
vector_companion
A local AI companion that uses a collection of free, open source AI models in order to create two virtual companions that will follow your computer journey wherever you go!
Stars: 130
Vector Companion is an AI tool designed to act as a virtual companion on your computer. It consists of two personalities, Axiom and Axis, who can engage in conversations based on what is happening on the screen. The tool can transcribe audio output and user microphone input, take screenshots, and read text via OCR to create lifelike interactions. It requires specific prerequisites to run on Windows and uses VB Cable to capture audio. Users can interact with Axiom and Axis by running the main script after installation and configuration.
README:
Your friendly AI Companion, with two distinct personalities: Axiom, Axis and the gang! Here to accompany you everywhere you go on your computer!
- Introduction
- Features
- Demo
- Installation
- Usage
- Troubleshooting VB Cable and Microphone Issues
- Contributing
- License
Whether playing games, watching videos, or browsing online, These agents will talk to each other about whatever you're doing and will also talk to you directly when prompted! The motivation behind this project is to create not one, but multiple multimodal virtual companions who are very lifelike, responsive, and charming. They can see, hear, and speak about anything presented to them on screen!
They transcribe audio output and user microphone input simultaneously while periodically taking screenshots and viewing/reading OCR text on screen. They use this information to form a conversation and chat about anything and everything under the sun!
- Can view images periodically, captioning images and reading text via OCR.
- Can hear and transcribe computer audio in real-time (English only due to base model size Whisper language limitations but you may replace base with WhisperV3 Turbo for multilingual support).
- Can hear user microphone input in real-time (English only due to base model size Whisper language limitations but you may replace base with WhisperV3 Turbo for multilingual support).
- Voice Cloning enables distinct voice output generation for agents Axiom and Axis.
Note: This framework is designed to run on Windows only.
- Minimum 15GB VRAM required to run the entire framework on
gemma2:2b-instruct-q8_0. You may swap out the model in thelanguage_modelvariable inmain.pyif you would like to lower the VRAM usage or replace the model with a larger one. - You will need a
torchversion compatible with your CUDA version installed. - You need to install Ollama if you haven't already and download
gemma2:2b-instruct-q8_0or whichever model you'd like to use in Ollama. You must also installminicpm-v:8b-2.6-q4_0(or greater size) in order to use updated vision component. - You need VB Cable installed on your PC in order for Python to listen to your own PC.
git clone https://github.com/SingularityMan/vector_companion.git
cd vector_companion
conda create --name vector_companion
conda activate vector_companion
pip install -r requirements.txt
On Windows, install VB Cable so Python can listen to the computer's audio output in real-time. Once installed, link VB Cable to the device (presumably your headset) via Windows Sound settings so Python can accurately capture the sound. Ensure VB Cable is selected as your speaker once it is configured, otherwise Vector Companion won't be able to hear audio.
After meeting the necessary prerequisites, installing the required dependencies, and configuring then troubleshooting any VB Cable issues (listed below), simply run main.py.
conda activate vector_companion
python main.py
If you successfully installed VB Cable and correctly linked it to the device of your choice but the framework isn't capturing computer audio (and therefore not transcribing it), review the input_device_index keyword parameter in p.open() under the record_audio_output() function in config/config.py. The script may or may not link to the correct device index. If you have multiple devices, it might incorrectly pick the wrong one. If this is the case, try manually assigning the index starting from index 0 and work your way up. You may receive streaming errors with each attempt:
def record_audio_output(audio, WAVE_OUTPUT_FILENAME, FORMAT, CHANNELS, RATE, CHUNK, RECORD_SECONDS, file_index_count):
global can_speak
file_index = 0
while True:
# Check if an agent is responding.
if not can_speak_event.is_set():
print("[record_audio_output] Waiting for response to complete...")
time.sleep(1)
continue
# Create a PyAudio instance
p = pyaudio.PyAudio()
# Find the device index of the VB-Cable adapter
device_index = None
for i in range(p.get_device_count()):
device_info = p.get_device_info_by_index(i)
if 'VB-Audio' in device_info['name']: # Look for 'VB-Audio' instead of 'VB-Cable'
device_index = i
break
if device_index is None:
print("Could not find VB-Cable device")
exit(1)
# Open the stream for recording
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK,
input_device_index=device_index) <------------------------------------- device_index
print("* recording Audio Transcript")
You will also most likely need to modify the input_device_index keyword argument under audio.open() in record_audio() to select the right microphone index for your headset, which is set to 1 by default. If no audio input is being captured, follow similar steps with record_audio() in config/config.py:
def record_audio(audio, WAVE_OUTPUT_FILENAME, FORMAT, RATE, CHANNELS, CHUNK, RECORD_SECONDS, THRESHOLD, SILENCE_LIMIT, vision_model, processor):
global image_lock
global can_speak
ii = 0
try:
while True:
# Cancel recording if Agent speaking
if not can_speak_event.is_set():
time.sleep(1)
print("[record_user_mic] Waiting for response to complete...")
continue
# Start Recording
stream = audio.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, input_device_index=1, frames_per_buffer=CHUNK) <------------------------------- device index
#print("waiting for speech...")
frames = []
image_path = None
Install Microsoft Visual Studio Code's latest version (2022) that is compatible with your CUDA version (12.2 or greater) and in the installer, make sure to include these capabilities:
- MSVC v143 - VS 2022 C++ x64/x86 build tools (x86 & x84)
- C++ CMake Tools for Windows
- Windows 10 or Windows 11 SDK, depending on your Windows OS
After that, install a version of torch compatible with your CUDA version that is compatible with MSVC.
Lastly, make sure to carefully edit then run flash-attn-clone-source-compile-stable-torch.bat in order to build flash_attn from source. Make sure to edit the file to compile flash_attn for a version compatible with your torch/CUDA and your python version.
Contributions are welcome! You may follow our contribution guides here.
This project is licensed under the Vector Companion License - see the LICENSE file for details.
Note: This project includes the XTTSv2 model, which is licensed under a restrictive license. Please refer to the XTTSv2 License for specific terms and conditions.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for vector_companion
Similar Open Source Tools
vector_companion
Vector Companion is an AI tool designed to act as a virtual companion on your computer. It consists of two personalities, Axiom and Axis, who can engage in conversations based on what is happening on the screen. The tool can transcribe audio output and user microphone input, take screenshots, and read text via OCR to create lifelike interactions. It requires specific prerequisites to run on Windows and uses VB Cable to capture audio. Users can interact with Axiom and Axis by running the main script after installation and configuration.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
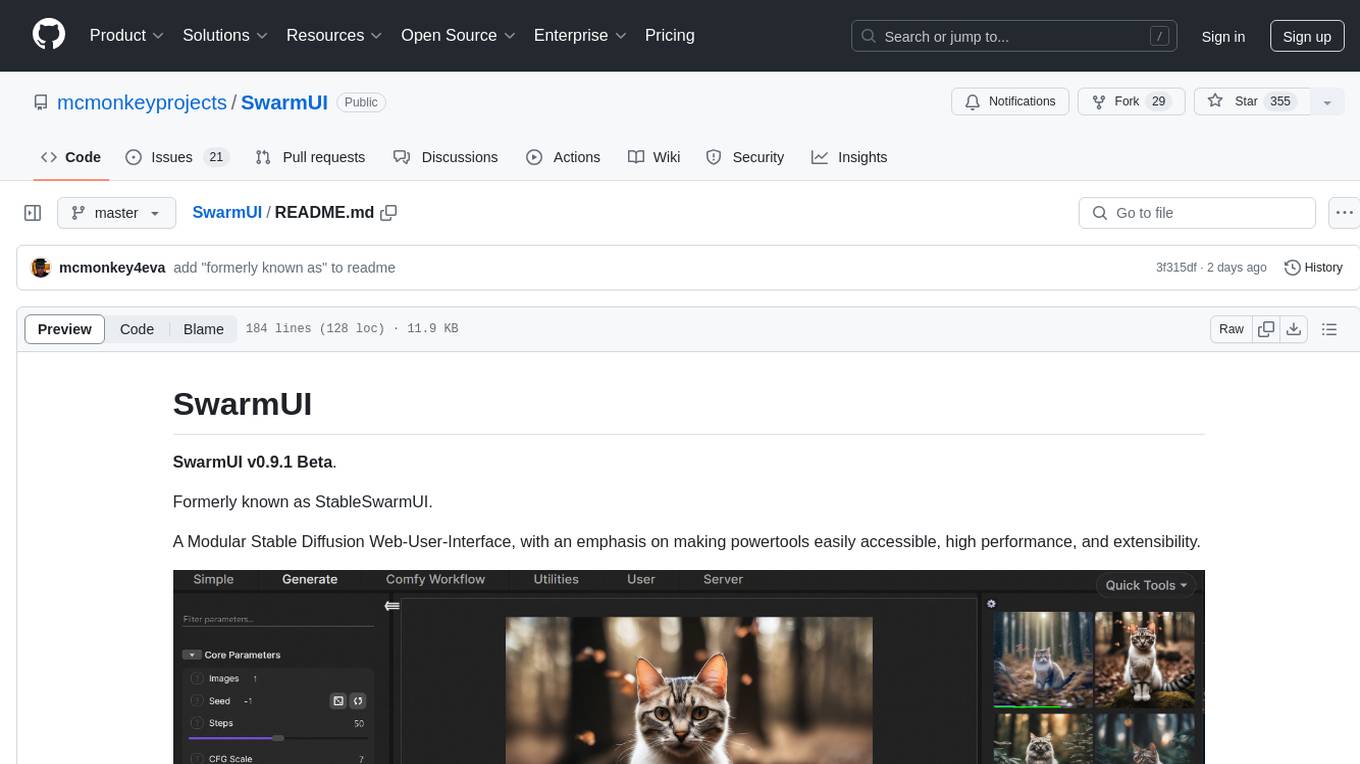
SwarmUI
SwarmUI is a modular stable diffusion web-user-interface designed to make powertools easily accessible, high performance, and extensible. It is in Beta status, offering a primary Generate tab for beginners and a Comfy Workflow tab for advanced users. The tool aims to become a full-featured one-stop-shop for all things Stable Diffusion, with plans for better mobile browser support, detailed 'Current Model' display, dynamic tab shifting, LLM-assisted prompting, and convenient direct distribution as an Electron app.
nobodywho
NobodyWho is a plugin for the Godot game engine that enables interaction with local LLMs for interactive storytelling. Users can install it from Godot editor or GitHub releases page, providing their own LLM in GGUF format. The plugin consists of `NobodyWhoModel` node for model file, `NobodyWhoChat` node for chat interaction, and `NobodyWhoEmbedding` node for generating embeddings. It offers a programming interface for sending text to LLM, receiving responses, and starting the LLM worker.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
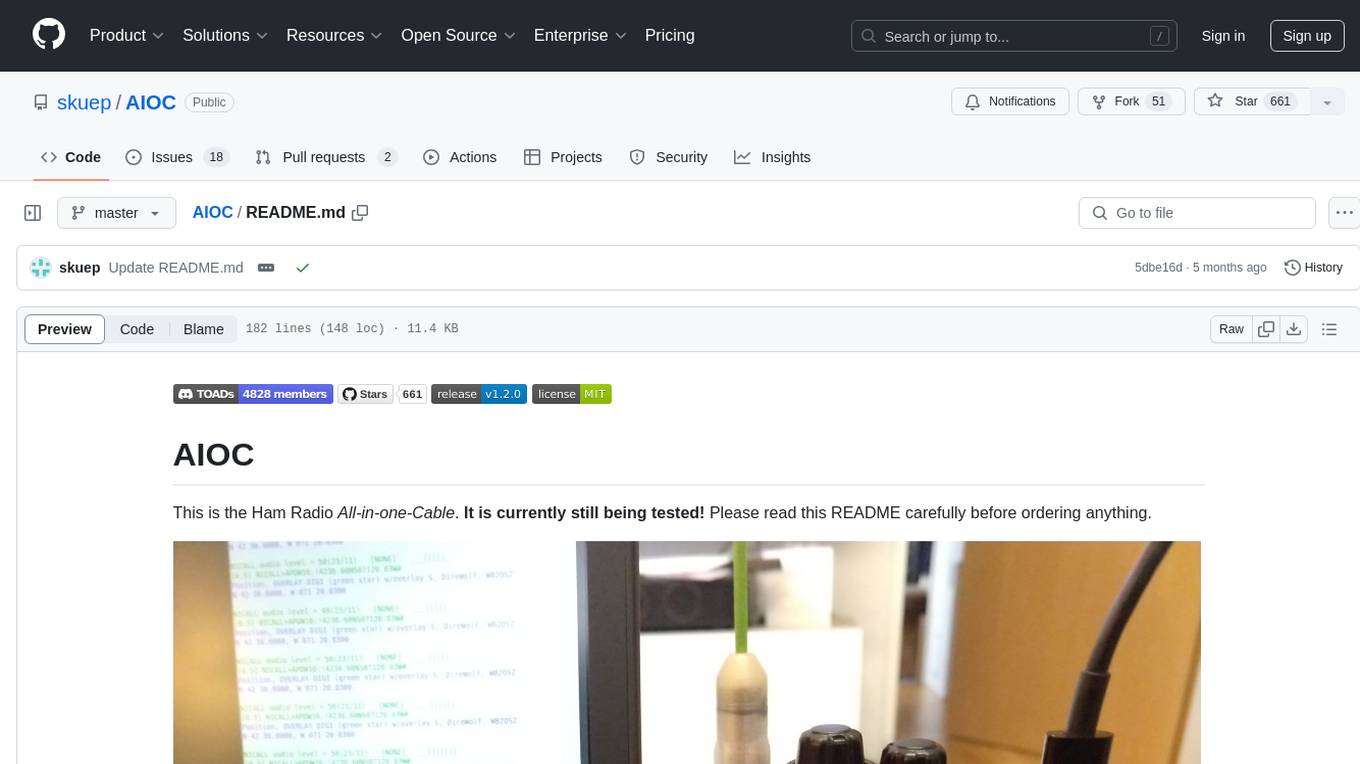
AIOC
AIOC is an All-in-one-Cable for Ham Radio enthusiasts, providing a cheap and hackable digital mode USB interface with features like sound-card, virtual tty, and CM108 compatible HID endpoint. It supports various software and tested radios for functions like programming, APRS, and Dual-PTT HTs. Users can fabricate and assemble the AIOC using specific instructions, and program it using STM32CubeIDE. The tool can be used for tasks like programming radios, asserting PTT, and accessing audio data channels. Future work includes configurable AIOC settings, virtual-PTT, and virtual-COS features.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
MusicGPT
MusicGPT is an application that allows running the latest music generation AI models locally in a performant way, supporting different music generation models transparently to the user. It can be interacted with through UI mode or CLI mode, generating music based on natural language prompts. The tool requires access to storage to save downloaded models and generated audios along with metadata. It is licensed under MIT License for the code and CC-BY-NC-4.0 License for the AI model weights.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.
For similar tasks

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

twinny
Twinny is a free and open-source AI code completion plugin for Visual Studio Code and compatible editors. It integrates with various tools and frameworks, including Ollama, llama.cpp, oobabooga/text-generation-webui, LM Studio, LiteLLM, and Open WebUI. Twinny offers features such as fill-in-the-middle code completion, chat with AI about your code, customizable API endpoints, and support for single or multiline fill-in-middle completions. It is easy to install via the Visual Studio Code extensions marketplace and provides a range of customization options. Twinny supports both online and offline operation and conforms to the OpenAI API standard.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.