
QualityScaler
QualityScaler - image/video AI upscaler app
Stars: 1958

QualityScaler is a Windows app powered by AI to enhance, upscale, and de-noise photographs and videos. It provides an easy-to-use GUI for upscaling images and videos using multiple AI models. The tool supports automatic image tiling and merging to avoid GPU VRAM limitations, resizing images/videos before upscaling, and interpolation between the original and upscaled content. QualityScaler is written in Python and utilizes external packages such as torch, onnxruntime-directml, customtkinter, OpenCV, moviepy, and nuitka. It requires Windows 11 or Windows 10, at least 8GB of RAM, and a Directx12 compatible GPU with 4GB VRAM or more. The tool aims to continue improving with upcoming versions by adding new features, enhancing performance, and supporting additional AI architectures.
README:
QualityScaler - image/video AI upscaler app

Qualityscaler is a Windows app powered by AI to enhance, upscale and de-noise photographs and videos.
- https://github.com/Djdefrag/RealScaler / RealScaler - image/video AI upscaler (Real-ESRGAN)
- https://github.com/Djdefrag/FluidFrames.RIFE / FluidFrames.RIFE - video AI frame generation
- BSRGAN - https://github.com/cszn/BSRGAN
- Real-ESRGAN - https://github.com/xinntao/Real-ESRGAN
- IRCNN - https://github.com/lipengFu/IRCNN
- https://80.lv/articles/80-level-digest-great-ai-powered-tools-for-upscaling-images/
- https://timesavervfx.com/ai-upscale/
QualityScaler is completely written in Python, from backend to frontend. External packages are:
- AI -> torch / onnxruntime-directml
- GUI -> customtkinter
- Image/video -> OpenCV / moviepy
- Packaging -> Pyinstaller
Prerequisites.
- Python installed on your pc, download from here (https://www.python.org/downloads/release/python-3119/)
- VSCode installed on your pc, download from here (https://code.visualstudio.com/)
Getting started.
- First of all, you need to download the project on your PC (Green button Code > Download ZIP)
- Extract the project directory from the .zip
- Now you need to download the AI models (github won't let me upload them directly because they are too big)
- In "AI-onnx" folder, there is the link to download the AI models, download the .zip and extract the files in AI-onnx directory
- Open the project with VSCode (just Drag&Drop the project directory on VSCode)
- Click on QualityScaler.py from left bar (VSCode will ask you to install some plugins, go ahead)
- Now, you need to install dependencies. In VSCode there is the "Terminal" panel, click there and execute the command "pip install -r requirements"
- Close VSCode and re-open it (this will refresh all the dependecies installed)
- Just click on the "Play button" in the upper right corner of VSCode
- Now the app should work
- Windows 11 / Windows 10
- RAM >= 8Gb
- Any Directx12 compatible GPU with >= 4GB VRAM
- [x] Elegant and easy to use GUI
- [x] Image and Video upscale
- [x] Multiple GPUs support
- [x] Compatible images - jpg, png, tif, bmp, webp, heic
- [x] Compatible video - mp4, wemb, mkv, flv, gif, avi, mov, mpg, qt, 3gp
- [x] Automatic image tilling to avoid gpu VRAM limitation
- [x] Resize image/video before upscaling
- [x] Interpolation beetween original file and upscaled file
- [x] Video upscaling STOP&RESUME
- [x] PRIVACY FOCUSED - no internet connection required / everything is on your PC
- [x] 1.X versions
- [x] Switch to Pytorch-directml to support all Directx12 compatible gpu (AMD, Intel, Nvidia)
- [x] New GUI with Windows 11 style
- [x] Include audio for upscaled video
- [x] Optimizing video frame resize and extraction speed
- [x] Multi GPU support (for pc with double GPU, integrated + dedicated)
- [x] Python 3.10 (expecting ~10% more performance)
- [x] 2.X versions
- [x] New, completely redesigned graphical interface based on @customtkinter
- [x] Upscaling images and videos at once (currently it is possible to upscale images or single video)
- [x] Upscale multiple videos at once
- [x] Choose upscaled video extension
- [x] Interpolation between the original and upscaled image/video
- [x] More Interpolation levels (Low, Medium, High)
- [x] Show the remaining time to complete video upscaling
- [x] Support for SRVGGNetCompact AI architecture
- [x] Metadata extraction and application from original file to upscaled file (via exiftool)
- [ ] 3.X versions
- [x] New AI engine powered by onnxruntime-directml (https://github.com/microsoft/onnxruntime))
- [x] Python 3.11 (performance improvements)
- [x] Python 3.12 (performance improvements)
- [x] Display images/videos upscaled resolution in the GUI
- [x] Updated FFMPEG to version 7.x (latest release)
- [x] Saving user settings (AI model, GPU, CPU etc.)
- [x] Video multi-threading AI upscale
- [x] Video upscaling STOP&RESUME





For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for QualityScaler
Similar Open Source Tools
QualityScaler
QualityScaler is a Windows app powered by AI to enhance, upscale, and de-noise photographs and videos. It provides an easy-to-use GUI for upscaling images and videos using multiple AI models. The tool supports automatic image tiling and merging to avoid GPU VRAM limitations, resizing images/videos before upscaling, and interpolation between the original and upscaled content. QualityScaler is written in Python and utilizes external packages such as torch, onnxruntime-directml, customtkinter, OpenCV, moviepy, and nuitka. It requires Windows 11 or Windows 10, at least 8GB of RAM, and a Directx12 compatible GPU with 4GB VRAM or more. The tool aims to continue improving with upcoming versions by adding new features, enhancing performance, and supporting additional AI architectures.

RealScaler
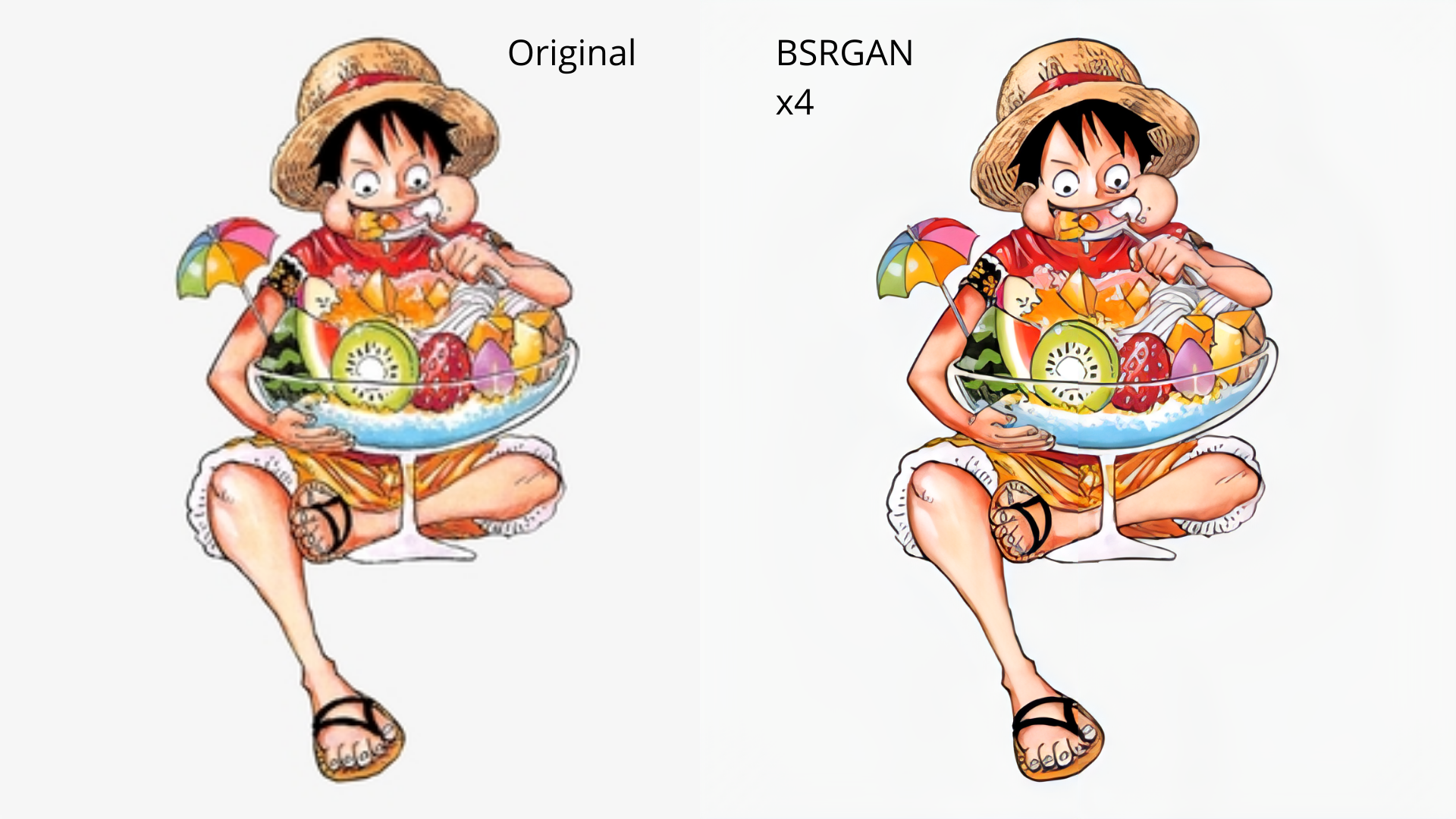
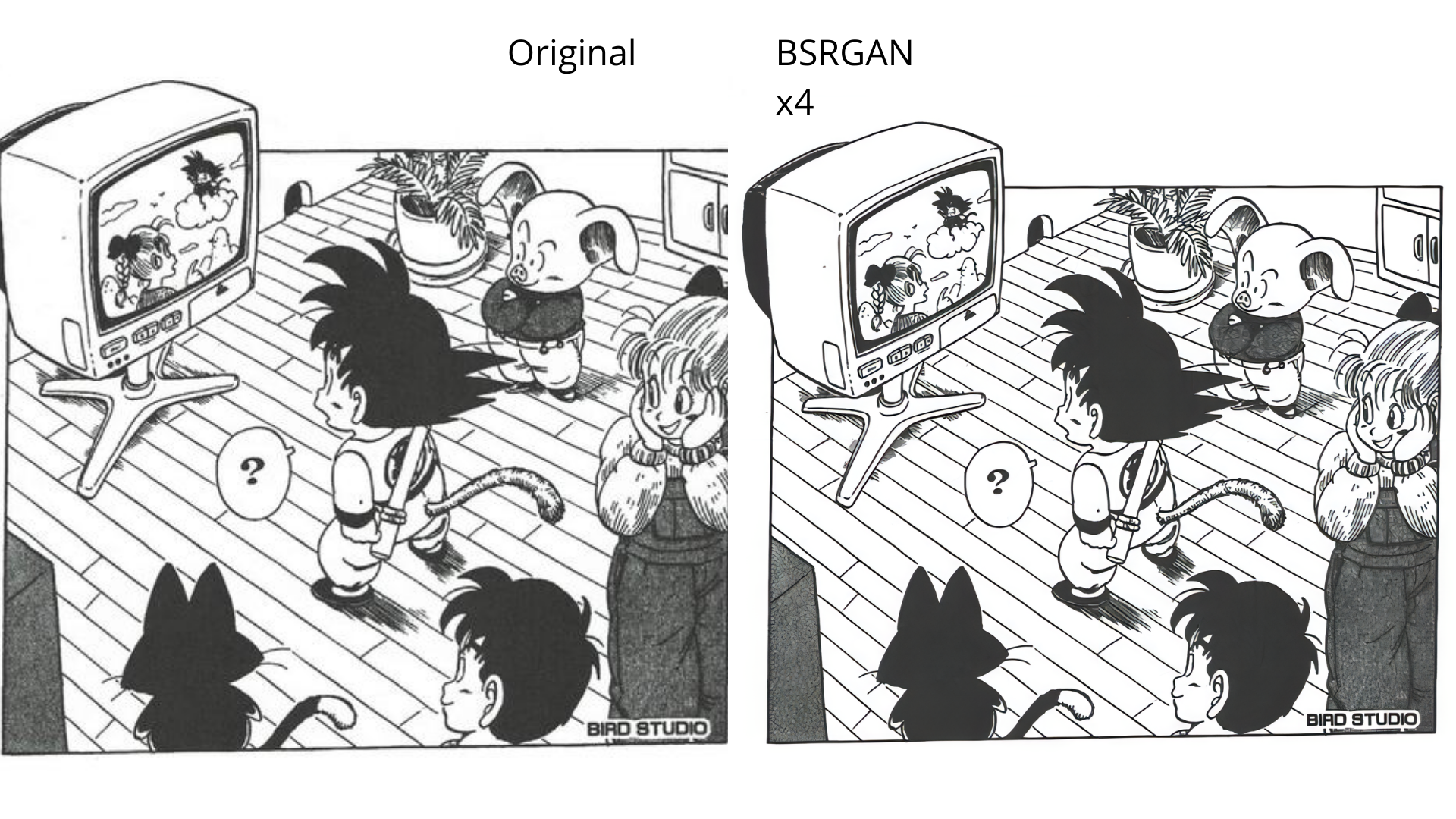
RealScaler is a Windows app powered by RealESRGAN AI to enhance, upscale, and de-noise photos and videos. It provides an easy-to-use GUI for upscaling images and videos using multiple AI models. The tool supports automatic image tiling and merging to avoid GPU VRAM limitations, resizing images/videos before upscaling, interpolation between original and upscaled content, and compatibility with various image and video formats. RealScaler is written in Python and requires Windows 11/10, at least 8GB RAM, and a Directx12 compatible GPU with 4GB VRAM. Future versions aim to enhance performance, support more GPUs, offer a new GUI with Windows 11 style, include audio for upscaled videos, and provide features like metadata extraction and application from original to upscaled files.
FluidFrames.RIFE
FluidFrames.RIFE is a Windows app powered by RIFE AI to create frame-generated and slowmotion videos. It is written in Python and utilizes external packages such as torch, onnxruntime-directml, customtkinter, OpenCV, moviepy, and Nuitka. The app features an elegant GUI, video frame generation at different speeds, video slow motion, video resizing, multiple GPU support, and compatibility with various video formats. Future versions aim to support different GPU types, enhance the GUI, include audio processing, optimize video processing speed, and introduce new features like saving AI-generated frames and supporting different RIFE AI models.
painting-droid
Painting Droid is an AI-powered cross-platform painting app inspired by MS Paint, expandable with plugins and open. It utilizes various AI models, from paid providers to self-hosted open-source models, as well as some lightweight ones built into the app. Features include regular painting app features, AI-generated content filling and augmentation, filters and effects, image manipulation, plugin support, and cross-platform compatibility.
witsy
Witsy is a generative AI desktop application that supports various models like OpenAI, Ollama, Anthropic, MistralAI, Google, Groq, and Cerebras. It offers features such as chat completion, image generation, scratchpad for content creation, prompt anywhere functionality, AI commands for productivity, expert prompts for specialization, LLM plugins for additional functionalities, read aloud capabilities, chat with local files, transcription/dictation, Anthropic Computer Use support, local history of conversations, code formatting, image copy/download, and more. Users can interact with the application to generate content, boost productivity, and perform various AI-related tasks.
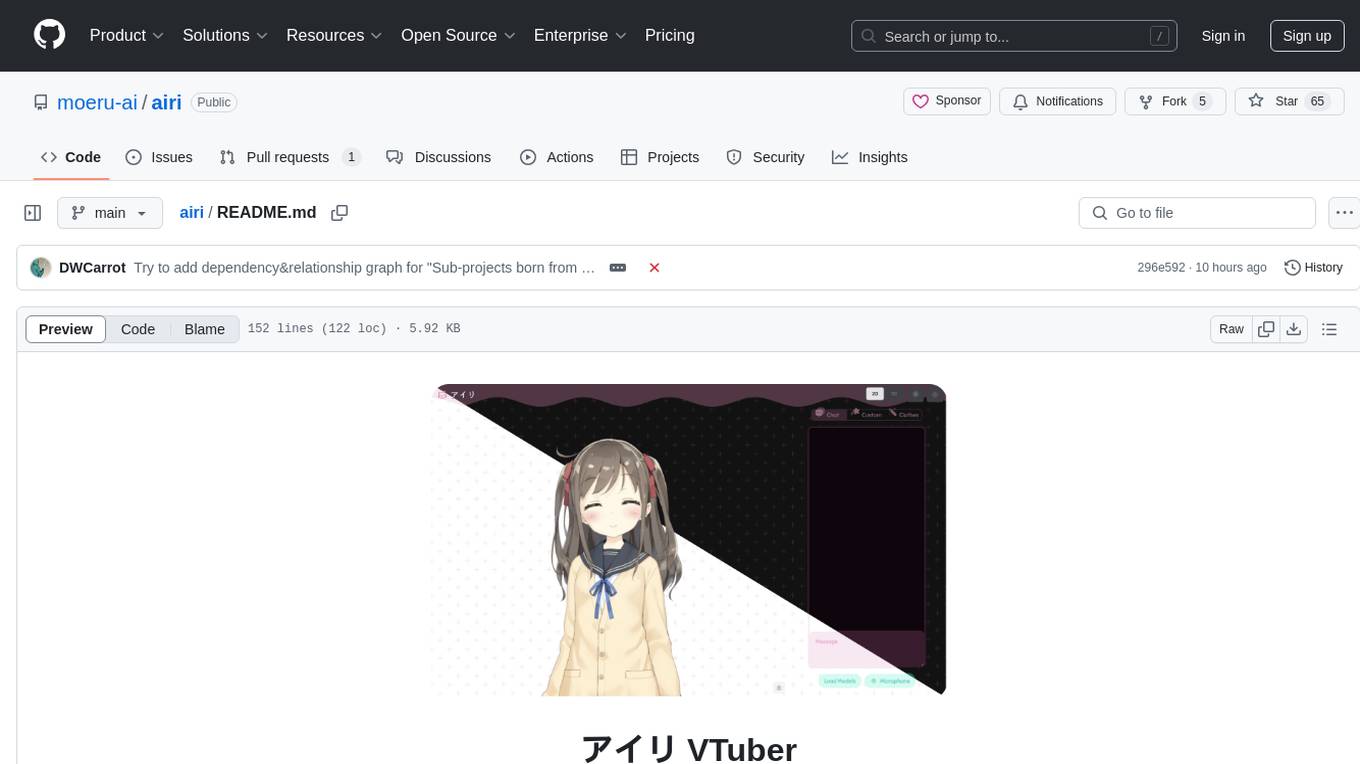
airi
Airi is a VTuber project heavily inspired by Neuro-sama. It is capable of various functions such as playing Minecraft, chatting in Telegram and Discord, audio input from browser and Discord, client side speech recognition, VRM and Live2D model support with animations, and more. The project also includes sub-projects like unspeech, hfup, Drizzle ORM driver for DuckDB WASM, and various other tools. Airi uses models like whisper-large-v3-turbo from Hugging Face and is similar to projects like z-waif, amica, eliza, AI-Waifu-Vtuber, and AIVTuber. The project acknowledges contributions from various sources and implements packages to interact with LLMs and models.

screenpipe
24/7 Screen & Audio Capture Library to build personalized AI powered by what you've seen, said, or heard. Works with Ollama. Alternative to Rewind.ai. Open. Secure. You own your data. Rust. We are shipping daily, make suggestions, post bugs, give feedback. Building a reliable stream of audio and screenshot data, simplifying life for developers by solving non-trivial problems. Multiple installation options available. Experimental tool with various integrations and features for screen and audio capture, OCR, STT, and more. Open source project focused on enabling tooling & infrastructure for a wide range of applications.
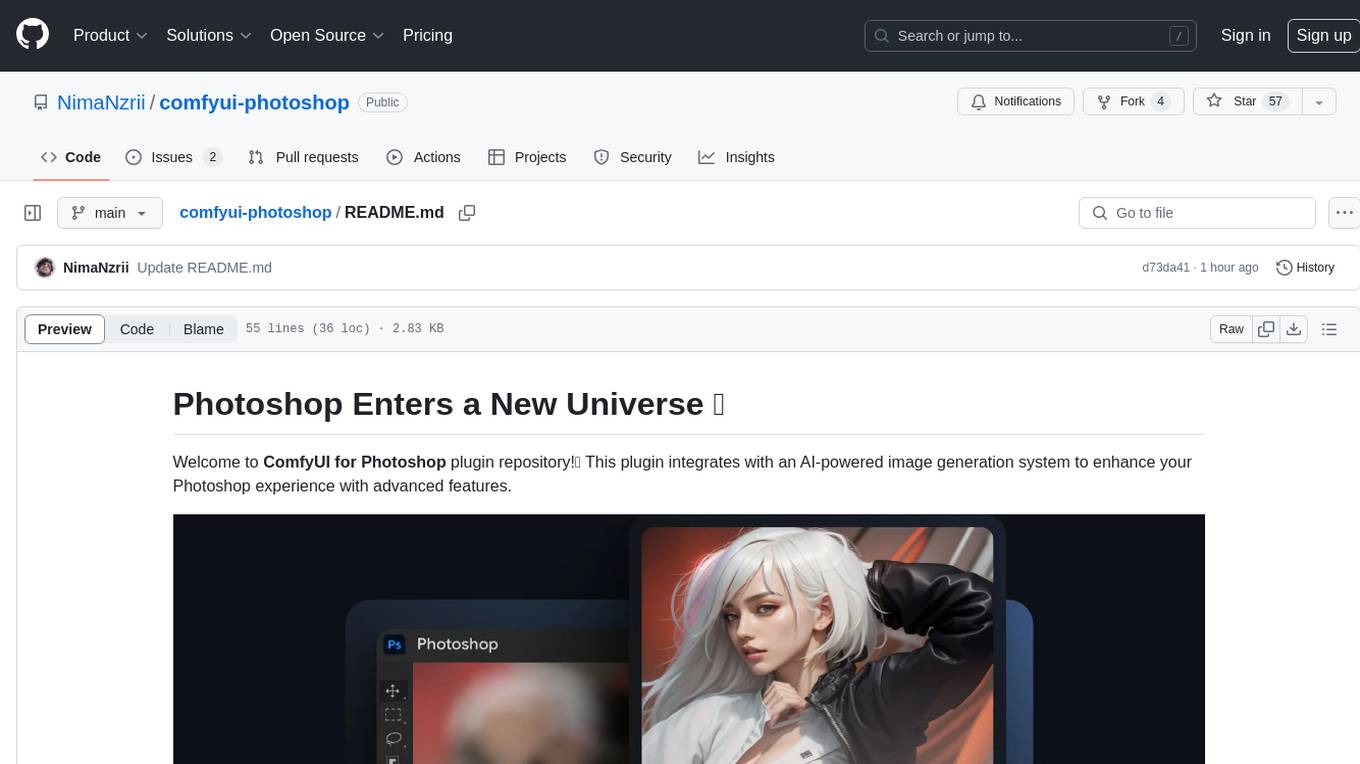
comfyui-photoshop
ComfyUI for Photoshop is a plugin that integrates with an AI-powered image generation system to enhance the Photoshop experience with features like unlimited generative fill, customizable back-end, AI-powered artistry, and one-click transformation. The plugin requires a minimum of 6GB graphics memory and 12GB RAM. Users can install the plugin and set up the ComfyUI workflow using provided links and files. Additionally, specific files like Check points, Loras, and Detailer Lora are required for different functionalities. Support and contributions are encouraged through GitHub.
Pallaidium
Pallaidium is a generative AI movie studio integrated into the Blender video editor. It allows users to AI-generate video, image, and audio from text prompts or existing media files. The tool provides various features such as text to video, text to audio, text to speech, text to image, image to image, image to video, video to video, image to text, and more. It requires a Windows system with a CUDA-supported Nvidia card and at least 6 GB VRAM. Pallaidium offers batch processing capabilities, text to audio conversion using Bark, and various performance optimization tips. Users can install the tool by downloading the add-on and following the installation instructions provided. The tool comes with a set of restrictions on usage, prohibiting the generation of harmful, pornographic, violent, or false content.
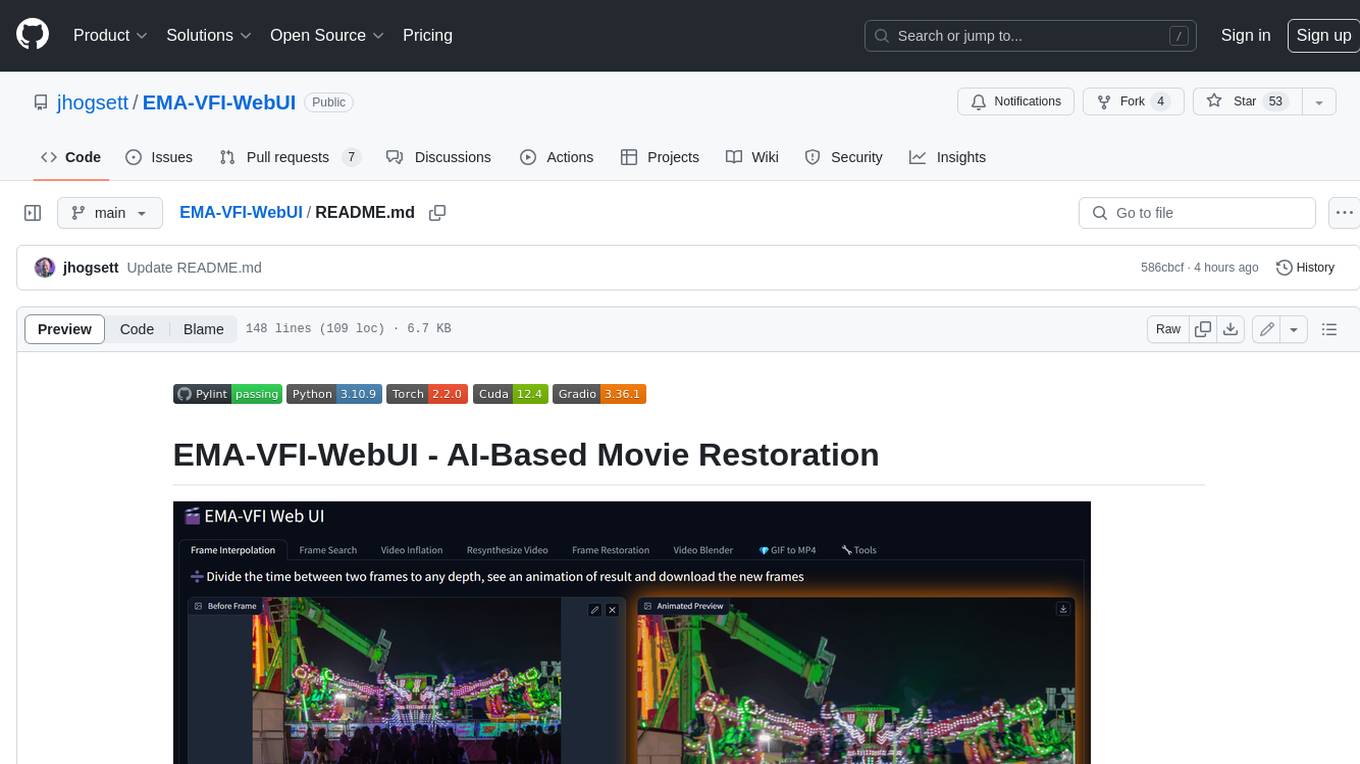
EMA-VFI-WebUI
EMA-VFI-WebUI is a web-based graphical user interface (GUI) for the EMA-VFI AI-based movie restoration tool. It provides a user-friendly interface for accessing the various features of EMA-VFI, including frame interpolation, frame search, video inflation, video resynthesis, frame restoration, video blending, file conversion, file resequencing, FPS conversion, GIF to MP4 conversion, and frame upscaling. The web UI makes it easy to use EMA-VFI's powerful features without having to deal with the command line interface.

ColossalAI
Colossal-AI is a deep learning system for large-scale parallel training. It provides a unified interface to scale sequential code of model training to distributed environments. Colossal-AI supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer.
LLMFarm
LLMFarm is an iOS and MacOS app designed to work with large language models (LLM). It allows users to load different LLMs with specific parameters, test the performance of various LLMs on iOS and macOS, and identify the most suitable model for their projects. The tool is based on ggml and llama.cpp by Georgi Gerganov and incorporates sources from rwkv.cpp by saharNooby, Mia by byroneverson, and LlamaChat by alexrozanski. LLMFarm features support for MacOS (13+) and iOS (16+), various inferences and sampling methods, Metal compatibility (not supported on Intel Mac), model setting templates, LoRA adapters support, LoRA finetune support, LoRA export as model support, and more. It also offers a range of inferences including LLaMA, GPTNeoX, Replit, GPT2, Starcoder, RWKV, Falcon, MPT, Bloom, and others. Additionally, it supports multimodal models like LLaVA, Obsidian, and MobileVLM. Users can customize inference options through JSON files and access supported models for download.
llama-assistant
Llama Assistant is a local AI assistant that respects your privacy. It is an AI-powered assistant that can recognize your voice, process natural language, and perform various actions based on your commands. It can help with tasks like summarizing text, rephrasing sentences, answering questions, writing emails, and more. The assistant runs offline on your local machine, ensuring privacy by not sending data to external servers. It supports voice recognition, natural language processing, and customizable UI with adjustable transparency. The project is a work in progress with new features being added regularly.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.
big-AGI
big-AGI is an AI suite designed for professionals seeking function, form, simplicity, and speed. It offers best-in-class Chats, Beams, and Calls with AI personas, visualizations, coding, drawing, side-by-side chatting, and more, all wrapped in a polished UX. The tool is powered by the latest models from 12 vendors and open-source servers, providing users with advanced AI capabilities and a seamless user experience. With continuous updates and enhancements, big-AGI aims to stay ahead of the curve in the AI landscape, catering to the needs of both developers and AI enthusiasts.

AIMr
AIMr is an AI aimbot tool written in Python that leverages modern technologies to achieve an undetected system with a pleasing appearance. It works on any game that uses human-shaped models. To optimize its performance, users should build OpenCV with CUDA. For Valorant, additional perks in the Discord and an Arduino Leonardo R3 are required.
For similar tasks
QualityScaler
QualityScaler is a Windows app powered by AI to enhance, upscale, and de-noise photographs and videos. It provides an easy-to-use GUI for upscaling images and videos using multiple AI models. The tool supports automatic image tiling and merging to avoid GPU VRAM limitations, resizing images/videos before upscaling, and interpolation between the original and upscaled content. QualityScaler is written in Python and utilizes external packages such as torch, onnxruntime-directml, customtkinter, OpenCV, moviepy, and nuitka. It requires Windows 11 or Windows 10, at least 8GB of RAM, and a Directx12 compatible GPU with 4GB VRAM or more. The tool aims to continue improving with upcoming versions by adding new features, enhancing performance, and supporting additional AI architectures.
XLICON-V2-MD
XLICON-V2-MD is a versatile Multi-Device WhatsApp bot developed by Salman Ahamed. It offers a wide range of features, making it an advanced and user-friendly bot for various purposes. The bot supports multi-device operation, AI photo enhancement, downloader commands, hidden NSFW commands, logo generation, anime exploration, economic activities, games, and audio/video editing. Users can deploy the bot on platforms like Heroku, Replit, Codespace, Okteto, Railway, Mongenius, Coolify, and Render. The bot is maintained by Salman Ahamed and Abraham Dwamena, with contributions from various developers and testers. Misusing the bot may result in a ban from WhatsApp, so users are advised to use it at their own risk.

easydiffusion
Easy Diffusion 3.0 is a user-friendly tool for installing and using Stable Diffusion on your computer. It offers hassle-free installation, clutter-free UI, task queue, intelligent model detection, live preview, image modifiers, multiple prompts file, saving generated images, UI themes, searchable models dropdown, and supports various image generation tasks like 'Text to Image', 'Image to Image', and 'InPainting'. The tool also provides advanced features such as custom models, merge models, custom VAE models, multi-GPU support, auto-updater, developer console, and more. It is designed for both new users and advanced users looking for powerful AI image generation capabilities.
RealScaler
RealScaler is a Windows app powered by RealESRGAN AI to enhance, upscale, and de-noise photos and videos. It provides an easy-to-use GUI for upscaling images and videos using multiple AI models. The tool supports automatic image tiling and merging to avoid GPU VRAM limitations, resizing images/videos before upscaling, interpolation between original and upscaled content, and compatibility with various image and video formats. RealScaler is written in Python and requires Windows 11/10, at least 8GB RAM, and a Directx12 compatible GPU with 4GB VRAM. Future versions aim to enhance performance, support more GPUs, offer a new GUI with Windows 11 style, include audio for upscaled videos, and provide features like metadata extraction and application from original to upscaled files.
Topu-ai
TOPU Md is a simple WhatsApp user bot created by Topu Tech. It offers various features such as multi-device support, AI photo enhancement, downloader commands, hidden NSFW commands, logo commands, anime commands, economy menu, various games, and audio/video editor commands. Users can fork the repo, get a session ID by pairing code, and deploy on Heroku. The bot requires Node version 18.x or higher for optimal performance. Contributions to TOPU-MD are welcome, and the tool is safe for use on WhatsApp and Heroku. The tool is licensed under the MIT License and is designed to enhance the WhatsApp experience with diverse features.
Adobe-Photoshop-CC---Download
Adobe Photoshop CC Download is a free software tool that offers full optimization through a simple and easy menu. It supports most systems, including Windows 7/8/8.1/10/11 (x32/64), and is completely safe for your Windows system. The tool provides features such as free proxy, compatibility with any PC, and 24/7 support. Users can download the latest version from the provided link and enjoy the benefits of Adobe Photoshop for various editing tasks.
Topaz-Photo-AI
Topaz-Photo-AI is a software tool designed to enhance and improve the quality of photos using artificial intelligence technology. Users can easily download, install, and run the software to apply various enhancements to their images. The tool provides a user-friendly interface and a range of features to help users enhance their photos with just a few simple steps. With Topaz-Photo-AI, users can achieve professional-level results in photo editing without the need for advanced skills or knowledge.
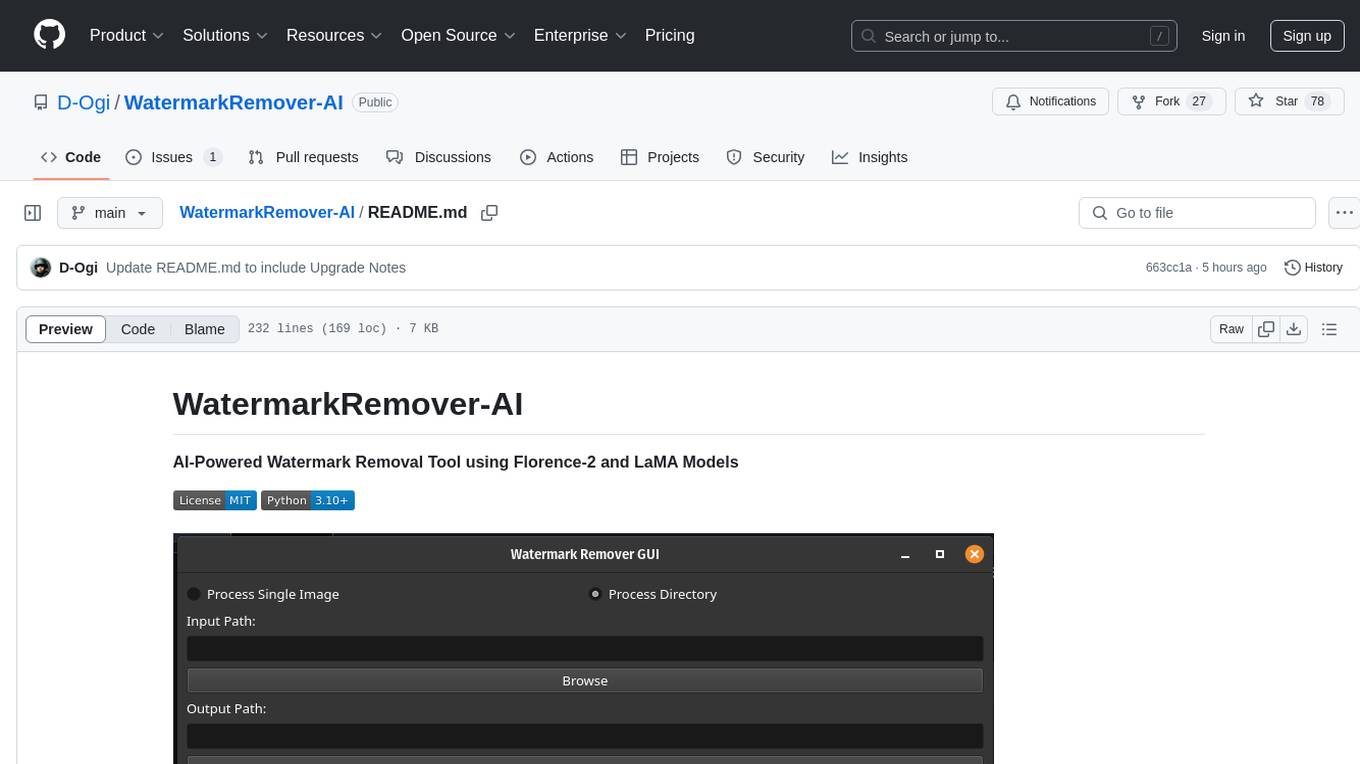
WatermarkRemover-AI
WatermarkRemover-AI is an advanced application that utilizes AI models for precise watermark detection and seamless removal. It leverages Florence-2 for watermark identification and LaMA for inpainting. The tool offers both a command-line interface (CLI) and a PyQt6-based graphical user interface (GUI), making it accessible to users of all levels. It supports dual modes for processing images, advanced watermark detection, seamless inpainting, customizable output settings, real-time progress tracking, dark mode support, and efficient GPU acceleration using CUDA.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.