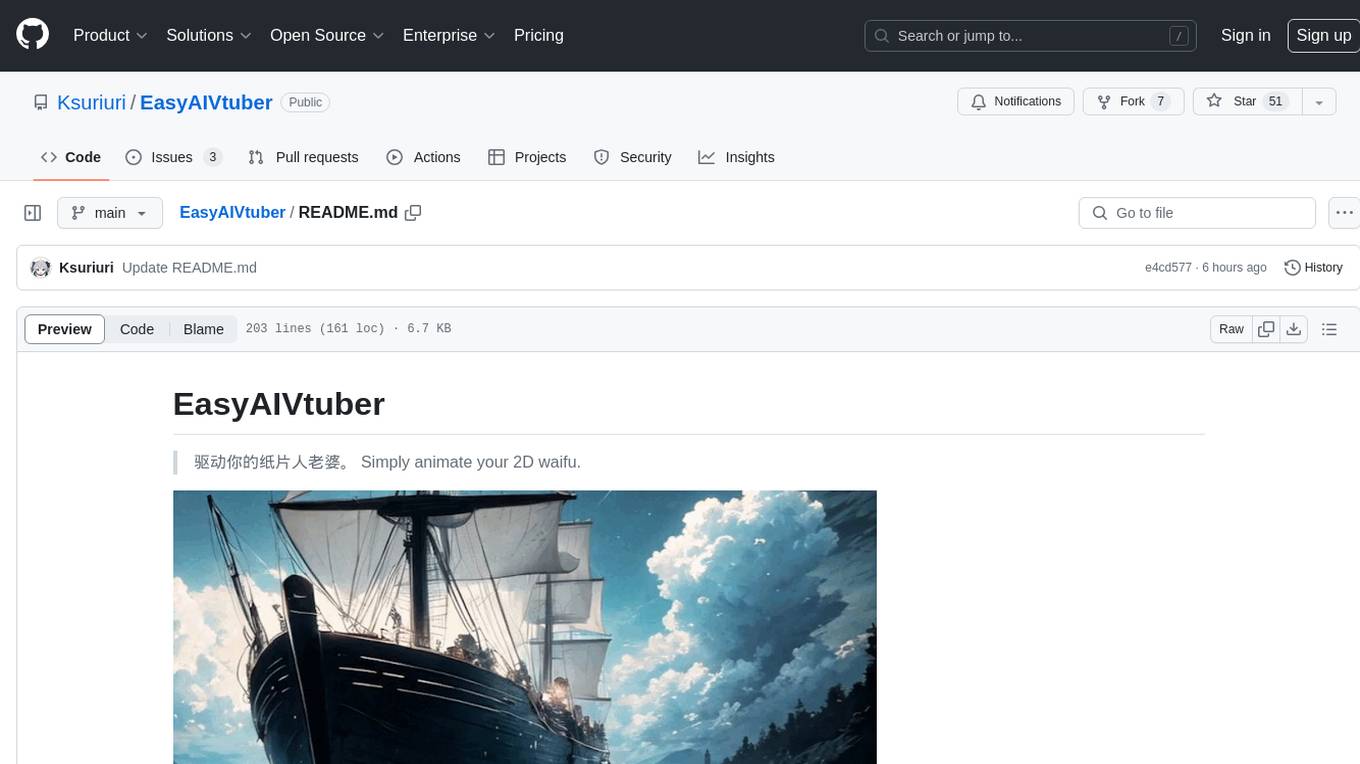
Deep-Live-Cam
Deep-Live-Cam is a software tool designed to assist artists in tasks such as animating custom characters or using characters as models for clothing. The tool includes built-in checks to prevent unethical applications, such as working on inappropriate media. Users are expected to use the tool responsibly and adhere to local laws, especially when using real faces for deepfake content. The tool supports both CPU and GPU acceleration for faster processing and provides a user-friendly GUI for swapping faces in images or videos.
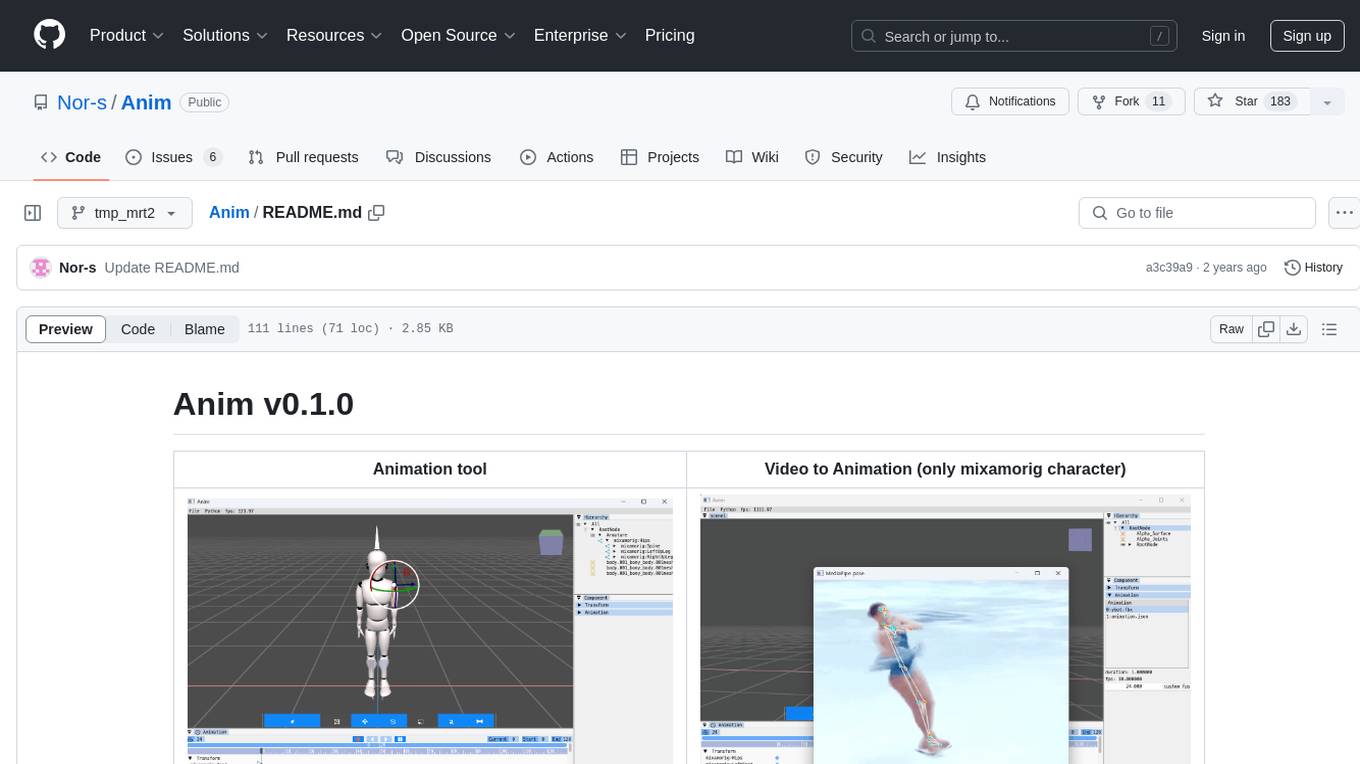
Anim
Anim v0.1.0 is an animation tool that allows users to convert videos to animations using mixamorig characters. It features FK animation editing, object selection, embedded Python support (only on Windows), and the ability to export to glTF and FBX formats. Users can also utilize Mediapipe to create animations. The tool is designed to assist users in creating animations with ease and flexibility.
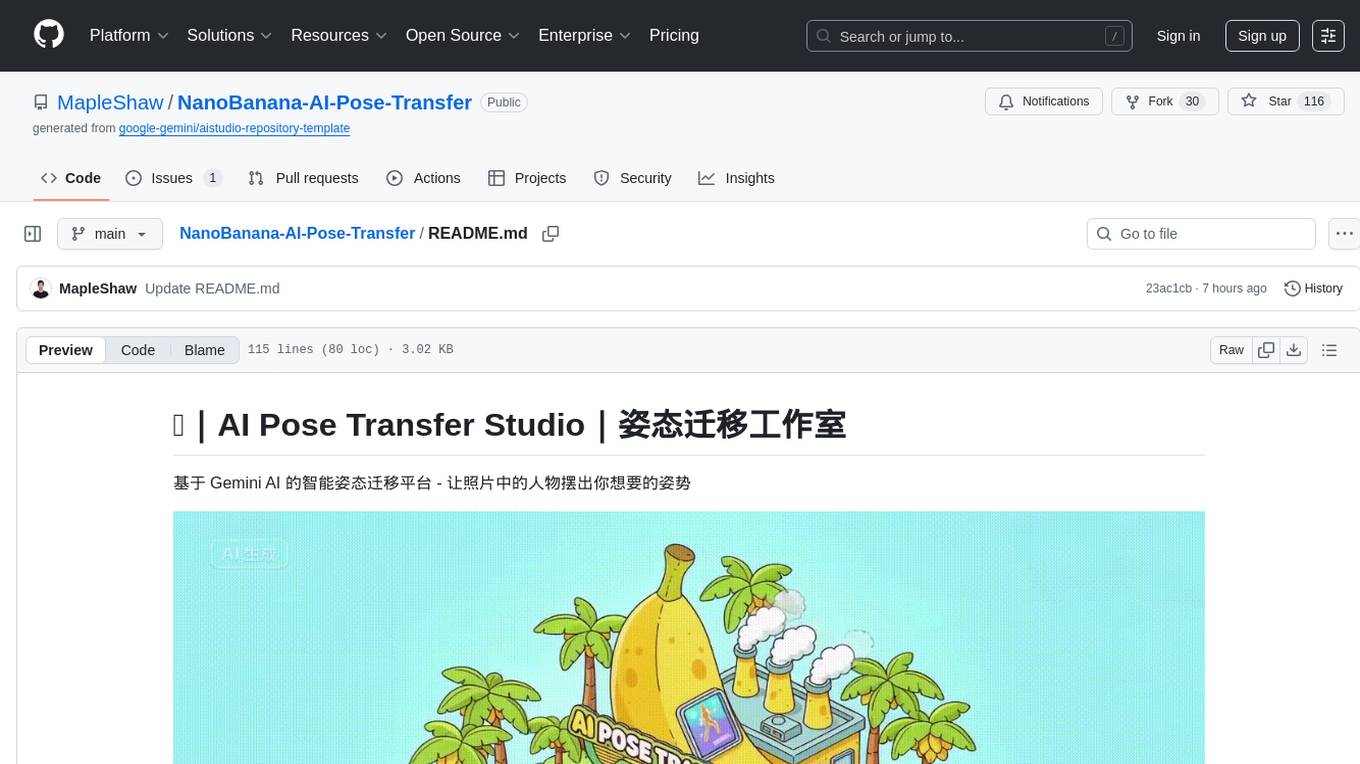
NanoBanana-AI-Pose-Transfer
NanoBanana-AI-Pose-Transfer is a lightweight tool for transferring poses between images using artificial intelligence. It leverages advanced AI algorithms to accurately map and transfer poses from a source image to a target image. This tool is designed to be user-friendly and efficient, allowing users to easily manipulate and transfer poses for various applications such as image editing, animation, and virtual reality. With NanoBanana-AI-Pose-Transfer, users can seamlessly transfer poses between images with high precision and quality.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.
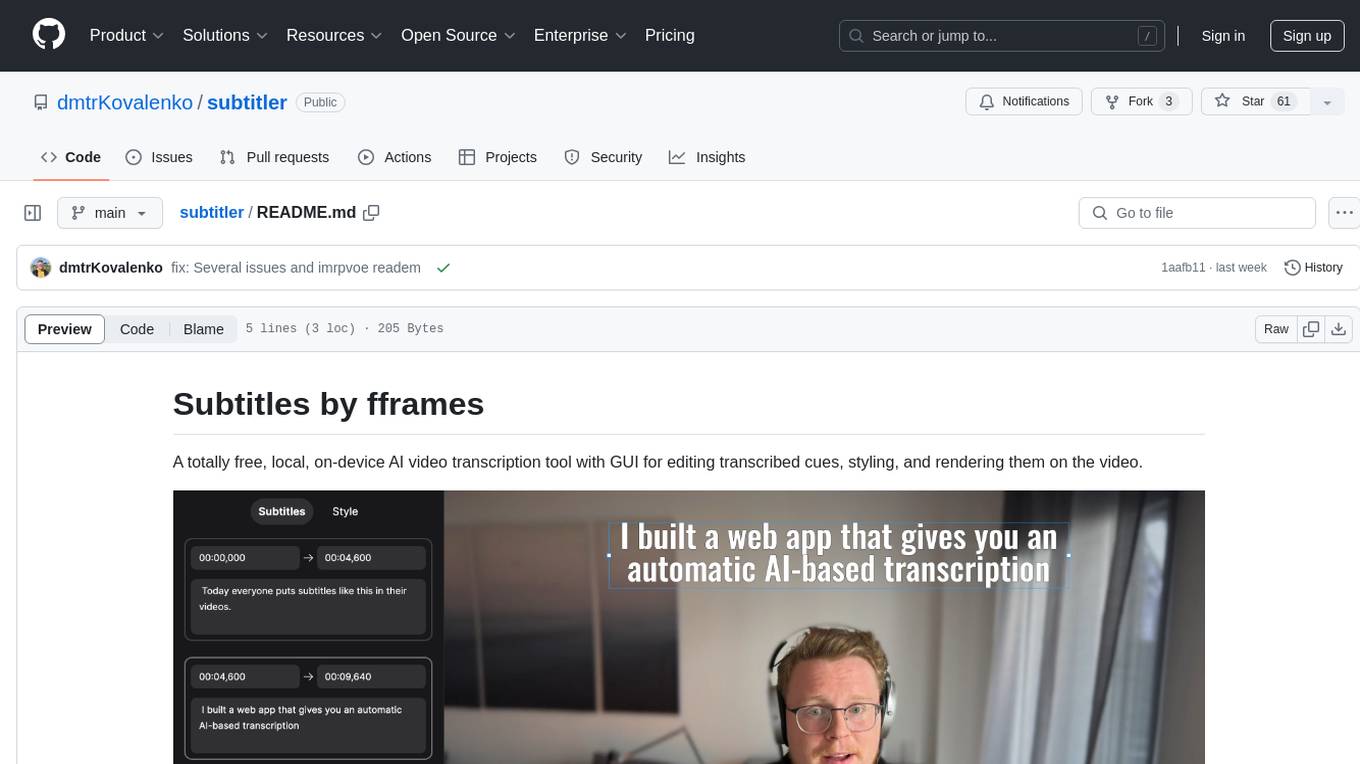
subtitler
Subtitles by fframes is a free, local, on-device AI video transcription tool with a user-friendly GUI. It allows users to transcribe video content, edit transcribed cues, style the subtitles, and render them directly onto the video. The tool provides a convenient way to create accurate subtitles for videos without the need for an internet connection.